

全文链接:
- 字符编码(一:术语及字符编码由来)
- 字符编码(二:简体汉字编码与 ANSI 编码 )
- 字符编码(三:Unicode 编码系统与字节序)
- 字符编码(四:UTF 系列编码详解)
- 字符编码(五:网络传输编码 Base64、百分号编码)
1.11 网络传输编码
下文为本人补充,有误导错误的地方,欢迎拍砖。网络传输编码方面只涉及 Base64、百分号编码等前端常用地方,其他咱也不明白。
电子邮件的限制
古代数据通信主要以声光为载体,例如旗语和击鼓等,只能在可视或可听的短距离内传输,可靠性差、速度慢、保密性低。当电替代声光作为信息载体后,远距离和大数据量的快速信息传递才得以实现。首先是可传送少量文字信息的电报网的出现。19 世纪 30 年代,由于铁路迅速发展,迫切需要一种不受天气影响并且比火车跑得快的通信工具,这是促进电报产生的社会基础。1838 年,美国人塞缪尔·莫尔斯(Samuel Finley Breese Morse)发明了莫尔斯电码,以点和划形式传递离散的文本信息,被认为是现代数据通信的原型,开启了电子通信时代的新纪元。电报网通信方式简单,内容单一,可传送的信息量也少,之后发明了电话网传真技术。
20 世纪 60 年代,随着计算机日益广泛的应用,产生了计算机之间大规模数据通信的需求。最初的计算机通信都是通过拨号联网,基于电话网和调制解调器实现的。传输速度低、可靠性差,效率低,价格高(大容量廉价的光通信技术当时还没有出现)。这种基于电话网的、通过调制解调器方式的数据通信模式(类似电话网的传真模式),根本无法满足未来计算机大规模组网和突发式、多速率通信的需求。
在 1969 年 ― ARPANET 网美国兰德公司(Rand)的 Paul Baran,英国国家物理实验室(NPL)的 Donald Davies 和麻省理工学院的博士生 Leonard Kleinrock,从不同的角度提出了目前被称为 “包交换 ”的网络技术。包交换技术将用户传送的数据分成若干比较短的、标准化的“分组”(或称包)进行交换和传输,每个分组由用户数据以及必要的地址和控制信息组成,从而保证网络能够将数据传递到目的地。
1971 年,ARPANET 网的创建者希望能有一种简便的相互交流方式,于是出现了 一种允许网络上不同主机间进行信息交换的系统(即电子邮件),而不只是允许同一台机器上的不同用户间交换信息。 发明者是在一家公司(现为 BBN 技术公司)工作的Raymond Tomlinson,他引入了 “@” 这个符号来区分用户和网络主机。后来,Tomlinson 先生说在两台计算机之间端对端传送的第一封电子邮件(e-mail)没什么特别的,“根本记不住”。但到 1973 年,电子邮件已经占到了 ARPANET 网所有活动的约四分之三。
1982 年,RFC 将传统电子邮件技术标准化为RFC 822文件,它的一个重要特点,就是规定电子邮件只能使用 US-ASCII 字符(也就是纯文字)且每 76 个字符加一个换行符。这导致了三个结果:
- 非英语字符都不能在电子邮件中使用;
- 电子邮件中不能插入二进制文件(如图片);
- 电子邮件不能有附件。
这实际上无法接受的,因此到了 1992 年,工程师们决定扩展电子邮件的技术规范,提出一系列补充规范,这就是 MIME 的由来。
MIME 的扩展
多用途互联网邮件扩展(英语:Multipurpose Internet Mail Extensions,缩写:MIME)是一个互联网标准,它扩展了电子邮件标准,并且在 1992 年最早应用于电子邮件系统,后来也应用到浏览器,其能够支持如下内容:
- 非 ASCII 字符文本;(将二进制数据转化为 7 位 ASCII 编码)
- 非文本格式附件(二进制、声音、图像等);
- 由多部分(multiple parts)组成的消息体;
- 包含非 ASCII 字符的头信息(Header information)。这个标准被定义在 RFC 2045 ~ RFC 2049 等RFC中。
MIME 在RFC 2822 ( 由 RFC 822 转变而来的 )中被标准化。以前的旧标准中规定:电子邮件标准并不允许在邮件消息中使用 7 位 ASCII 字符集以外的字符。正因如此,一些非英语字符消息和二进制文件,图像,声音等非文字消息原本都不能在电子邮件中传输( MIME 可以了)。MIME 规定了用于表示各种各样的数据类型的符号化方法。此外,在万维网中使用的HTTP 协议中也使用了 MIME 的框架,标准被扩展为互联网媒体类型。
ps:MIME 它设计的最初目的是为了在发送电子邮件时附加多媒体数据(即定义了传送非 ASCII 码的编码规则),让邮件客户程序能根据其类型进行处理。然而当它被 HTTP 协议支持之后,它的意义就更为显著了。它使得 HTTP 传输的不仅是普通的文本,而变得丰富多彩。
MIME 所规定的的内容传输编码( Content-Transfer-Encoding ),支持如下字符编码方式:
- 7 bit;7 位 ASCII 码(即基础 ASCII )
- 8 bit;众多扩展 ASCII 码
- binary;二进制
- quoted-printable;将二进制转为 7 位 ASCII 码字符
- Base64。将二进制转为符合 ASCII 码中可打印字符
MIME 主要使用其中的两种编码转换方式 ---- Quoted-printable (咱们简称它为: QP,好记 )和 Base64 ---- 将 8 位的非英语字符转化为 7 位的 ASCII 字符。
ps:上文的 QP 与 Base64 编码转换方式,还有百分号编码(即 url 编码)、字符值引用(即字符实体引用)等都可以理解为前文提到的现代字符编码模型中的第五层 —— 传输编码语法 TES。
这两种编码转换方式不仅是为了解决电子邮件中不能直接使用非 ASCII 码字符的规定,还有另一个重要的意义:所有的二进制文件,都可以因此转化为可打印的文本编码,使用文本软件进行编辑。
这代表着一切能转化为二进制的数据,如图片、影音、文本都可以由二进制数据再编码转换为 7 位 ASCII 编码的可打印字符,来进行网络传输(电子邮件或 http 协议方式)。
Quoted-printable 编码
Quoted-printable 或 QP encoding,没有规范的中文译名,可译为可打印字符引用编码或使用可打印字符的编码。Quoted-printable 是使用可打印的 ASCII 字符(如字母、数字与 “=”)表示各种编码格式下的字符,以便能在 7-bit 数据通路上传输 8-bit 数据。
MIME 定义了在 e-mail ( http 协议也使用 MIME 框架)中发送各种信息的方法, 包括非英语的其它语言文本信息, 使用非 ASCII 的其它字符编码。这些编码常常使用 ASCII 范围以外的值来编码字符( 比如 GB18030 或者 UTF-8 等中文字符),因此需要进一步被编码,把任意字节序列映射为 ASCII 字符序列。
编码转换算法
- 非可打印 ASCII 字符:将每一个 8 位的字节,转为 3 个字符
- 第一个字符必须是等号 “=”;
- 后面二个字符是二个十六进制数,分别代表了这个字节前四位和后四位的二进制数值(二进制转为十六进制)。
- 所有可打印 ASCII 字符(十进制值的范围为 33 到 126 ),可用 ASCII 字符编码来直接表示,但是原有的等号 “=”( 十进制值为 61 ),必须表示为 “=3D”。
- ASCII 的水平制表符( tab )与空格符, 十进制为 9 和 32, 如果不出现在行尾则可以用其 ASCII 字符编码直接表示。如果这两个字符出现在行尾,必须 QP 编码表示为 “=09”( tab )或 “=20” ( space )。
- 如果数据中包含有意义的行结束标志,必须转换为 ASCII 回车( CR )和换行( LF )序列,既不能用原来的 ASCII 字符也不能用 QP 编码的 “=” 转义字符序列。 相反,如果字节值 13 与 10 有其它的不是行结束的含义,它们必须 QP 编码为 =0D 与 =0A。
- 数据的每行长度不能超过 76 个字符。为满足此要求又不改变被编码文本,在 QP 编码结果的每行末尾加上 “软换行”( soft line break )。即在每行末尾加上一个 “=” 。
如下例子:
- (转换编码前)
If you believe that truth=beauty, then surely mathematics is the most beautiful branch of philosophy.
- (转换编码后)
If you believe that truth=3Dbeauty, then surely=20=
mathematics is the most beautiful branch of philosophy.
Base64 编码
Base64 也是使用一部分可打印的 ASCII 字符表示各种编码格式下的字符,以便能在 7-bit 数据通路上传输 8-bit 数据。其在所有 ASCII 可打印字符(十进制 32~126,共 95 个字符)中挑选于 64 个可打印字符来表示二进制数据。原则上,计算机中所有内容都是二进制形式( 0 和 1 )存储的,所以所有内容(包括文本、影音、图片等)都可以用 Base64 来进行转码成二进制数据,以便进行网络传输( 电子邮件及 http 协议)。
百度百科中对 Base64 有一个很好的解释:“ Base64 是网络上最常见的用于传输 8 Bit 字节码的编码方式之一”。
Base64 的字符编码范围为 ASCII 码可打印字符中的:小写字母 a ~ z 、大写字母 A ~ Z 、数字 0 ~ 9 、符号 " + " 、" / " ,一共 64 个,并且使用一个或者两个等号 “ = ” 作为编码的后缀补充,详见后文。
Base64 并不是加密方式,因为从二进制的角度上看,它依然是明码,即可以通过逆向解码得到原数据。只是二进制数据或者编码后的字符对于人类来说并不直观,不能通过肉眼识别信息,即不可读性。
完整的 Base64 定义可见 RFC 1421( 1993 年) 和 RFC 2045( 1996 年)。
编码算法
通过前文已知道通过各种字符编码方式,比如 UTF-8、GBK 等,得到了各个字符(即每一种编码方式对应的 Base64 值都不同)的二进制数据;图片、影音内容则是通过其他算法得到二进制流数据。这些二进制数再转化为 Base64( 或者 QP )得以进行网络传输(电子邮件或 http 协议下)
Base64 将二进制文本数据编码转换过程如下:,
-
将每 3 个字节的数据作为一组,一共是 24 个二进制位,先后顺序放入缓冲区。
-
先来的字节占高位,后来的占据低位,每次从高位中取出 6 个比特位,其值转为十进制后按照 Base64 编码表中的索引,找到相对应字符作为编码后输出,直到全部输入数据转换完成。
-
如果数据不足 3 字节的话,将缓冲器中剩下的比特位(即低位)用 0 补足。
-
若原数据长度(指字节)不是 3 的倍数,最后会多出1个或 2 个字节,按下面两种情况处理:
-
若多出 1 个字节,则在缓冲区末尾补 16 个 0,凑成 3 个字节,其中后 12 位 0 不进行转换为 "AA" ,直接在输出结果后加 2 个等号 “=” 。
-
若多出 2 个字节,则在缓冲区末尾补 8 个 0,凑成 3 个字节,其中后 6 位 0 不进行转换为 "A" ,直接在输出结果后加 1 个等号 “=” 。
-
-
每 76 个字符加一个换行符。
注意:经过编码算法的 5 条规则编码后的数据,在存储到计算机或者进行网络传输时,并不是使用 Base64,它仅仅是一种转换编码方式( ps:工具人),转换成可传输的 7 位 ASCII 码。所以其最后,是按 ASCII 码来进行二进制流的存储和传输的。其他计算机或者程序接收到数据后,再按 Base64 算法过程进行逆向解码,得到原始数据(文本、图片与影音等)。
其他字符编码方式都是将字符到二进制(常用十六进制表示)的过程称为编码,逆向为解码。Base64 与 QP 是反过来的:将字符(即 ASCII 码可打印字符)到二进制的过程为解码,从二进制到字符的过程为编码。
下表为 Base64 编码索引表:
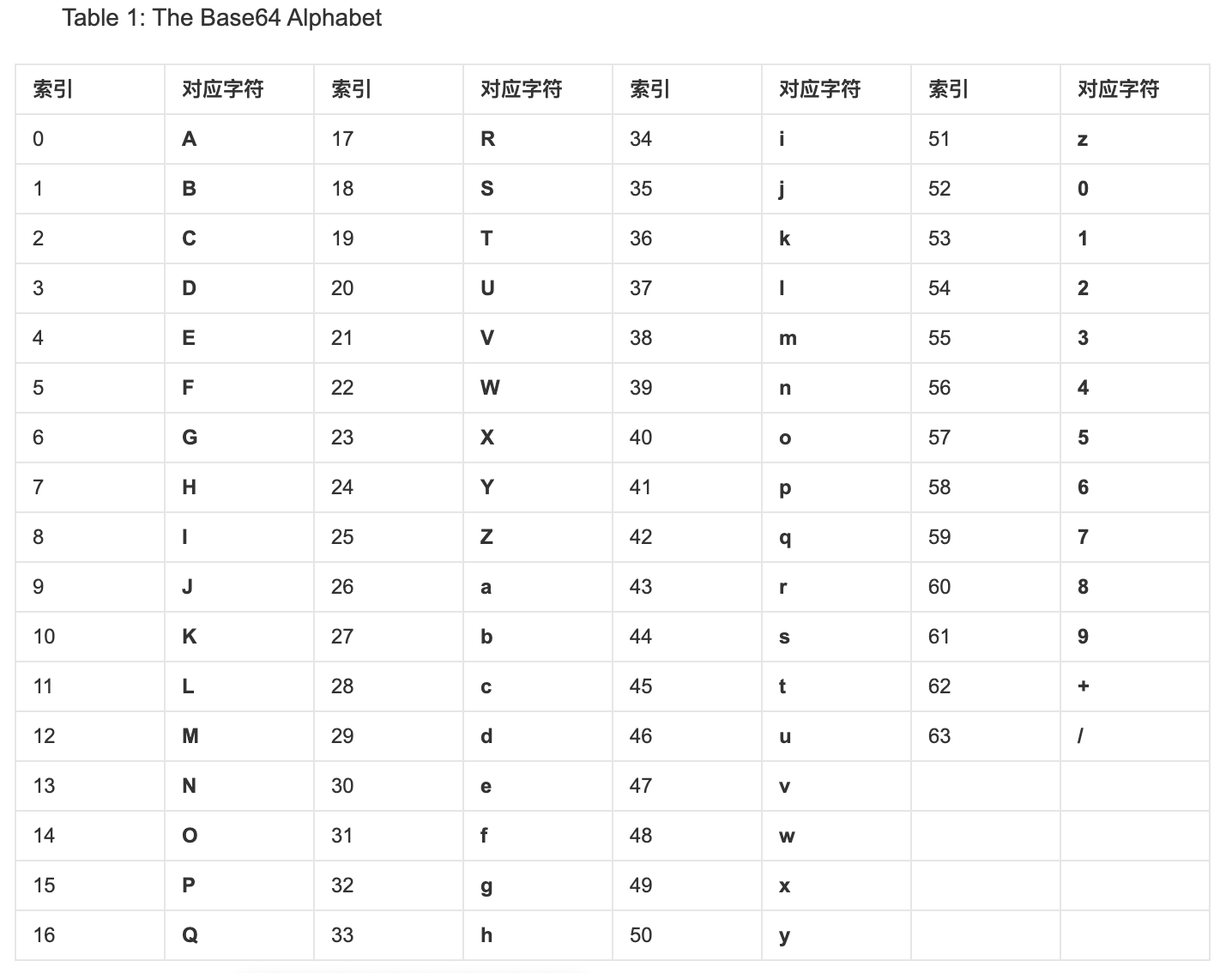
举个中文例子,汉字 "严" 如何转化成 Base64 编码 ?(摘自阮一峰老师的例子),这里需要注意,汉字本身可以有多种编码,比如 gb2312、utf-8、gbk 等等,每一种编码的 Base64 对应值都不一样。下面的例子以 UTF-8 为例。
首先,"严" 的 UTF-8 编码为 E4B8A5,二进制表示就是三字节的 "1110 0100 1011 1000 1010 0101"。将这个 24 位的二进制字符串,按照上文第 2 步中的规则,依次从高位到低位输出 4 次,每次取 6 位比特,相应的十进制数为 57、11、34、37,它们对应的 Base64 编码值就为 5、L、i、l 。
所以,汉字 "严"( UTF-8 编码)的 Base64 值就是 " 5Lil " 。
注意:

如果原数据的字节总数不足 3 或者不足 3 的倍数,则按上文编码算法中的第 4 规则处理:

为什么只取 64 个字符
Base64 取名 64 也是因为 64 个可打印字符而来,至于为什么只取 64 个可打印字符;可能是因为 ASCII 码的可见字符只有 95 个,向下取整( 2 的 n 次方)正好是 64 。而且又因为 log(64)2 = 6 ,所以在 Base64 中用 6 个比特位表示一个单元,对应一个可打印字符。
为什么文件变大
通过上文的例子中,汉字 “严” 的 Base64 的编码值 “ 5Lil ” 在计算机存储中会按照 ASCII 码被存储(或者传输)为 “ 0000 0101 0010 1100 0110 1001 0010 1001 ” 共 32 个二进制位,而其原 UTF-8 编码方式是按 “ 1110 0100 1011 1000 1010 0101 ” 共 24 个二进制位存储的。所以经过 Base64 编码后的数据会比原数据大一些,大概 3/4 。在电子邮件中,根据 RFC 822 ( 1982 年)规定,每 76 个字符,还需要加上一个回车换行。可以估算编码后数据长度大约为原长的 135.1%。
正是因为这个原因,前端 base64 编码只适用于小文件,因为增加的体积不多,还可以省下一次网络请求;但当文件体积比较大时,会影响网站初次加载和渲染的速度( 解码 Base64 大文件也会消耗性能),这种时候文件还是放 CDN 比较好。
使用 QP 还是 Base64 ?
如果大量中文字符情况下使用 QP,通过其转换编码算法得知,非 ASCII 字符,将每一个 8 位字节,转为 24 位 3 个字节,这等于是扩大 3 倍大小了;而 Base64 大概为原数据的 135.1% 左右。
所以遇到中文很多的情况下,用 Base64 合适。
Quoted-printable 是遇到非 ASCII 码则转,所以在英文很多,中文很少的情况下,转换后的结果是有一定可读性的,优于 Base64 (完全不可读),还是用 Quoted-printable 合适。
在 URL 中的应用
Base64 编码可用于在 HTTP 环境下传递较长的标识信息。例如,在Java 持久化系统 Hibernate 中,就采用了 Base64 来将一个较长的唯一标识符(一般为 128-bit 的UUID)编码为一个字符串,用作 HTTP 表单和 HTTP GET URL 中的参数。在其他应用程序中,也常常需要把二进制数据编码为适合放在 URL(包括隐藏表单域)中的形式。此时,采用 Base64 编码不仅比较简短,同时也具有不可读性,即所编码的数据不会被人用肉眼所直接看到。
然而,标准的 Base64 并不适合直接放在 URL 里传输,因为 URL 编码器( URL-Encoding )会把标准 Base64 中的/和+字符变为形如%XX的形式,而这些%号在存入数据库时还需要再进行转换,因为 ANSI SQL 中已将%号用作通配符。
为解决此问题,可采用一种用于 URL 的改进 Base64编码( RFC 4648,2006 年),它不在末尾填充=号,并将标准 Base64 中的+和/分别改成了-和_,这样就免去了在 URL 编码解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
另有一种用于正则表达式的改进 Base64变种,它将+和/改成了!和-,因为+,*以及某些软件用到的[和]在正则表达式中都有特殊含义。
Java 实现与调用
Java 中的实现细节
public static String base64UrlEncode(byte[] simple)
{
String s = new String(Base64.encodeBase64(simple)); // Regular base64 encoder
s = s.split("=")[0]; // Remove any trailing '='s
s = s.replace('+', '-'); // 62nd char of encoding
s = s.replace('/', '_'); // 63rd char of encoding
return s;
}
public static byte[] base64UrlDecode(String cipher)
{
String s = cipher;
s = s.replace('-', '+'); // 62nd char of encoding
s = s.replace('_', '/'); // 63rd char of encoding
switch (s.length() % 4)
{ // Pad with trailing '='s
case 0:
break; // No pad chars in this case
case 2:
s += "==";
break; // Two pad chars
case 3:
s += "=";
break; // One pad char
default:
System.err.println("Illegal base64url String!");
}
return Base64.decodeBase64(s); // Standard base64 decoder
}
不过 Java 本身已经替我们写好 Base64 的实现细节,使用的时候直接调用即可。具体代码如下所示:
package com.first;
import org.junit.Test;
import java.io.UnsupportedEncodingException;
import java.util.Base64;
public class Test {
@Test
public void test() throws UnsupportedEncodingException {
// 编码
String encode = Base64.getEncoder().encodeToString("So".getBytes("UTF-8"));
System.out.println(encode);
// 解码
byte[] decode = Base64.getDecoder().decode(encode);
System.out.println(new String(decode, "UTF-8"));
}
JavaScript 实现与调用
在 javascript 中如何使用 Base64 转码
var str = 'javascript';
window.btoa(str)
//转码结果 "amF2YXNjcmlwdA=="
window.atob("amF2YXNjcmlwdA==")
//解码结果 "javascript"
复制代码
对于转码来说,Base64 转码的对象只能是字符串,因此来说,对于其他数据还有这一定的局限性。在此特别需要注意的是对 Unicode 转码问题,window.btoa与 window.atob 不支持中文。
var str = "China,中国"
window.btoa(str)
// Uncaught DOMException: Failed to execute 'btoa' on 'Window': The string to be encoded contains characters outside of the Latin1 range.
上面代码报错提示看,Latin1 为 ISO 8859-1 即 ASCII 超集,btoa与atob显然是不支持中文的。那么如何让他支持汉字呢,这就要使用 window.encodeURIComponent和window.decodeURIComponent。前一个方法将字符串解码为 UTF-8 码点值,其码点值十六进制就自然是 ASCII 码可打印字符范围内了,再转为 Base64 编码。后一个方法逆向。
var str = "China,中国";
window.btoa(window.encodeURIComponent(str))
//"Q2hpbmElRUYlQkMlOEMlRTQlQjglQUQlRTUlOUIlQkQ="
window.decodeURIComponent(window.atob('Q2hpbmElRUYlQkMlOEMlRTQlQjglQUQlRTUlOUIlQkQ='))
//"China,中国"
// 逆向解码
图片转为 Base64
网络上有相关工具直接将图片转为 Base64,这里记录一下 JS 中的方法,来自 tellyourmad ,思路如下:
- 构造一个 img 元素,将 url 赋给 img2. 给元素的内容赋值为你所想要 copy 的文本
- 等待图片加载完成
- 构造一个 canvas 元素
- 将 img 元素画到 canvas 上
- 通过 canvas 的 api 将 url 转化为 base64
function convertImgToBase64(url, callback, outputFormat){
var canvas = document.createElement('CANVAS'),
ctx = canvas.getContext('2d'),
img = new Image;
img.crossOrigin = 'Anonymous';
img.onload = function(){
canvas.height = img.height;
canvas.width = img.width;
ctx.drawImage(img,0,0);
var dataURL = canvas.toDataURL(outputFormat || 'image/png');
callback.call(this, dataURL);
canvas = null;
};
img.src = url;
}
var url = "static/img/js1.jpg";//这是站内的一张图片资源,采用的相对路径
convertImgToBase64(url, function(base64Img){
//转化后的base64
alert(base64Img);
});
HTML 中内嵌 Base64 图片
就是说这种状况下,图片不是以链接地址的方式嵌到 HTML 中去的,图片本身已被转为 Base64 编码的字符串放到 HTML 页面文本中去了,成为 HTML 文本的一部分。当 HTML 页面拉取完成之后,图片数据也就下来了,不再需要再去拉取图片。如下格式:
<img src='data:image/png;base64,base64code'>
这种标签图片的显示需要浏览器的支持,先 Base64 解码,再去显示不同格式的图片。
还有一种方式:使用 data: URI 直接在网页中嵌入,data: URI 定义于 RFC 2397。
data: URI 的基本使用格式如下:
data:[<MIME-type>][;base64|charset=some_charset],<data>
MIME-type 是嵌入数据的 MIME 类型,比如 png 图片就是 image/png。如果后面跟 Base64,说明后面的 data 是采用 base64 方式进行编码的。
网络上有相关工具直接将图片转为 Base64。
需要注意这种直接内嵌 HTML 的方式只适合小图片文件,不然会拖慢加载速度。
其他应用场景
迅雷等下载工具,就有他们自己特有的下载链接,如 thunder:// 其实就是把一个 HTTP URL 资源地址加上了某些东西后再进行 Base64 编码,然后加上 thunder:// 头。
百度地图 API 的地址转化(例如GPS坐标->百度地图坐标)结果,使用了base64加密。
百分号(URL)编码
百分号编码(英语:Percent-encoding),又称:URL 编码( URL encoding )是特定上下文的统一资源定位符 (URL)的编码机制,实际上也适用于统一资源标志符(URI)的编码。也用于为 application/x-www-form-urlencoded MIME准备数据,因为它用于通过 HTTP 的请求操作(request)提交 HTML 表单数据。
通过上面的维基介绍,我们知道百分号编码作用,但是为什么要进行 URL 编码 ?
因为早在 URL 被发明出来作为万维网地址时,就已规定只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。后被标准化为 RFC 1738,是硬性规定。这意味着,如果 URL 中有汉字或者其他标准之外的字符,就必须编码后使用。
保留与未保留字符
在 RFC 1738 ( 1994 年)中 URI 所允许的字符分作保留与未保留。保留字符是那些具有特殊含义的字符,例如:斜线字符用于 URL(或 URI )不同部分的分界符;未保留字符没有这些特殊含义。
-
保留字符有:
$、-、_、.、+、!、*、'、(、)、, -
未保留字符有:数字 0 ~ 9 、小写字母 a ~ z 、大写字母 A ~ Z
后来在 RFC 3986 ( 2005 年)中对之前的标准做了一些修改,保留与未保留字符修改为:
-
保留字符有:
!、*、'、(、)、;、:、@、&、=、+、$、,、、/、?、#、[、] -
未保留字符有:数字 0 ~ 9 、小写字母 a ~ z 、大写字母 A ~ Z 、
-、_、.、~
上述情形随 URI 与 URI 的不同版本规格会有轻微的变化。
需要注意的是,这些允许的字符都是 US-ASCII 编码的可打印字符。
百分号编码规则
- 对于未保留字符,不需要进行百分号编码(强制要求),直接表示即可。
- 两个 URI 的差别如果仅在于未保留字符是用百分号编码还是用字符自身表示,那么这两个 URI 具有等价的语义。但 URI 处理器实际上并不总是把二者视作等价。例如, 某些 URI 的编码器中不应该把
%41与A视作不同, 但是某些 URI 的编码器就是这么做了。所以为了最大的兼容性, URI 的使用者不应该对未保留字符进行百分号编码。
- 两个 URI 的差别如果仅在于未保留字符是用百分号编码还是用字符自身表示,那么这两个 URI 具有等价的语义。但 URI 处理器实际上并不总是把二者视作等价。例如, 某些 URI 的编码器中不应该把
- 对于保留字符,分两种情况:
- 当保留字符在 URL 或者 URI 中为特殊功能时,如
:用作分割协议与服务器,/用作不同部分的分界符等,这些特殊功能情况下,不需要进行百分号编码,直接表示即可 - 当保留字符在 URL 或者 URI 中是内容的一部分,如路径名、查询字符串、片段等的一部分时,需要进行百分号编码,以免编码器当做特殊功能,而解析错误。其编码规则如下:
- 首先需要把该字符的 US-ASCII 码点值表示为两个 16 进制的数字,然后在其前面放置转义字符("
%"),置入 URI 中的相应位置。 - 例如,"
/", 如果用作 URI 的路径成分的分界符, 则是具有特殊功能的保留字符. 如果该字符需要出现在 URI一个路径成分的内部, 则三字符序列%2F或%2f(不分大小写)就用于代替原本的"/"出现在该 URI 路径成分的内部.
- 首先需要把该字符的 US-ASCII 码点值表示为两个 16 进制的数字,然后在其前面放置转义字符("
- 当保留字符在 URL 或者 URI 中为特殊功能时,如
- 对于百分号
%自身,由于其自身也是特殊功能的用途(但其并不是保留与未保留字符);当其为内容的一部分,如路径名、查询字符串、片段等的一部分时,也需要进行百分号编码,以免编码器将其自身与后两个字符当做整体,而解析错误。其编码规则如下:- 使用
%25代表其%自身,用于 URI 内容的一部分。
- 使用
- 对于出现在 URI 中的二进制数据,应该优先使用 8 位元组序列(即 Latin-1,ISO 8859),然后对每个 8 位元组按照上述方式进行百分号编码。这样使得 URL 更短。
- 对于非 ASCII 字符, 需要转换为 UTF-8 字节序,然后每个字节按上述方式进行百分号编码。
非标准的实现
有一些不符合标准的把 Unicode 字符在 URI 中表示为: %uxxxx, 其中 xxxx 是用 4 个十六进制数字表示的 Unicode 的码点值。任何 RFC 都没有这样的字符表示方法,并且已经被 W3C 拒绝。第三版的 ECMA-262 仍然包含函数escape(string)使用这种语法(已被废弃),但也有函数encodeURI(uri)和 encodeURIComponent 转换字符到 UTF-8 字节序列并用百分号编码每个字节。
最后,还有个特殊的 PHP urlencode(),有需要自行了解。
百分号编码与 Base64 异同
相同点:它们都是用给定的 US-ASCII 码可打印字符去表示更广范围数据的方法。
区别:百分号编码是针对超出 URI 合法字符范围外的字符做编码,而 Base64 是针对二进制数据做编码;一个是对文本的编码,一个是对二进制数据的编码。
文本本质上也是二进制数据,因此也可以强行拿来做 base64 编码
Base64 编码中的斜杠号 / 和等号 = 不属于 URI 合法字符,故 Base64 编码串不能直接带在 URI 链接参数上,当然也出现了兼容方案:用于 URL 的改进 Base64编码( RFC 4648,2006 年)。
