这是我参与2022首次更文挑战的第10天,活动详情查看:2022首次更文挑战
更多可以看这里:草履虫都能看懂的 白话解析《动手学深度学习》专栏(juejin.cn)
还在更新中…………
循环神经网络中存在一个严重的问题就是会出现梯度爆炸或者梯度消失的现象。并且有的时候,在一段序列中有许多无关紧要的内容,如果都需要对其进行记忆,不仅浪费计算资源而且影响模型效果。因此我们希望有一些机制来 跳过 隐状态表示中的“无关”词元。
现在的解决办法有:
- 长-短期记忆 (long-short-term memory, LSMT)1,这个我们之后再讨论。
- 门控循环单元(gated recurrent unit, GRU)2 是一个稍微简化的变体,通常能够提供同等的效果,并且计算 3 的速度明显更快。
由于门控循环单元更简单,就让我们从门控循环单元开始。
相关的参考文献我已经放到了最后,点击右上角的那个角标可以直接跳转到最后的相关论文中。
门控神经网络单元相对于循环神经网络的计算来讲,就是多了一个控制选项。相较于RNN的不加差别的更新状态,GRU就是对状态进行选择性的更新:即可以选择更新,也可以选择重置。
重置门和更新门
回忆一下在循环神经网络中,上一层的隐状态和本层的输入会生成本层的隐状态;而在门控循环单元中,我们是生成一个重置门Rt 和一个更新门Zt。
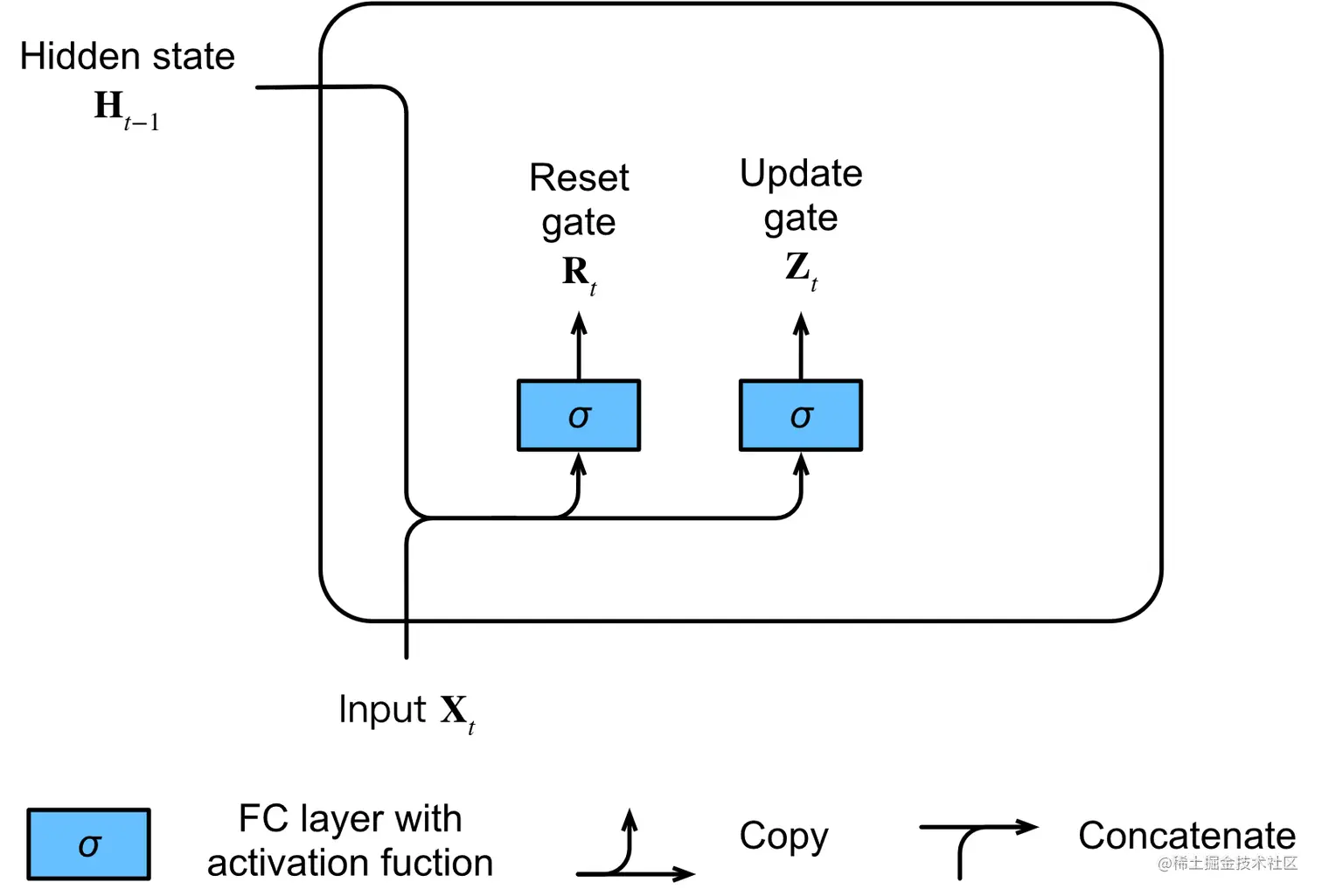
重置门:Rt=σ(XtWxr+Ht−1Whr+br),更新门:Zt=σ(XtWxz+Ht−1Whz+bz),
当然上边的式子我们可以写为化简的状态。
Rt=σ([Xt,Ht−1]Wr+br),Zt=σ([Xt,Ht−1]Wz+bz),
在这里我们使用的激活函数是sigmoid,它是将数据转换成0或1之间的值,更重要的是经过计算之后使结果趋向于0或1。
简化方法就是将上一时间步的隐状态和本步的输入进行拼接,将权重进行拼接。这样不会影响计算结果。不理解的建议回去补RNN的知识。
候选隐藏状态
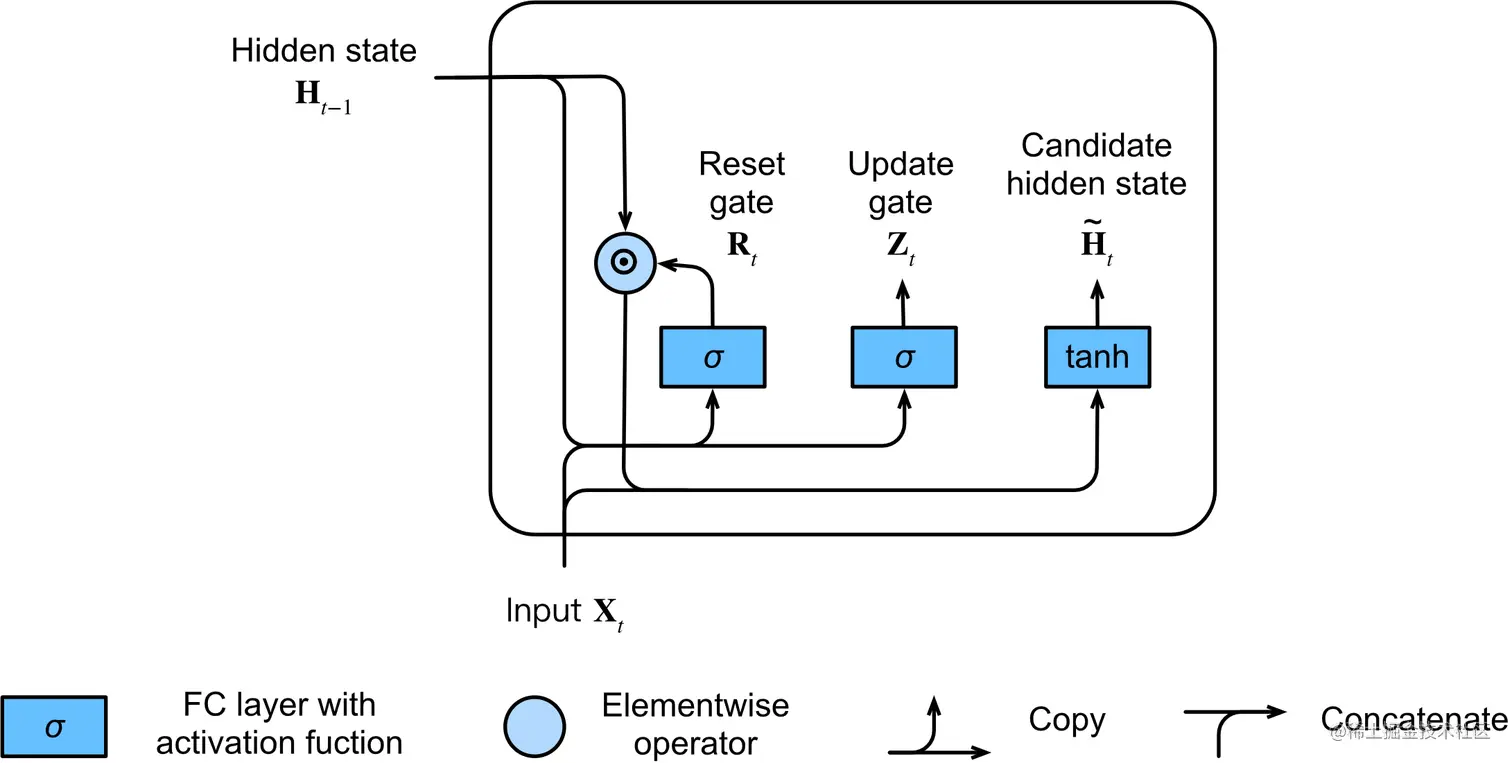
接下来,让我们将重置门 Rt 与我们之前RNN中的常规隐状态更新机制集成,得到在时间步 t 的候选隐藏状态 H~t∈Rn×h。
H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)
- 其中 Wxh∈Rd×h 和 Whh∈Rh×h 是权重参数,bh∈R1×h 是偏置项
- 符号 ⊙ 是哈达码乘积(按元素乘积)运算符。
- 使用 tanh 作为激活函数,确保候选隐藏状态中的值保持在区间 (−1,1) 之间
计算的结果是候选隐藏状态,因为我们仍然需要结合更新门的操作。
这一步主要是为了展示重置门的作用。
我们先来看一下候选隐藏状态。他在计算与普通RNN的计算有什么差别呢。就是在上一步的隐藏状态加上一步计算,与重置门进行哈达码乘积(按元素乘积)。
经过上一步的sigmoid激活函数计算之后重置门中的值应该是趋近于0或者趋近于1的。
-
每当重置门 Rt 中的项接近 1 时,那就相当于对上一步的隐藏状态不进行改变。公式就会变成H~t=tanh(XtWxh+Ht−1Whh+bh),这就和普通的循环神经网络没有什么两样。
-
对于重置门 Rt 中所有接近 0 的时候,H~t=tanh(XtWxh+bh),我们就可以看做是忽略了上一步的隐藏状态。这一步的候选隐藏状态是以 Xt 作为输入的计算结果。因此,任何预先存在的隐藏状态都会被重置为默认值。
隐藏状态
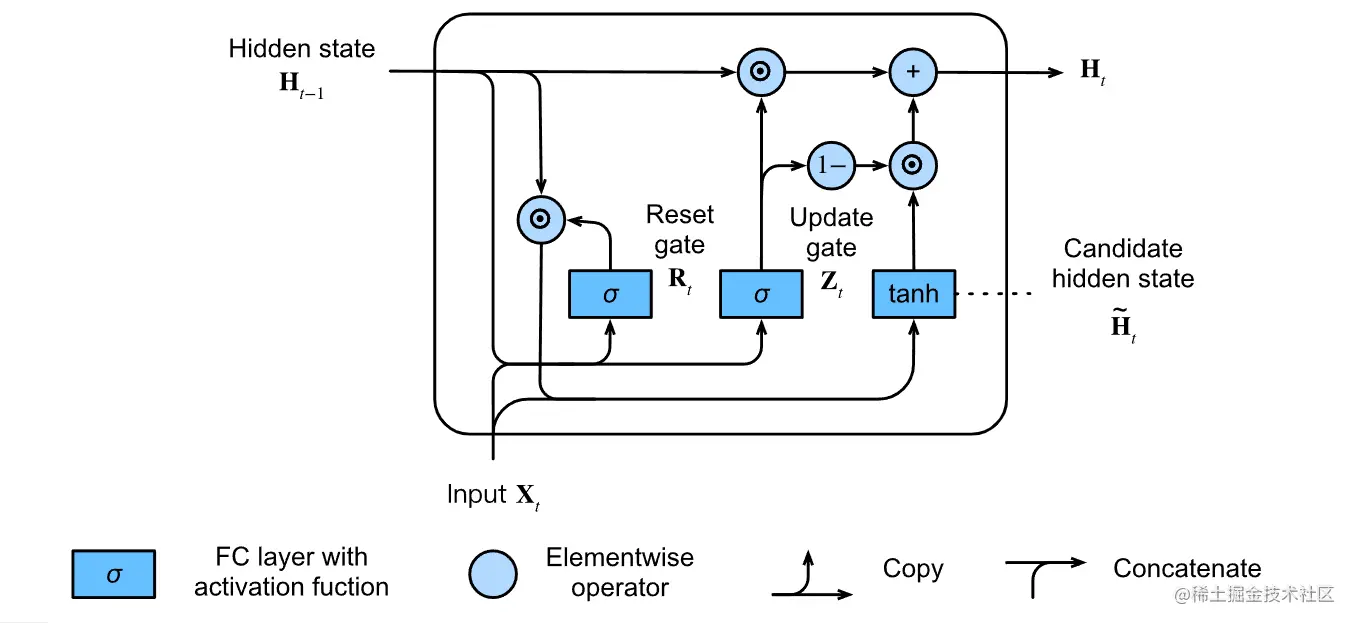
上一步中说了。我们说出来的只是候选隐藏状态。真正的隐藏状态还是要结合更新的来进行计算。那这一步我们就是结合更新门 Zt 进行计算。
确定新的隐藏状态 Ht∈Rn×h 在多大程度上使用旧的状态 Ht−1 ,以及对新的候选状态 H~t 的使用量。更新门 Zt 仅需要在 Ht−1 和 H~t 之间进行按元素的凸组合就可以实现这个目标。这就得出了门控循环单元的最终更新公式:
Ht=Zt⊙Ht−1+(1−Zt)⊙H~t
之前说过了,经过sigmoid计算之后,更新门的数值也是趋近于0或者1的。
- 每当更新门 Zt 接近 1 时,我们就只保留旧状态。此时,来自 Xt 的信息基本上被忽略,从而有效地跳过了依赖链条中的时间步 t。
- 当 Zt 接近 0 时,新的隐藏状态 Ht 就会接近候选的隐藏状态 H~t。
这些设计可以帮助我们处理循环神经网络中的梯度消失问题,并更好地捕获时间步距离很长的序列的依赖关系。例如,如果整个子序列的所有时间步的更新门都接近于 1,则无论序列的长度如何,在序列起始时间步的旧隐藏状态都将很容易保留并传递到序列结束。
结束
到这GRU就完成了他的任务:
- 重置门有助于捕获序列中的短期依赖关系。
- 更新门有助于捕获序列中的长期依赖关系。
相关论文阅读
-
Long Short-Term Memory | MIT Press Journals & Magazine | IEEE Xplore
-
[1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate (arxiv.org)
-
[1412.3555v1] Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling (arxiv.org)


