

本系列旨在结合seq2seq,分析一些常用的attention模型。
1.背景:
此时nmt(neural machine translation)已经提出来了,不同于之前的smt(statistical machine translation),nmt是一个端到端的模型。seq2seq就是其中一种。
2.什么是seq2seq模型
seq2seq包括一个encoder和一个decoder,通常是不同的rnn网络。encoder处理输入序列,将其压缩成一个固定长度的向量,称为context vector。该向量包含了输入序列的全部信息。 decoder每次输出一个预测结果,输入是上一次预测的结果和上一个rnn的隐藏层。初始化时,输入就是context vector。 该模型通过最大化正确的翻译结果学习网络参数。
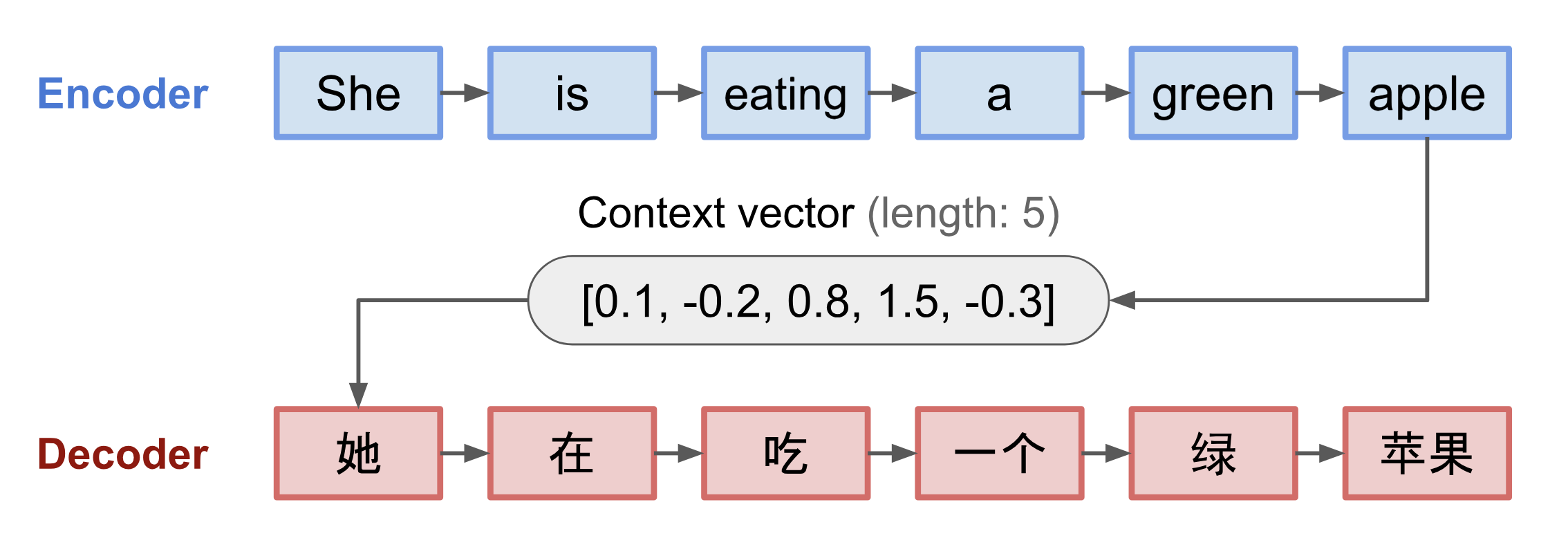
这个模型可以处理序列关系,但是由于rnn的局限性, 很难记住很长的句子中靠前的词。而翻译一个词的时候,和原句对应词附近的词或多或少有关系。例如,当你要去见一个好友的时候, 想和她说点啥, 这时候你就要回忆过去你们之间的事情,然后选一些感兴趣的话题。同样的,翻译的时候关注原句各个词与当前翻译词的关系,就产生了attention。
3.attention
attention的运用使得长句也能取得较好的翻译结果,且能易于可视化。 attention的种类和使用方式随着transformer大热,甚至抛弃了原有的rnn结构,仅仅使用attention。 该系列就随着seq2seq的发展的历史,来讲解各类模型和attention。
