

一、概述
HashSet是Java集合Set的一个实现类,此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素 ,并且,HashSet不是线程安全的。
二、基础属性和方法
基础属性
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable{
//使用 HashMap 的 key 保存 HashSet 中所有元素
private transient HashMap<E,Object> map;
// 定义一个静态的 Object 对象作为 HashMap 的 value
private static final Object PRESENT = new Object();
构造方法
// 内部初始化HashMap
public HashSet() {
map = new HashMap<>();
}
//将一个集合添加到HashMap中
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
// 初始化一个HashMap,指定容量和加载因子
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
// 初始化一个HashMap,指定容量
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
由HashSet的基础属性和构造方法可以看出,HashSet本质还是在内部维护一个HashMap对象,将所有的数据都交给HashMap进行处理
三、重要方法
add(E e)
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
将指定元素存入HashSet,内部实现就是将指定元素作为key,用常量对象PRESENT作为value存入HashMap
remove(Object o)
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
从集合中删除指定的元素,如果集合包含指定的元素,则返回true。同样调用的HashMap的remove方法
contains(Object o)
public boolean contains(Object o) {
return map.containsKey(o);
}
contains方法的目的是检查给定HashSet中是否存在元素。如果找到该元素,则返回true,否则返回false。每当将对象传递给此方法时,都会计算哈希值。然后,解析并遍历相应的存储块位置。
clear() clear() 用于清空HashSet中的数据,底层是采用HashMap的clar()方法,原理是便利HashMap中的桶数组,将桶中的每个位置置null
public void clear() {
map.clear();
}
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}
iterator() 遍历HashSet(),在内部是遍历的HashMap的keySet
四、HashSet总结
总的来说,HashSet只是在HashMap的基础上包装了一层,基本都使用的HashMap的方法。总结一下HashSet的特点吧:
- 无序的
- 不允许元素重复
- 最多只有一个null值
- 不是同步的,不安全
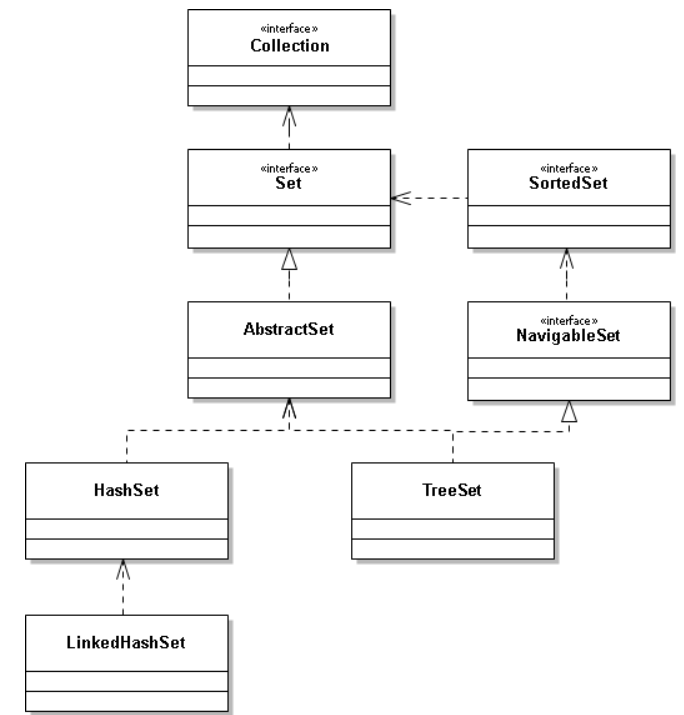
五、扩展LinkedHashSet和TreeSet
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}
LinkedHashSet是HashSet的子类,通过源码发现,它竟然也是一个空壳,构造方法都调用HashSet的一个default构造方法 通过HashSet的这个default构造方法可知,LinkedHashSet也是对LinkedHashMap包装了一层。。。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
而TreeSet也是基于TreeMap实现的,就不在这里专门讲了。
