

小知识,大挑战!本文正在参与“程序员必备小知识”创作活动。
谢谢你这么好看还关注我,虽然还没关注,但不会真的不关注吧🥰
👀写在前面
如果你学过概率论,你只需要看看黑体和例题 大概就能看懂朴素贝叶斯它到底想干啥😬
条件概率
现在有一盒巧克力,里面装了16块,其中黑色、白色、棕色巧克力各4块,红色、黄色巧克力各2块。如果把这些巧克力分别放在A、B两个盒子里,从A盒中取出黑色巧克力的概率是多少?
🤔我们看着盒子数一数就知道,在A中黑色巧克力有3个,盒内一共有7个巧克力,那么从A盒中取出黑色巧克力的概率是
我们也可以使用条件概率的形式表达出来:
这说明已知一块黑色巧克力是来自A盒的,它的概率等于巧克力是黑色的并且来自A盒的概率除以巧克力来自于A盒的概率
通过数一数,我们看到巧克力总数是16,巧克力是黑色的并且来自于A盒的个数是3,巧克力来自于A盒的个数是7,
💥条件概率公式:
贝叶斯定理
1.贝叶斯定理
还是基于上面的问题背景:
已知取出一块黑色的巧克力,它来自A盒的概率是多少?
这里,可以把分子的公式用上题的结果来表达:
最终将②③代入①式计算出:
已知:存在K类 c1, c2,..., cK,给定一个新的实例 x=(x(1),x(2),...,x(n))。问:该实例归属第ci类的可能性有多大?
分子是同时满足两种情况的概率,分母是发生这一条件的全概率公式
贝叶斯定理为:
2.贝叶斯分类
已知:有A和B两盒巧克力,现在拿到一块黑色的巧克力。问:该巧克力最有可能是哪个盒子的?
,所以来自A盒的概率最大,那么巧克力最有可能来自于A盒,这就是贝叶斯分类。
存在K类c1,c2,...,cK,给定一个新的实例x=(x(1),x(2),...,x(n))问:该实例归属于哪一类?
我们可以分别计算 的值,然后找到最大的那个。这里面的分母都是相同的,因此只需要计算不同类下的分子👇,找到最大值就可以确定归属的类了。
朴素贝叶斯
朴素贝叶斯和贝叶斯相比,有一个前提条件:假设实例点中的每个特征是相互独立的。这就是朴素的含义😁
根据朴素贝叶斯所有的x(1),x(2),....,x(n)都是相互独立的,那么分子其中一部分的就可以写成:
最终只需要求出👇:
从而找出归属的类别,即可完成朴素贝叶斯算法的分类。
后验概率最大化准则
请问:巧克力是黑色的并且来自于A盒的概率P是多少?
由上文②式得,
P(A盒)叫做先验概率分布,也可以表示成:
P(黑色巧克力|A盒)叫做条件概率分布,也可以表示成:
当条件变成对调时,由P(X|Y)变成P(Y|X),得到贝叶斯定理得:
这个就称为后验概率分布(就是贝叶斯定理那个公式)
1. 朴素贝叶斯分类方法
假如存在K类c1,c2,...,cK,现在给定一个新的实例 x=(x(1),x(2),...,x(n))。问该实例归属于哪一类?
上面的后验概率公式 ,由于分母都相同,因此,只需要计算出分子的最大值就可以找出这个实例所对应的类。
PS:不用被这里一堆公式吓到,你在前面朴素贝叶斯那里已经见过了,是一样的😋
2. 0-1损失函数
在k近邻法中,为了制定规则来决定这个分类函数的好与坏,我们需要比较分类问题的损失情况,在朴素贝叶斯方法中继续用到0-1损失函数:
0-1~损失函数
f(X)是分类决策函数
Y是对应的分类,输出空间为{c1,c2,...,cK}
当两者相等时,证明分类正确,没有损失,反之记为1,有损失
这个损失函数对应的期望是:
详见:简博士-后验概率最大化
一顿操作下来,反正就是 把期望风险最小化转换为后验概率最大化🤨
极大似然估计
先验概率 的极大似然估计是
简单来说,这个公式的意思就是掰着手指头🖐数一数训练样本集中ck的样本有多少个,然后除以样本总数N
条件概率 的极大似然估计是
这个公式的含义是:计算出某一特征在某一类条件下的概率,分子是在这个类中对应特征的样本个数,分母是这个类中的样本总数
朴素贝叶斯算法步骤
目标🏆:如果有一个实例点x,想通过朴素贝叶斯的分类法找到它对应的类别y
解决途径🛶:通过后验概率最大化实现
计算过程🔑:
round 1: 求出先验概率(极大似然估计)
round 2: 求出一系列的条件概率(极大似然估计)
round 3: 把各类的先验概率和条件概率连乘,得出计算结果最大值,就是对应的类
例题解说
输入:训练集
输出:实例点 x=(2,S)T 的类标记 y
接下来,我们就用上面的3步走来计算。
round 1:求出先验概率
数一数🔍就知道,在这个数据集中,有2个类别,分别是Y=1和Y=-1两类,总共有实例15个,
round 2:求出一系列的条件概率
数据集的X有两个特征,分别是 X(1) 和 X(2),其中 X(1) 的取值空间为{1,2,3},X(2) 的取值空间为{S,M,L},这里需要对每一类中的每一个特征分别进行计算:
对于类别 Y=1 而言:
从9个 Y=1 里面数一下, X(1)=1 的实例有2个,那么
以此类推,可以求出 Y=1 类下的其他特征条件概率。
对于类别 Y=-1 而言:
从6个 Y=-1 里面数一下,X(1)=1 的实例有3个,那么
以此类推,也可以求出 Y=-1 类下的其他特征条件概率。
round 3:把各类的先验概率和条件概率连乘,得出计算结果最大值,就是对应的类
假如两个特征相互独立,对于实例 x=(2,S) 而言,分别计算两个类别下的后验概率
通过比较两个后验概率值,发现 Y=-1 时后验概率最大,所以 y=-1
贝叶斯估计
若 在 Y=1时,不存在 X(2)=S 的实例点,则
那么会导致
这显然是错误的
为了避免用极大似然估计法计算出概率值为0的情况,贝叶斯估计在先验概率和条件概率的分子分母上均引入了一个 ,当 =0时就是极大似然估计。
先验概率的贝叶斯估计
贝叶斯估计常取 =1,也称为拉普拉斯平滑或拉普拉斯估计
条件概率的贝叶斯估计
例题解说
还是基于上面那道题,用贝叶斯估计再做一遍
输入:训练集
输出:实例点 x=(2,S)T 的类标记 y
还是老规矩,三步走🤠~
round 1:求出贝叶斯估计的先验概率
在这个数据集中👀,一共有两个Y类,所以 K=2,同样的还是共有15个实例
round 2:求出贝叶斯估计的条件概率
Sj 怎么找呢?🥺
其实就是,数据集中分别有两个特征 X(1) 和 X(2) ,那么就对应 j=1 和 j=2,其中 X(1) 取值有{1,2,3},共有3种,所以这里 S1 =3, X(2) 取值有{S,M,L},也是3种,所以 S2 =3
对于类别 Y=1 中的特征 X(1) 而言:
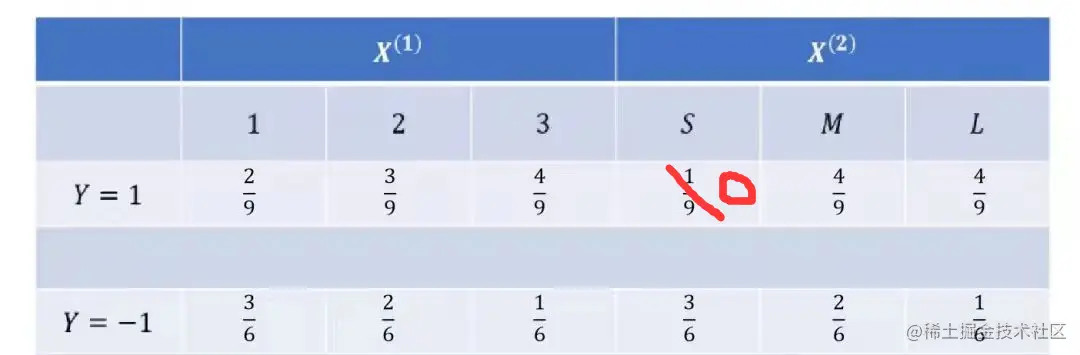
简单来说,就是把上文中的式子都引入了一个,以此类推可求得 、、等等,我们把所有结果写在下表里:
round 3:把各类的先验概率和条件概率连乘,得出计算结果最大值,就是对应的类
对于实例 而言,分别计算两个类别下的后验概率:
通过比较发现, 的计算结果较大,所以 y=-1
📓写在后面
当我在朴素贝叶斯里绕来绕去后才发现,这几乎差不多就是把概率论的内容复习了一遍😅
如有问题,欢迎交流呐~
可以私信到公众号后台 :昕之一方
代码仓库含朴素贝叶斯的完整实现过程代码及scikit-learn实例,请戳👉gitee.com/xin-yue-qin… 👈
参考资料:简博士-朴素贝叶斯定理
