k-NN
KNN(k近邻学习)的工作机制很简单:对于给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个邻居的信息来预测。
通常:
- 分类任务用投票法:选择k个样本中出现最多的类别标记
- 回归任务用平均法:选择k个样本的实值输出标记的平均值
KNN为懒惰学习(lazy learning)方法:即训练时间开销为0,在收到测试样本后才会处理训练样本。与之相对的是急切学习(eager learning):在训练阶段就会对样本进行学习处理。
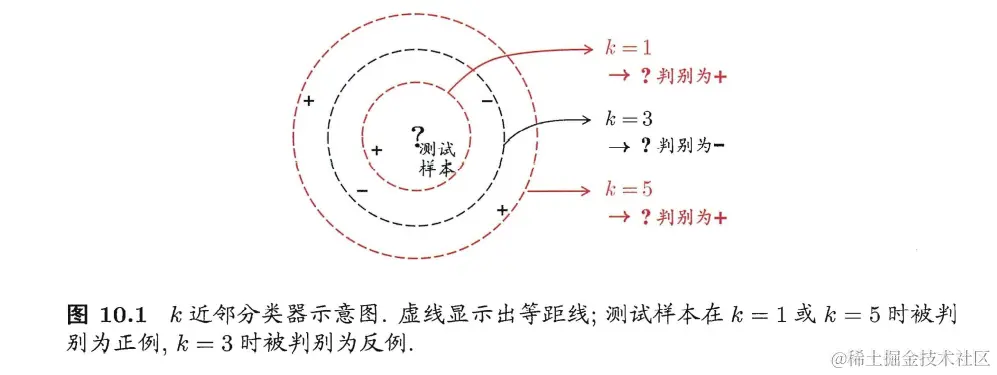
KNN中k值的设置是一个重要参数,会验证影响分类结果,如下图所示:
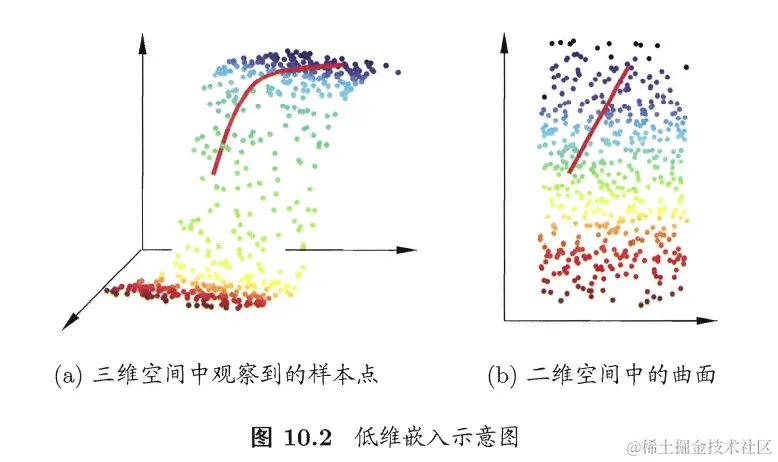
低维嵌入 low-dimensionality embedding
KNN的方法要求训练样本的采样密度足够大,称为密采样(dense sample),这样才能令测试样本附近任意小的某距离范围内总能找到一个训练样本。然而现实中很难存在这种情况,尤其是特征维数较高的情况下。
在高维情况下出现的数据样本稀疏、距离计算困难等问题是所有机器学习方法共同面临的障碍,称为维数灾难(curse of dimensionality)。
缓解维数灾难的一个重要方法是降维(dimension reduction),通过某种数学变换将原始高维特征空间转变为一个低维子空间。降维的理论基础在于:日常观测到的样本是高维的,但是与学习任务相关的可能仅是某个低维分布,即高维空间中的一个低维嵌入(embedding)。
Multiple Dimensional Scali 多维缩放 MDS
MDS是一种降维方法,将原始空间中的样本距离特征保留到低维空间中。
假定m个样本在原始空间的距离矩阵为DD∈Rm×m,第i行j列的元素distij表示样本xxi到xxj的距离。
MDS的目标是获得样本点在d′维空间的表示ZZ∈Rd′×m,d′≤d,且两个样本在d′维空间中的欧式距离等于其在原始空间中的距离,即∣∣zzi−zzj∣∣=distij。
distij2=∣∣zi∣∣2+∣∣zj∣∣2−2ziTzj
令BB=ZZTZZ∈Rm×m,bij=2ziTzj,则:distij2=bii+bjj−2bij。
MDS的思路在于:给定距离矩阵DD,能否通过distij2得到矩阵B?
不加限制条件的情况下,通过整体平移和旋转是不会影响样本间的距离,也就是说可以得到无数个BB这显然不是正确的解法,因此在二维空间中需要为BB的求解增加限制条件——数据中心化:
i=1∑mzik=0,k=0,1,...,d
i=1∑mbij=i=1∑mzizjT=i=1∑mk=1∑dzikzjk=k=1∑d(i=1∑mzik)zjk=0
于是有:∑i=1mbij=∑j=1mbij=0。
tr(⋅)表示矩阵的迹(trace),tr(BB)=∑i=1m∣∣zi∣∣2。
综上可得:
i=1∑mdistij2=i=1∑m(bii+bjj−2bij)=i=1∑m(∣∣zi∣∣2+bjj−0)=tr(BB)+mbjj
同理可得:
j=1∑mdistij2=tr(BB)+mbii i=1∑mj=1∑mdistij2=i=1∑mj=1∑m(bii+bjj−2bij)=i=1∑m(tr(BB)+mbii)=2m tr(BB)
定义几个新的符号,令:
disti.2=m1i=1∑mj=1∑mdistij2dist.j2=m1i=1∑mdistij2dist..2=m21i=1∑mj=1∑mdistij2
这一步的目标是用dist来表示bii,bjj,bij,从而可以求解出BB,综合上述内容可得:
tr(BB)=2m∑i=1m∑j=1mdistij2=2mm2dist..2=2mdist..2
同理可推得:
bii=m1(mdisti2−2mdist..2) bjj=m1(mdistj2−2mdist..2)
综上可得:
bij=21(distij2−disti.2−dist2.j+dist..2)
由此可以推出矩阵DD降维后保持不变的矩阵ZZ的内积矩阵BB。
最后一步就是:通过BB求解ZZ(使用特征值分解):
BB=VVΛΛVVT
其中VV为特征向量矩阵,ΛΛ=diag(λ1,...,λd′),为特征值构成的对角矩阵,可知ΛΛ=ΛΛT。
BB=ZZZZT=VVΛΛVVT=VVΛΛΛΛTVVT
可知:ZZ=ΛΛVVT。在实际应用中通常只报了前d′个特征及其相应的特征矩阵Λ~(影响最大),因此可得:
ZZ=Λ~VV~T ∈Rd′×m

主成因分析 PCA
见之前写过的文章
kernelized 核化线性降维
线性降维方法假设从高维到低维的空间函数映射是线性的,然而现实任务中很多需要非线性映射,如下图所示。
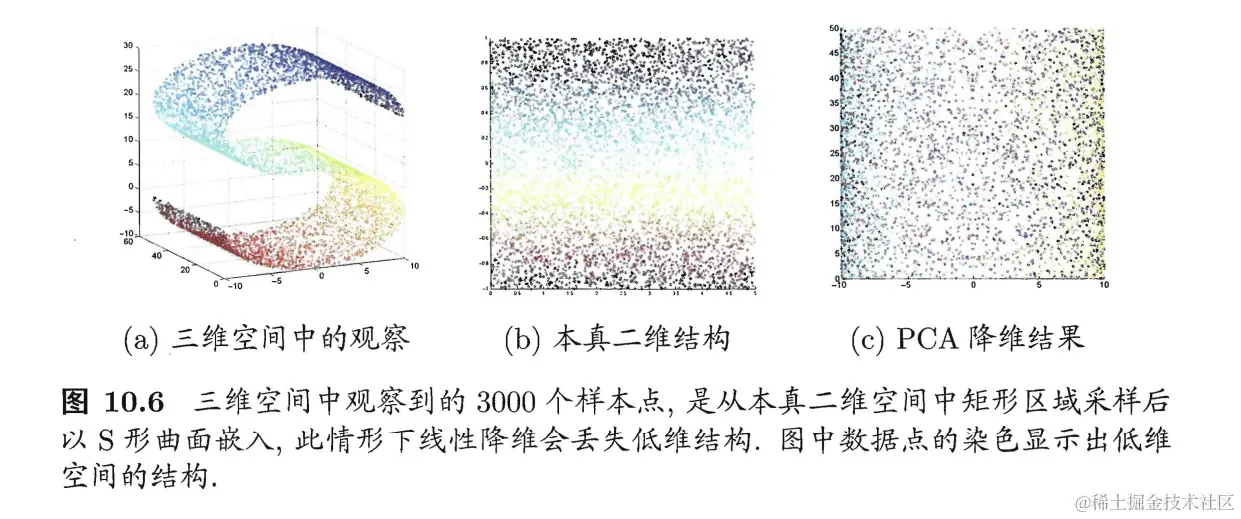
因此需要非线性降维方法,有代表性的一种就是基于核方法对传统线性降维方法进行“核化”,例如核主成因分析((Kernelized PCA, KPCA)。
manifold learning 流形学习
流形学习的主要启发点在于流形数据集局部存在欧式空间的性质可以用欧式距离度量,因此可以通过在局部建立降维映射关系,再设法将局部映射关系推广到全局中。
Isometric Mapping 等度量映射
如下图所示,流形空间中若直接计算两个点在低维嵌入的欧式距离(黑线)是不可取的,因为不能脱离曲面来行走,(如(a)所示),正确的行走路径为红线。
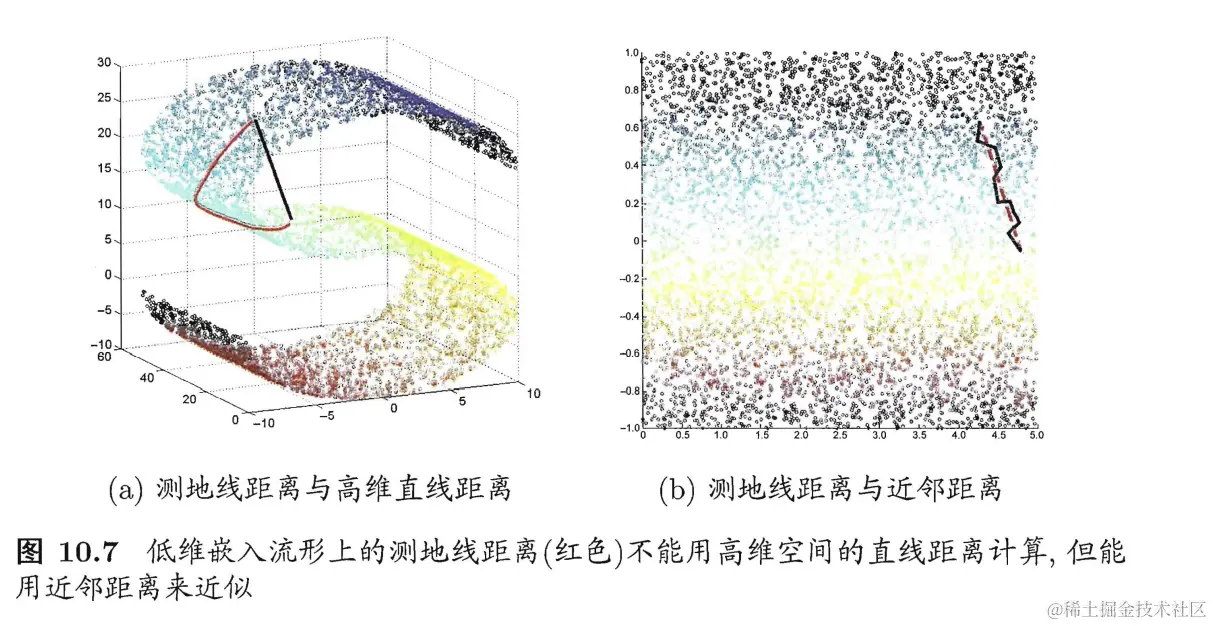
如何计算这个距离呢?此时可以考虑在流形的局部使用欧式空间的性质,即对于每个点基于欧式距离找到临近的点,建立近邻连接图,非近邻的点间不存在连接,然后根据图来计算两个点之间的最短路径问题。

局部线性嵌入 LLE
见之前写过的文章

metric learning 度量学习
降维的目的是在合适的低维空间中寻找一个合适的度量,度量学习的目的在于:研究能否直接找到一个合适的距离度量。
之前介绍了很多距离度量方法,但是都是静态的,没有可调节的参数,想要学习一个好的度量必然涉及到参数调节问题,因此可以先对之前提出过的距离做一个改进:
对于两个特征维度d的样本xxi,xxj,他们之间欧式距离的平方可以写为:
disted2(xxi,xxj)=∣∣xxi−xxj∣∣22=distij,12+...+distij,d2
其中distij,k表示xxi,xxj在第k维上的距离,根据不同特征的重要程度可以引入特征权重ww:
distwed2(xxi,xxj)=w1distij,12+...+wddistij,d2=(xxi−xxj)TWW(xxi−xxj)
其中WW=diag(ww)。
更进一步,WW限制为对角矩阵,即其认为不同特征间无关,但是现实中特征是可能相关的(如一个人的身高和体重),因此将对角矩阵替换成一个普通的半正定矩阵MM即可得到马氏距离的公式:
distmah2(xxi,xxj)=(xxi−xxj)TMM(xxi−xxj)=∣∣xxi−xxj∣∣M2
MM亦可称为度量矩阵,度量学习的目的就是学习出MM,在现实任务中通常还需要根据任务需求,增加一些限制条件来求解最优的MM。


