

1.HTML语义
语义类标签的特点是视觉表现上互相都差不多,主要的区别在于它们表示了不同的语义,比如section、nav、p,这些都是语义类的标签。
语义类标签是纯文字的补充,比如标题、自然段、章节、列表,这些内容都是纯文字无法表达的,需要依靠语义标签代为表达。
- 语义类标签对开发者更为友好,使用语义类标签增强了可读性,即便是在没有 CSS 的时候,开发者也能够清晰地看出网页的结构,也更为便于团队的开发和维护。
- 除了对人类友好之外,语义类标签也十分适宜机器阅读。它的文字表现力丰富,更适合搜索引擎检索(SEO),也可以让搜索引擎爬虫更好地获取到更多有效信息,有效提升网页的搜索量,并且语义类还可以支持读屏软件,根据文章可以自动生成目录等等。
错误地使用语义标签,会给机器阅读造成混淆、增加嵌套,给 CSS 编写加重负担。
是否要语义化?---分场景
- 自然语言表达能力的补充;
ruby - 文章标题摘要;
hroup - 适合机器阅读的整体结构。
header、section、footer
static001.geekbang.org/static/time…
aside
article
hgroup, h1, h2
abbr
hr
p
strong
blockquote, q, cite
time
figure, figcaption
dfn
nav, ol, ul
pre, samp, code
补充
建议: 只用熟悉的语义标签,并且只在有把握的场景引入语义标签。这样,才能保证语义标签不被滥用,造成更多的问题。
2.HTML元信息类标签
3.链接
4.HTML替换型元素
替换型元素是把文件的内容引入,替换掉自身位置的一类标签。
script 标签是为数不多的既可以作为替换型标签,又可以不作为替换型标签的元素。
<script type="text/javascript">
console.log("Hello world!");
</script>
<script type="text/javascript" src="my.js"></script>
这个例子中,展示了两种 script 标签的写法,一种是直接把脚本代码写在 script 标签之间,另一种是把代码放到独立的 js 文件中,用 src 属性引入。
凡是替换型元素,都是使用 src 属性来引用文件的
style 标签并非替换型元素,不能使用 src 属性,这样,用 link 标签引入 CSS 文件,当然就是用 href 标签啦。
5.HTML语言:DTD到底是什么?
HTML 作为 SGML 的子集,它遵循 SGML 的基本语法:包括标签、转义等
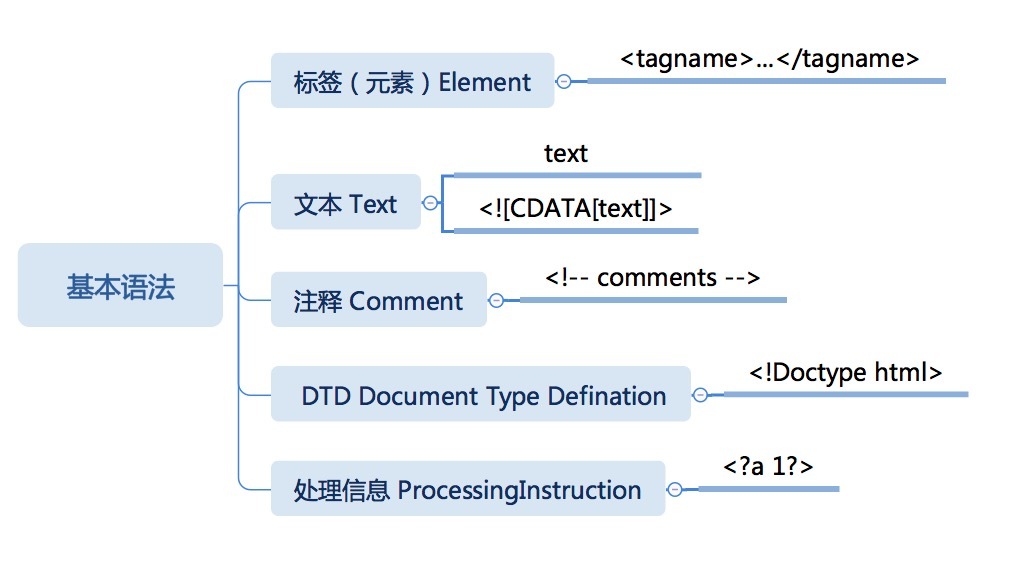
- 开始标签:<tagname>
- 带属性的开始标签: <tagname attributename="attributevalue">
- 结束标签:</tagname>
- 自闭合标签:<tagname />
HTML 中开始标签的标签名称只能使用英文字母。
一定需要转义的有下面几种。
- 无引号属性:<tab> <LF> <FF> <SPACE> &五种字符。
- 单引号属性:' &两种字符。
- 双引号属性:" &两种字符。
文本语法
HTML 中,规定了两种文本语法,一种是普通的文本节点,另一种是 CDATA 文本节点。
文本节点看似是普通的文本,但是,其中有两种字符是必须做转义的:< 和 &。
如果从某处拷贝了一段文本,里面包含了大量的 < 和 &,这时候,就轮到我们的 CDATA 节点出场了。
CDATA 也是一种文本,它存在的意义是语法上的意义:在 CDATA 节点内,不需要考虑多数的转义情况。
CDATA 内,只有字符组合]]>需要处理,这里不能使用转义,只能拆成两个 CDATA 节点。
注释语法
HTML 注释语法以<!--开头,以-->结尾,注释的内容非常自由,除了-->都没有问题。
如果注释的内容一定要出现 -->,我们可以拆成多个注释节点。
DTD 语法(文档类型定义)
SGML 的 DTD 语法十分复杂,但是对 HTML 来说,其实 DTD 的选项是有限的,浏览器在解析 DTD 时,把它当做几种字符串之一
ProcessingInstruction 语法(处理信息)
ProcessingInstruction 多数情况下,是给机器看的。HTML 中规定了可以有ProcessingInstruction,但是并没有规定它的具体内容,所以可以把它视为一种保留的扩展机制。对浏览器而言,ProcessingInstruction 的作用类似于注释。
ProcessingInstruction 包含两个部分,紧挨着第一个问号后,空格前的部分被称为“目标”,这个目标一般表示处理 ProcessingInstruction 的程序名
剩余部分是它的文本信息,没有任何格式上的约定,完全由文档编写者和处理程序的编写者约定
DTD
现在我们来讲一下 DTD,DTD 的全称是 Document Type Defination,也就是文档类型定义。SGML 用 DTD 来定义每一种文档类型,HTML 属于 SGML,在 HTML5 出现之前,HTML 都是使用符合 SGML 规定的 DTD。
HTML4.01 有三种 DTD。分别是严格模式、过渡模式和 frameset 模式。
- 严格模式的 DTD 规定了 HTML4.01 中需要的标签。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> - 过渡模式的 DTD 除了 html4.01,还包含了一些被贬斥的标签,这些标签已经不再推荐使用了,但是过渡模式中仍保留了它们。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd">
文本实体
所谓文本实体定义就是类似: <, ,>,&
DTD 在 HTML4.01 和之前都非常的复杂,到了 HTML5,抛弃了 SGML 兼容,变成简单的。
6.HTML·ARIA
ARIA 全称为 Accessible Rich Internet Applications,它表现为一组属性,是用于可访问性的一份标准。关于可访问性,它被提到最多的,就是它可以为视觉障碍用户服务,但是,这是一个误解。
实际上,可访问性其实是一个相当大的课题,它的定义包含了各种设备访问、各种环境、各种人群访问的友好性。不单单是永久性的残障人士需要用到可访问性,健康的人也可能在特定时刻处于需要可访问性的环境。
ARIA 系统还提供了一系列 ARIA 属性给 checkbox 这个 role,这意味着,可以通过 HTML 属性变化来理解这个 JavaScript 组件的状态,读屏软件等三方客户端,就可以理解 UI 变化,这正是 ARIA 标准的意义。
role 的定义是一个树形的继承关系
-
Widget 角色
按照继承关系的列表和简要说明:
widget 同时还会带来对应的 ARIA 属性,比如,Checkbox 角色,会带来两个属性:
- aria-checked 表示复选框是否已经被选中;
- aria-labelledby 表示复选框对应的文字。 而 Button 角色,则会带来另外两个属性:
- aria-pressed 按钮是否已经被按下;
- aria-expanded 按钮控制的目标是否已经被展开。
-
structure 角色
 注:separator 在允许焦点时属于组件,在不允许焦点时属于文档结构。
注:separator 在允许焦点时属于组件,在不允许焦点时属于文档结构。Landmark 角色直接翻译是地标,它是 ARIA 标准中总结的 Web 网页中最常见的 8 个结构,Landmark 角色实际上是 section 的子类,这些角色在生成页面摘要时有很大可能性需要被保留,它们是:
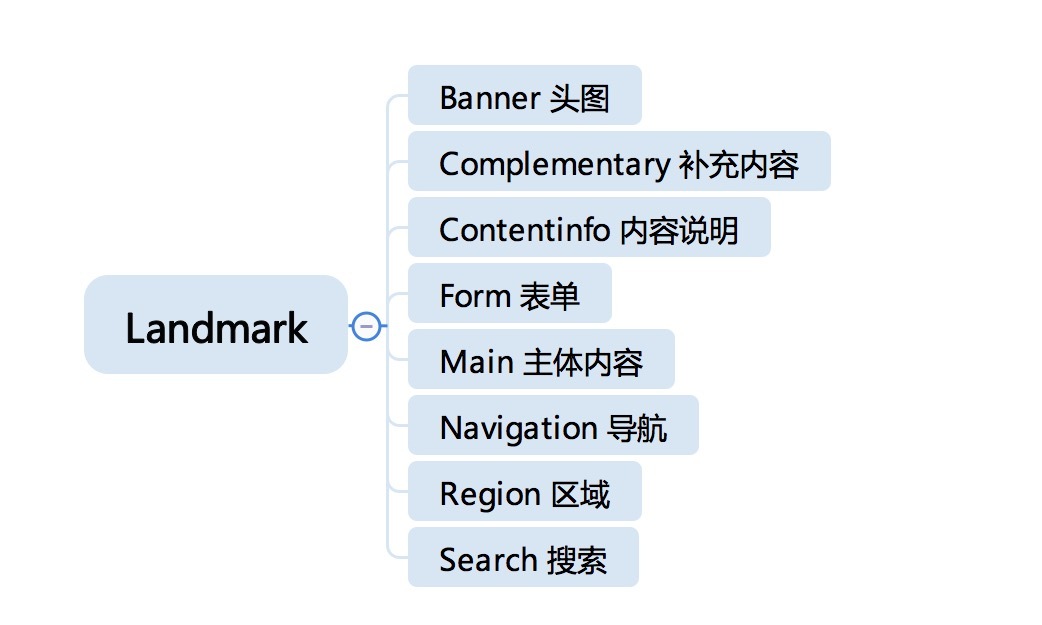
-
window 角色 在我们的网页中,有些元素表示“新窗口”,这时候,会用到 window 角色。window 系角色非常少,只有三个角色:
-
window
- dialog
- alertdialog
- dialog
dialog 可能会产生“焦点陷阱”,也就是说,当这样的角色被激活时,焦点无法离开这个区域。
总结
- Widget 角色:主要是各种可交互的控件。
- 结构角色:文档的结构。
- 窗体角色:弹出的窗体。
7.浏览器DOM
文档对象模型:用来描述文档,这里的文档,是特指 HTML 文档(也用于 XML 文档,但是本课不讨论 XML)。同时它又是一个“对象模型”,这意味着它使用的是对象这样的概念来描述 HTML 文档。
DOM API 大致会包含 4 个部分。
- 节点:DOM 树形结构中的节点相关 API。
- 事件:触发和监听事件相关 API。
- Range:操作文字范围相关 API。
- 遍历:遍历 DOM 需要的 API。
节点
DOM 的树形结构所有的节点有统一的接口 Node,继承关系的节点的类型。
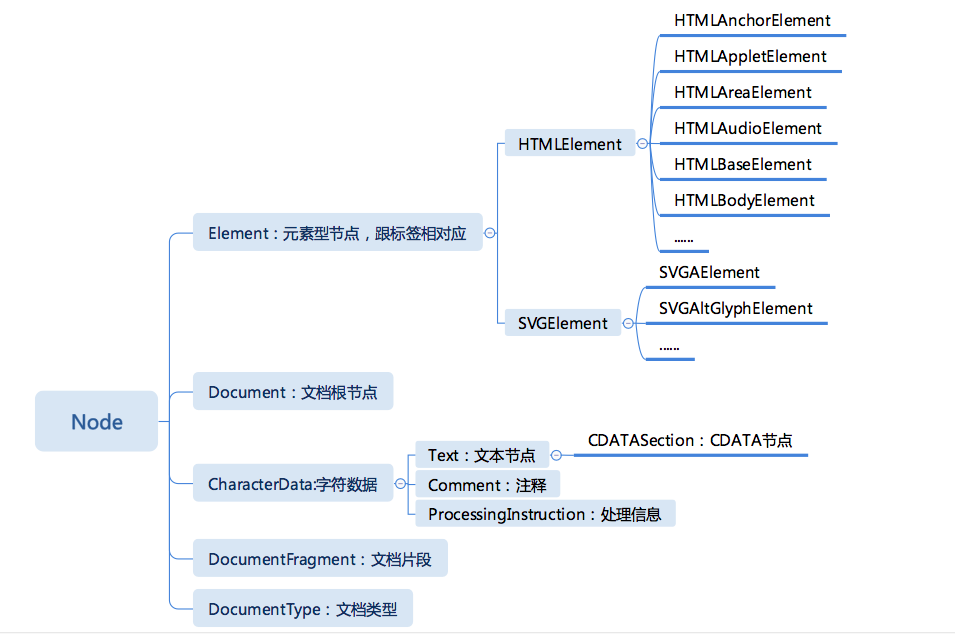
node
Node 是 DOM 树继承关系的根节点,它定义了 DOM 节点在 DOM 树上的操作,首先,Node 提供了一组属性,来表示它在 DOM 树中的关系,它们是:
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
从命名上,可以很清晰地看出,这一组属性提供了前、后、父、子关系,有了这几个属性,可以很方便地根据相对位置获取元素。当然,Node 中也提供了操作 DOM 树的 API,主要有下面几种。
- appendChild 给一个元素追加一个子元素:当前元素.appendChild(子元素);
- insertBefore 在指定的元素前插入新的元素:父级.insertBefore(‘新元素’,’当前元素’);
- removeChild 删除节点(只能在父级下进行操作):父级.removeChild(‘要删除的节点’);
- replaceChild 替换节点:父级.replaceChild(替换的元素,被替换的元素);
node高级 API
- compareDocumentPosition 是一个用于比较两个节点中关系的函数。
- contains 检查一个节点是否包含另一个节点的函数。
- isEqualNode 检查两个节点是否完全相同。
- isSameNode 检查两个节点是否是同一个节点,实际上在 JavaScript 中可以用“===”。
- cloneNode 复制一个节点,如果传入参数 true,则会连同子元素做深拷贝。
DOM 标准规定了节点必须从文档的 create 方法创建出来,不能够使用原生的 JavaScript 的 new 运算。于是 document 对象有这些方法。用于创建对应的节点类型:
- createElement
- createTextNode
- createCDATASection
- createComment
- createProcessingInstruction
- createDocumentFragment
- createDocumentType
Element 与 Attribute
我们可以把元素的 Attribute 当作字符串来看待,这样就有以下的 API:
- getAttribute
- setAttribute
- removeAttribute
- hasAttribute
如果追求极致的性能,还可以把 Attribute 当作节点:
- getAttributeNode
- setAttributeNode
此外,如果像property 一样的访问 attribute,还可以使用 attributes 对象,比如 document.body.attributes.class = “a” 等效于 document.body.setAttribute(“class”, “a”)。
查找元素
- querySelector
- querySelectorAll
- getElementById
- getElementsByName
- getElementsByTagName
- getElementsByClassName
需要注意,getElementById、getElementsByName、getElementsByTagName、getElementsByClassName,这几个 API 的性能高于 querySelector。
遍历
前面已经提到过,通过 Node 的相关属性,我们可以用 JavaScript 遍历整个树。实际上,DOM API 中还提供了 NodeIterator 和 TreeWalker 来遍历树。
比起直接用属性来遍历,NodeIterator 和 TreeWalker 提供了过滤功能,还可以把属性节点也包含在遍历之内。
NodeIterator 的基本用法示例如下:
var iterator = document.createNodeIterator(document.body, NodeFilter.SHOW_TEXT | NodeFilter.SHOW_COMMENT, null, false);
var node;
while(node = iterator.nextNode())
{
console.log(node);
}
TreeWalker 的用法:
var walker = document.createTreeWalker(document.body, NodeFilter.SHOW_ELEMENT, null, false)
var node;
while(node = walker.nextNode())
{
if(node.tagName === "p")
node.nextSibling();
console.log(node);
}
比起 NodeIterator,TreeWalker 多了在 DOM 树上自由移动当前节点的能力,一般来说,这种 API 用于“跳过”某些节点,或者重复遍历某些节点。
Range
Range API 是一个比较专业的领域,如果不做富文本编辑类的业务,不需要太深入
Range API 表示一个 HTML 上的范围,这个范围是以文字为最小单位的,所以 Range 不一定包含完整的节点,它可能是 Text 节点中的一段,也可以是头尾两个 Text 的一部分加上中间的元素
