

[深度概念]·Softmax优缺点解析
个人主页--> xiaosongshine.github.io/
Softmax是soft(软化)的max。在CNN的分类问题中,我们的ground truth是one-hot形式,下面以四分类为例,理想输出应该是(1,0,0,0),或者说(100%,0%,0%,0%),这就是我们想让CNN学到的终极目标。
网络输出的幅值千差万别,输出最大的那一路对应的就是我们需要的分类结果。通常用百分比形式计算分类置信度,最简单的方式就是计算输出占比,假设输出特征是 ,这种最直接最最普通的方式,相对于soft的max,在这里我们把它叫做hard的max:
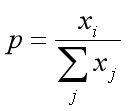
而现在通用的是soft的max,将每个输出x非线性放大到exp(x),形式如下:
hard的max和soft的max到底有什么区别呢?看几个例子
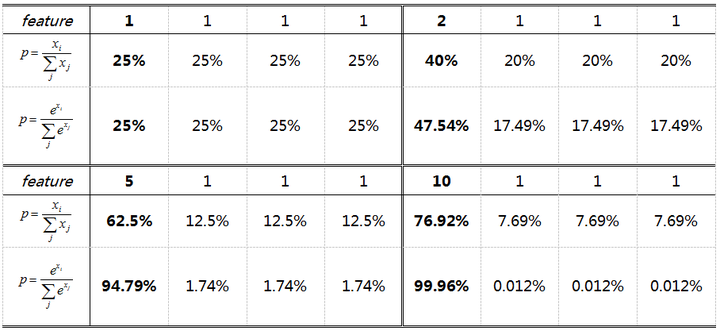
相同输出特征情况,soft max比hard max更容易达到终极目标one-hot形式,或者说,softmax降低了训练难度,使得多分类问题更容易收敛。
到底想说什么呢?Softmax鼓励真实目标类别输出比其他类别要大,但并不要求大很多。对于人脸识别的特征映射(feature embedding)来说,Softmax鼓励不同类别的特征分开,但并不鼓励特征分离很多,如上表(5,1,1,1)时loss就已经很小了,此时CNN接近收敛梯度不再下降。
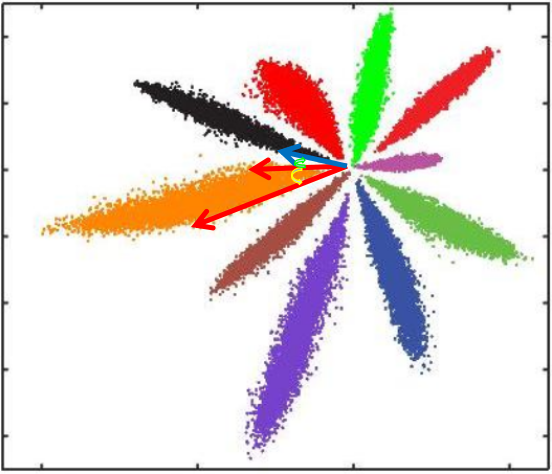
Softmax Loss训练CNN,MNIST上10分类的2维特征映射可视化如下:
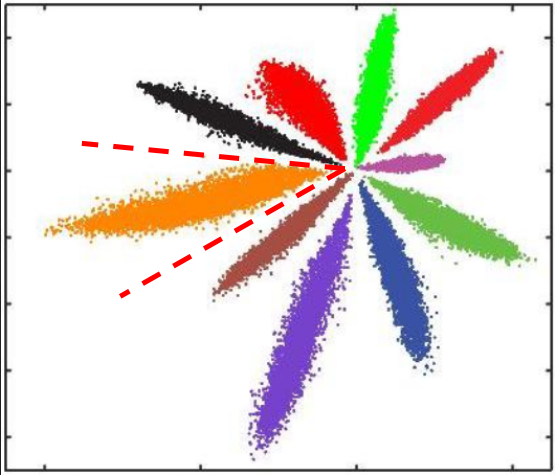
不同类别明显分开了,但这种情况并不满足我们人脸识别中特征向量对比的需求。人脸识别中特征向量相似度计算,常用欧式距离(L2 distance)和余弦距离(cosine distance),我们分别讨论这两种情况:
- L2距离:L2距离越小,向量相似度越高。可能同类的特征向量距离(黄色)比不同类的特征向量距离(绿色)更大
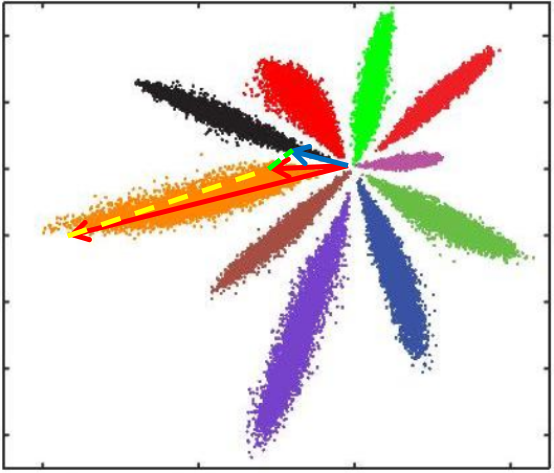
- cos距离:夹角越小,cos距离越大,向量相似度越高。可能同类的特征向量夹角(黄色)比不同类的特征向量夹角(绿色)更大
总结来说:
- Softmax训练的深度特征,会把整个超空间或者超球,按照分类个数进行划分,保证类别是可分的,这一点对多分类任务如MNIST和ImageNet非常合适,因为测试类别必定在训练类别中。
- 但Softmax并不要求类内紧凑和类间分离,这一点非常不适合人脸识别任务,因为训练集的1W人数,相对测试集整个世界70亿人类来说,非常微不足道,而我们不可能拿到所有人的训练样本,更过分的是,一般我们还要求训练集和测试集不重叠。
- 所以需要改造Softmax,除了保证可分性外,还要做到特征向量类内尽可能紧凑,类间尽可能分离。
