

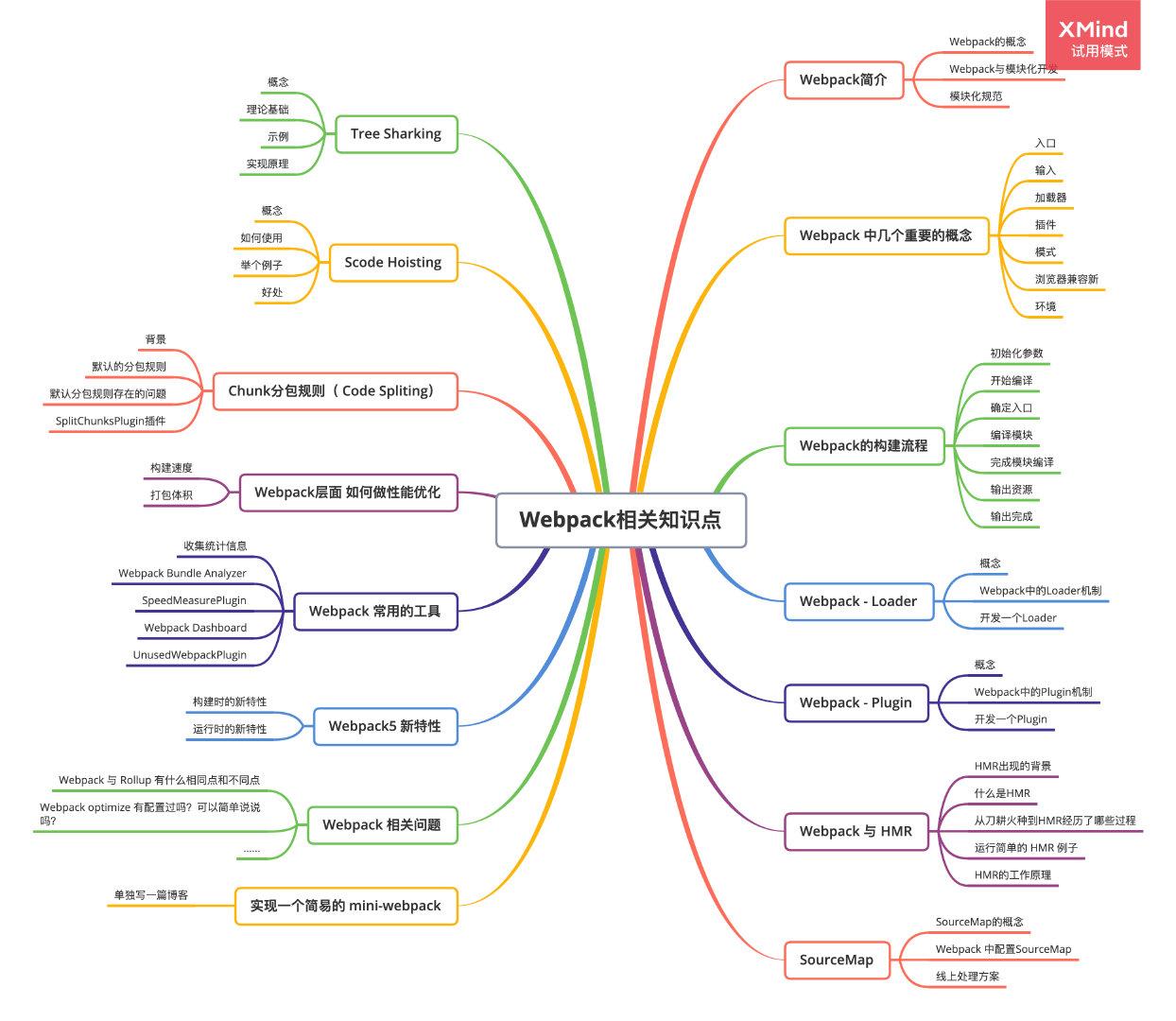
前端面试题系列文章:
【12】「2023」性能优化相关知识点
【13】「2023」H5相关知识点
Webpack简介
Webpack的概念
Webpack本质上是一个用于现代JavaScript应用程序的静态模块打包工具。
当Webpack处理应用程序时,它会在内部从一个或者多个入口构建一个依赖图(dependency graph),然后将你项目中所需的每一个模块组合成一个或多个(通常是多个)浏览器能直接识别的bundles,用于在浏览器中展示你的内容。
Webpack与模块化开发
随着前段技术的深入发展,html + css + js 一把嗦的方式如今已经不再适用了。假设在一个html中引入大量的js文件很难管理,首先想到的就是变量污染的问题,A模块的变量可能和B模块的变量重名。其次,不存在私有空间,所有内部模块的变量都有可能在模块外部被修改。除此之外,模块与模块之间的依赖关系也非常难管理。
为了解决这些问题,前端在发展过程中也提出过一些解决方案。
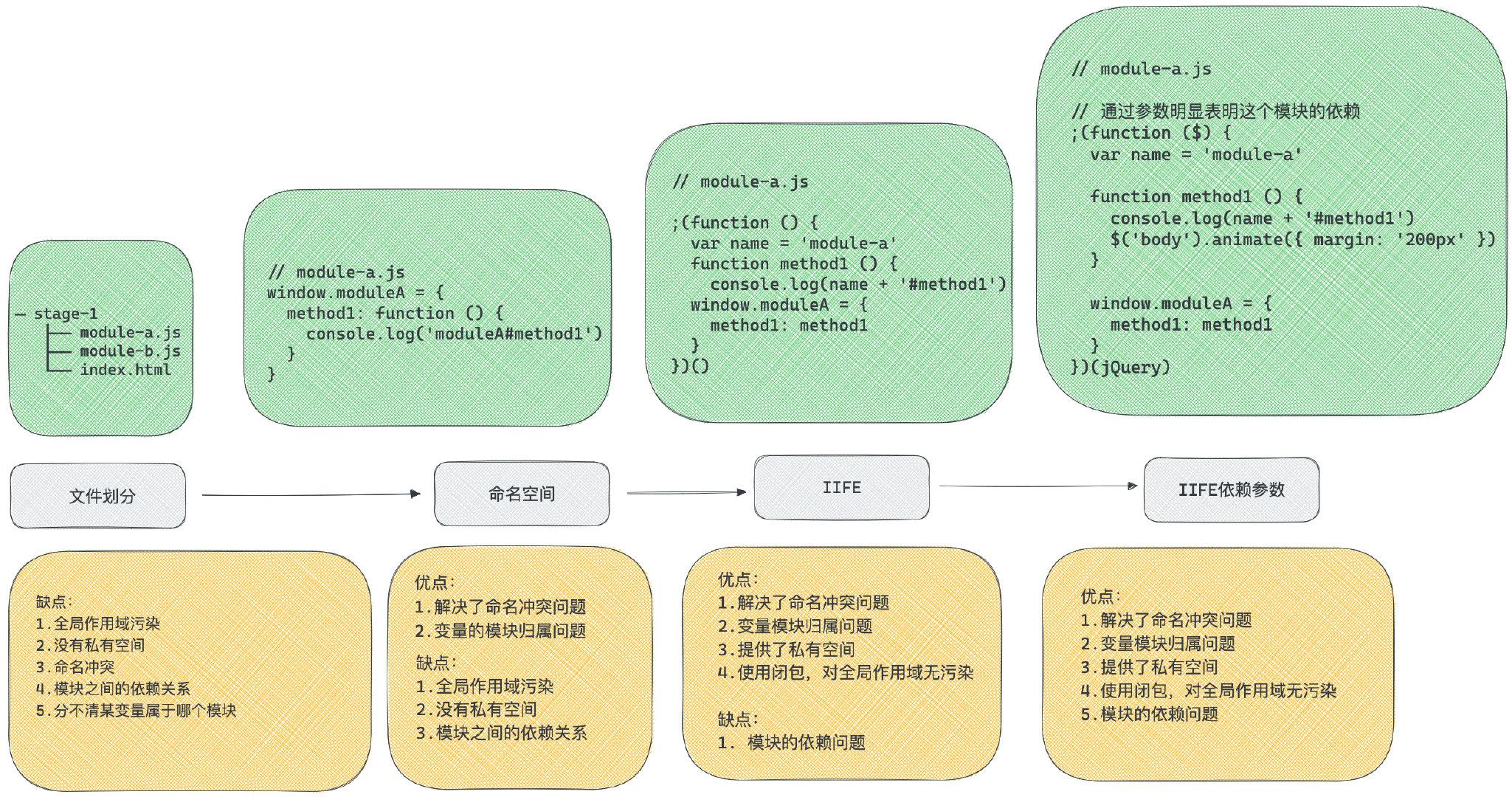
以上四个阶段是早期没有工具和规范的情况下对前端模块化管理的解决方案。虽然一定程度上实现了前端模块化,但是仍然存在一些问题。其中最主要的问题就是模块的加载问题:我们是通过script标签引入的方式加载各个模块的,这意味着模块的加载并不受代码的控制,时间就了维护起来就很麻烦。
所以!更为理想的方式是在页面中引入一个JS入口文件,其余要用到的模块我们可以通过代码控制,按需加载进来。
模块化规范的出现
- Node: CommonJS
- 浏览器端: AMD => Sea.js => ES Modules
模块化打包工具的基本功能
模块化规范的出现帮助我们更好的解决复杂应用中的代码组织问题,但是模块化规范也存在一些需要解决的问题:
- 首先ES Modules 是在ES6中提出来的,目前来说还存在兼容性问题。尽管目前主流的浏览器都支持,但是要保证覆盖到大部分的用户,我们还需要解决低版本兼容性问题。
- 其次,模块化的划分方式会导致划分出来的模块过多,前端应用运行在浏览器中,一个应用加载大量零散的JS文件,不论是对程序性能还是网络资源的占用,都显得不太合理。
- 随着前端能力的快速发展,需要模块化的静态资源不仅仅是JS,Html、Css、Less等其他静态文件也同样需要被模块化。
所以,基于以上问题,一个基本的模块化打包工具应该具有如下能力(文章的最后会自己实现一个):
- 具备代码编译能力,能帮我们把浏览器不支持的高级语法降级,转化成大部分浏览器都能运行的低版本JS代码

-
在生产阶段能够将零散的模块再打包到一起,减少网络请求。

-
需要支持不同类型的前端模块,也就是说开发过程中涉及到的样式、图片、字体等都作为模块来使用,统一打包为浏览器能识别的JS、Css、Html文件。而且,所有的资源文件在开发阶段都可以JS脚本来控制,与业务代码统一维护。
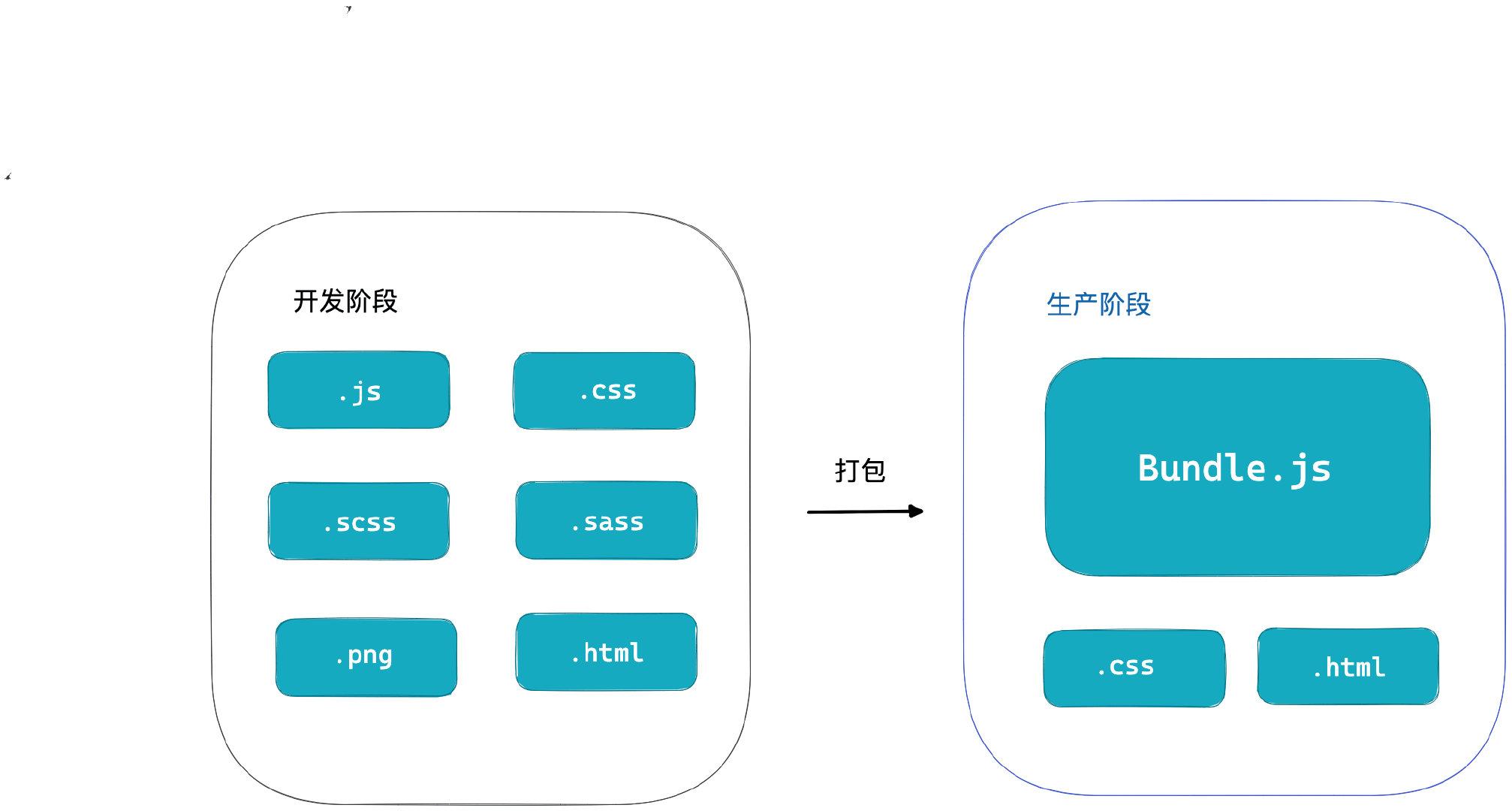
简单来说,Webpack就是为了实现前端的模块化而产生的。最主要解决的问题有三:1. 如何将零散的模块合并到一起。2. 对不同静态文件的处理。 3. 高级JS语法的浏览器兼容性问题。
Webpack中的核心概念
- 入口:entry
- 输入:output
- 加载器:loader
- 插件:plugin
- 模式: mode
- 浏览器兼容性:browser comptibility
- 环境: environment
Webpack的构建流程
面试常问问题:Webpack的工作流程是怎么样的?
- 初始化阶段:根据配置创建一个compiler对象,并且调用所有插件的apply方法。
- 构建阶段:从入口文件开始,调用相应的loader将模块转化为标准的JS内容,然后通过webpack内置的JavascriptParser解析成AST,得到「依赖关系图」
- 打包阶段(seal):根据模块之间的依赖关系,将Module组装成chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表(最后可以修改文件内容的阶段)
- 生成阶段(emit):把文件内容写入到文件系统
构建主要流程
Webpack的运行流程是一个串行的过程,从启动到结束会依次执行以下流程:
- 初始化参数:从配置文件和 Shell 语句中读取与合并参数,得到最终的参数。
- 开始编译:用上一步得到的参数初始化
Compiler对象,加载所有配置了的插件。执行Compiler对象的run方法开始执行编译。 - 确定入口:根据配置文件中的
entry找出所有的入口文件。 - 编译模块:从入口文件出发,调用对应配置的
Loader模块对不同类型的模块进行翻译,再找出该模块的依赖的模块,递归本步骤直到所有入口依赖的文件都经过了本步骤的处理。 - 完成模块编译:在经过第4步使用
Loader翻译完所有模块后,得到了每个模块被翻译后的最终内容以及各个模块之间的依赖关系图。 - 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的
Chunk,再把每个Chunk转化成一个单独的文件加入到输出列表,这也是可以修改输出内容的最后机会。 - 输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到计算机上的某个位置。
在以上过程中,Webpack会在特定的时间点广播出特定的事件,插件在监听到感兴趣的时间后会执行特定的逻辑,并且插件可以调用Webpack的API改变Webpack的运行结果。
从构建流程图看构建流程
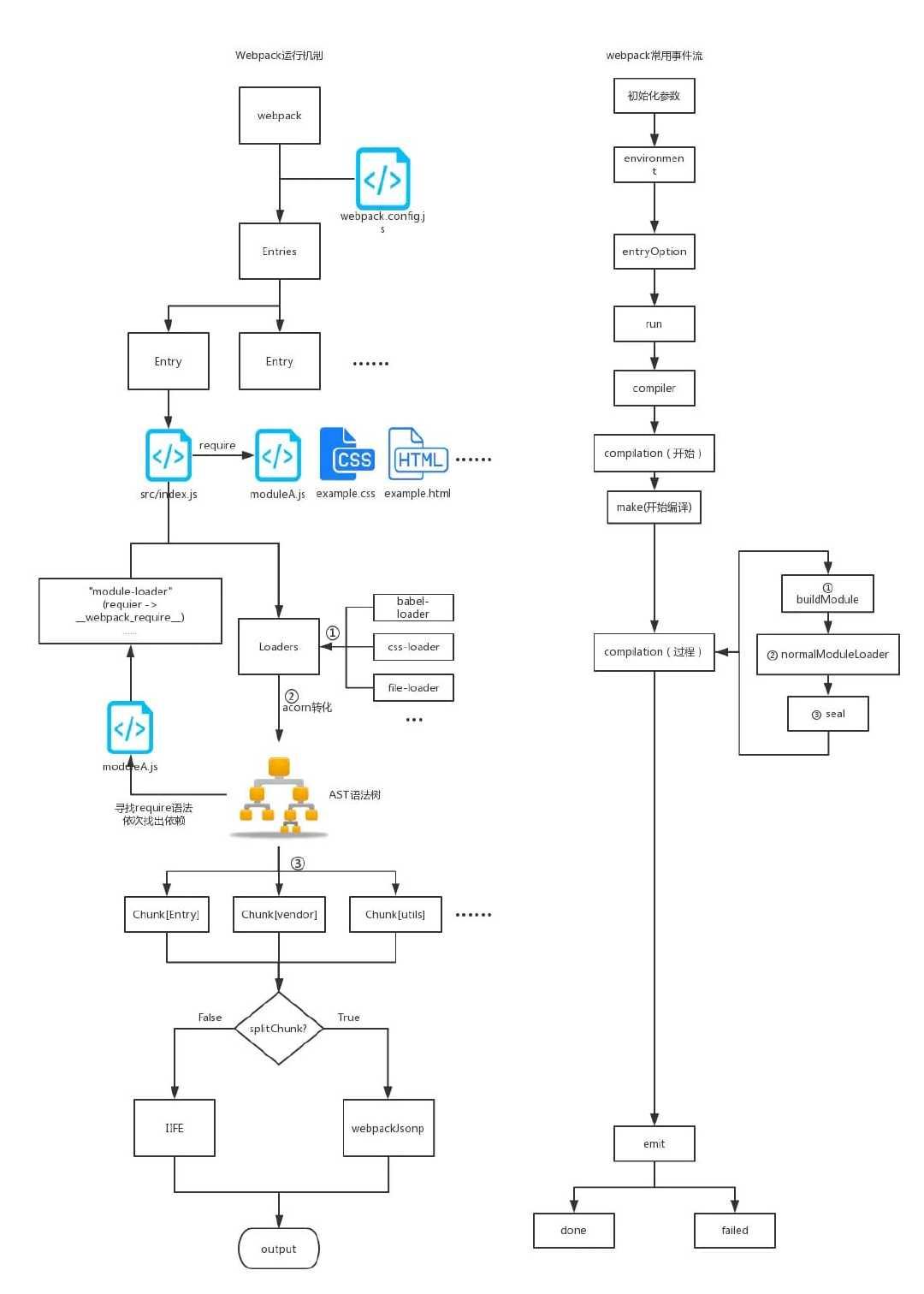
1.首先,Webpack会读取命令行中传入的配置以及你的
webpack.config.js文件,初始化本次构建的参数。并且执行配置文件中的插件实例化语句,生成Compiler对象传入plugin的apply方法(这就是为什么我们自定义插件一定要有一个apply方法)。2.接下来的
entryOption会读取Webpack配置文件中的Enties,遍历并递归入口文件。3.遍历递归完文件后,下面是
compilation过程。使用对应的Loader依次对每个入口文件内容进行编译(buildModule),我们可以从传入事件回调的compilation上拿到module的resource(资源路径)、loaders(经过的loaders)等信息。最后,再将编译好的文件内容使用acorn解析生成AST静态语法树。分析文件的依赖的模块递归上述过程。最后将所有模块中的require语法替换成__webpack_require__来模拟模块化操作。我们就得到了各个模块的内容和依赖关系图。4.emit阶段,所有文件的编译及转化都已经完成,包含了最终输出的资源,我们可以在传入事件回调的
compilation.assets上拿到所需数据,其中包括即将输出的资源、代码块Chunk等等信息。
Loader
概念
Loader直译为”加载器“。Webpack给自己的定位是静态模块打包工具。而前端项目中的各种资源(包括 CSS 文件、图片等)都应该属于需要被管理的模块。实际上 Webpack 本身只能够处理JS模块代码,而 Webpack 中的 Loader 才是 Webpack 能够加载不同种类资源模块的功臣。
Webpack中的Loader机制
假设我们目前没有配置任何的 Loader ,然后在项目中导入css文件。
└─ 01-es-modules
├── src
│ ├── index.js
│ └── css.js
└── index.html
body {
background-color: red;
}
import './index.css'
console.log('success');
运行 npx webpack

报错了,Webpack内部默认只能够处理js模块代码,而对于除了js之外的模块,我们需要额外的 Loader 帮助我们去处理(.css文件本身并没有模块化),于是我们自然就想到了css-loader。修改 webpack.config.js:
const path = require('path');
/*** @type { import('webpack').Configuration }*/
module.exports = {
mode: 'none',
entry: './src/index.js',
output: {
filename: 'bundle.js',
path: path.join(__dirname, 'dist')
},
module: {
rules: [
{
test: /\.css$/,
use: 'css-loader'
}
]
}
}
安装 css-loader 依赖后,重新运行打包 npx webpack, 成功!
开发一个Loader
思路:Loader本质上是对各种类型的模块内容进行转义,本质上就是将不同文件的内容读取出来(source),然后将源文件一步步翻译成想要的样子。
假设我们需要开发一个可以加载 markdown 文件的加载器,以便可以在代码中直接导入md文件。在此之前,我们借助一个能把md文件转化成 html 的包 --marked。
// ./markdown-loader.js
const marked = require('marked')
module.exports = source => {
console.log('source-----', source);
// 1. 将 markdown 转换为 html 字符串
const html = marked(source)
// html => '<h1>About</h1><p>this is a markdown file.</p>'
// 2. 将 html 字符串拼接为一段导出字符串的 JS 代码
const code = `module.exports = ${JSON.stringify(html)}`
console.log('code', code);
return code
// code => 'export default "<h1>About</h1><p>this is a markdown file.</p>"'
}
在 webpack.config.js 中使用自定义markdown-laoder。
// ...
rules: [
{
test: /\.md$/,
use: './markdown-loader.js'
}
]
在 markdown-laoder.js中,我们接收一个参数 source 包含了md文件中的内容。并且将 source 和经过 markdown-loader转化后的内容打印了出来。

一个简单的 Webpack Loader 就实现了。
Plugin
概念
Plugin直译为”插件“。插件可以拓展 Webpack 的功能,让 Webpack 具有更多的灵活性。在 Webpack 运行的生命周期中会广播出许多事件,Plugin 会监听这些事件,在合适的时机通过 Webpack 提供的API改变输出结果。
Webpack中的Plugin机制
- clean-webpack-plugin 插件可以自动在打包前清除指定目录
- html-webpack-plugin 自动生成应用所需的html文件,并引入入口文件
创建目录
05-webpack-plugin
├── src
│ ├── index.html
│ └── main.js
└── index.html
在 Webpack 的配置文件中声明构建过程中用到的插件
// ./webpack.config.js
const path = require('path');
const { CleanWebpackPlugin } = require('clean-webpack-plugin');
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
mode: 'none',
entry: './src/main.js',
output: {
filename: 'bundle.js',
path: path.join(__dirname, 'dist')
},
plugins: [
new CleanWebpackPlugin(),
new HtmlWebpackPlugin({
template: './src/index.html'
})
]
}
npx webpack
输出的目录结构
disk
├── bundle.js
└── index.html
index.html (我们可以看到自动引入了入口文件)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script src="bundle.js"></script></body>
<script></script>
</html>
开发一个Plugin
思路:在
Webpack构建的第一步,会执行配置文件中的插件实例化语句,并且将生成的compiler实例传到apply方法中。所以Webpack插件一定要有一个apply函数,apply函数接收compiler实例作为参数,并且监听构建过程中的某个事件,以达到改变Webpack构建结果的目的。
下面我们来开发一个清除每行开头注释的插件 --- remove-comments-plugin.js
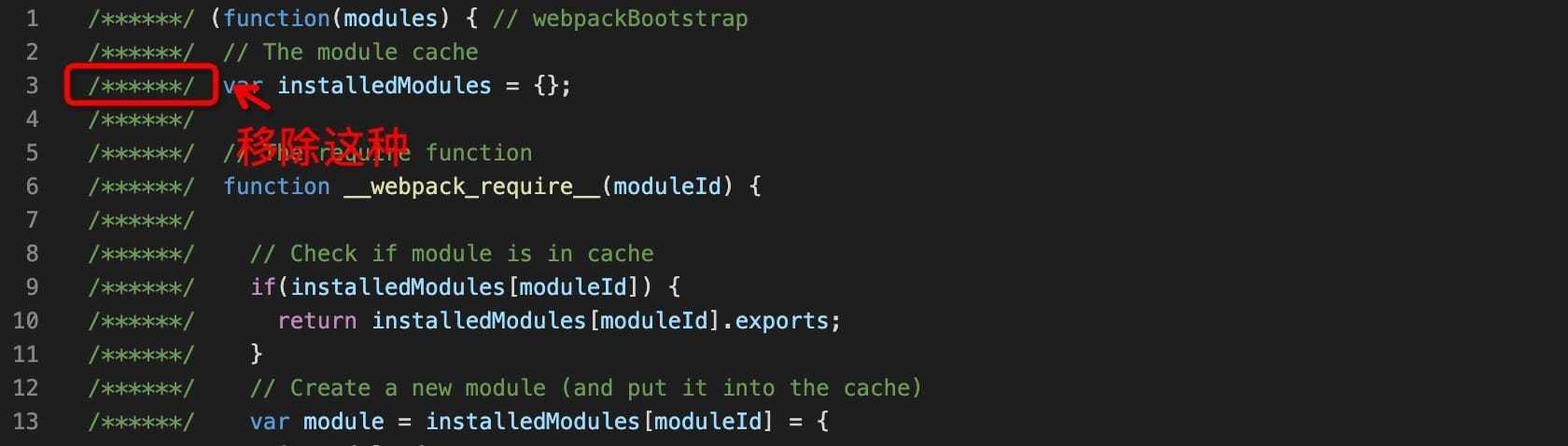
- 首先,按照 Webpack 的标准,一个插件一定要是一个 Class
- Class 中必须包含一个 apply函数
- 通过 compiler 对象监听 Webpack 构建过程中广播出来的某个特定事件(生命周期钩子函数)
- 通过 改变 compilation 中的 assets 达到改变 Webpack 构建结果的目的
// 第一步,创建一个类
class RemoveCommentsPlugin {
// 第二步,类中必须包含 apply 方法。 在webpack初始化的时候会统一实例化并调用。
apply(compiler) {
// 第三步 通过 compiler.hooks.? 拿到 webpack构建过程中广播出来的事件,并且
compiler.hooks.emit.tap("RemoveCommentsPlugin", (compilation) => {
// compilation => 包含了此次构建的所有文件的信息
for (const name in compilation.assets) {
if (name.endsWith('.js')) {
const contents = compilation.assets[name].source();
// 将所有 /*****/ 的注释替换成空字符串
const noComments = contents.replace(/\/\*{2,}\/\s?/g, '');
compilation.assets[name] = {
source: () => noComments,
size: () => noComments.length,
}
}
}
});
}
}
在 webpack.config.js中使用
const path = require('path');
const { CleanWebpackPlugin } = require('clean-webpack-plugin');
const HtmlWebpackPlugin = require('html-webpack-plugin');
// const CopyWebpackPlugin = require('copy-webpack-plugin');
const RemoveCommentsPlugin = require('./remove-comments-plugin.js');
module.exports = {
mode: 'none',
entry: './src/index.js',
output: {
filename: 'bundle.js',
path: path.join(__dirname, 'dist')
},
plugins: [
new CleanWebpackPlugin(),
new HtmlWebpackPlugin({
title: 'My App',
template: './src/index.html'
}),
new RemoveCommentsPlugin(),
]
}
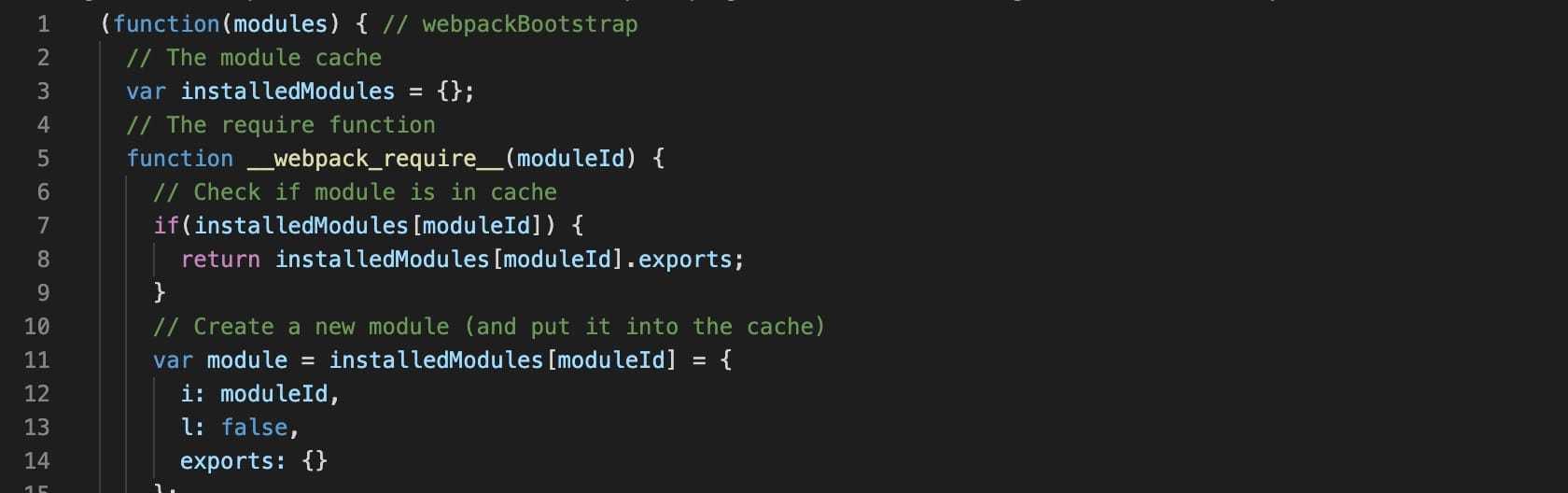
看看插件的效果!确实移除了。
Webpack与HMR
HMR出现的背景
在 HMR 出现之前,应用的加载、更新是一种页面级别的原子操作,即使只是单个代码文件发生变更都需要刷新整个页面才能最新代码映射到浏览器上,这会丢失之前在页面执行过的所有交互与状态,例如:
- 对于复杂表单场景,这意味着你可能需要重新填充非常多字段信息
- 弹框消失,你必须重新执行交互动作才会重新弹出
再小的改动,例如更新字体大小,改变备注信息都会需要整个页面重新加载执行,影响开发体验。引入 HMR 后,虽然无法覆盖所有场景,但大多数小改动都可以实时热更新到页面上,从而确保连续、顺畅的开发调试体验,对开发效率有较大增益效果。
什么是HMR
在使用Webpack Dev Server以后 可以让我们在开发工程中 专注于 Coding, 因为它可以监听代码的变化 从而实现打包更新,并且最后通过自动刷新的方式同步到浏览器,便于我们及时查看效果。 但是 Dev Server 从监听到打包再到通知浏览器整体刷新页面 就会导致一个让人困扰的问题 那就是 无法保存应用状态 因此 针对这个问题,Webpack 提供了一个新的解决方案 Hot Module Replacement。
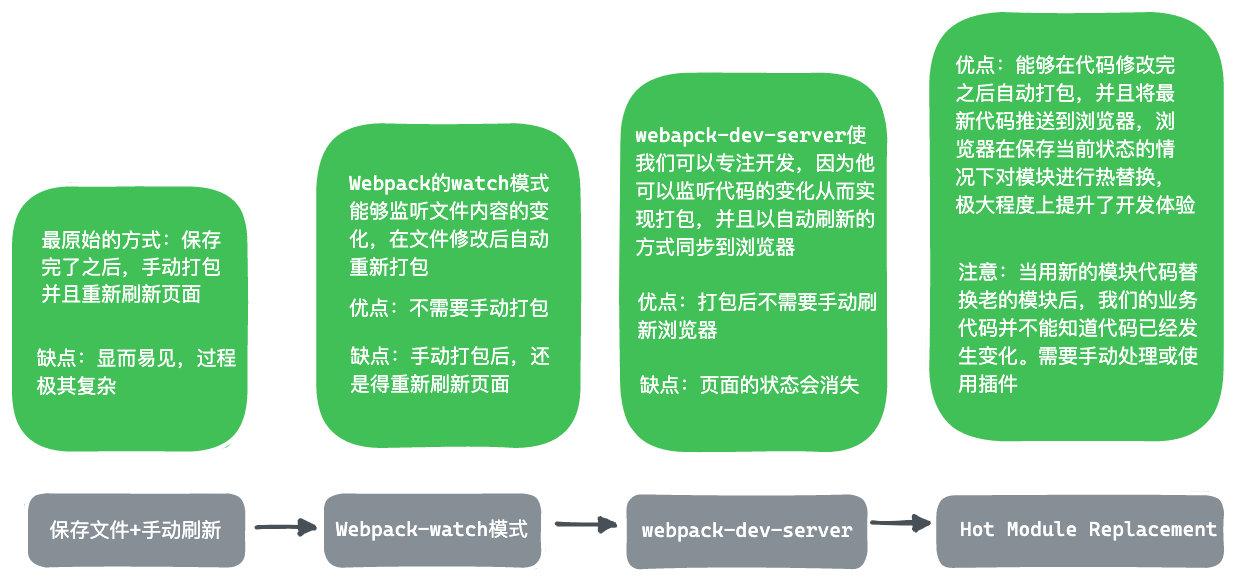
从刀耕火种到HMR经历了哪些过程
运行简单的 HMR 例子
- 配置
devServer.hot属性为 true,如:
// webpack.config.js
module.exports = {
// ...
devServer: {
// 必须设置 devServer.hot = true,启动 HMR 功能
hot: true
}
};
-
在页面的
Input框中输入一些文字,保证文件更改之前是有状态的 -
修改代码,加入一些文案,保存
-
可以看到,代码重新编译后,新的文案出现了。
Input框中用户输入的内容任然存在
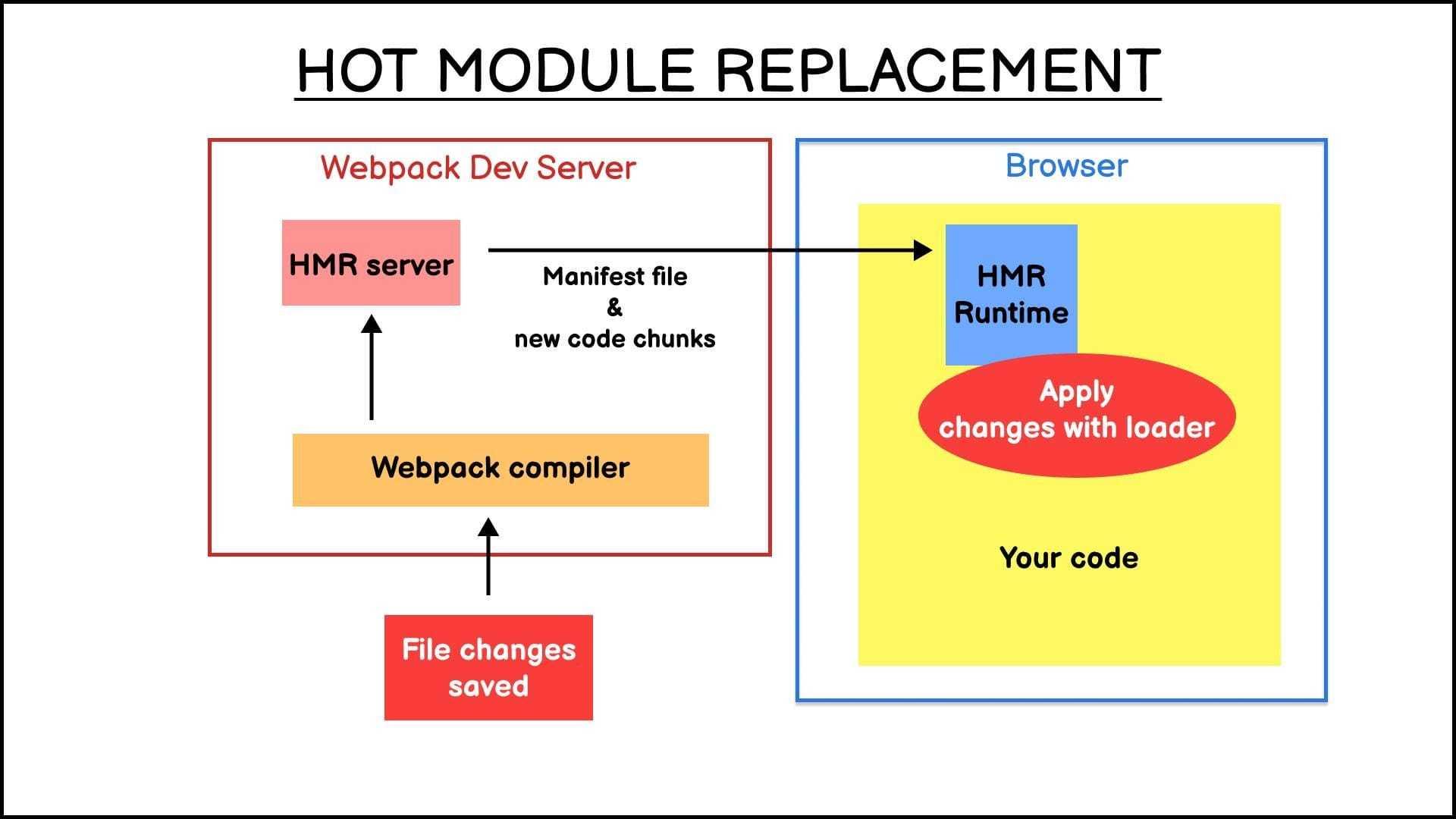
HMR的工作原理
面试常问问题:Webpack中的热更新怎么实现的?
- 首先,用webpack-dev-server来启动webpack的话,webpack-dev-server内部会启动webpack 的watch能力。并且HotModuleReplacementPlugin这个插件会往我们客户端的代码中注入热更新的 runtime代码
- 当webpack内置的watchpack模块监听到文件的改动后,就会调用compiler.compile方法重新编译
- 当webpack重新编译完成之后,会触发一个compiler.hooks.done事件。webpack-dev-server中会向客户端发送hash事件和一个ok事件
- 客户端监听到ok事件之后,会查看服务端的hot-update.json文件,确认修改范围
- 客户端拿到修改的返回之后,会加载新的资源。并且触发hot.module.accept()回调。对应的loader,或者react中的react-refresh注入的runtime会执行替换逻辑
Webpack HMR 特性的原理并不复杂,核心流程:
-
使用
webpack-dev-server托管静态资源,同时以Runtime的方式注入 HMR 客户端代码 -
浏览器加载页面后,与 WDS 简历 WebSocket 连接
-
Webpack 监听内部构建完成的事件,如果有文件内容发生改变,通过 WebSocket 发送
hash事件到客户端 -
浏览器端收到
hash事件后,请求mainfest资源文件,确认发生改变的文件名列表 -
浏览器重新发
AJAX加载发生变化的文件 -
Webpack 运行时触发变更模块的
module.hot.accept回调,执行代码替换逻辑module.hot.accept模块代码的替换逻辑可能非常复杂,幸运的是我们不太需要对此过多关注,社区很多 Webpack Loader 已经提供了很多针对不同资源的 HMR 功能,例如:style-loader内置 Css 模块热更新功能vue-loader内置 Vue 模块热更新功能react-hot-reload内置 React 模块热更新接口
SourceMap
SourceMap的概念
Source Map 是将编译、打包、压缩后的代码映射回源代码的过程。打包压缩后的代码不具备良好的可读性,想要调试源码就需要 Soucre Map。(map文件只要不打开开发者工具,浏览器是不会加载的)
Webpack 中配置SourceMap
其实source-map的模式有很多种,devtool可选的属性非常多
const path = require('path');
const webpack = require('webpack');
module.exports = {
mode: 'none',
entry: './src/index.js',
+ devtool: 'source-map', // source map 设置
output: {
filename: 'bundle.js',
path: path.join(__dirname, 'dist')
},
plugins: [],
}
线上环境处理方案
none: 为了安全,直接不用SouceMap文件hidden-source-map:借助第三方错误监控平台 Sentry 使用nosources-source-map:只会显示具体行数以及查看源代码的错误栈。安全性比 sourcemap 高sourcemap:通过 nginx 设置将 .map 文件只对白名单开放(公司内网)
Tree shaking
概念
Tree-Shaking 是一种基于 ES Module 规范的 Dead Code Elimination 技术,它会在运行过程中静态分析模块之间的导入导出,确定 ESM 模块中哪些导出值未曾其它模块使用,并将其删除,以此实现打包产物的优化。
Tree Shaking 较早前由 Rich Harris 在 Rollup 中率先实现,Webpack 自 2.0 版本开始接入,至今已经成为一种应用广泛的性能优化手段。
理论基础
在 CommonJs、AMD、CMD等旧版本的 JavaScript 模块化方案中,导入导出的行为是高度动态的,难以预测,例如:
if(process.env.NODE_ENV === 'development'){
require('./bar');
exports.foo = 'foo';
}
而 ESM 方案从规范层面规避这一行为,它要求所有的导入导出语句只能出现在模块顶层,且导入导出的模块名必须为字符串常量。所以 ESM 规范下,模块之间的依赖关系是高度确定的,与运行状态无关,编译工具只需要对 ESM 模块做静态分析,就可以从代码字面量中推断出哪些模块值未曾被其他模块使用,这是实现 Tree Shaking 的必要条件。
示例
// index.js
import { ModuleA, ModuleB } from './bar';
console.log(ModuleB);
// a.js
export const ModuleA = 'ModuleA';
export const ModuleB = 'ModuleB';
示例中,a 模块导出了 ModuleA 、ModuleB ,但只有 ModuleB 导出值被其它模块使用,经过 Tree Shaking 处理后,ModuleA 变量会被视作无用代码删除。
实现原理
Webpack 中, Tree-shaking 的实现首先是标记出模块导出值中那些没有被用过。二是使用 Terser 删掉这些没被用到的导出语句。标记过程大致可划分为三个步骤:
- Make阶段,收集模块导出变量并记录到模块依赖关系图 ModuleGraph 变量中
- Seal阶段,遍历 ModuleGraph 标记模块导出变量有没有被使用
- 生成产物时,若变量没有被其他模块使用,则删除对应的导出语句
标记功能需要配置
optimization.usedExports = true开启
Scope Hoisting
概念
Scope Hoisting 是 Webpack3 的新功能,直译过来就是作用域提升。由于构建后的代码会存在大量闭包,造成体积增大,运行代码时创建的函数作用域变多,内存开销变大。Scope hoisting 将所有模块的代码按照引用顺序放在一个函数作用域里,然后适当的重命名一些变量以防止变量名冲突。它可以让 webpack 打包出来的代码文件更小,运行更快。
举个例子
首先回顾下在没有 Scope Hoisting 时用 webpack 打包下面两个文件:
// main.js
export default "hello leo~";
// index.js
import str from "./main.js";
console.log(str);
使用 webpack 打包后输出文件内容如下:
[
function (module, __webpack_exports__, __webpack_require__) {
var __WEBPACK_IMPORTED_MODULE_0__main_js__ = __webpack_require__(1);
console.log(__WEBPACK_IMPORTED_MODULE_0__main_js__["a"]);
},
function (module, __webpack_exports__, __webpack_require__) {
__webpack_exports__["a"] = "hello leo~";
},
];
再开启 Scope Hoisting 后,相同源码打包输出结果变为:
[
(function (module, __webpack_exports__, __webpack_require__) {
var main = ('hello leo~');
console.log(main);
})
]
对比两种打包方式输出的代码,我们可以看出,启用 Scope Hoisting 后,函数声明变成一个, main.js 中定义的内容被直接注入到 main.js 对应模块中,这样做的好处:
- 代码体积更小:因为函数申明语句会产生大量代码,导致包体积增大(模块越多越明显);
- 内存开销也随之变小:代码在运行时因为创建的函数作用域更少。
如何使用
- 自动启用:在 webpack 的
mode设置为production时,会默认自动启用Scope Hoisting 。 - 手动启用:在 webpack 中已经内置 Scope Hoisting ,所以用起来很简单,只需要配置
ModuleConcatenationPlugin插件即可(或者在optimization中设置concatenateModules为true)。
考虑到 Scope Hoisting 以来 ES6 模块化语法,而现在很多 npm 包的第三方库还是使用 CommonJS 语法,为了充分发挥 Scope Hoisting 效果,我们可以增加以下
mainFields配置:
// webpack.config.js
// ...
const webpack = require('webpack');
module.exports = {
// ...
resolve: {
// 针对 npm 中的第三方模块优先采用 jsnext:main 中指向的 ES6 模块化语法的文件
mainFields: ['jsnext:main', 'browser', 'main']
},
plugins: [
new webpack.optimize.ModuleConcatenationPlugin()
]
};
Scope Hoisting 原理
Scope Hoisting 的实现原理其实很简单:分析出模块之间的依赖关系,尽可能将打散的模块合并到一个函数中,前提是不能造成代码冗余。 因此只有那些被引用了一次的模块才能被合并。
由于 Scope Hoisting 需要分析出模块之间的依赖关系,因此源码必须采用 ES6 模块化语句,不然它将无法生效。。
Chunk 分包规则( Code Spliting)
背景
在 Webpack 的实现中,原始的资源模块以Module对象的形式存在、流转、解析处理。而Chunk则是输出产物的基本单位。在生成阶段 Webpack 按规则将 entry以及其他Module插入Chunk中,之后再由SplitChunksPlugin插件根据优化规则与ChunkGraph对Chunk做一系列的变化、拆解、合并操作,重新组织成一批性能更高的Chunks。
最终 Webpack 将这一些列的
Chunks输出到文件系统,完成编译工作。
默认的分包规则
- Entry分包处理:在生成阶段,Webpack 首先根据遍历用户提供的 entry 属性值,为每一个 entry 创建 Chunk 对象。
- 异步模块分包处理:分析
ModuleDependencyGraph时,每次遇到异步模块都会为之创建单独的 Chunk 对象,单独打包异步模块。 - Runtime 分包:Webpack 5 之后还能根据
entry.runtime配置单独打包运行时代码。
默认分包规则存在的问题
- 重复模块多次打包:默认分包规则最大的问题是无法解决模块重复,如果多个 Chunk 同时包含同一个
module,那么这个module会被不受限制地重复打包进这些 Chunk。 - 资源冗余:如果项目体积无限膨胀,导致首次加载时间过长。
- 缓存失效:如果所有的文件都打包进一个 Chunk,只要发生一点小小的改动,那么原来的文件就会发生改变,所有模块的缓存都失效了。
SplitChunksPlugin 分包策略
SplitChunksPlugin是 Webpack 4之后引入的分包方案(Webpack 3为 CommonsCHunkPlugin),它能够基于一些启发式的规则将 Module 编排进不同的 Chunk 序列,并最终将应用代码分门别类打包出多份产物,从而实现分包功能。
- 根据 Module 使用频率分包:
SplitChunksPlugin支持按 Module 被 Chunk 引用的次数决定是否进行分包。开发者可以通过optization.splitChunks.miniChunks设定最小引用次数,例如
module.exports = {
//...
optimization: {
splitChunks: {
// 设定引用次数超过 3 的模块才进行分包
minChunks: 3
},
},
}
注意!这里的”Chunk 被引用次数“并不直接等价于
import的次数,而是取决于上有调用者是否被视作 Initial Chunk 或 Async Chunk 处理
-
限制分包体积:在满足了 Module 使用频率的规则后。SplitChunksPlugin 还会进一步判断 Chunk 包的大小来决定要不要分包,这一规则相关的配置项非常多:
-
miniSize:生成 chunk 的最小体积(以 bytes 为单位) -
maxSize:使用maxSize告诉 webpack 尝试将大于maxSize个字节的 chunk 分割成较小的部分。 这些较小的部分在体积上至少为minSize设置
maxSize的值会同时设置maxAsyncSize和maxInitialSize的值。 -
maxAsyncSize:与maxSize功能类似,但只对异步引入的模块生效 -
maxInitialSize:与maxSize类似,但只对entry配置的入口模块生效 -
enforceSizeThreshold:超过这个尺寸的 Chunk 会被强制分包,忽略上述其它 size 限制
-
-
限制分包数量:在满足 minChunks 基础上,还可以通过
maxInitialRequest/maxAsyncRequests配置项限定分包数量,配置项语义:-
maxInitialRequest:用于设置 Initial Chunk 最大并行请求数 -
maxAsyncRequests:用于设置 Async Chunk 最大并行请求数这里说的”请求数“,是指加载一个 Chunk 时所需同步加载的分包数。例如一个 Chunk A,如果根据分包规则(如模块引用次数、第三方包)分离出了若干子 Chunk,那么请求A时并行的请求书等于:子 Chunk 数 + 1。
-
注意,这些属性的优先级顺序为: maxInitialRequest/maxAsyncRequests < maxSize < minSize
-
**cacheGroups **:除了
minChunks、minSize、maxInitialRequest等基础规则外,SplitChunksPlugin还提供了cacheGroups配置项用于为不同文件组设置不同的规则,例如:module.exports = { //... optimization: { splitChunks: { cacheGroups: { vendors: { test: /[\\/]node_modules[\\/]/, minChunks: 1, minSize: 0 } }, }, }, };示例通过
cacheGroups属性设置vendors缓存组(实际上就是生成一个vendor~main.xxxxxx.js),所有命中vendors.test规则的模块都会被视作vendors分组,优先应用该组下的minChunks、minSize等分包配置。除了
minChunks等分包基础配置项之外,cacheGroups还支持一些与分组逻辑强相关的属性,包括:test: ((...args: any[]) => boolean) | string | RegExp:所有符合test判断的 Module 或 Chunk 都会被分到该组enforce?: boolean: 忽略 minChunks、minimum chunks等配置,强行把匹配到的 Chunks 打到当前匹配到的cacheGroups中idHint:string:用于设置 Chunk ID,它还会被追加到最终产物文件名中,例如idHint = 'vendors'时,输出产物文件名形如vendors-xxx-xxx.jspriority:number:用于设置该分组的优先级,若模块命中多个缓存组,则优先被分到priority更大的组。
Webpack层面 如何做性能优化
构建速度
- 更新到最新版本:使用高版本的 Webpack 和 Node
- 指定Loader处理的范围:通过
include字段,仅将 Loader 应用在实际需要将其转化的模块 - 多进程/多实例构建:HappyPack(不维护了)、thread-loader
- 代码压缩速度:在使用压缩工具的时候开启多进程
- webpack-paralle-uglify-plugin
- uglifyjs-webpack-plugin 开启 parallel 参数
- terser-webpack-plugin 开启 parallel 参数
- 通过 mini-css-extract-plugin 提取 Chunk 中的 CSS 代码到单独文件,通过 css-loader 的 minimize 选项开启 cssnano 压缩 CSS
- DLL:使用DLLPlugin将不太会改动的代码先打包成静态资源,避免反复编译浪费时间
- 充分利用缓存提升二次构建速度:
- bable-loader开启缓存
- Terser-webpack-plugin开启缓存
- 使用 cache-loader 或者 hard-source-webpack-plugin
- Scope Hoisting:构建后的代码会存在大量闭包,造成体积增大,运行代码时创建的函数作用域变多,内存开销变大。Scope hoisting 将所有模块的代码按照引用顺序放在一个函数作用域里,然后适当的重命名一些变量以防止变量名冲突,以达到代码文件更小,运行速度更快的
- 提取页面公共资源:使用 html-webpack-externals-plugin,将基础包通过 CDN 引入,不打入 bundle 中
打包体积
- Tree Shaking:使用 Tree Shaking “摇”掉无用代码
- terser-webpack-plugin: 使用 terser 对代码进行压缩(生产环境下默认开启)
- splitChunksPlugin:使用该插件提取公共模块
- optimize-css-assets-webpack-plugin:使用该插件来压缩css文件
- compression-webpack-plugin:该插件可以将文件压缩成gzip的格式
Webpack 使用分析工具
收集统计信息
Webpack 运行过程会收集各种统计信息,只需要在启动时附加 --json 参数即可获得:
npx webpack --json > stats.json
Webpack Bundle Analyzer
webpack-bundle-analyzer 是一个 webpack 插件,只需要简单的配置就可以在 webpack 运行结束后获得 treemap 形态的模块分布统计图,用户可以仔细对比 treemap 内容推断是否包含重复模块、不必要的模块等场景

SpeedMeasurePlugin
加入 SpeedMeasurePlugin 插件可以对各个阶段的时间进行分析,查看各个Plugins/Loaders在构建过程中耗费的时间
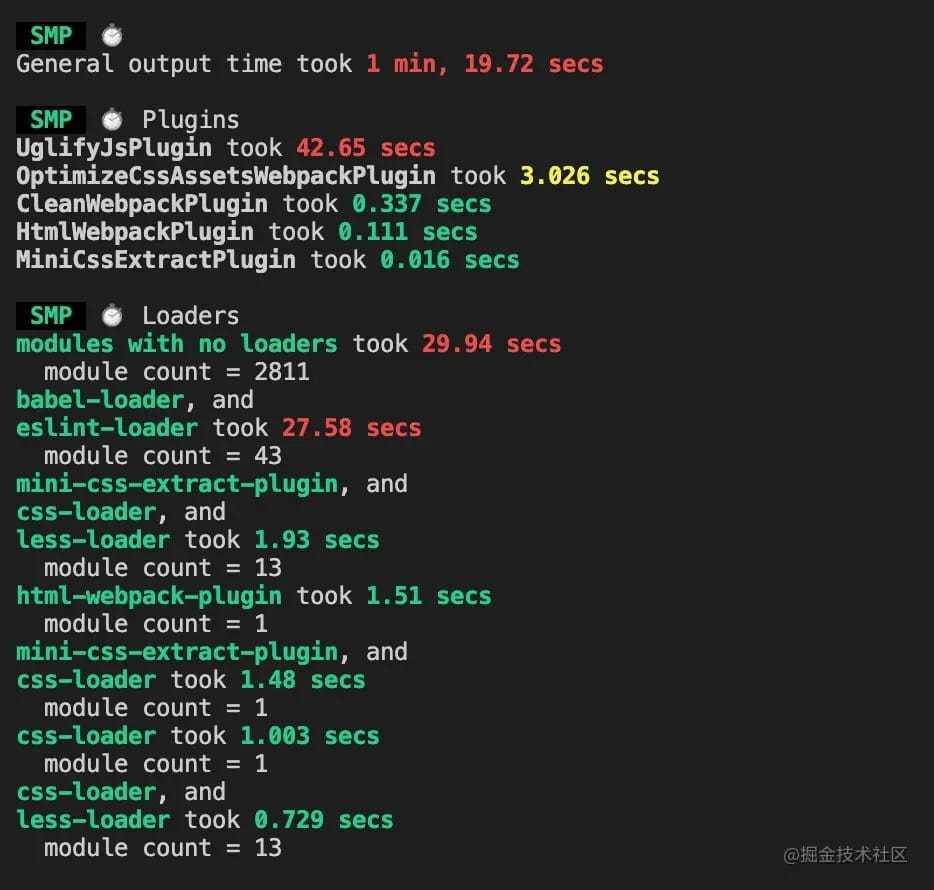
Webpack Dashboard
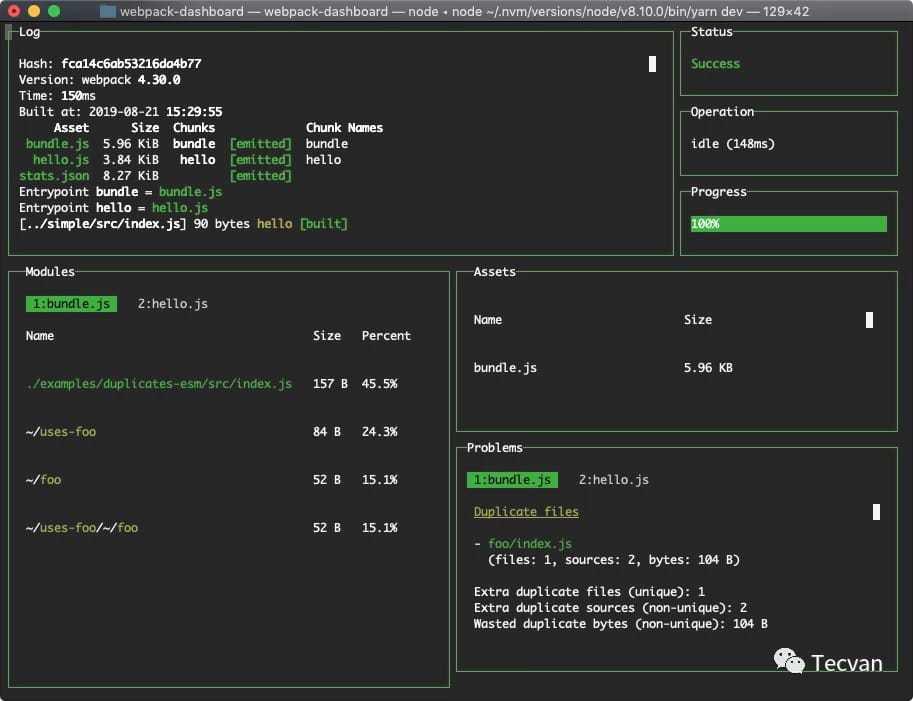
webpack-dashboard 是一个命令行可视化工具,能够在编译过程中实时展示编译进度、模块分布、产物信息等,与 webpack-bundle-size-analyzer 类似,它也只需要一些简单的改造就能运行。
const DashboardPlugin = require("webpack-dashboard/plugin");
module.exports = {
// ...
plugins: [new DashboardPlugin()],
};
// package.json
"scripts": {
"dev": "webpack-dashboard -- node index.js", # OR
"dev": "webpack-dashboard -- webpack-dev-server", # OR
"dev": "webpack-dashboard -- webpack",
}
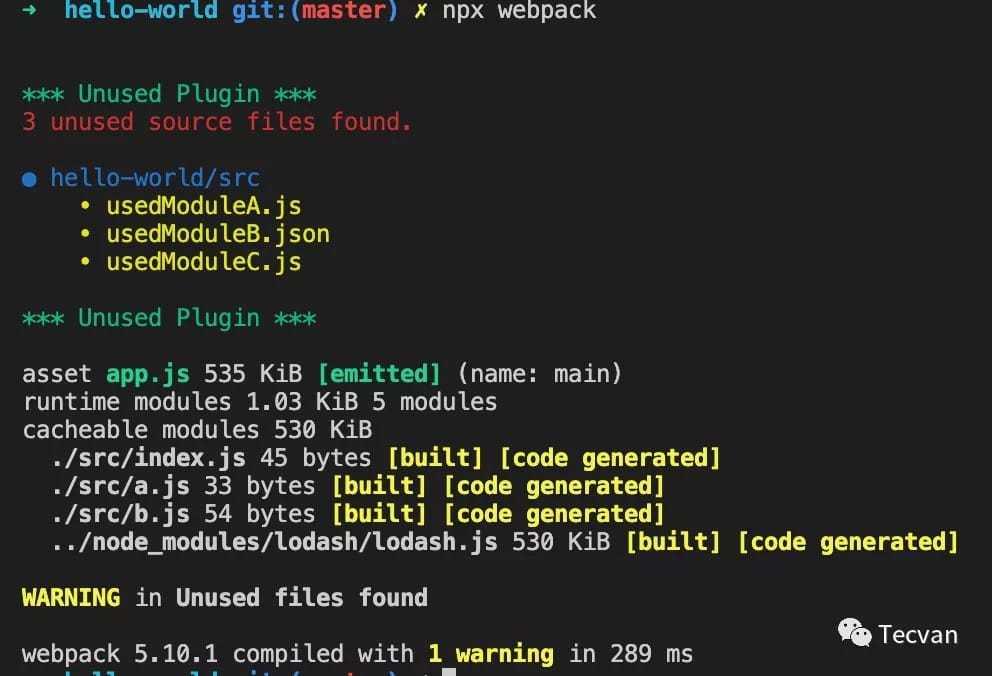
UnusedWebpackPlugin
最后分享 UnusedWebpackPlugin 插件,它能够根据 webpack 统计信息,反向查找出工程项目里那些文件没有被用到,我日常在各种项目重构工作中都会用到,非常实用。用法也比较简单:
const UnusedWebpackPlugin = require("unused-webpack-plugin");
module.exports = {
// ...
plugins: [
new UnusedWebpackPlugin({
directories: [path.join(__dirname, "src")],
root: path.join(__dirname, "../"),
}),
],
};
示例中,directories 用于指定需要分析的文件目录;root 用于指定根路径,与输出有关。配置插件后,webpack 每次运行完毕都会输出 directories 目录中,有那些文件没有被用到:
Webpack 5新特性
构建时的新特性
-
内置静态资源构建能力 —— Asset Modules
在Webpack 5之前,我们一般会使用以下几个loader来处理一些常见的静态资源,比如 PNG图片、SVG图标等等。而Webpack 5提供了内置的静态资源构建能力,我们不需要安装额外的loader,仅需要简单的配置就能实现静态资源的打包和分目录存放。
-
内置 FileSystem Cache 能力加速二次构建
在Webpack 5之前,我们会使用
bable-loader缓存一些性能开销较大的loader,或者是使用hard-source-webpack-plugin对模块提供一些中间缓存。在Webpack 5之后,默认就为我们继承了一种自带的缓存能力(对 module 和 chunks 进行缓存)。可在二次构建时提速 -
内置 WebAssembly 编辑及异步加载能力
WebAssembly 被设计为一种面向 web 的二进制的格式文件,以其更接近于机器码而拥有着更小的文件体积和更快速的执行效率。c/c++ 等高级语言都能直接编译成
.wasm文件而被 js 调用。Webpack4 本身就已经集成了 WebAssembly 的加载能力,只不过在 Webpack5 拓展了 WebAssembly 的异步加载能力,使得我们可以更灵活地借助 WebAssembly 做更多有意思的事情。 -
内置 Web Worker 构建能力
Web Worker 为 Web 内容在后台线程中运行提供了一种简单的方法。线程可以执行任务而不干扰用户界面。通常,我们可以将一些加密或者图片处理等一些比较复杂的算法置于子线程中,当子线程执行完毕之后,再向主线程通信。
运行时的新特性
-
移除了 Node.js Polyfill,Ployfill交由开发者自由控制
由于移除了 Node Polyfill,如果前端包里使用了 process、path这些依赖,需要手动添加 Polyfill支持。
-
资源打包策略更优,构建产物更“轻量”
PrePack 是 Facebook 开源的一个 JavaScript 代码优化工具,运行在“编译”阶段,生成优化后的代码。
Webpack 5内置了 PrePack 的部分能力,能够在极之上,再度优化你的项目产物体积。
-
深度 Tree Shaking 能力支持
Webpack 5有了更深度的Tree Shaking,举个例子:
// inner.js export const a = 1; export const b = 2; // module.js import * as inner from "./inner"; export { inner } // user.js import * as module from "./module"; console.log(module.inner.a);在本例中,可以在生产模式下删除导出文件b。
-
更友好的Long Term Cache 支持性,chunkId不变
Webpack5 之前,文件打包后的名称是通过 ID 顺序排列的,一旦后续有一个文件进行了改动,那么必将造成后面的文件打包出来的文件名产生变化,即使文件内容没有产生改变。因此会造成资源的缓存失效。
Webpack5 有着更友好的长期缓存能力支持,其通过 hash 生成算法,为打包后的 modules 和 chunks 计算出一个短的数字 ID ,这样即使中间删除了某一个文件,也不会造成大量的文件缓存失效。
-
支持 Top Level Await,从此告别 async
Webpack5 还支持 Top Level Await。即允许开发者在 async 函数外部使用 await 字段。它就像巨大的 async 函数,原因是 import 它们的模块会等待它们开始执行它的代码,因此,这种省略 async 的方式只有在顶层才能使用。
面试常问问题整理
Webpack的loader和Plugin有什么区别?
面试常问问题:Webpack的loader和Plugin有什么区别?
Loader本质上就是一个函数,在该函数中对接受到的内容进行转化,并返回转化后的结果。因为Webpack本身只能认识JavaScript文件,所以Loader就成了翻译官,对其他类型的资源文件进行转移。
而Plugin就是插件,他是一个class类包含一个
apply函数,基于事件流框架Tapable。插件可以拓展Webpack的能力,在Webpack运行的生命周期中会暴露出许多之间,Plugin可以监听这些事件,在合适的时机通过Webpack提供的API改变输出结果。
Webpack在plugin中怎么取到上下文信息?
面试常问问题:Webpack在plugin中怎么取到上下文信息?
在Webapck内部有一个Tapable的库,他暴露了很多的hooks,这个hooks在触发的时候,会把compiler以及一些上下文信息带到回调函数中,我们的plugin中就可以在回调函数中拿到对应的上下文信息,对构建流程产生一些副作用。
Webpack中的依赖图的收集是怎么实现的?
面试常问问题:Webpack中的依赖图的收集是怎么实现的?
基于AST和ES6的语法规范,当我们把文件解析成AST之后,通过import这个关键字就能识别出这个文件里面依赖了哪些文件,然后去找文件的文件,这样递归去找,最终生成了依赖图。
Webapck中对静态资源的体积是怎么做优化的?分包策略是怎么样的?
面试常问问题:Webapck中对静态资源的体积是怎么做优化的?分包策略是怎么样的?
对于静态资源的体积,可以通过Tree Sharking去除一些无用的代码,然后使用Terser对一些无用代码进行删除,上传到服务器之前还会压缩成gzip的格式。 对于分包策略,我们内部有关于http1.1和http2.0的两种策略,如果是http1.1的话我们会考虑控制一下包的数量,如果是http2.0的话我们会尽可能把三方包单独打成一个静态资源的文件,因为http2.0协议实现了多路复用,可以不考虑单域名下的请求限制。
Webpack中去Dead Code是怎么实现的?
面试常问问题:Webpack中去Dead Code是怎么实现的?
在Webpack中,去除Dead Code主要通过Tree-Shaking技术实现。首先,确保代码采用ES Module规范,配置中开启
optimization.usedExports标记功能。在打包过程中,Webpack通过静态分析模块之间的依赖关系,标记哪些导出值被使用,哪些未被使用。最后,在生成代码时,根据标记结果,删除未使用的导出语句。
