这是我参与2022首次更文挑战的第11天,活动详情查看:2022首次更文挑战
本系列更多文章可以看这里:草履虫都能看懂的 白话解析《动手学深度学习》专栏(juejin.cn)
还在更新中…………
在上一节里边,我们已经说到了如何使用门控单元对某些无关内容的忽略。也提到了其实首先是出现了LSTM,后来才出现了GRU,但是因为GRU更简单。所以现在很多都会先讲GRU。上一节已经讲完了GRU那这一节就来讲一讲LSTM。
温馨提示,本节内容会结合GRU进行讲解,所以请务必熟读上一篇的内容。动手学深度学习9.1 GRU - 掘金 (juejin.cn)
Long Short-Term Memory | MIT Press Journals & Magazine | IEEE Xplore
长短期存储器(long short-term memory, LSTM) 它有许多与门控循环单元一样的属性.
但是长短期记忆网络的设计比门控循环单元稍微复杂一些,并且它的诞生比GRU早了二十来年。
因为难易程度的问题,现在很多课程的讲课顺序都是先说GRU再说LSTM。
1 输入门、忘记门、输出门
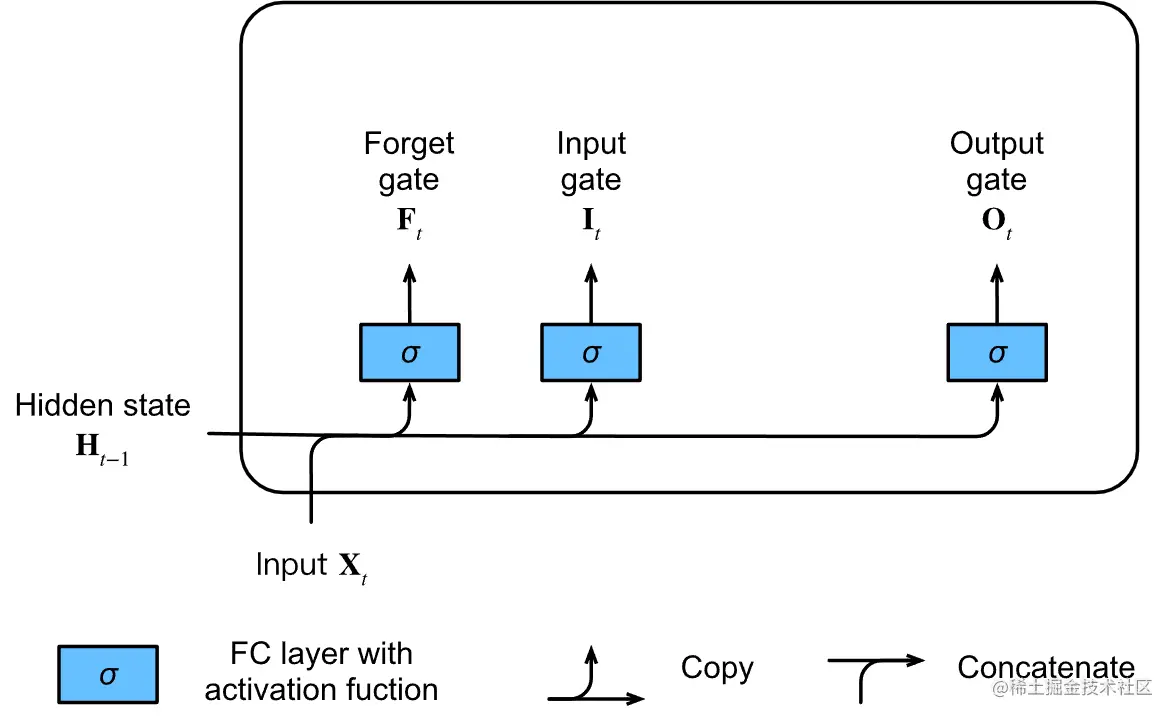
和GRU不同,GRU有两个门,LSTM有三个门,它分别是输入门It、忘记门Ft和输出门Ot。
假设有 h 个隐藏单元,批量大小为 n,输入数为 d。
公式如下:
It=σ(XtWxi+Ht−1Whi+bi),Ft=σ(XtWxf+Ht−1Whf+bf),Ot=σ(XtWxo+Ht−1Who+bo),
- 其中输入 Xt∈Rn×d
- 前一时间步的隐藏状态为 Ht−1∈Rn×h。
- t时间步时, 输入门It∈Rn×h,遗忘门Ft∈Rn×h,输出门Ot∈Rn×h。
- Wxi,Wxf,Wxo∈Rd×h 和 Whi,Whf,Who∈Rh×h 是权重参数
- bi,bf,bo∈R1×h 是偏置参数。
- 激活函数依旧使用sigmoid
当然也可以合并起来写:
It=σ([Xt,Ht−1]Wi+bi),Ft=σ([Xt,Ht−1]Wf+bf),Ot=σ([Xt,Ht−1]Wo+bo),
再次强调,不懂这里为什么能合并的建议回去补RNN的知识。
2 候选记忆单元
长短期记忆网络引入了存储记忆单元(memory cell),或简称为单元(cell)。有些文献认为存储单元是隐藏状态的一种特殊类型。嗯。
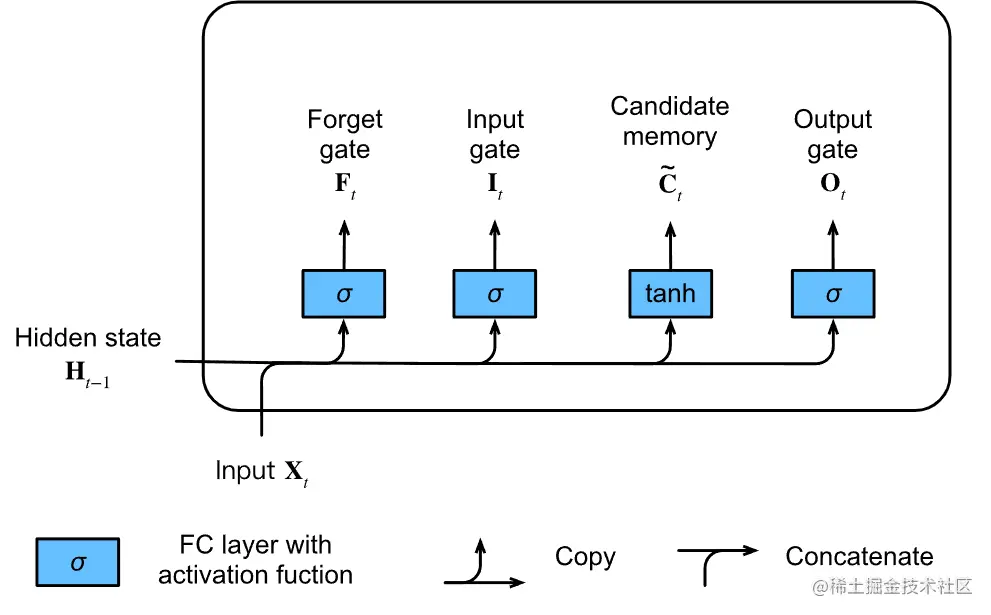
然后是候选记忆单元C~t 的计算。LSTM中候选记忆单元是直接进行计算的。这一点和GRU不太相同。GRU这一步是结合遗忘门来进行候选隐藏状态的计算。
候选记忆单元就是将本步的输入和上一步的隐状态进行计算。
候选记忆单元公式如下:
C~t=tanh(XtWxc+Ht−1Whc+bc)
- Wxc∈Rd×h 和 Whc∈Rh×h 是权重参数。
- bc∈R1×h 是偏置参数。
- 候选记忆单元使用的激活函数是tanh。
3 记忆单元
先来回顾一下在GRU当中,我们使用重置门来决定是否忽略上一步的隐藏状态。使用更新门来计算新的隐藏状态。而更新门的作用是决定使用多少本步的候选隐藏状态和上一步的隐藏状态。
类似地,在长短期记忆网络中,也有两个门用于这样的目的:输入门 It 控制采用多少来自 C~t 的新数据,而遗忘门 Ft 控制保留了多少旧记忆单元 Ct−1∈Rn×h 的内容。最后计算结果存储在记忆单元Ct 中。
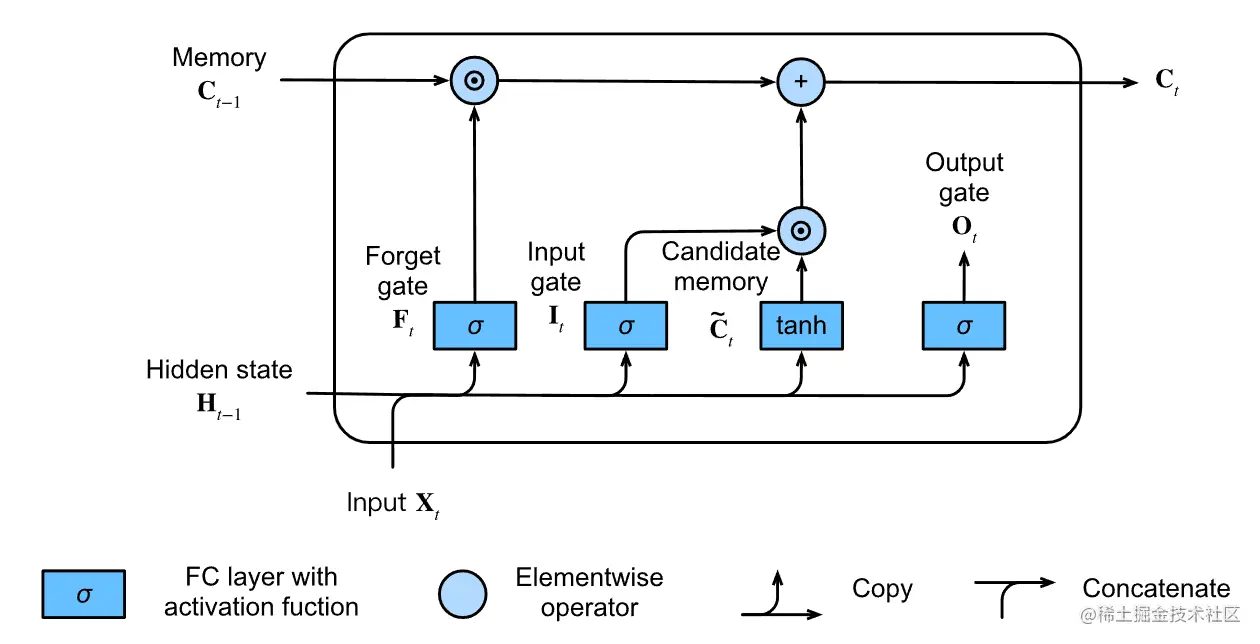
公式如下:
Ct=Ft⊙Ct−1+It⊙C~t
因为输入门、忘记门他们都使用的sigmoid作为激活函数。因此它们两个的值都是趋近于0或者近于1的。
- 如果遗忘门为 1 且输入门为 0,则过去的记忆单元 Ct−1 将随时间被保存并传递到当前时间步。
- 如果遗忘门为 0 且输入门为 1,则过去的记忆单元 Ct−1 被丢弃掉,仅使用当前的候选记忆单元C~t。
引入这种设计是为了缓解梯度消失问题,并更好地捕获序列中的长距离依赖关系。
4 隐藏单元
输入门遗忘门都介绍了,输出门的作用就在 隐藏单元Ht 计算这一步。
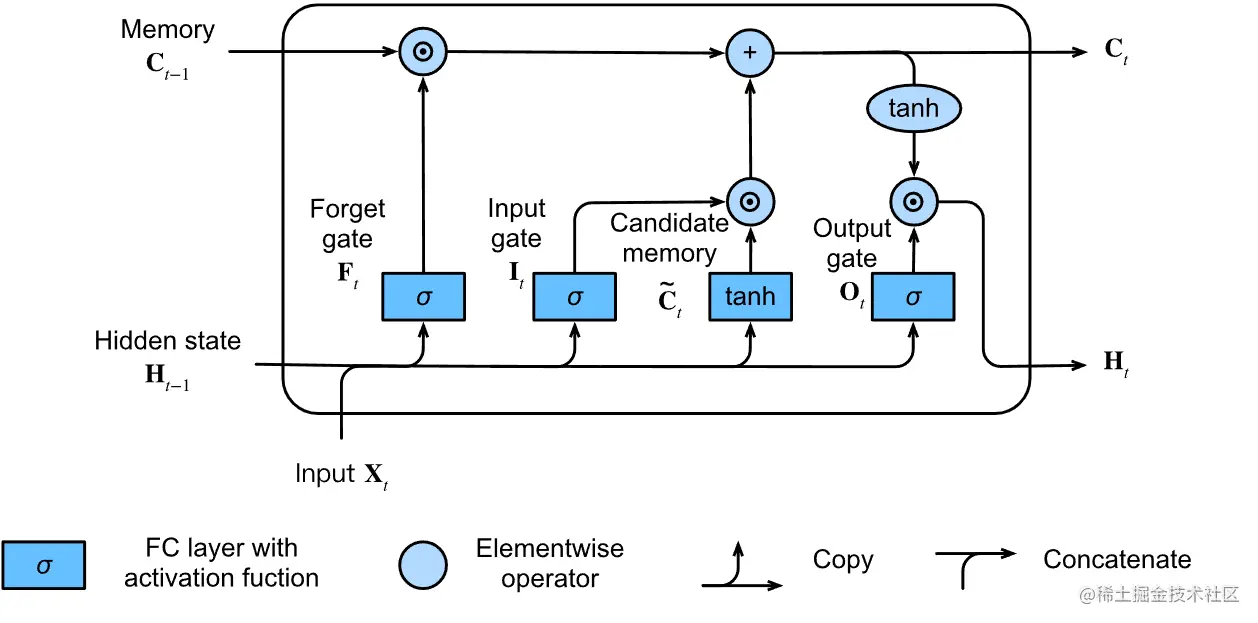
公式如下:
Ht=Ot⊙tanh(Ct)
- 输出门接近 1,我们就能够把我们的记忆单元信息传递下去。
- 输出门接近 0,我们只保留存储单元内的所有信息。


