

在说优化之前,要先明白Draw Call是什么?
- 在Opengl中我们每次要将一个物体绘制出来时,CPU端都需要调用一次glDrawElements或者 glDrawArrays命令 (前者依靠索引绘制,后者直接靠顶点顺序绘制),其实这就是一个Draw Call。
- 所以Draw Call本身只是一个很简单的命令(仅仅是向GPU的Command Buffer中加入几个字节的数据),对于强大的GPU来说,根本不值一提。
那么为什么好多人做优化时都会说要降低Draw Call呢?那是因为CPU在分配一个Draw Call之前需要做很多的准备工作,例如:
- 提交和整理数据,例如提交顶点数据,顶点索引数据,shader,材质属性,光源信息等等,也就是State面板中显示Batches,一次Batch代表一次提交;
- 切换渲染状态,主要出现在材质不同的时候,如果这次Draw Call使用的Draw Call和上一个Draw Call使用的不是同种材质或者同一个材质的不同pass,那么就要触发一次set pass call来重新设定渲染状态。
- 如下图所示,8个不透明物体使用两种不同的材质,间接摆放,
使用自定义渲染管线,使其渲染顺序从后向前渲染(真实情况与其相反,而且引擎内部有优化,此处只是更直观)。则会提交九次,并切换九次渲染状态,其中一次是绘制天空盒。
- 使用同样的渲染顺序,这次由于同一种材质的都比另一种材质的靠前,虽然提交次数相同,但是切换渲染状态的次数明显减少。
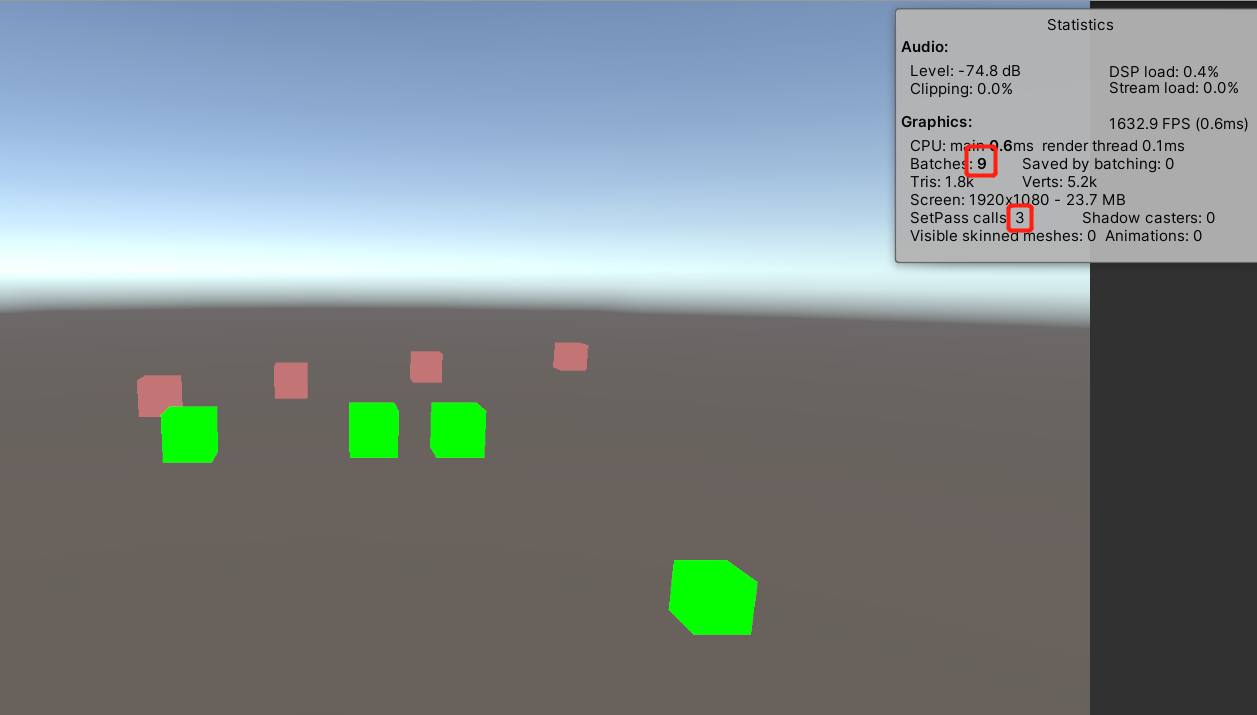
- 上述两点这才是消耗的重点。
所以优化本身要做的就是减少提交的数据和提交的次数,同时减少渲染状态的切换,(一次提交,多次绘制)这其实就是我们常说的批处理操作。
-
Static Batch:在
使用相同材质球的条件下,在Build(项目打包)的时候Unity会自动地提取这些共享材质的静态模型的Vertex buffer和Index buffer。根据其摆放在场景中的位置等最终状态信息,将这些模型的顶点数据变换到世界空间下,存储在新构建的大Vertex buffer和Index buffer中。并且记录每一个子模型的Index buffer数据在构建的大Index buffer中的起始及结束位置;- 在后续的绘制过程中,做完视锥体剔除操作后,一次性提交所有的顶点数据,而只是提交需要渲染部分的索引数据。然后设置一次渲染状态,调用多次Draw call分别绘制每一个子模型。这期间并没有再次提交数据,也没有再次切换渲染状态,所以起到了优化作用。
- 同时顶点预先变换到了世界空间,减少了运算量。
- 但是,会增大应用程序的体积增大,运行时占有的运行内存也会增多。主要是因为场景中所有引用相同模型的GameObject都必须将模型顶点信息复制,并经过计算变化到最终在世界空间中,存储在最终生成的Vertex buffer中。这就导致了打包的体积及运行时内存的占用增大。
-
Dynamic Batch:在使用
相同材质的情况下,Unity会在运行时将视野中的符合条件的对象的顶点转换到世界空间,并存储在一个新的Vertex Buffer和一个新的Index Buffer中,(这些运算发生在CPU端,而且每一帧都需要进行,所以会对CPU造成一定的消耗,所以顶点不宜太多),- 绘制时将所需的数据一次上传到GPU,并设置一次渲染状态,调用多次Draw Call分别绘制每一部分(其实是这些命令先加入CommandBuffer中,可以一并提交到GPU的CommandBuffer中)。

- 绘制时将所需的数据一次上传到GPU,并设置一次渲染状态,调用多次Draw Call分别绘制每一部分(其实是这些命令先加入CommandBuffer中,可以一并提交到GPU的CommandBuffer中)。
-
GPUInstance:使用相同材质,相同mesh的情况下,unity会自动收集视野中所有符合要求的对象,将其材质属性,矩阵信息(如物体到世界空间的矩阵),uv偏移等收集到结构数组中,一并传到GPU存储在Constant Buffer中,而且只需要传递一个mesh数据。最后调用类似OpenGL中 glDrawArraysInstanced或 glDrawElementsInstanced的接口多次绘制即可。
- 也是只需一次提交,绘制多次,
但是需要每帧都收集信息,并上传到GPU中。 - 由于数据都存储在Constant Buffer中,而Constant Buffer有大小限制,一个最大为64kB,一个shader中可以有多个CB,所有一次提交的物体信息的数量不可能太多,PC为500,移动端为250左右。


- 因为在名为unity_Builtins0的结构数组中最少需要包含两个矩阵,object to world(物体到世界),world to object(世界到物体,用于变换法线) 。所以64000 / 128 = 500.
#ifdef UNITY_ASSUME_UNIFORM_SCALING #define UNITY_WORLDTOOBJECTARRAY_CB 1 #else #define UNITY_WORLDTOOBJECTARRAY_CB 0 #endif //上面两句,若shader中声明了 #pragma instancing_options assumeuniformscaling //这句话,则会自动生成一个名为UNITY_ASSUME_UNIFORM_SCALING的宏 // --------------------------------------------- UNITY_INSTANCING_BUFFER_START(PerDraw0) #ifndef UNITY_DONT_INSTANCE_OBJECT_MATRICES UNITY_DEFINE_INSTANCED_PROP(float4x4, unity_ObjectToWorldArray) #if UNITY_WORLDTOOBJECTARRAY_CB == 0 UNITY_DEFINE_INSTANCED_PROP(float4x4, unity_WorldToObjectArray) #endif #endif //... 忽略其他不是必须的数据 UNITY_INSTANCING_BUFFER_END(unity_Builtins0) //这两个宏声明一个结构数组,数组的名字为UNITY_INSTANCING_BUFFER_END后的值加上“##Array” #define UNITY_INSTANCING_BUFFER_START(buf) UNITY_INSTANCING_CBUFFER_SCOPE_BEGIN(UnityInstancing_##buf) struct { #define UNITY_INSTANCING_BUFFER_END(arr) } arr##Array[UNITY_INSTANCED_ARRAY_SIZE]; UNITY_INSTANCING_CBUFFER_SCOPE_END //在结构中声明一个变量 #define UNITY_DEFINE_INSTANCED_PROP(type, var) type var; //根据unity_InstanceID访问结构数组中某个项中的某个变量 #define UNITY_ACCESS_INSTANCED_PROP(arr, var) arr##Array[unity_InstanceID].var #ifndef UNITY_DONT_INSTANCE_OBJECT_MATRICES #undef UNITY_MATRIX_M #undef UNITY_MATRIX_I_M #define MERGE_UNITY_BUILTINS_INDEX(X) unity_Builtins##X //..省略不重要的东西 #else #define UNITY_MATRIX_M UNITY_ACCESS_INSTANCED_PROP(unity_Builtins0, unity_ObjectToWorldArray) #define UNITY_MATRIX_I_M UNITY_ACCESS_INSTANCED_PROP(MERGE_UNITY_BUILTINS_INDEX(UNITY_WORLDTOOBJECTARRAY_CB), unity_WorldToObjectArray) #endif #endif //根据unity_InstanceID访问结构数组中的 object to world matrix,world to object matrix。-
所以当调用Unity自带的API--Graphics.DrawMeshInstanced(最多可以绘制1023个)绘制物体时,若绘制1023个物体,会分三次提交,产生三个batch,图中为四个是因为其中有一个为天空盒的数据。
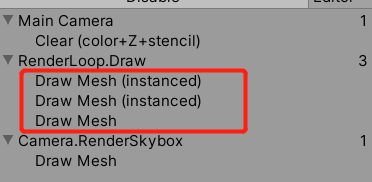
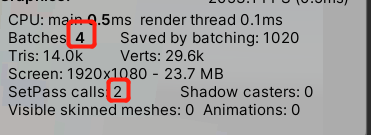
-
若要可以通过一次提交绘制无限个物体,则需要使用Graphics.DrawMeshInstancedIndirectUnity接口。同时还需要我们避开使用Constant Buffer,其实可以使用StructuredBuffer代替(缺点是在Opnegl的顶点着色器不支持访问StructuredBuffer,但是Vulkan,Metal,DX都支持),将所需要的数据一次都提交到shader后(这些数据最起码可以产生物体到世界的矩阵,从而将顶点从物体空间变化到世界空间,至于法线,可以使用统意的地表法线),调用DrawCall 命令可以多次绘制(这些DC命令也是存储在CommandBuffer中,一次提交的 )。
-
由于调用Graphics.DrawMeshInstanced和Graphics.DrawMeshInstancedIndirect接口产生的物体不受视锥剔除和裁剪的影响,所以需要我们自己做一下简单的剔除,若物体很少的话可以在CPU端做一下简单的剔除工作;若很多则可以联合ComputeShader来做,这样做的好处是产生的结果可以直接传送到Shader中。
-
关于视锥剔除看我这篇。
- 也是只需一次提交,绘制多次,
-
SRPBatcher:这应该是自定义渲染管线最大的好处了,使用相同shader变体(也就是Keyword)的物体就可以参与合批,步骤如下:
- 每当场景种产生一个新的材质时,unity会自动收集材质的属性,并将其保存在GPU中,并且只有属性改变时才会更新。
- 将每个物体的引擎属性(例如物体到世界矩阵,世界到物体矩阵等等)缓存在GPU中,每次只需要更新,不需要重新创建.
- 所以SRP Batcher只是降低了Batch的成本。
总结
- 四者的优先顺序为Static Batch ,SRPBatcher,GPUInstancing,DynamicBatch。
- 对于大型不移动的物体推荐使用Static Batch;相同且大量的物体使用GPUInstancing,可以在运行时才显示出来;mesh种类不同,但使用了相同的shader变体的情况下使用SRPBatcher;最后在考虑DynamicBatch。
