阅读论文:2010 Fast Context-aware Recommendations with Factorization Machines
背景
文章研究了context-aware的推荐系统,文章针对的任务是给定用户特征、 商品特征,给出排序,本质上是一个回归的问题。
文中对context特征的解释如下
The difference between such user/ item attributes and context is that attributes are attached only to either an item or user (e.g. a genre is attached to a movie) whereas context is attached to the whole rating event (e.g. the mood of a user when rating an item).
context特征包括用户访问推荐系统的时间、地点、心情等。
问题建模
模型输入为用户特征:U={u1,u2,…},商品特征:I={i1,i2,…},以及上述提到的上下文特征C={c1,c2,…}。文中给出例子如下,其中图左侧为推荐输入的特征,中间为编码后特征向量,右侧为预测目标。
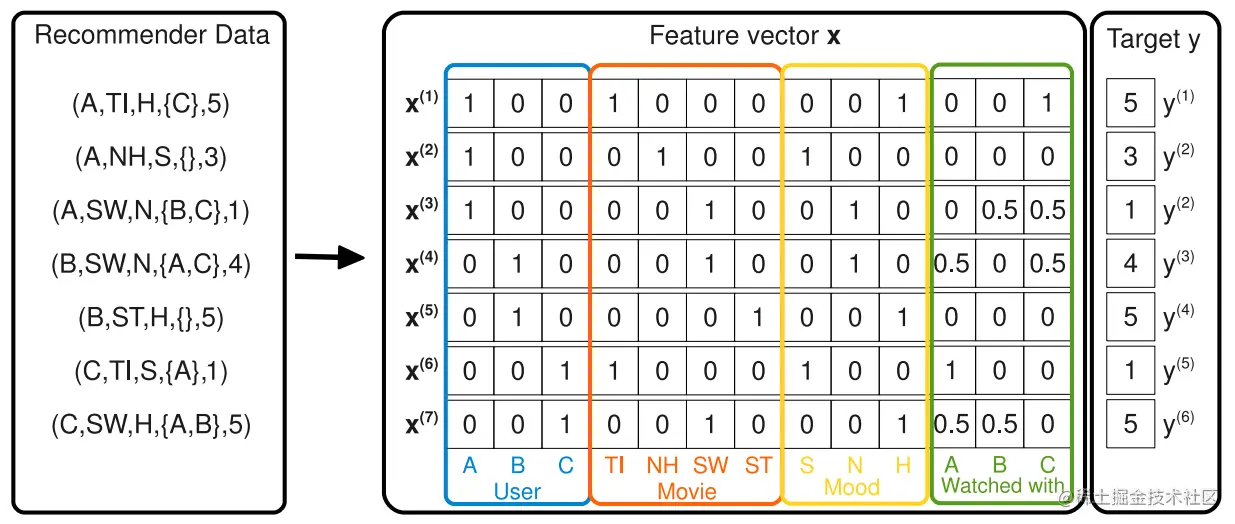
在上述例子中,用户的特征可以表示为y:U×I×C3…×Cm→R,其中C特征从3开始是因为把用户特征和商品特征认为是下标1和2。特征的值表示为
UIC3C4={ Alice, Bob, Charlie }={ TItanic, Notting Hill, Star Wars, Star Trek }={Sad, Normal, Happy}=P(U)
所以上图中第一行表示为:Alice rated TItanic with 5 stars and that she has watched this movie with Charlie while she was Happy.
文中主要贡献为使用FM求解上述问题,并使用ALS优化算法求解,在文中将FM算法和Multiverse Recommendationx算法进行对比,因此下面也做简单记录。
Multiverse Recommendationx
使用Multiverse Recommendationx求解时,问题表示如下(没看明白这个原理,但是不影响理解本文工作)
y^(u,i,c3,…,cm):=∑f1k1…∑fmkmbf1,…,fmvu,f1(U)vi,f2(I)∏l=3mvcl,flCl
其中具体参数维度如下
B∈Rk1×…×km,V(I)∈R∣I∣×k2,V(U)∈R∣U∣×k1V(Cl)∈R∣Cl∣×kl
Multiverse Recommendationx算法存在以下问题
- 令式子中ki=k,则计算复杂度为O(km),导致训练和预测的时间都很慢。
- Multiverse Recommendationx算法只适用于categorical context。
- 在标签推荐的相关任务中,通常情况下,分解几个较低的变量交互作用比分解一个m-ary关系(如Tucker分解)更好。这是因为在高稀疏度下,因式分解的两两关系可以很好地估计,但因式分解的m-ary关系很难估计(翻译的,我也没理解)。
文中解释了三类特征:Categorical domain, Categorical set domain, Real valued domains
- Categorical domain: one-hot的编码方式,非零元素只有1个,表现为:(1, 0, 0)。
- Categorical set domain:编码时在属性对应的维度为非零,非零元素可以有多个,表现为:(0,0.5,0.5)。
- Real valued domains:实数表示的特征,就是值本身。
Factorization Machines
使用FM求解时,问题表示如下
y^(x):=w0+∑i=1nwixi+∑i=1n∑j=i+1nw^i,jxixj
其中w^i,j为特征对之间的相互作用参数,为:w^i,j:=⟨vi,vj⟩=∑f=1kvi,f⋅vj,f,w0∈R,w∈Rn,V∈Rn×k。
因此模型考虑到了特征与特征之间的组合。这么做的意义,参考资料中给出解释如下
同时通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如“化妆品”类商品与“女”性,“球类运动配件”的商品与“男”性,“电影票”的商品与“电影”品类偏好等。因此,引入两个特征的组合是非常有意义的。
上述式子可以化简如下,因此计算复杂度为O(k⋅m(x)),m(x)为特征表示的维度。
y^(x)=w0+∑i=1nwixi+21∑f=1k((∑i=1nvi,fxi)2−∑i=1nvi,f2xi2)
加上正则项,模型优化的目标如下
RLS−OPT=∑(x,y)∈S(y^(x)−y)2+∑θ∈Θλ(θ)θ2
ALS优化算法
上述问题可以通过SGD进行求解,但是文中探讨了使用ALS(Alternating Least Square)求解。通过使用ALS求解,可以避免调节学习率,ALS的推导比较复杂,此处只给记录,部分细节还没看懂(这一块抄的参考资料的)。
LEMMA 1( LINEARITY IN θ) A FM is a linear function with respect to every single model parameter θ∈Θ and thus can be reexpressed as:
y^(x∣θ)=g(θ)(x)+θh(θ)(x)
每一个参数θ都可以单独拎出来,其前面的系数就是h,其他项的和就是g。
h就是y对于θ的偏微分:
h(θ)(x)=∂θ∂y^(x∣θ)
LEMMA 2 (OPTIMAL VALUE FOR θ ) The regularized leastsquare solution of a single parameter θ for a linear model y^(x∣θ) is:
θ=−∑(x,y)∈Sh(θ)2(x)+λ(θ)∑(x,y)∈S(g(θ)(x)−y)h(θ)(x)
令提到的损失函数RLS_OPT的对于θ的偏导为0,且在化简过程带入Lemma 1中的两个方程即可。
算法流程如下,对于lower interatcion的weight首先进行训练,因为他们的数据量更多,进行得更可靠(因为具有单特征的样本明显比多特征的样本要多)。对于2-way interaction,一个维度一个维度轮流进行训练。训练复杂度为O(∣S∣mk),其中∣S∣为样本个数,m为特征长度,k为特征隐式表示的embedding长度。文中还对ALS进行了加速,这边省略不记录。

实验
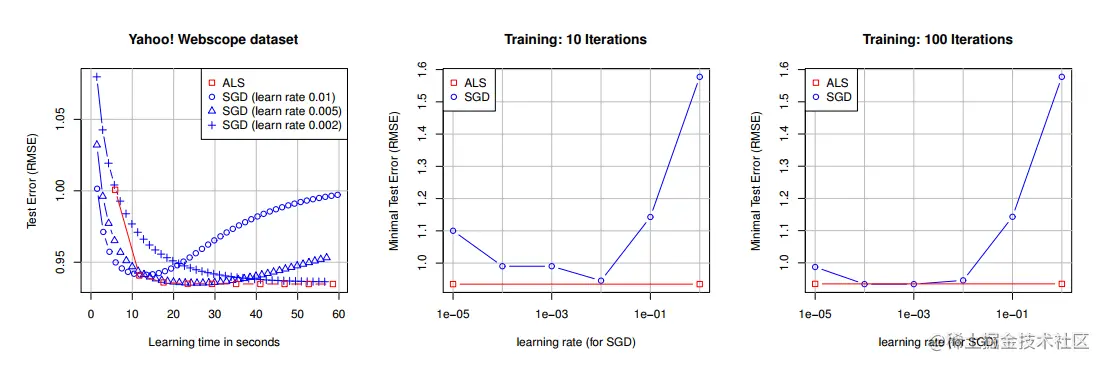
ALS和SGD对比
实验结果如下所示,左图表示SGD在不同学习率下误差相差较大,并且ALS是优于SGD的;中间和由图表示在不同学习率下SGD和ALS对比结果,可以看到ALS完胜。
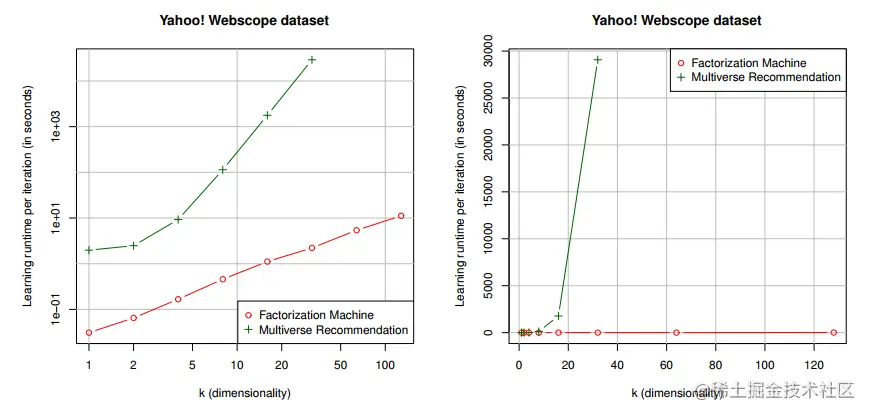
Multiverse Recommendation和FM时间对比
实验结果如下所示,在对于Multiverse Recommendation算法,取m=4,时间复杂度表示如下。FM运行时间为线性,Multiverse Recommendation运行时间为O(k4),差的不是一点。
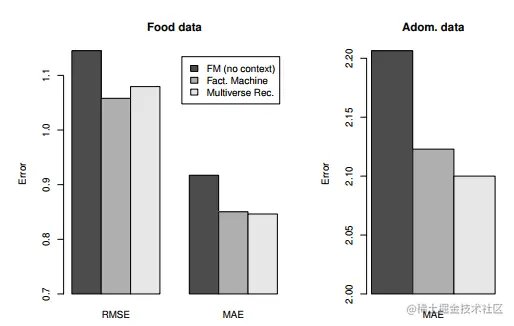
预测结果对比
不同方法的在不同数据集上对比结果如下,这里Fact Meachine看着应该就是FM,FM(no context)就退化为简单的线性模型,可以看到FM效果不错,RMSE和MAE都最低。考虑了context的特征下Multiverse Recommendation也比FM(no context)更好。
在不同context的比例下,实验结果如下所示,随着context特征占比增加,FM和Multiverse Recommendation效果提升;FM(no context)效果下降,原因是无法捕捉context特征(猜测是特征太稀疏无法捕捉)。
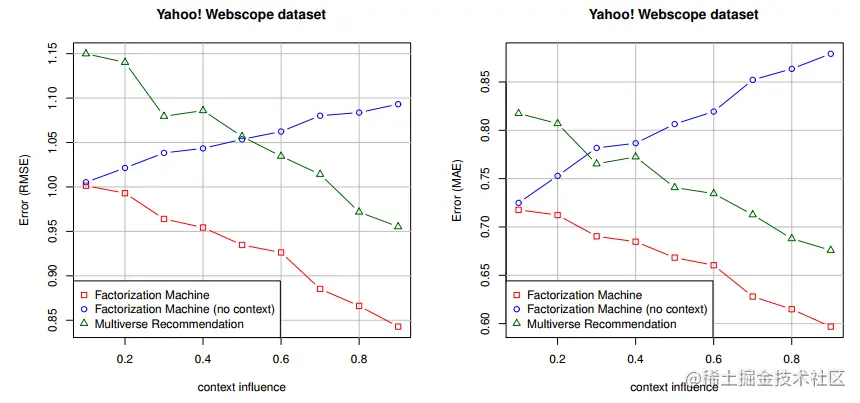 ,
,
总结
FM的公式十分简洁和优美,也具有很强的解释性。相对来说全文更加关注数学,工程方面的介绍较少,数学部分的推导有待深入理解。
参考资料
- 【FM】Factorization Machines 论文理解与简单思考
- 深入FFM原理与实践


