

我们已经大概知道sqlSession的创建过程和sqlSession的sql查询的原理,实际上,SqlSession的执行过程就是通过Executor、StatementHandler、ParameterHandler、ResultSetHandler这四个对象来完成对数据库的操作和返回结果的
Executor
它是一个执行器,真正进行java与数据库交互的对象,实际干活的。
public interface Executor {
ResultHandler NO_RESULT_HANDLER = null;
int update(MappedStatement ms, Object parameter) throws SQLException;
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException;
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;
<E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException;
List<BatchResult> flushStatements() throws SQLException;
void commit(boolean required) throws SQLException;
void rollback(boolean required) throws SQLException;
CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql);
boolean isCached(MappedStatement ms, CacheKey key);
void clearLocalCache();
void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType);
Transaction getTransaction();
void close(boolean forceRollback);
boolean isClosed();
void setExecutorWrapper(Executor executor);
}
根据方法名和参数,我们大概可以知道每个方法的作用是干嘛的
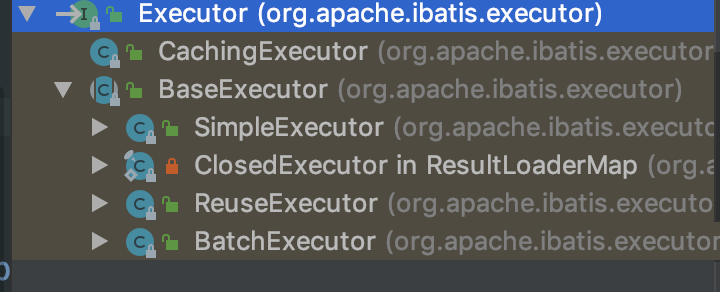
Executor分类
Executor分成两大类:
-
BaseExecutor
- SimpleExecutor:每执行一次update或select,就开启一个 Statement对象,用完立刻关闭Statement对象。(可以是Statement或PrepareStatement对象)
- ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map<String, Statement>内,供下一次使用。(可以是Statement或PrepareStatement对象)
- BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理的;BatchExecutor相当于维护了多个桶,每个桶里都装了很多属于自己的SQL,就像苹果蓝里装了很多苹果,番茄蓝里装了很多番茄,最后,再统一倒进仓库。(可以是Statement或PrepareStatement对象)
-
CachingExecutor
- 先从缓存中获取查询结果,存在就返回,不存在,再委托给Executor delegate去数据库取,delegate可以是上面任一的SimpleExecutor、ReuseExecutor、BatchExecutor。
Executor的创建
现在我们再来回顾下SqlSession的执行原理 Executor是跟SqlSession绑定在一起的,每一个SqlSession都拥有一个新的Executor对象由Configuration创建 在DefaultSqlSessionFactory类中,也就是实际创建sqlSession的方法---openSessionFromDataSource方法中 查看源码
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
其中ExecutorType execType是存在默认值的,也就是在Configuration中,已经默认定义了
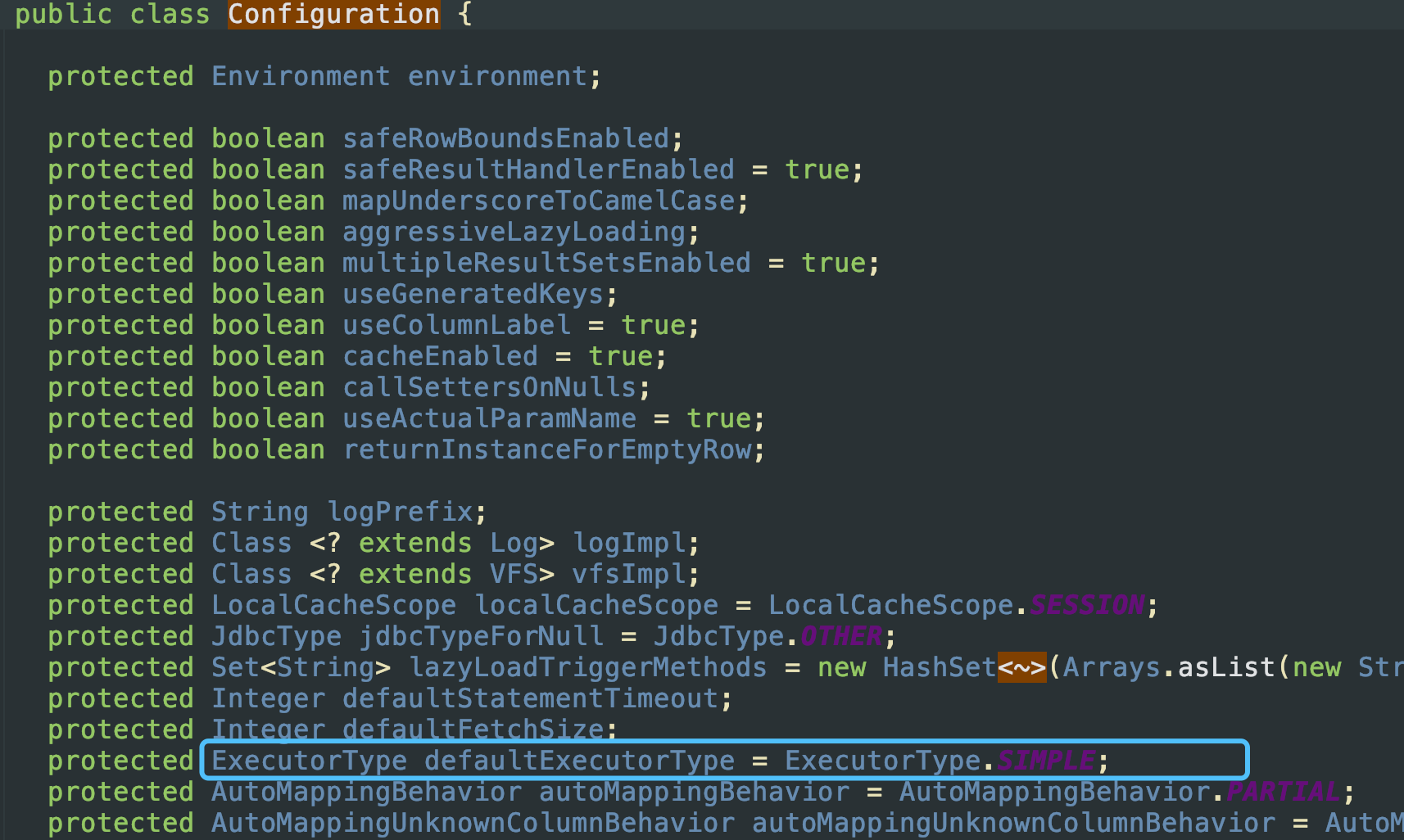
public enum ExecutorType {
SIMPLE, REUSE, BATCH
}
正和BaseExecutor中的SimpleExecutor,ReuseExecutor,BatchExecutor类对应 回到方法
final Executor executor = configuration.newExecutor(tx, execType);
进入newExecutor
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
经过简单判断,可以知道最后返回SimpleExecutor对象 到了现在,executor创建成功,我们看下它在哪里运行的把
Executor执行
通过对sqlSession执行sql的原理了解,我们知道Executor的使用是在具体使用sql语句时,开始使用Executor的方法 这里举selectList方法把
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
进入executor.query方法
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
继续进入query方法,直到进入我们创建的SimpleExecutor对象中的doQuery方法
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
好!!!现在第二个关键对象StatementHandler出现了
StatementHandler
它负责处理Mybatis与JDBC之间Statement的交互,而JDBC中的Statement,我们在学习JDBC的时候就了解过,就是负责与数据库进行交互的对象,和Executor一样,由configuration创建
public interface StatementHandler {
Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException;
void parameterize(Statement statement) throws SQLException;
void batch(Statement statement) throws SQLException;
int update(Statement statement) throws SQLException;
<E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException;
<E> Cursor<E> queryCursor(Statement statement) throws SQLException;
BoundSql getBoundSql();
ParameterHandler getParameterHandler();
StatementHandler分类
StatementHandler接口的实现大致有四个,其中三个实现类都是和JDBC中的Statement相对应的
- SimpleStatementHandler,这个很简单了,就是对应我们JDBC中常用的Statement接口,用于简单SQL的处理;
- PreparedStatementHandler,这个对应JDBC中的PreparedStatement,预编译SQL的接口;
- CallableStatementHandler,这个对应JDBC中CallableStatement,用于执行存储过程相关的接口;
- RoutingStatementHandler,这个接口是以上三个接口的路由,没有实际操作,只是负责上面三个StatementHandler的创建及调用。
StatementHandler创建
回到doQuery方法代码
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
wrapper就是我们的Executor ms简而言之是就是我们在xml配置的namespace中的id的内容 parameter是我们的输入值 rowBounds是分页 resultHandler等下讲(其实它目前在这里的值为null) boundSql就是实际调用的sql语句及对应的参数相关的对象
进入newStatementHandler方法
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
正如StatementHandler分类中的RoutingStatementHandler接口再重新解释下
- 这个接口是以上三个接口的路由,没有实际操作,只是负责上面三个StatementHandler的创建及调用
进入方法new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
根据之前的分析,ms就是MappedStatement对象 很明显根据statementType的类型来判断是哪一种StatementHandler的实现,并且RoutingStatementHandler维护了一个delegate对象,通过delegate对象来实现对实际Handler对象的调用。其实,咱们的statementType在创建时,和Executor一样,被默认设置过,嘿嘿嘿,默认是PREPARED 下面来简单捋一捋MappedStatement创建过程把
MappedStatement
回头看,找到第一个MappedStatement出现的地方 嗯,在DefaultSqlSession的selectList方法中
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
开挖!进入
public MappedStatement getMappedStatement(String id) {
return this.getMappedStatement(id, true);
}
继续挖
public MappedStatement getMappedStatement(String id, boolean validateIncompleteStatements) {
if (validateIncompleteStatements) {
buildAllStatements();
}
return mappedStatements.get(id);
}
根据validateIncompleteStatements传参,是true,继续挖
if (!incompleteResultMaps.isEmpty()) {
synchronized (incompleteResultMaps) {
// This always throws a BuilderException.
incompleteResultMaps.iterator().next().resolve();
}
}
if (!incompleteCacheRefs.isEmpty()) {
synchronized (incompleteCacheRefs) {
// This always throws a BuilderException.
incompleteCacheRefs.iterator().next().resolveCacheRef();
}
}
if (!incompleteStatements.isEmpty()) {
synchronized (incompleteStatements) {
// This always throws a BuilderException.
incompleteStatements.iterator().next().parseStatementNode();
}
}
if (!incompleteMethods.isEmpty()) {
synchronized (incompleteMethods) {
// This always throws a BuilderException.
incompleteMethods.iterator().next().resolve();
}
}
}
找和MappedStatement有关的方法,定位到 incompleteStatements.iterator().next().parseStatementNode(); 迭代,最后parseStatementNode()方法,进去 进去后,发现一大堆赋值语句,最后定位到最后一句 builderAssistant.addMappedStatement 进去瞅瞅
MappedStatement.Builder statementBuilder = new MappedStatement.Builder
找到以上代码,嗯又是Builder,进去把
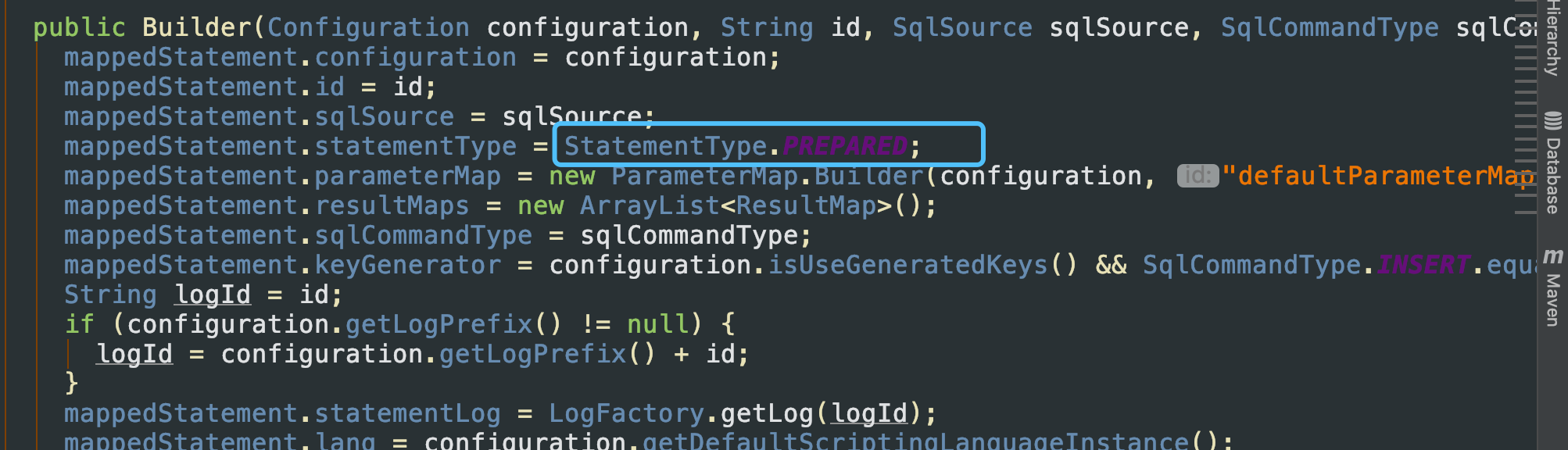
public enum StatementType {
STATEMENT, PREPARED, CALLABLE
}
好了,现在StatementHandler对象我们有了,回到doQuery方法
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
进入下一个方法
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
继续进入handler.prepare方法
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
statement = instantiateStatement(connection);
setStatementTimeout(statement, transactionTimeout);
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
代码不多,继续进入,因为我们知道了我们的statement是PreparedStatement,所以我们直接看PreparedStatementHandler类中的实现把
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
return connection.prepareStatement(sql);
}
}
不多说了,就是通过Connection的方法来获取Statement实例对象而已,至此,我们创建好了StatementHandler具体实现对象 现在回到我们的prepareStatement方法
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
进入handler.parameterize(stmt);方法
public void parameterize(Statement statement) throws SQLException {
parameterHandler.setParameters((PreparedStatement) statement);
}
我们的第三个对象出现了parameterHandler
parameterHandler
ParameterHandler是用来设置参数规则的
public interface ParameterHandler {
Object getParameterObject();
void setParameters(PreparedStatement ps)
throws SQLException;
}
不难猜出,它的两个方法分别为get输入参数和set输入参数 他有且只有一个实现类DefaultParameterHandler
DefaultParameterHandler
咱们主要看它的set方法,因为我们parameterize方法中,调用的就是setParameters方法
public void setParameters(PreparedStatement ps) throws SQLException {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
// parameterMappings 是对#{} 里给出的参数信息的封装,即这个SQL是个参数化SQL(SQL语句中带占位符?)时会存在
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
//如果是参数化SQL,便要设置参数
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
//如果参数的类型不是OUT类型,CallableStatementHandler会用到
//因为存储过程才存在输出参数,所以当参数不是输出参数的时候,就需要设置
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
//在本次查询中,对应的不是一个Bean,对应的是一个additionalParameters Map对象,所以这里的property不是Bean的属性,而是经过封装的Key(可以通过Key找到对应的Value,该Value就是我们要找的值)
//如果是Bean 则通过属性的反射来得到Value
String propertyName = parameterMapping.getProperty();
//如果propertyName是additionalParameters中的key
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
//通过Key来得到Map中的Value
value = boundSql.getAdditionalParameter(propertyName);
}//如果不是additionalParameters中的Key,而且传入参数是null,那value就为null
else if (parameterObject == null) {
value = null;
}
//如果在typeHandlerRegistry中已经注册了这个参数的Class对象,即他是Primitive类型或者是String ByteArray 等等 26个类型 也就是说不是JavaBean 也不是Map List类型时。value直接等于Method传进来的参数
else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
}
//否则就是Map(Method穿进行的原始参数是List类型或者是Array类型时,这时已经被封装成了Map类型了)类型或者是Bean 通过封装的MataObject对象,用propertyName得到相应的Value,Bean通过反射得到,Map类型则是通过Key得到Value
else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
//在通过SqlSource的parse方法得到paramterMappings的具体实现中,我们会得到parameterMapping的TypeHandler
//本次查询中TypeHandler均为IntegerTypeHandler
TypeHandler typeHandler = parameterMapping.getTypeHandler();
//得到相应parameterMapping的JdbcType,如果没有在#{}中显式的指定JdbcType,则为null
JdbcType jdbcType = parameterMapping.getJdbcType();
//如果得到的value为null并且jdbcType也是null的时候,jdbcType就会成为configuration.getJdbcTypeForNull(); 即OTHER,所以我们在编写Mapper配置文件的Insert或者Update类型的SqlMapper时,如果某个#{propertyName}对应的Value是null的话,插入数据库是会报错的,
// 因为此时的JdbcType是Other,执行setNull时会报错,
//java.sql.SQLException: 无效的列类型: 1111
//1111 就是OTHER对应的sqlType
// 所以Value为null的情况下,我们需要指定JdbcType
if (value == null && jdbcType == null) jdbcType = configuration.getJdbcTypeForNull();
//这一行实现了具体的ps.set***
typeHandler.setParameter(ps, i + 1, value, jdbcType);
}
}
}
}
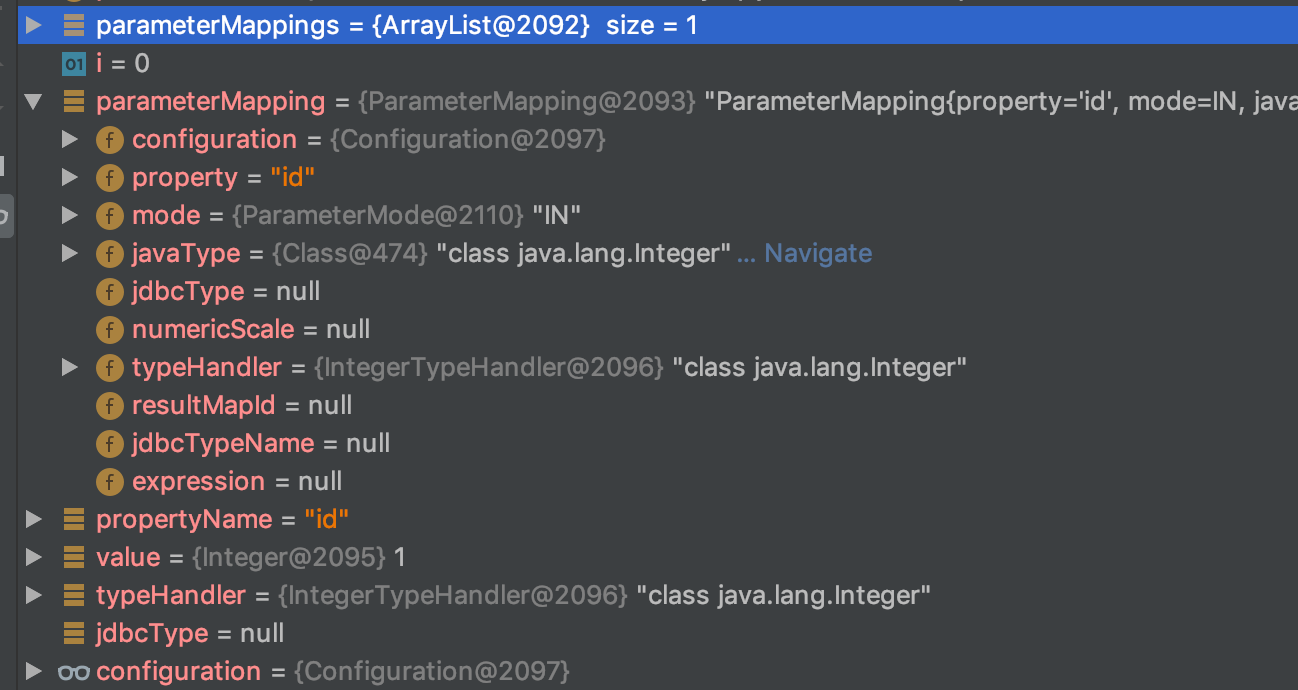
public void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException {
if (parameter == null) {
if (jdbcType == null) {
throw new TypeException("JDBC requires that the JdbcType must be specified for all nullable parameters.");
}
try {
ps.setNull(i, jdbcType.TYPE_CODE);
} catch (SQLException e) {
throw new TypeException("Error setting null for parameter #" + i + " with JdbcType " + jdbcType + " . " +
"Try setting a different JdbcType for this parameter or a different jdbcTypeForNull configuration property. " +
"Cause: " + e, e);
}
} else {
try {
setNonNullParameter(ps, i, parameter, jdbcType);
} catch (Exception e) {
throw new TypeException("Error setting non null for parameter #" + i + " with JdbcType " + jdbcType + " . " +
"Try setting a different JdbcType for this parameter or a different configuration property. " +
"Cause: " + e, e);
}
}
}
大部分都是判断null的情况,直接进入setNonNullParameter,它是一个抽象方法,具体实现在子类,我们在这里打个断点进入子类具体实现
public void setNonNullParameter(PreparedStatement ps, int i, Integer parameter, JdbcType jdbcType)
throws SQLException {
ps.setInt(i, parameter);
}
很简单,就是一个PreparedStatement的具体方法,也就是给我们之前的?赋值 到这里,赋值操作就完成了 继续回到我们SimpleExecutor的doQuery方法
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
打个断点看下stmt的值
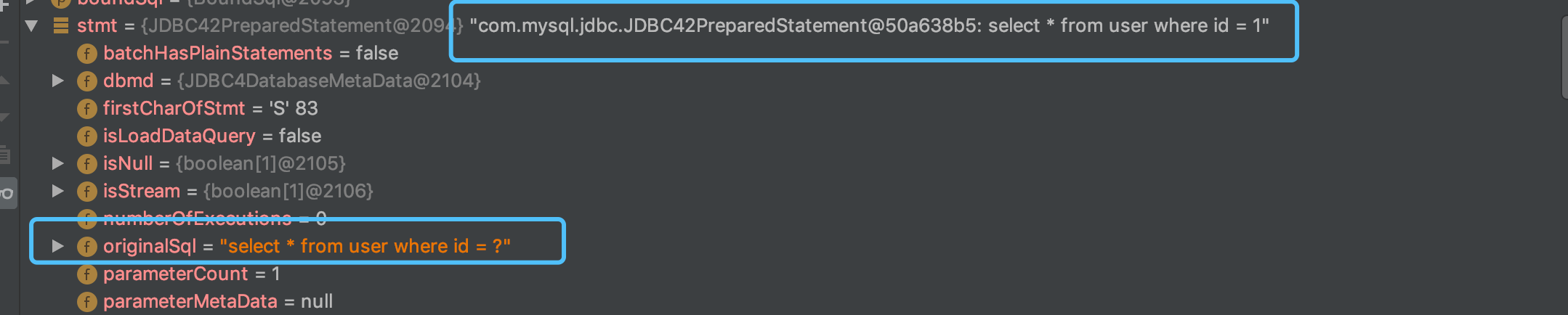
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.<E> handleResultSets(ps);
}
现在,我们的第三个对象也就是之前默默无闻的resultSetHandler开始干活了
ResultSetHandler
负责将数据库结果集转换为Java对象集合。
public interface ResultSetHandler {
<E> List<E> handleResultSets(Statement stmt) throws SQLException;
<E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException;
void handleOutputParameters(CallableStatement cs) throws SQLException;
}
根据方法不难判断,第一个方法是返回list结果集合,第二个是封装成Cursor对象
ResultSetHandler分类
其实它有且只有一个实现类DefaultResultSetHandler。

handleResultSets
具体代码:
/**
* 处理结果集的方法,在StatementHandler里面的query方法会调用该方法
* PS:该方法可以处理Statement,PreparedStatement和存储过程的CallableStatement返回的结果集。而CallableStatement是支持返回多结
* 果集的,普通查询一般是单个结果集
* */
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
//1.保存结果集对象。普通的查询,实际就一个ResultSet,也就是说,multipleResults最多就一个元素。在多ResultSet的
//结果集合一般在存储过程出现,此时每个ResultSet对应一个Object对象,每个Object是 List<Object>对象。
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
//2.Statement可能返回多个结果集对象,先处理第一个结果集,封装成ResultSetWrapper对象
ResultSetWrapper rsw = getFirstResultSet(stmt);
//3.将结果集转换需要知道转换规则,而记录和JavaBean的转换规则都在resultMap里面,这里获取resultMap,注意获取
//的是全部的resultMap,是一个list,但是对于普通查询,resultMaps只有一个元素(普通查询一个响应只有一个ResultSet,存储过程可能有多个)
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
//4.结果集和转换规则均不能为空,否则抛异常
validateResultMapsCount(rsw, resultMapCount);
//5.一个一个处理(普通查询其实就处理一次)
while (rsw != null && resultMapCount > resultSetCount) {
//6.获取当前结果集对应的resultMap(注意前面是全部的resultMap,这里是获取到自己需要的,普通查询就是获取一个,一般也就只有一个)
ResultMap resultMap = resultMaps.get(resultSetCount);
//7.根据规则(resultMap)处理 ResultSet,将结果集转换为Object列表,并保存到multipleResults
//这是获取结果集的最核心的方法步骤
handleResultSet(rsw, resultMap, multipleResults, null);
//8.获取下一个结果集
rsw = getNextResultSet(stmt);
//9.清空nestedResultObjects对象
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
//10.获取多结果集。一般出现在存储过程中,不分析了...
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
//11.如果是multipleResults只有一个元素,则取首元素返回(collapseSingleResultList中会判断如果只有一个元素就获取并返回)
return collapseSingleResultList(multipleResults);
}
其核心代码为
handleResultSet(rsw, resultMap, multipleResults, null);
handleResultSet
进入发现代码
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
//1.非存储过程的情况,parentMapping为null。handleResultSets方法的第一个while循环传参就是null
if (parentMapping != null) {
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
//1.2如果没有自定义的resultHandler,则使用默认的DefaultResultHandler对象
if (resultHandler == null) {
//1.3创建DefaultResultHandler对象
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
//1.4(核心方法)处理ResultSet返回的每一行Row,里面会循环处理全部的结果集
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
//1.5将defaultResultHandler的处理结果,添加到multipleResults中
multipleResults.add(defaultResultHandler.getResultList());
} else {
//1.6 和1.4一样,处理每一行,里面会循环处理全部的结果集
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// issue #228 (close resultsets)
//关闭ResultSet对象
closeResultSet(rsw.getResultSet());
}
}
再往下就是对结果和对象关系进行一一映射了
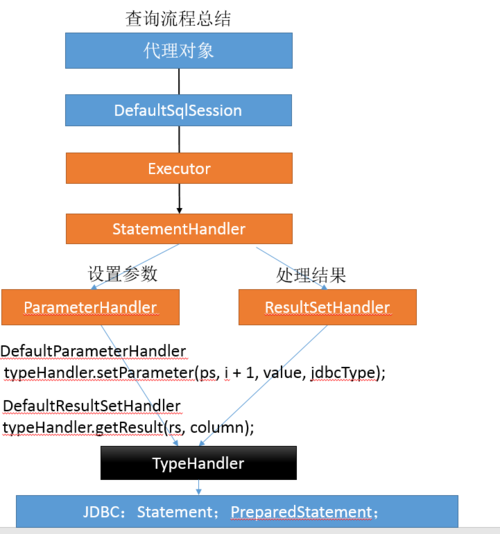
总结
- 内部我们是调用我们的四大对象之一Executor来进行实际的增删改查的,然后就是对我们传入参数进行两次包装的过程,
- 紧接着我们创建了四大对象之二StatementHandler,我们通过StatementHandler来执行预编译,插入值,执行sql,封装结果这四大步骤。
- 而我们可以更加具体的来对StatementHandler进行一个分工,我们StatementHandler执行了预编译,相当于创建出来我们的PrepareStatment对象来。紧接着使用我们的四大对象之三parameterHandler来进行一个设置参数的工作,然后StatementHandler进行stm.execute();将我们设置的参数传入数据库,
- 最后使用四大对象的最后一个resultSetHandler对象来完成映射处理封装结果的作用。
- 而一有个打零工的Handler默默的做着类型转换和参数解析的工作,他就是TypeHandler,parameterHandler和resultSetHandler的参数设置和处理结果都需要它的帮助。
Mybatis源码(一)---SqlSessionFactoryBuilder(获得配置文件)
Mybatis源码(二)---parseConfiguration读取XML文件
Mybatis源码(三)---SqlSession完成sql查询
Mybatis源码(四)---SqlSession完成动态代理
个人拙见,感谢您的阅读。欢迎讨论,个人博客
