阅读论文--xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
背景
针对CTR预测问题,文章从特征组合的角度开展研究,在DeepFM、Wide & Deep的基础上,提出了Compressed Interaction Network(CIN),CIN实现了
- 使用vector-wise的形式进行特征交互,取代之前的bit-wise形式
- 高阶特征的交互方式是显示的(可以明确最大特征交叉阶数为多少)
- 网络的复杂度不会随着交互的程度呈指数增长
与vector-wise概念相对应的是bit-wise,在最开始的FM模型当中,通过特征隐向量之间的点积来表征特征之间的交叉组合。特征交叉参与运算的最小单位为向量,且同一隐向量内的元素并不会有交叉乘积,这种方式称为vector-wise。后续FM的衍生模型,尤其是引入DNN模块后,常见的做法是,将embedding之后的特征向量拼接到一起,然后送入后续的DNN结构模拟特征交叉的过程。这种方式与vector-wise的区别在于,各特征向量concat在一起成为一个向量,抹去了不同特征向量的概念,后续模块计算时,对于同一特征向量内的元素会有交互计算的现象出现,这种方式称为bit-wise。
将常见的bit-wise方式改为vector-wise,使模型与FM思想更贴切,这也是xDeepFM的Motivation之一。这里需要提醒的是,vector-wise的方式其实在之前介绍的PNN、NFM、AFM与DeepFM中都有使用,但是并没有单独拎出来说明清楚。
文章使用CIN+DNN+Linear构建了eXtreme Deep Factorization Machine(xDeepFM)模型,并且在数据集上验证了模型的效果。
预备知识
embedding layer
使用01表示特征时,特征是高阶的,稀疏的,如下图所示
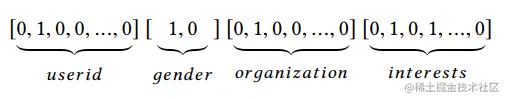
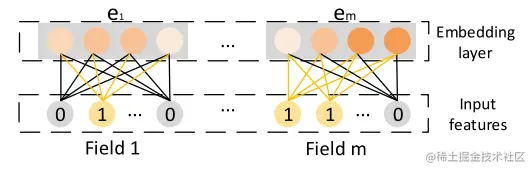
使用embedding layer将原始特征变为embedding表示,形式为:e=[e1,e2,...,em],其中ei∈RD,embedding的长度为m×D。embedding layer表示如下图所示
隐式高阶相互作用
神经网络中特征运算如下所示,其中同一个field的embedding也会互相影响。DNN不能推断出具体学到了多少阶的交叉特征,因此被称之为隐式特征交互。
x1=σ(W(1)e+b1)
xk=σ(W(k)x(k−1)+bk)
显示高阶相互作用
在Cross Network(CrossNet)中,显示交互表示为:xk=x0xk−1Twk+bk+xk−1,文中推导得到如下
xi+1=x0xiTwi+1+xi=x0((αix0)Twi+1)+αix0=αi+1x0
其中αi+1=αi(x0Twi+1+1),因此可以推导出特征交互的阶数,CrossNet的表示有如下的缺点
- Cross-Network的输出以特殊形式限制,每个隐藏层是x0标量的倍数
- 特征交互以bit-wise方式进行。
CIN模型
文中将embedding表示为矩阵的形式,其中输入为X0∈Rm×D,在CIN中第k层的embedding表示为Xk∈RHk×D,其中Hk表示特征向量的个数,Xi,∗0为X0的第i行特征。
CIN中,Xk的计算方式如下
Xh,∗k=∑i=1Hk−1∑j=1mWijk,h(Xi,∗k−1∘Xj,∗0)。
其中1≤h≤Hk,Wk,h∈RHk−1×m,∘为Hadamard product, ⟨a1,a2,a3⟩∘⟨b1,b2,b3⟩=⟨a1b1,a2b2,a3b3⟩。
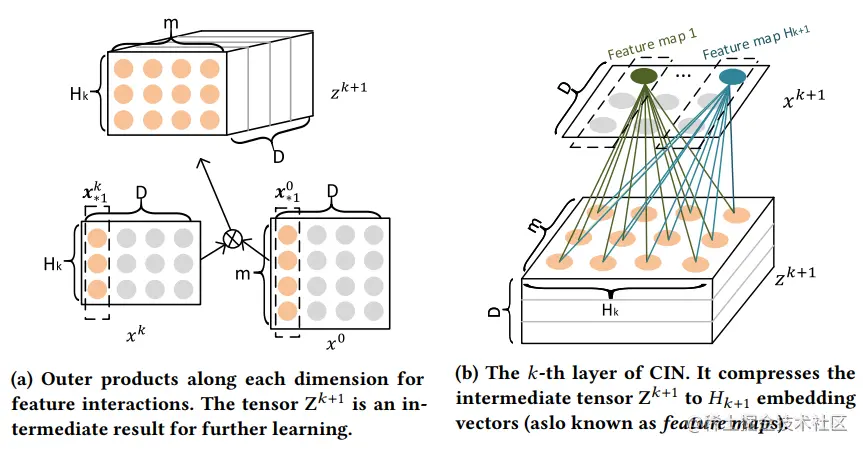
Xk的计算可以形象表示为两步,
- Xk和X0两两求Hadamard积,构成了Hk∗m个D维度的tensor,文中记为Zk+1,如下左图所示
- 然后在进行求和,如下右图所示。
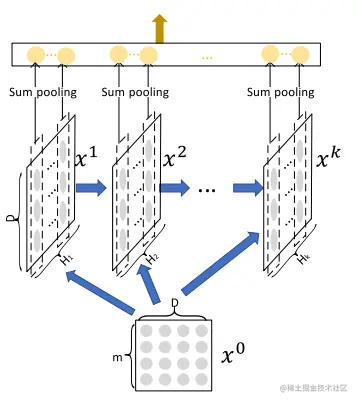
对于Xk,k∈[1,T],对每一层进行sum pooling,即pik=∑j=1DXi,jk,Xk经过pooling后的向量为pk=[p1k,p2k,…,pHkk],将1到T得到的pk进行拼接为:p+=[p1,p2,…,pT]∈R∑i=1THi,经过线性模型进行预测方式为:y=1+exp(p+Two)1。
文中从Space Complexity、Time Complexity、Polynomial Approximation对CIN进行分析。
Space Complexity
- CIN参数量为:∑k=1THk×(1+Hk−1×m),参数复杂度为:O(mTH2)
- DNN参数量为:m×D×H1+HT+∑k=2THk×Hk−1,参数复杂度为:O(mDH+TH2)和D相关
Time Complexity
- CIN时间复杂度:O(mH2DT)
- DNN时间复杂度:O(mHD+H2T)
Polynomial Approximation
第k层的第h个特征向量可以表示如下,个人理解也就是特征的k阶表示。
xhk=i∈[m]∑Wi,jk,h(xik−1∘xj0)=j∈[m]∑…i∈[m]∑…r∈[m]∑l∈[m]∑Wi,jk,h…Wl,s1,r(t∈[m]s∈[m]xj0∘…∘xs0∘xl0)
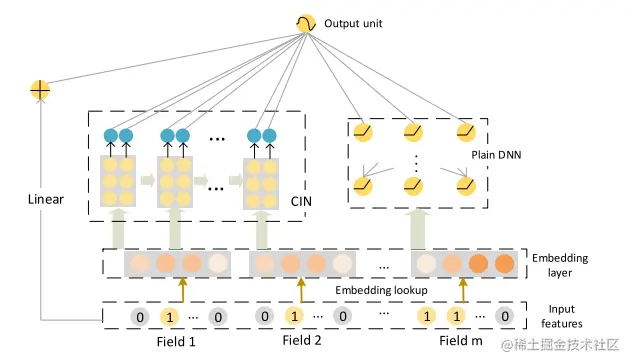
XDeepFM模型
XDeepFM由CIN、DNN、Linear组成,包括了低阶和高阶的特征交互。
-
网络表示为:y^=σ(wlinear Ta+wdnnTxdnnk+wcinTp++b)
-
损失函数为Cross entropy损失函数:L=−N1∑i=1Nyilogy^i+(1−yi)log(1−y^i),在损失函数中加入正则项,最终损失函数为:J=L+λ∗∥Θ∥。
网络结构如下图所示
实验
实验探索了3个问题
- 提出的CIN在高阶特征交互学习中表现如何?
- 推荐系统是否需要结合隐式特征交互和显示特征交互?
- 网络设置如何影响xDeepFM的性能?
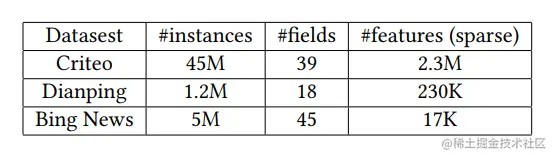
实验数据集如下,使用AUC(Area Under the ROC curve)和Logloss(cross entropy)进行评价,具体参数可参考论文。
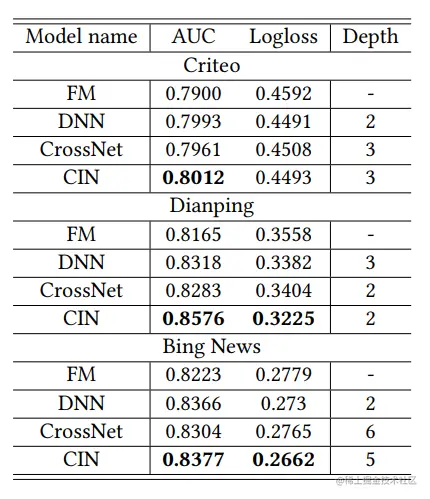
问题1:CIN效果
实验结果如下,其中层数为最优的网络层数(通过搜索得到),得到的结论有:
- 稀疏特征上的高阶交互是必要的,这一点可以通过DNN、CrossNet和CIN在三个数据集上的性能明显优于FM得到验证
- CIN是最好的模型,这表明CIN在建模显式高阶特征交互方面的有效性。k层CIN可以模拟k度特征交互作用。同样有趣的是,CIN需要5层才能在Bing新闻数据集上产生最佳结果。
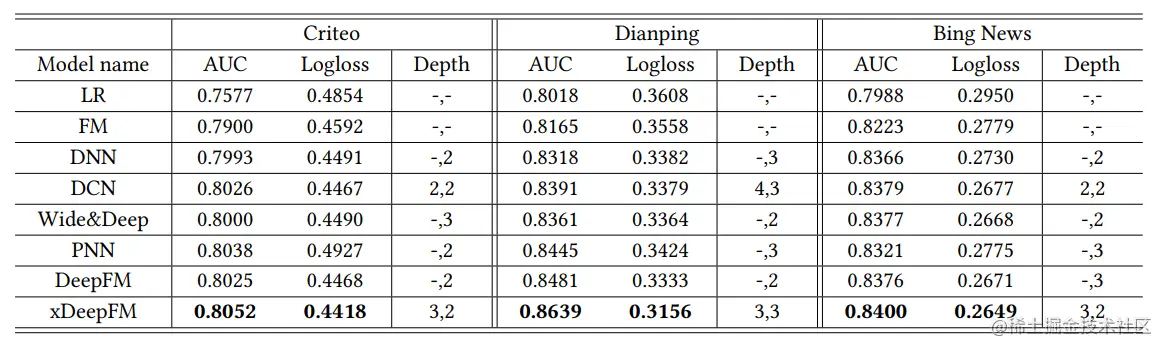
问题2:隐式特征交互+显示特征交互
使用结果如下所示,结论有
- LR比其他所有模型都差得多,这说明基于因子分解的模型对于测量稀疏特征是必不可少的
- Wide&Deep, DCN, DeepFM和xDeepFM都明显优于DNN,这直接反映了混合组件虽然简单,但对于提高预测系统的准确性是很重要的
- 提出的xDeepFM在所有数据集上都取得了最好的性能,这表明将显式和隐式高阶相结合是可行的
- 深度超参数的典型设置是2和3,xDeepFM的最佳深度设置是3,这表明我们学习的交互最多为4阶
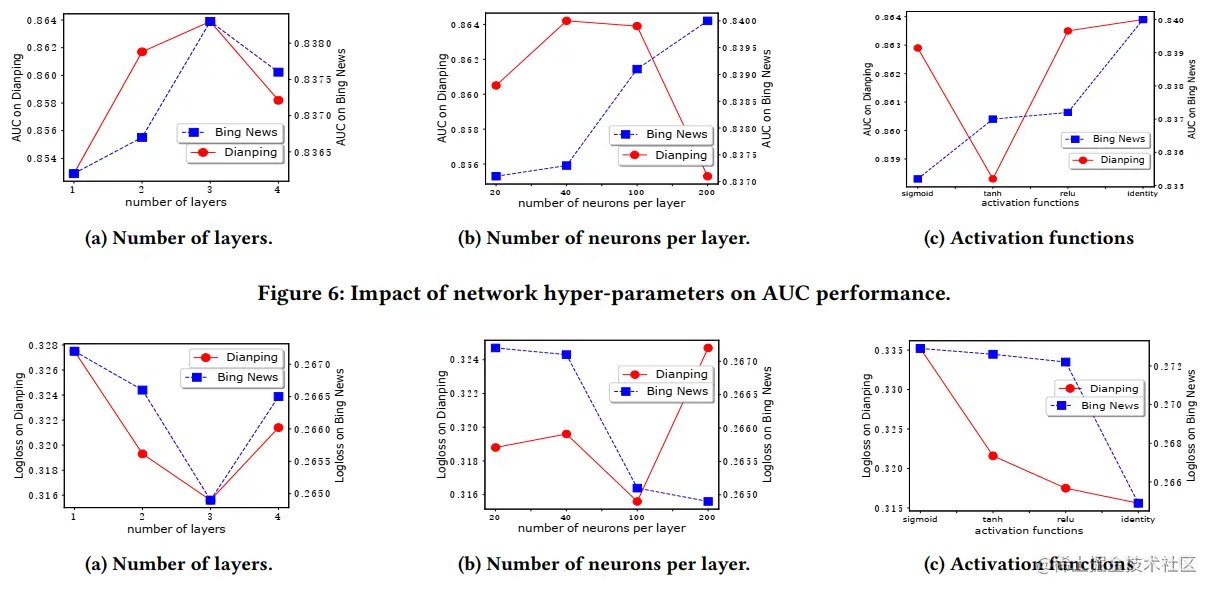
问题3:参数探索
研究以下问题,结论如下图所示
- Depth of Network
- Number of Neurons per Layer
- Activation Function
总结
在DeepFM的基础上对特征表示更加进了一步,个人觉得模型也更加复杂了,不知道在实际业务中是否有大量应用,应用在实际业务中效果如何。
参考资料
- 推荐系统 - 排序 - xDeepFM
- CTR预估 论文精读(十)--xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems


