数据,模型,算法共同决定深度学习模型效果
2020/4/20 FesianXu
∇ 联系方式:
e-mail: FesianXu@gmail.com
QQ: 973926198
github: github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:

在文献[1]中对few-shot learning进行了很好地总结,其中提到了一个比较有意思的观点,这里和大家分享下。先抛开few-shot learning的概念,我们先从几个基本的机器学习的概念进行分析。
期望风险最小化(expected risk minimization): 假设数据分布p(x,y)已知,其中x是特征,y是标签,在给定了特定损失函数L(⋅)的情况下,对于某个模型假设h∈H,我们期望机器学习算法能够最小化其期望风险,期望风险定义为:
R(h)=∫L(h(x),y)dp(x,y)=E[L(h(x),y)](1)
假如模型的参数集合为θ,那么我们的目标是:
θ=argθminR(h)(2)
经验风险最小化(empirical risk minimization): 实际上,数据分布p(x,y)通常不可知,那么我们就不能对其进行积分了,我们一般对该分布进行采样,得到若干个具有标签的样本,我们将其数量记为I,那么我们用采样结果对这个分布进行近似,因此,我们追求最小化经验风险,这里的经验(experience)的意思也就是指的是采样得到的数据集:
RI(h)=I1i=1∑IL(h(xi),yi)(3)
此处的经验风险(3)就可以近似期望风险(1)的近似进行最小化了(当然,在实践中通常需要加上正则项)。
我们进行以下三种表示:
h^=arghminR(h)(4)
h∗=argh∈HminR(h)(5)
hI=argh∈HminRI(h)(6)
其中(4)表示最小化期望风险得到的理论上最优的假设h^,(5)表示在指定的假设空间h∈H中最小化期望风险得到的约束最优假设h∗,(6)表示在指定的数据量为I的数据集上进行优化,并且在指定的假设空间h∈H下最小化经验风险得到的最优假设hI。
因为我们没办法知道p(x,y),因此我们没办法求得h^,那么作为近似,h∗是在假定了特定假设空间时候的近似,而hI是在特定的数据集和特定假设空间里面的近似。进行简单的代数变换,我们有(7):
E[R(hI)−R(h^)]=E[R(h∗)−R(h^)+R(hI)−R(h∗)]=E[R(h∗)−R(h^)]+E[R(hI)−R(h∗)](7)
其中用Eapp(H)=E[R(h∗)−R(h^)], Eest(H,I)=E[R(hI)−R(h∗)]。Eapp(H)表征了在期望损失下,在给定的假设空间H下的最优假设h∗能多接近最佳假设h^。而Eest(H,I)表示了在给定假设空间H下,对经验风险进行优化,而不是对期望风险进行优化造成的影响。不失特别的,我们用Dtrain表示整个训练集,有Dtrain={X,Y},X={x1,⋯,xn},Y={y1,⋯,yn}。
我们不难发现,整个深度模型算法的效果,最后取决于假设空间H和训练集中数据量I。换句话说,为了减少总损失,我们可以从以下几种角度进行考虑:
-
数据,也就是Dtrain。
-
模型,其决定了假设空间H。
-
算法,如何在指定的假设空间H中去搜索最佳假设以拟合Dtrain。
通常来说,如果Dtrain数据量很大,那么我们就有充足的监督信息,在指定的假设空间h∈H中,最小化hI得到的R(hI)就可以提供对R(h∗)的一个良好近似。然而,在few-shot learning (FSL)中,某些类别的样本数特别少,不足以支撑起对良好假设的一个近似。其经验风险项RI(h)和期望风险项R(h)可能有着很大的距离,从而导致假设hI过拟合。事实上,这个是在FSL中的核心问题,即是 经验风险最小假设hI变得不再可靠。整个过程如Fig 1所示,左图有着充足的样本,因此其经验风险最小假设hI和h∗相当接近,在H设计合理的情况下,可以更好地近似h^。而右图则不同,hI和h∗都比较远,跟别说和h^了。
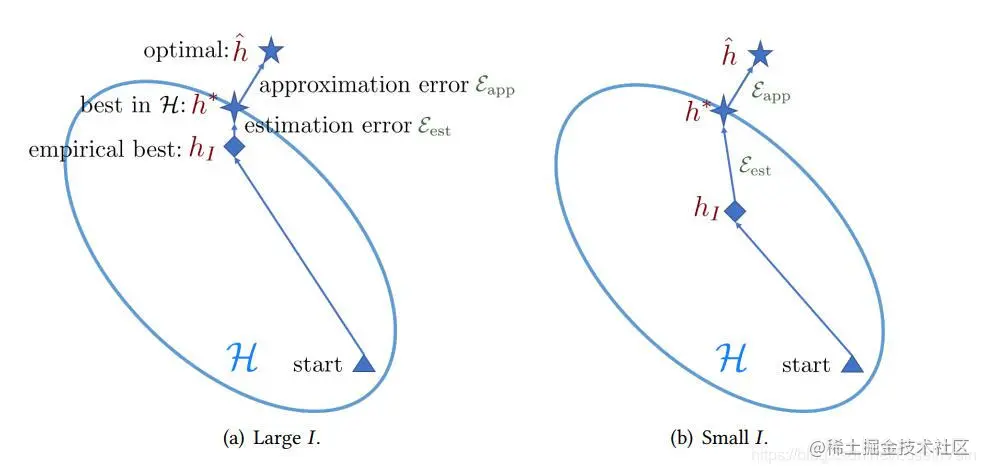
Fig 1. 样本充足和样本缺乏,在学习过程中结果的示意图。
为了解决在数据量缺少的情况下的不可靠的经验风险问题,也就是FSL问题,我们必须要引入先验知识,考虑到从数据,模型,算法这三个角度分别引入先验知识,现有的FSL工作可以被分为以下几种:
- 数据。在这类型方法中,我们利用先验知识去对Dtrain进行数据增广(data augment),从数据量I提高到I,通常I>>I。随后标准的机器学习算法就可以在已经增广过后的数据集上进行。因此,我们可以得到更为精确的假设hI。如Fig 2 (a)所示。
- 模型。这类型方法通过先验知识去约束了假设空间 H 的复杂度,得到了各位窄小的假设空间H。如Fig 2 (b) 所示。灰色区域已经通过先验知识给排除掉了,因此模型不会考虑往这些方向进行更新,因此,往往需要更少的数据就可以达到更为可靠的经验风险假设。
- 算法。这类型的方法考虑使用先验知识,指导如何对θ进行搜索。先验知识可以通过提供一个好的参数初始化,或者指导参数的更新步,进而影响参数搜索策略。对于后者来说,其导致的搜索更新步由先验知识和经验风险最小项共同决定。
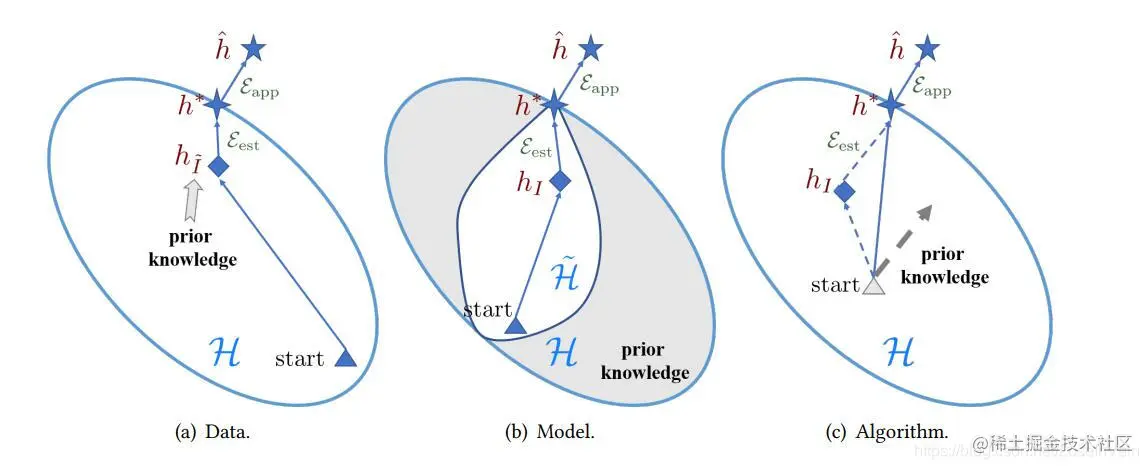
Fig 2. 分别从数据,模型和算法三个角度去引入先验知识。
Reference
[1]. Wang Y, Yao Q, Kwok J, et al. Generalizing from a few examples: A survey on few-shot learning[M]//arXiv: 1904.05046. 2019.


