

「初」前言
在学习数据结构与算法的过程中,感觉真的是一入算法深似海,但是越学越觉得有趣。不过我们会发现在终身学习的过程中,我们都是越学越多,不知的也越来越多,但是更渴望认知更多的知识,越是对知识感兴趣。
本期讲说最常见的数据结构类型分别有数组、链表、跳表。这一期我们一起来了解它们的原理与实现。
「一」数组 Array
- Java, C++: int a[100]
- Python: list = []
- JavaScript: let x = [1, 2, 3]
当今的高级数据语言中,对于数组里面的类型没有严格要求,相对来说比较多元化。
在语言下有一个标准的叫法叫做
泛型,也就说任何一个单元类型都可以放入数组。
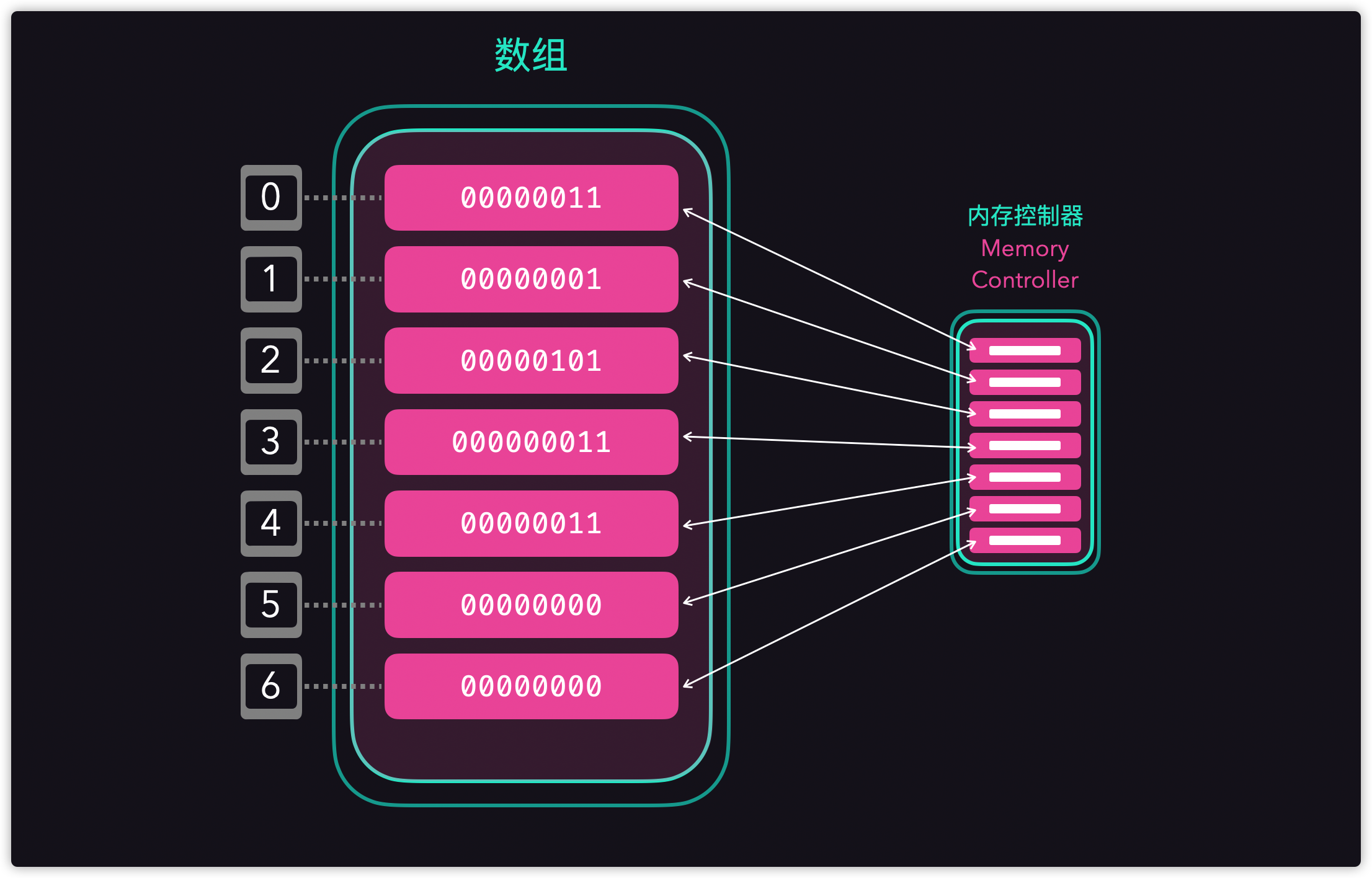
数组的原理
- 数组底层的硬件实现是有一个
内存管理器的; - 当我们向计算机申请数组时,实际上计算机是在内存中给我们开辟了一段连续的地址;
- 每一个地址都是可以通过内存管理进行访问;
- 无论我们是访问第一个值,还是里面其中一个值,时间复杂度都是
常数O(1); - 并且可以随意访问任何一个元素,所以它的访问速度非常的快,也是数组的特性之一;
数组的缺陷
数组的问题关键是在增加与删除元素的时候。
数组插入操作
假设现在我们定义了一个[A, B, C, E, F, G]的数组,然后我们要插入一个D到这个数组里面。现在假设我们要把D插入到指针3的位置,我们要怎么实现呢?
- 首先我们需要把
E,F,G都挪动到各自的下一个指针; - 然后加入
D到指针3上;
详细实现效果请查看下效果图:
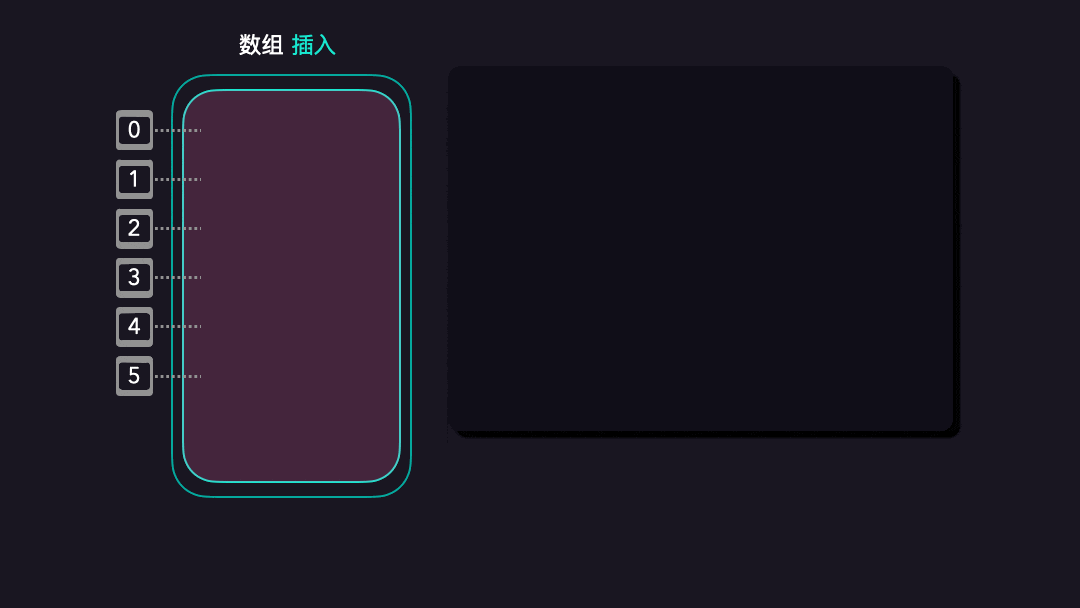
因为插入操作的时候,我们需要挪动平均一半的元素(N/2),所以数组每次插入元素时,平均就是
O(n)的时间复杂度。
数组删除操作
删除元素也是同理的,假设我们现在有[A, B, C, Z, D, E, F]的一个数组,我们现在需要把Z从这个数组中移除。实现逻辑如下:
- 首先把指针
3的值置空; - 然后把
D、E、F三个值往上移动一个位置; - 最后在例如
Java的数组语言中,我们需要把数组的长度减一即可;
具体的实现效果看下图:
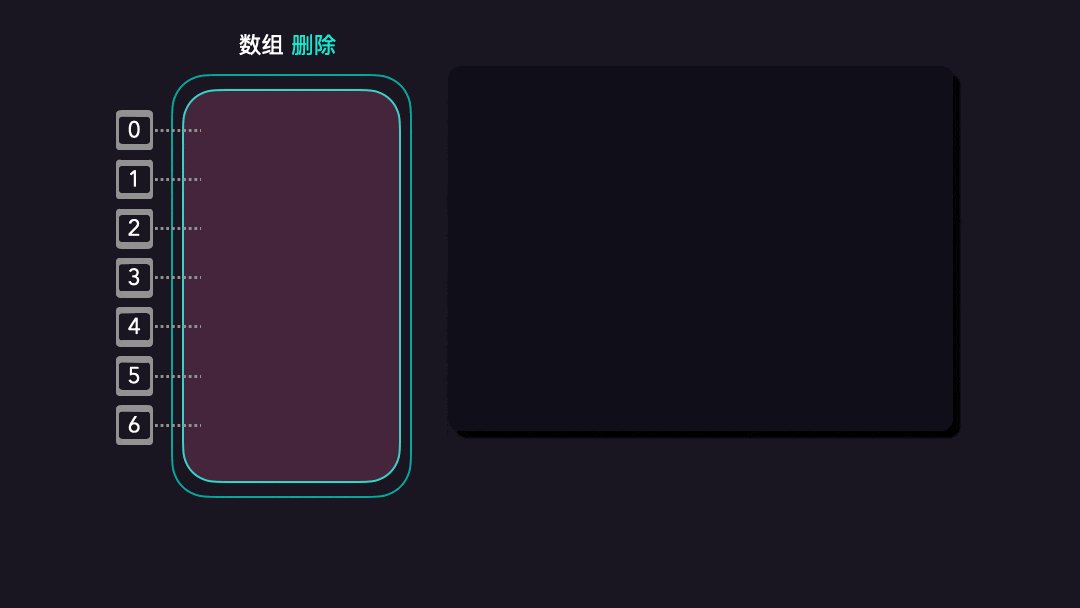
因为删除操作的时候,也是需要挪动平均一半的元素(
N/2),所以数组每次删除元素时,平均就是O(n)的时间复杂度。
数组时间复杂度
| 操作类型 | 时间复杂度 |
|---|---|
| 查询上一个 (prepend) | O(1) |
| 查询下一个 (append) | O(1) |
| 查询某一个元素 (lookup) | O(1) |
| 新增结点 (insert) | O(N) |
| 删除结点 (delete) | O(N) |

「二」 链表 Linked List
下来我们一起来看看另外一个数据结构链表。链表的诞生就是为了解决数组的缺点。
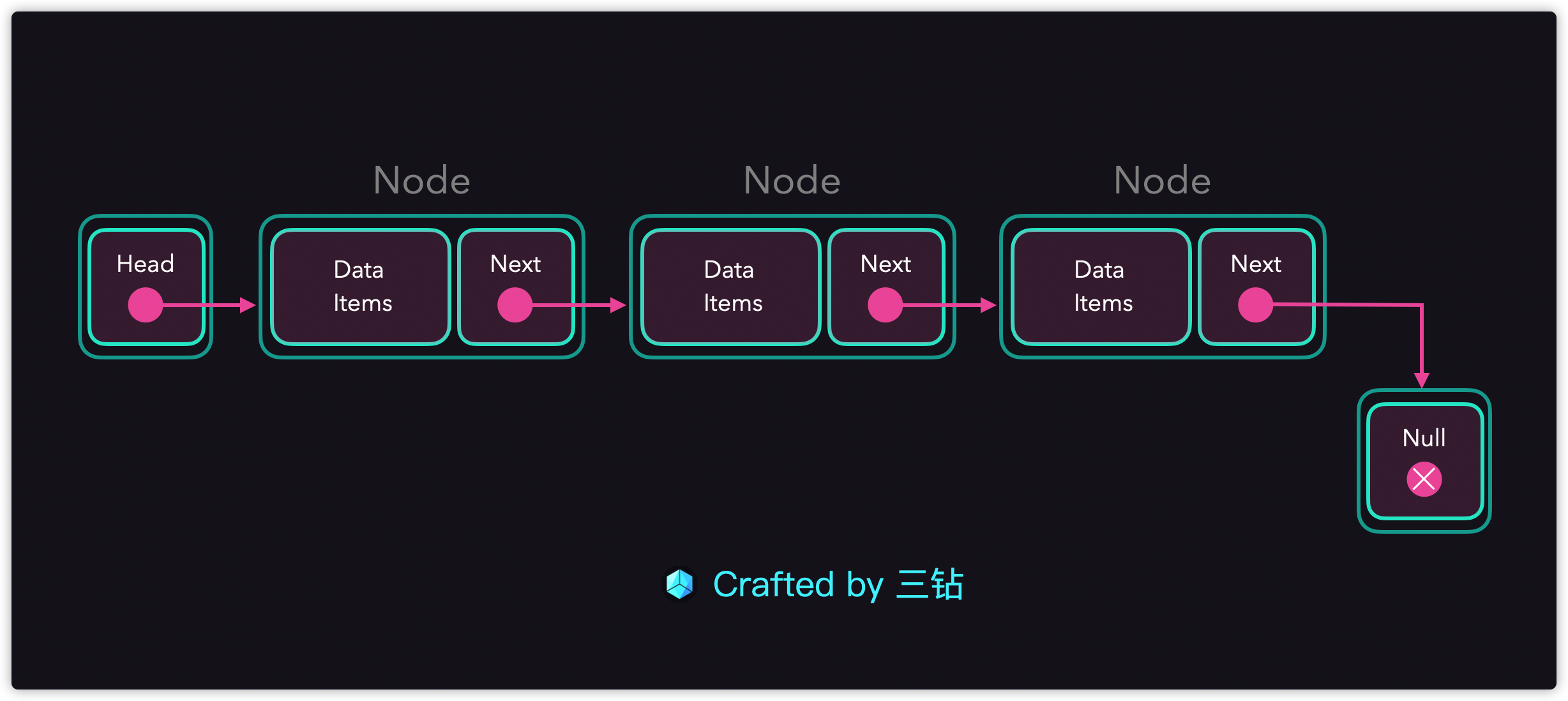
链表的特性:
- 每一个元素有两个成员变量
value值与next指针(指向下一个元素); - 每一个元素串在一起后与数组是非常相似的结构;
- 与数组不一样的就是每一个元素一般都要定义一个
Class(类):一般都叫一个Node; 单链表:只有一个next指针;双向链表:拥有一个prev或者previous指针指向前一个元素;- 头指针用Head来表示,尾指针用Tail来表示;
- 尾部指针的next指针都会指向一个None(空);
循环链表:尾指针的next指针指向头指针;
链表添加结点
下来我们一起来看看一个链表新添加一个元素的原理:
- 首先为新的元素创建一个结点(Node);
- 然后我们需要把这个新元素插入到连个元素之间;
- 把前一个元素的
next指针指向新的Node; - 把新元素的
next指针指向后一个元素;
具体实现效果看下图:

链表的插入操作总共是2次,但是常数次的,所以时间复杂度为
O(1)。
链表删除结点
接下来我们一起来看看删除结点的原理,删除与新增大致上是一样的,是
- 在需要把删除的结点的前一个node的
next,改为删除结点的下一个node;
具体的实效效果看下图:

链表的删除操作只需要一次,所以时间复杂也是
O(1)。
链表时间复杂度
通过分析链表的新增和删除操作,我们发现链表中并没有像数组一样需要挪动一半或者多个的元素的位置和复制元素等。也是因为这样它的移动和修改操作的效率非常高为O(1)。 但是在查询的时候,当我们需要访问链表中某一个值的时候,就相对变得复杂了,为O(N)。
我们来看看一下的链表时间复杂度:
| 操作类型 | 时间复杂度 |
|---|---|
| 查询上一个 (prepend) | O(1) |
| 查询下一个 (append) | O(1) |
| 查询某一个元素 (lookup) | O(N) |
| 新增结点 (insert) | O(1) |
| 删除结点 (delete) | O(1) |
看完Array和Linked List的两种数据结构的特性后,我们可以发现是没有完美的数据结构的。如果有完美的那就不需要Array或者Linked List并存了。所以我们需要看场景来决定我们需要用那种数据结构。
「三」跳表 Skip List
后续有技术科学家对链表进行了优化,诞生出第三个数据结构叫做跳表(Skip List)。跳表可能有些小伙伴没有怎么接触过,但是其实它一直都在我们身边的应用中使用。在Redis里面就使用了跳表。不过面试过程中并不会给大家出跳表的题目来写程序,所以我们只需要理解它的原理即可。
跳表的核心是为了优化链表元素随机访问的时间复杂度过高的问题 (O(n))。
这个优化的中心思想其实是贯穿于整个算法数据结构,甚至也贯穿于整个数学与物理的世界。那就是
升维思想 / 空间换时间- 顾名思义就是在原有的链表中添加第二维的链表叫第一级索引。
添加第一级索引
我们看看下面图什么是一级索引:
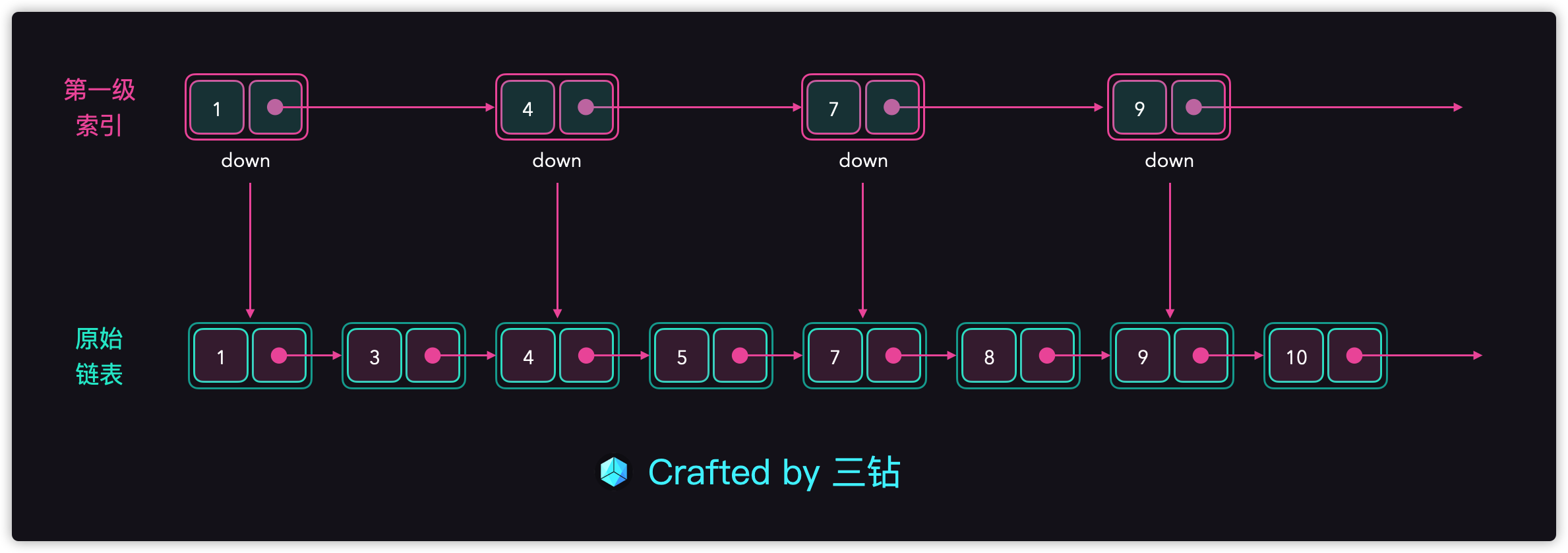
- 首先索引的第一个索引指向头 (head),也就是第一个元素 (1);
- 然后索引的下一个元素指向的就是next + 1,也就是第三个元素 (4);
- 换句话来说,就是第一级索引的元素比原始链表走快2倍的速度;
假设现在我们需要访问结点7,添加了这个索引后,是怎么提高了访问速度呢?我们来看看下面的图:

- 首先从第一级索引中走到索引7;
- 然后从索引7下来找到第7个结点;
- 这里总共的步数4步降到2步就能找到第7个结点;
虽然说速度是快了,但是能不能更快呢?可以的,只需要我们再叠加维度,用空间换时间的中心思想即可。
添加第二级索引
第二级索引比第一级的索引再走快一步,那就是每次走两步,也就是next+2。这样访问结点的时候就更快了。首先我们来看看加入第二级索引后的结构图:
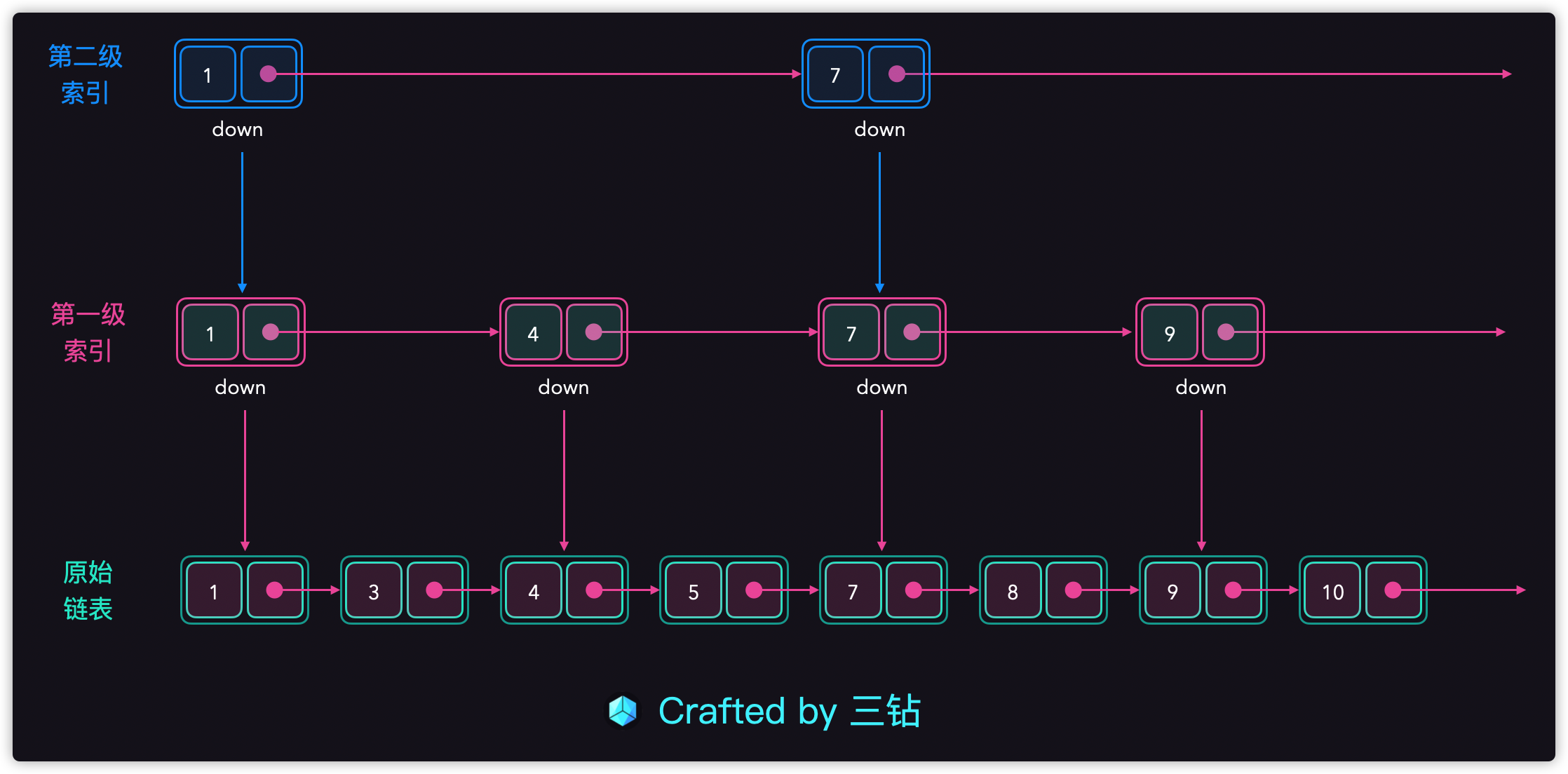
- 同理二级索引的第一个是指向一级索引的第一个,最终指向的是头 (head);
- 二级索引的第个人结点指向的就是结点7,因为二级索引是next+2,每次跳3步的进行步伐;
加入了二级索引后,我们访问结点7的时候是怎么样的呢?
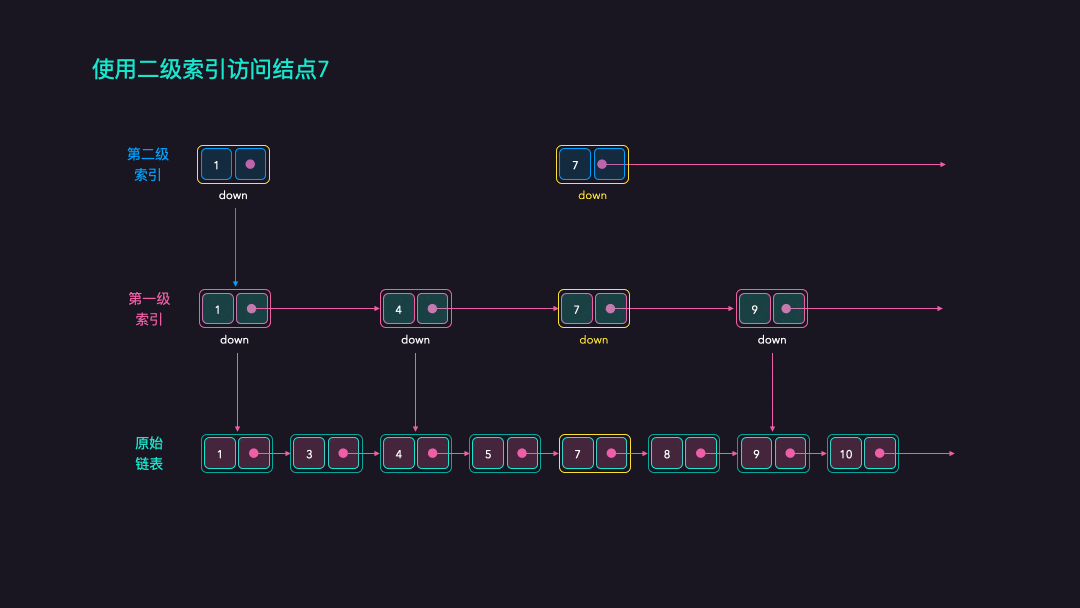
- 维度升级到第二级时,只需要1步就能到达结点7的索引;
- 加入二级索引后,我们从4步降到1步完成结点7的访问;
所以清晰看到,当我们升级多一层的维度后,链表的访问速度也会相对应的提升。也就是说,在一个非常长的链表中,我们可以加入N级索引,也就是提高N层的维度就可以提高这个链表访问的速度。总体来说我们就是需要添加
log2n个级索引,来达到最高级索引维度。
跳表查询的时间复杂度分析
- 首先每一级索引我们提升了2倍的跨度,那就是减少了2倍的步数,所以是n/2、n/4、n/8以此类推;
- 第 k 级索引结点的个数就是 n/(2^k);
- 假设索引有 h 级, 最高的索引有2个结点;
- n/(2^h) = 2, 从这个公式我们可以求得 h = log2(n)-1;
- 所以最后得出跳表的时间复杂度是
O(log n)
跳表查询的空间复杂度分析
- 首先原始链表长度为n
- 如果索引是每2个结点有一个索引结点,每层索引的结点数:n/2, n/4, n/8 ... , 8, 4, 2 以此类推;
- 或者所以是每3个结点有一个索引结点,每层索引的结点数:n/3, n/9, n/27 ... , 9, 3, 1 以此类推;
- 所以空间复杂度是
O(n);
跳表现实中的形态
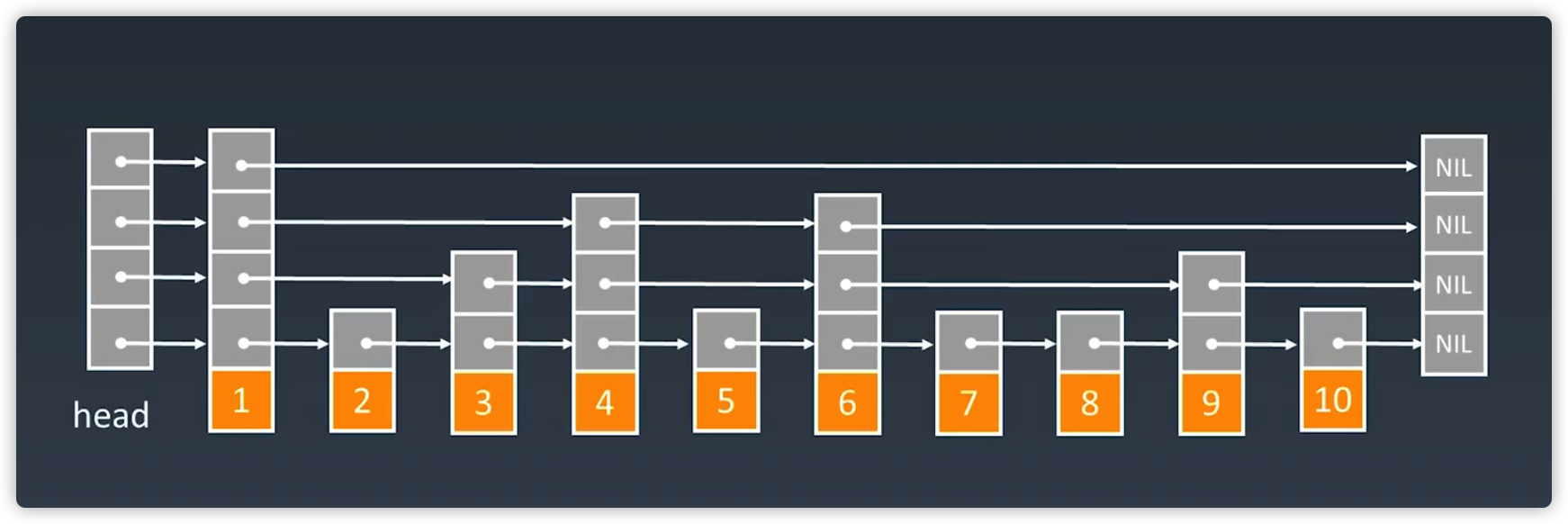
- 在现实使用中,链表的索引并不是那么整齐和有规则的;
- 这个是因为在元素增加与删除的过程中会有所变化;
- 最后经过多次改动之后,有一些索引会跨步多几步或者少哭跨几步;
- 而且维护成本相对要高 - 新增或者删除时需要把所有索引都更新一遍;
- 最后在新增和删除的过程中的更新,时间复杂度也是
O(log n);
升维思想和空间换时间的思维,我们一定要记下来,并且融会贯通。后面在解决相应的面试题的时候我们会经常用到这种思维。比如:树,二叉搜索树等经常用高级数据库结构。
「四」工程中的应用
链表在日常工程中其实应用是很多的,但是因为这些都属于高级的数据结构了,无论是Java也好、C++、JavaScript还是Go语言,这些语言里面都提供了封装好的数据结构,我们只需要直接使用就可以了。
链表的应用
链表最常见的一个应用就是LRU Cache,没有接触过的小伙伴,可以百度一下深挖一下。然后这里附上一道Leetcode的题目[面试题 16.25. LRU缓存,这道题的话使用双链表就可以实现。有兴趣的小伙伴可以尝试实现。
跳表的应用
跳表的话在Redis中就有应用到。 想了解更多的小伙伴可以搜索Redis的跳跃表进深挖。
「终」总结
- 数据结构:
- 数组:随机查询快
O(1),但是删除与插入较慢O(n); - 链表:删除与插入快
O(1),但是随机查询慢O(n); - 跳表:为了提高链表的随机查询而生的,随机查询能提升到
O(log n),但是维护成本高;
- 数组:随机查询快
- 思维重点:
- 升维思想 + 空间换时间
- 应用:
- 链表:LRU Cache
- 跳表:Redis
我是三钻,一个在技术银河中等和你们一起来终身漂泊学习。 点赞是力量,关注是认可,评论是关爱!下期再见 👋!
公众号《技术银河》回复"算法资料",可以获得这个系列文章的PDF版和其他资料!
系列阅读
- 《如何高效学习数据结构与算法》 —— 到了如今,如果想成为一个高级开发工程师或者进入大厂,不论岗位是前端、后端还是AI,算法都是重中之重。也无论我们需要进入的公司的岗位是否最后是做算法工程师,前提面试就需要考算法。所以小时不学算法,长大掉头发。
- 《分析时间与空间复杂度》 —— 算法的核心时间和空间复杂度,《数据结构与算法》都是围绕着这个核心开展的。它的存在也是为了解决我们在编程的过程中性能问题,同时也让我们有更高级的思维和思路,写出更优质的程序。
