

css部分
需要了解这些问题。

css盒模型
分为标准盒模型和IE模型,盒模型由border、padding、content四个部分组成。
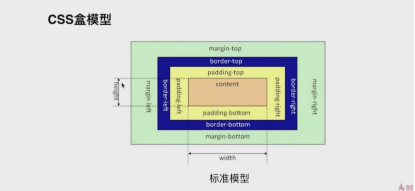
css盒模型的区别
标准盒模型的长宽以content为主,IE盒模型的长宽是包括margin、border、padding、content这四个部分。
css如何设置盒模型的类别
box-sizing: content-box(标准模型) box-sizing: border-box(IE模型)
js如何获取盒模型对应的长宽
- dom.style.width/height : 只能取出内联样式的宽和高 eg:
- dom.currentStyle.width/height 获取即时计算的样式,但是只有 IE 支持,要想支持其他浏览器,可以通过下面的方式
- window.getComputedStyle(dom).width/heigt 兼容性更好。
- dom.getBoundingClientRect().width/height: 这个较少用,主要是要来计算在页面中的绝对位置。
边距重叠
什么是边距重叠呢?
边界重叠是指两个或多个盒子(可能相邻也可能嵌套)的相邻边界(其间没有任何非空内容、补白、边框)重合在一起而形成一个单一边界。
- 父子重叠的边距重叠问题
<style>
.parent {
background: #e7a1c5;
}
.parent .child {
background: #c8cdf5;
height: 100px;
margin-top: 10px;
}
</style>
<section class="parent">
<article class="child"></article>
</section>
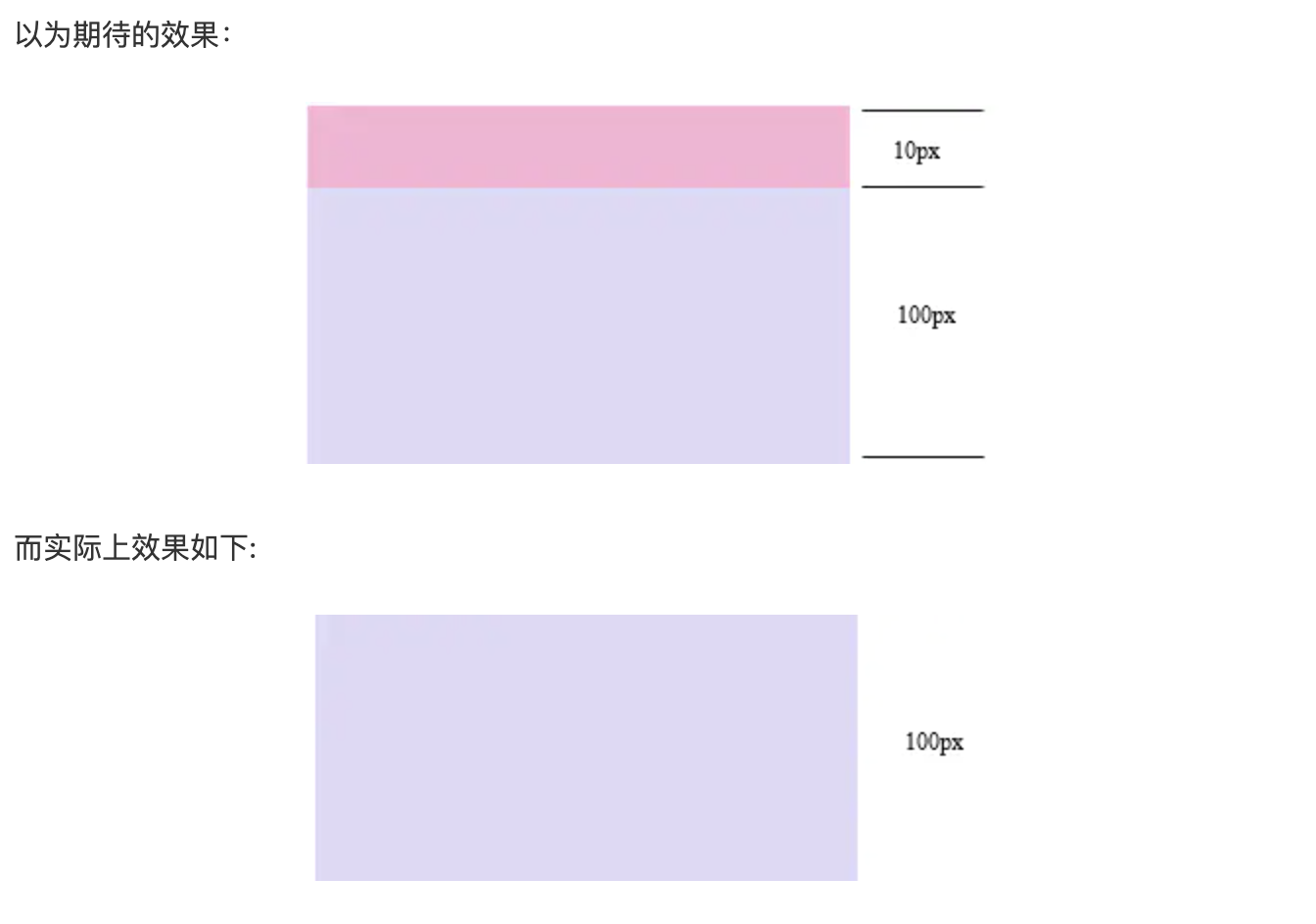
- 兄弟元素的边界重叠
<style>
#margin {
background: #e7a1c5;
overflow: hidden;
width: 300px;
}
#margin > p {
background: #c8cdf5;
margin: 20px auto 30px;
}
</style>
<section id="margin">
<p>1</p>
<p>2</p>
<p>3</p>
</section>

- 空元素的边界重叠
假设有一个空元素,它有外边距,但是没有边框或填充。在这种情况下,上外边距与下外边距就碰到了一起,它们会发生合并:

BFC
解决上述问题的其中一个办法就是创建 BFC。BFC 的全称为 Block Formatting Context,即块级格式化上下文。
- 处于同一个 BFC 中的元素相互影响,可能会发生 margin collapse;
- BFC 在页面上是一个独立的容器,容器里面的子元素不会影响到外面的元素,反之亦然;
- 计算 BFC 的高度时,考虑 BFC 所包含的所有元素,包括浮动元素也参与计算;
- 浮动盒的区域不会叠加到 BFC 上;
创建BFC
- 根元素或包含根元素的元素
- 浮动元素(元素的 float 不是 none)
- 绝对定位元素(元素的 position 为 absolute 或 fixed)
- 行内块元素(元素的 display 为 inline-block)
- 表格单元格(元素的 display为 table-cell,HTML表格单元格默认为该值)
- 表格标题(元素的 display 为 table-caption,HTML表格标题默认为该值)
- 匿名表格单元格元素(元素的 display为 table、
table-row、 table-row-group、table-header-group、``table-footer-group(分别是HTML table、row、tbody、thead、tfoot的默认属性)或 inline-table) - overflow 值不为 visible 的块元素
- display 值为 flow-root 的元素
- contain 值为 layout、content或 strict 的元素
- 弹性元素(display为 flex 或 inline-flex元素的直接子元素)
- 网格元素(display为 grid 或 inline-grid 元素的直接子元素)
- 多列容器(元素的 column-count 或 column-width 不为 auto,包括 ``column-count 为 1)
- column-span 为 all 的元素始终会创建一个新的BFC,即使该元素没有包裹在一个多列容器中(标准变更,Chrome bug)。
BFC的使用场景
- 不和浮动元素重叠
- 清除元素内部的浮动
- 防止垂直margin重叠 参考地址: juejin.cn/post/684490…
dom部分
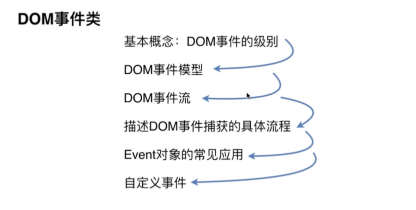
dom 事件类别

- DOM0 直接在元素节点上添加onClick类似的事件。
- DOM2 在节点上添加addEventListener监听事件。
- DOM3 在 DOM2 的基础上添加更多的监听事件,同时允许自定义事件。 参考: juejin.cn/post/684490…
DOM事件流
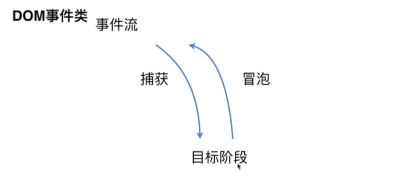
- DOM捕获过程
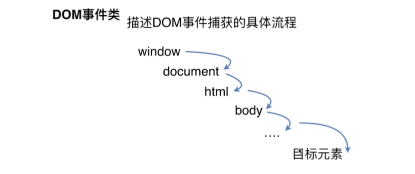
- DOM 的冒泡过程是反过来的。
DOM自定义事件
- 使用Event构造函数创建:
var event = new Event('build');
// Listen for the event.
elem.addEventListener('build', function (e) { ... }, false);
// Dispatch the event.
elem.dispatchEvent(event);
这里build是自创的事件名。dispatchEvent()用于触发事件。 绝大多数现代浏览器中都会支持这个构造函数(Internet Explorer 例外)。 要了解更为复杂的方法,可参考下面的 过时的方法 一节。 2. 使用CustomEvent床架:
var event = new CustomEvent('build', {
'detail': elem.dataset.time,
bubbles: true,
});
// Listen for the event.
elem.addEventListener('build', function (e) {
log('The time is: ' + e.detail);
}, false);
// Dispatch the event.
elem.dispatchEvent(event);
这里在创建的时候设置了detail属性,在监听的事件那块可以拿到数据。注意只能使用detail属性来传递数据。bubbles来设置是否在冒泡阶段触发。 3. 使用createEvent方法,比较老的方法。
// 创建事件
var event = document.createEvent('Event');
// 定义事件名为'build'.
event.initEvent('build', true, true);
// 监听事件
elem.addEventListener('build', function (e) {
// e.target matches elem
}, false);
// 触发对象可以是任何元素或其他事件目标
elem.dispatchEvent(event);
DOM常见事件。
-
event.preventDefault: Event 接口的 preventDefault()方法,告诉user agent:如果此事件没有被显式处理,它默认的动作也不应该照常执行。此事件还是继续传播,除非碰到事件侦听器调用stopPropagation() 或stopImmediatePropagation(),才停止传播。 大白话就是阻止事件的默认行为的发生(比如点击复选框默认勾选),但是该事件还是会照常传播,捕获和冒泡会继续执行,除非使用stopPropagation() 或stopImmediatePropagation()阻止了传播。
-
event.stopPropagation: 阻止捕获和冒泡阶段中当前事件的进一步传播。至于是在阻止捕获还是阻止冒泡,和event定义的第二个参数有关系,默认为false,在冒泡阶段。
-
event.stopImmediatePropagation: 阻止事件冒泡并且阻止相同事件的其他侦听器被调用。
不同点 stopPropagation可以阻止事件冒泡,但不会影响改事件的其他监听方法执行,而stopImmediatePropagation不仅阻止事件冒泡,还会阻止该事件后面的监听方法执行
-
event.currentTarget event.currentTarget 当事件遍历DOM时,标识事件的当前目标。它总是引用事件处理程序附加到的元素
-
event.target Event.target 对触发事件的对象的引用(即它标识事件发生的元素)
target在事件流的目标阶段;currentTarget在事件流的捕获,目标及冒泡阶段。只有当事件流处在目标阶段的时候,两个的指向才是一样的, 而当处于捕获和冒泡阶段的时候,target指向被单击的对象而currentTarget指向当前事件活动的对象(一般为父级)。
也就是说target指的是事件设定的控件本身,currentTarget指的是事件传播过程中的当前元素。
http部分

http 主要特点
特点: 简单快速、灵活、无状态、无连接
简单快速: 所有资源都是通过统一资源符进行访问的,格式固定,比较简单。 灵活: http 头部会有数据类型的记录,通过http协议可以进行各种数据类型的传输。 无连接:每次连接完会断开。 无状态:客户端和服务器进行http请求,每次连接是没法区分和上一次连接是不是同一身份,应为http本身不保存状态。
http 报文的组成部分。
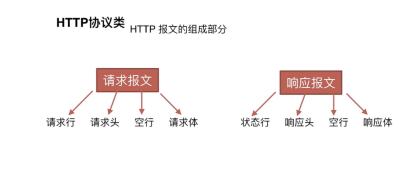
- 请求行:请求行由请求方法、URL和HTTP协议版本3个字段组成,它们用空格分隔。
- 请求头部: 请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。请求头部通知服务器有关于客户端请求的信息,
通用首部(General Header) 请求首部(Request Header) 响应首部(Response Header) 实体首部(Entity Header Fields)
- 空行:最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
- 请求体:请求数据不在GET方法中使用,而是在POST方法中使用。POST方法适用于需要客户填写表单的场合。与请求数据相关的最常使用的请求头是Content-Type和Content-Length。
响应报文组成部分:响应行、响应头、空行、响应体
状态行 : HTTP-Version Status-Code Reason-Phrase CRLF
HTTP-Version 服务器HTTP协议的版本 Status-Code 服务器发回的响应状态代码 Reason-Phrase 状态代码的文本描述
http 的方法

get 方法和 post 方法的区别

http 状态码
5大类型:

具体状态码:


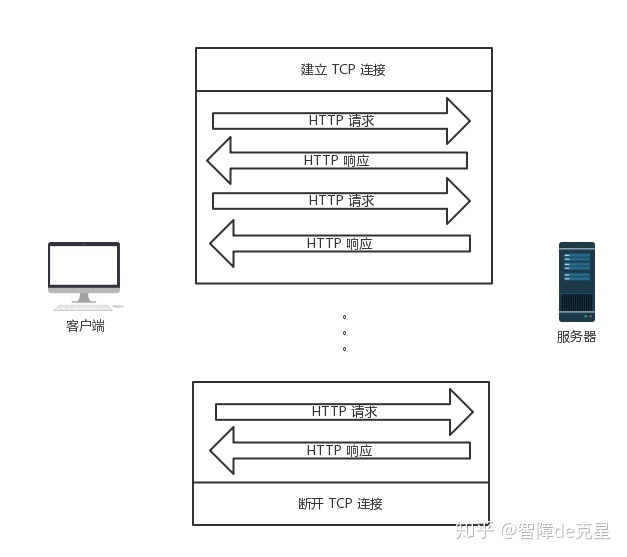
http 持久连接

http 管线化
在持久化的前提下,多个请求按正常情况应该如下:
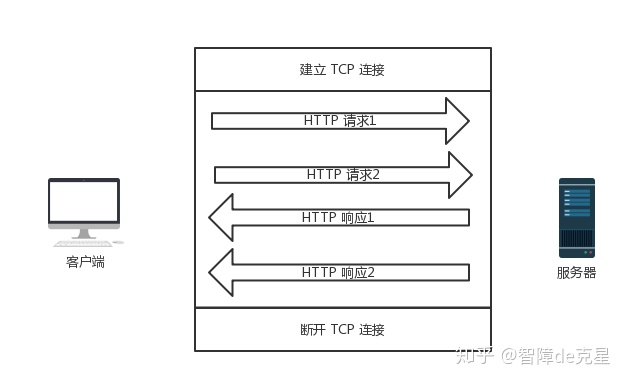
管线化要点:

原型链类
有以下几个问题
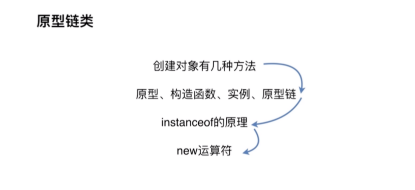
对象的创建方法有几种
- 字面量
var o1 ={name: '01'}
var o11 = new Object({name: 'o11'});
- 显式构造函数
var M = function(){
this.name = 'o2'
}
var o2 = new M();
- Object.create()方法
var P = {name: 'o3'};
var o3 = Object.create(P);
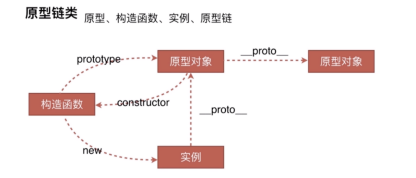
原型
instanceof原理
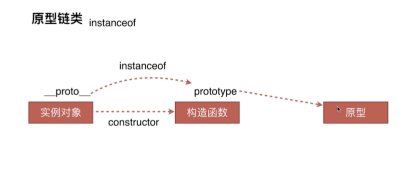
var M = { name: '03' };
o3 = new M();
o3 instanceof M // true
o3.__proto__ === M.prototype // true
M.prototype.__proto__ == Object.prototype // true
o3.__proto__.constructor == M // true
有没有发现如果一直依靠 instaceof 来判断原型,只要是原型链上有相同的类型,返回就是true,这样也就出现了一个问题,不准确。例如: o3 instanceof Object 为true,问题我们需要的的原型应该是M才对啊。如何准确判别呢? o3.proto.constructor == M // true
利用原型对象的构造函数来进行判断,更为准确。
new 运算符

var new2 = function(func){
var o = Object.create(func.prototype)
var k = func.call(o)
// 构造函数返回是否是对象
if(typeof k = 'object'){
return k;
}else{
return o
}
}
Object.create()方法
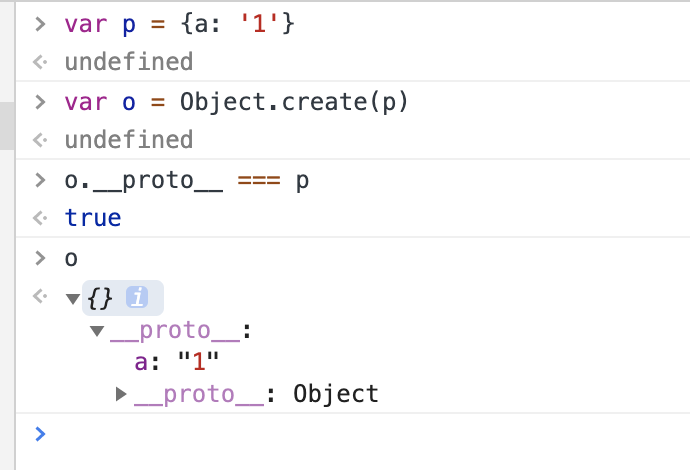
从这可以看出,Object.create()的创建过程是先创建一个空对象o,然后使用__propo__属性指向原型对象p,通过原型链拿到属性的,和字面量和构造函数生成的对象是不一样的。
对象与继承关系

类的声明
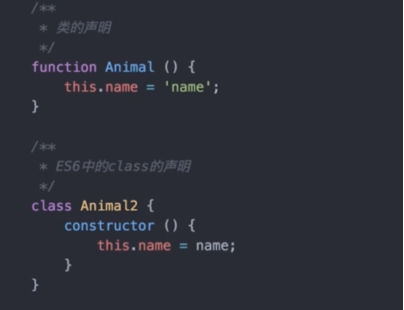
继承方式
- 借助构造函数实现继承
function Parent1(){
this.name = 'parent1'
}
Parent1.prototype.say = function(){}
function Child1(){
Parent1.call(this)
this.type = 'child1'
}
new Child1().say() // 报错,拿不到say属性
缺点: 这种方式只能部分继承,只能拿到父类构造函数里的成员变量、方法,不能拿到原型链的内容
- 借助原型链实现继承
function Parent2(){
this.name = 'parent2'
this.play = [1, 2, 3]
}
function Child2(){
this.type = 'child2'
}
Child2.prototype = new Parent2(); // 访问父类的原型
var s1 = new Child2();
var s2 = new Child2();
s1.play.push(4)
console.log(s1.play, s2.play) // [1, 2, 3, 4], [1, 2, 3, 4]
显而易见,原型链继承使用的是同一个原型对象,里面的属性是公用的,对象之间属性操作是会相互影响的。没有隔离开来。 3. 组合方式继承
function Parent3(){
this.name = 'parent3'
this.play = [1, 2, 3]
}
function Child3(){
Parent3.call(this)
this.type = 'child3'
}
Child3.prototype = new Parent3();
var s3 = new Child3();
var s4 = new Child3();
s4.play.push(4)
console.log(s3.play, s4.play) // [1, 2, 3], [1, 2, 3, 4]
优点:此方法结合上述两种方法的优点,就可实现继承父类的所有属性,同时属性不相互影响。 缺点: 这种方式会调用两次Parent3构造函数。
优化方案一:
function Parent4(){
this.name = 'parent4'
this.play = [1, 2, 3]
}
function Child4(){
Parent4.call(this)
this.type = 'child4'
}
Child4.prototype = Parent4.prototype;
var s5 = new Child4();
var s6 = new Child4();
s6.play.push(4)
console.log(s5.play, s6.play) // [1, 2, 3], [1, 2, 3, 4]
console.log(s5 instanceof Child4, s5 instanceof Parent4) // true true
console.log(s5.__proto__.constructor === Parent4)
优点:这个方案可以避免多次调用父类的构造函数 缺点:s5.proto.constructor === Parent4 ,显而易见没法区分子类与父类的构造函数。
优化方案二:
function Parent5(){
this.name = 'parent5'
this.play = [1, 2, 3]
}
function Child5(){
Parent5.call(this)
this.type = 'child5'
}
Child5.prototype = Object.create(Parent5.prototype);
Child5.prototype.constructor = Child5;
var s5 = new Child5();
var s6 = new Child5();
s6.play.push(4)
console.log(s5.play, s6.play) // [1, 2, 3], [1, 2, 3, 4]
此方法同时既满足了实现原型链的继承,同时改变了子类构造函数的指向。 此时 s5.proto.constructor === Child5,也可以拿到父类的属性。
小疑问: 为什么不在上面也修改constructor指向呢?
Child4.prototype = Parent4.prototype;
Child4.prototype.constructor = Child4;
答:因为上面的对象是共用的同一个原型对象,会造成所有的子类相互影响,为了避免这种问题,只能各自生成新的对象,才能避免互不打扰,此时Object.create 方法最为合适。
通信类
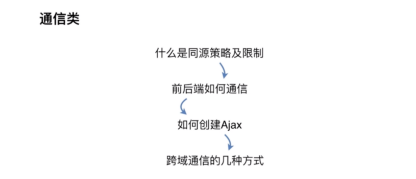
什么是同源策略及限制

同源指的是: 同协议、同域名、同端口。
前后端通讯的方式
- Ajax
- WebSocket
- CORS
如何创建Ajax

function ajax(url, success, fail){
// 1. 创建连接
var xhr = null;
xhr = XMLHttpRequest? new XMLHttpRequest(): new ActiveXObject("Microsoft.XMLHTTP");
// 2. 连接服务器
if(请求方式为 'get'){
url = url+'?'+拼接参数
xhr.open('get', url, true)
}else{
xhr.open('post', url, true);
xhr.setRequestHeader('Content-type', 'application/x-www-form-urlencoded')
}
// 3. 发送请求
if(请求方式为 'get'){
xhr.send();
}else{
xhr.send(data);
}
// 4. 接受请求
xhr.onreadystatechange = function(){
if(xhr.readyState == 4){
if(xhr.status == 200){
success(xhr.responseText);
} else { // fail
fail && fail(xhr.status);
}
}
}
// 这里也可以处理数据,这是加载完时的回调函数
xmlhttp.onload = function () {
// 处理取回的数据(在 xmlhttp.response 中找到)
};
}
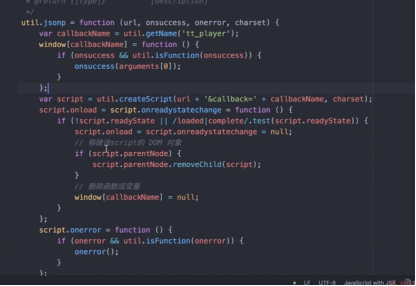
跨域通讯的几种方式
- JSONP
- Hash方式(iframe的方式,监听hash变化)
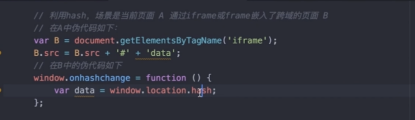
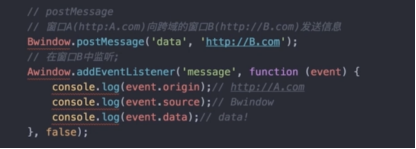
- postMessage方式
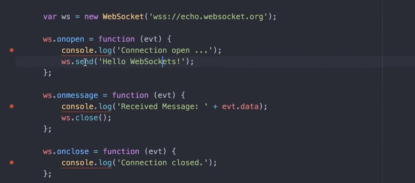
- webSocket方式
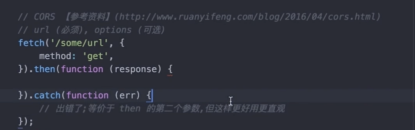
- CROS方式(配置自行查找)
安全类
CSRF
基本概念
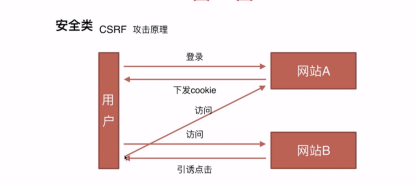
CSRF , 通常称为跨站请求伪造,英文名Cross-site request forgery 缩写CSRF
攻击原理
CSRF防御措施
- Referer 验证 大家都知道 HTTP 头中有一个 Referer 字段,这个字段用以标明请求来源于哪个地址。通过在网站中校验请求的该字段,我们能知道请求是否是从本站发出的。我们可以拒绝一切非本站发出的请求,这样避免了 CSRF 的跨站特性。
const { parse } = require('url');
module.exports = class extends think.Logic {
indexAction() {
const referrer = this.ctx.referrer();
const {host: referrerHost} = parse(referrer);
if(referrerHost !== 'xxx') {
return this.fail('REFERRER_ERROR');
}
}
}
这种方式利用了客户端无法构造 Referrer 的特性,虽然简单,不过当网站域名有多个,或者经常变换域名的时候会变得非常的麻烦,同时也具有一定的局限性。
- token验证 由于 CSRF 是利用了浏览器自动传递 cookie 的特性,另外一个防御思路就是校验信息不通过 cookie 传递,在其他参数中增加随机加密串进行校验。
-
随机字符串:为每一个提交增加一个随机串参数,该参数服务端通过页面下发,每次请求的时候补充到提交参数中,服务端通过校验该参数是否一致来判断是否是用户请求。由于 CSRF 攻击中攻击者是无从事先得知该随机字符串的值,所以服务端就可以通过校验该值拒绝可以请求。
-
JWT:实际上除了 session 登录之外,现在越来越流行 JWT token 登录校验。该方式是在前端记录登录 token,每次请求的时候通过在 Header 中添加认证头的方式来实现登录校验过程。由于 CSRF 攻击中攻击者无法知道该 token 值,通过这种方式也是可以防止 CSRF 攻击的。(这种方法把token隐藏再请求头里)
XSS
XSS,即 Cross Site Script,中译是跨站脚本攻击;其原本缩写是 CSS,但为了和层叠样式表(Cascading Style Sheet)有所区分,因而在安全领域叫做 XSS。
XSS 攻击是指攻击者在网站上注入恶意的客户端代码,通过恶意脚本对客户端网页进行篡改,从而在用户浏览网页时,对用户浏览器进行控制或者获取用户隐私数据的一种攻击方式。
攻击者对客户端网页注入的恶意脚本一般包括 JavaScript,有时也会包含 HTML 和 Flash。有很多种方式进行 XSS 攻击,但它们的共同点为:将一些隐私数据像 cookie、session 发送给攻击者,将受害者重定向到一个由攻击者控制的网站,在受害者的机器上进行一些恶意操作。
XSS攻击可以分为3类:反射型(非持久型)、存储型(持久型)、基于DOM。
渲染机制类
浏览器渲染机制
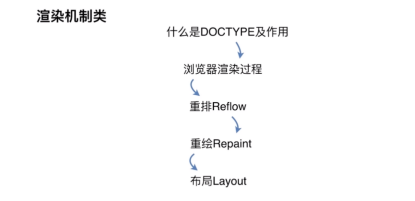


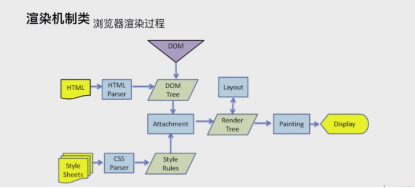
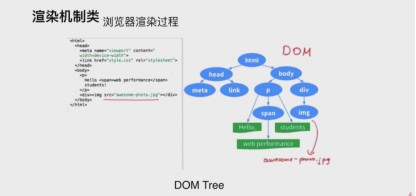
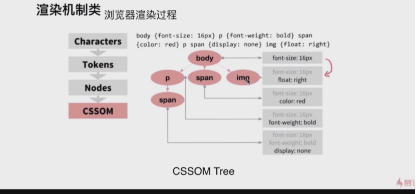
重排

重绘

运行机制
- 如何理解js的单线程?
- 什么是任务队列
- 什么是Event Loop
- 哪些语句会放到异步队列中
- 理解语句放入异步任务队列的时机
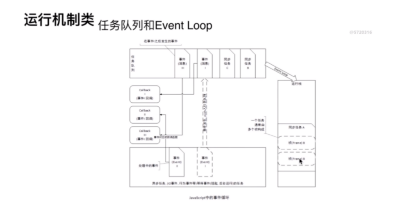
-
同一时间内只能执行一个事件被称为单线程。
-
任务队列分同步任务和异步任务,同步任务直接进入执行栈里,异步任务则以回调的形式挂在任务队列中,直到执行栈空了,才从任务队列中拿出有返回结果的回调到执行队列,直到任务队列清空。任务队列即是存放异步任务回调的一个中间队列。
-
事件循环过程: 首先要知道,JS分为同步任务和异步任务 同步任务都在主线程(这里的主线程就是JS引擎线程)上执行,会形成一个执行栈 主线程之外,事件触发线程管理着一个任务队列,只要异步任务有了运行结果,就在任务队列之中放一个事件回调 一旦执行栈中的所有同步任务执行完毕(也就是JS引擎线程空闲了),系统就会读取任务队列,将可运行的异步任务(任务队列中的事件回调,只要任务队列中有事件回调,就说明可以执行)添加到执行栈中,开始执行。一直不断放入队列和取出到执行栈的过程形成了事件循环这个过程。
-
什么情况下会执行异步任务: setTimeout 和 setInterval事件、dom事件、es6的promise事件、网络请求等等。
-
异步任务不会立即执行,而是会在同步任务执行完之后读取任务队列,取出顺序是按异步任务返回结果的时间点来算的。同时 异步任务最小执行时间是4ms,低于这个时间也会自动改成这个时间来执行,所以0毫秒和4毫秒是没区别的。 参考:juejin.cn/post/684490…
页面优化类
优化措施有哪几种
- 资源合并,减少http请求
- 非核心代码异步加载 --> 异步加载的方式 --> 异步加载的区别
- 利用浏览器缓存 --> 缓存的分类 --> 缓存的原理
- 使用CDN加速

异步加载
异步加载的方式
- 动态脚本加载: 动态加载包括一下3种方式
- 直接document.write
<script language="javascript">
document.write("<script src='test.js'><\/script>");
</script>
- 动态改变已有script的src属性
<script src='' id="s1"></script>
<script language="javascript">
s1.src="test.js"
</script>
- 动态创建script元素
<script>
var oHead = document.getElementsByTagName('HEAD').item(0);
var oScript= document.createElement("script");
oScript.type = "text/javascript";
oScript.src="test.js";
oHead.appendChild( oScript);
</script
- defer
<script src='' id="s1" defer></script>
- async
<script src='' id="s1" async></script>
异步加载的区别
- 没有标记defer和async 的脚本即是加载解析到它就开始执行,而非异步的。
- defer 和 async 都是异步加载,只不过defer是在html全部解析完才执行,如果是多个,按照加载的顺序依次执行
- async 脚本解析和html解析是同步进行的,当脚本加载完就会执行,不用考虑html解析是否完成,多个async脚本的执行顺序与加载顺序无关。
浏览器缓存
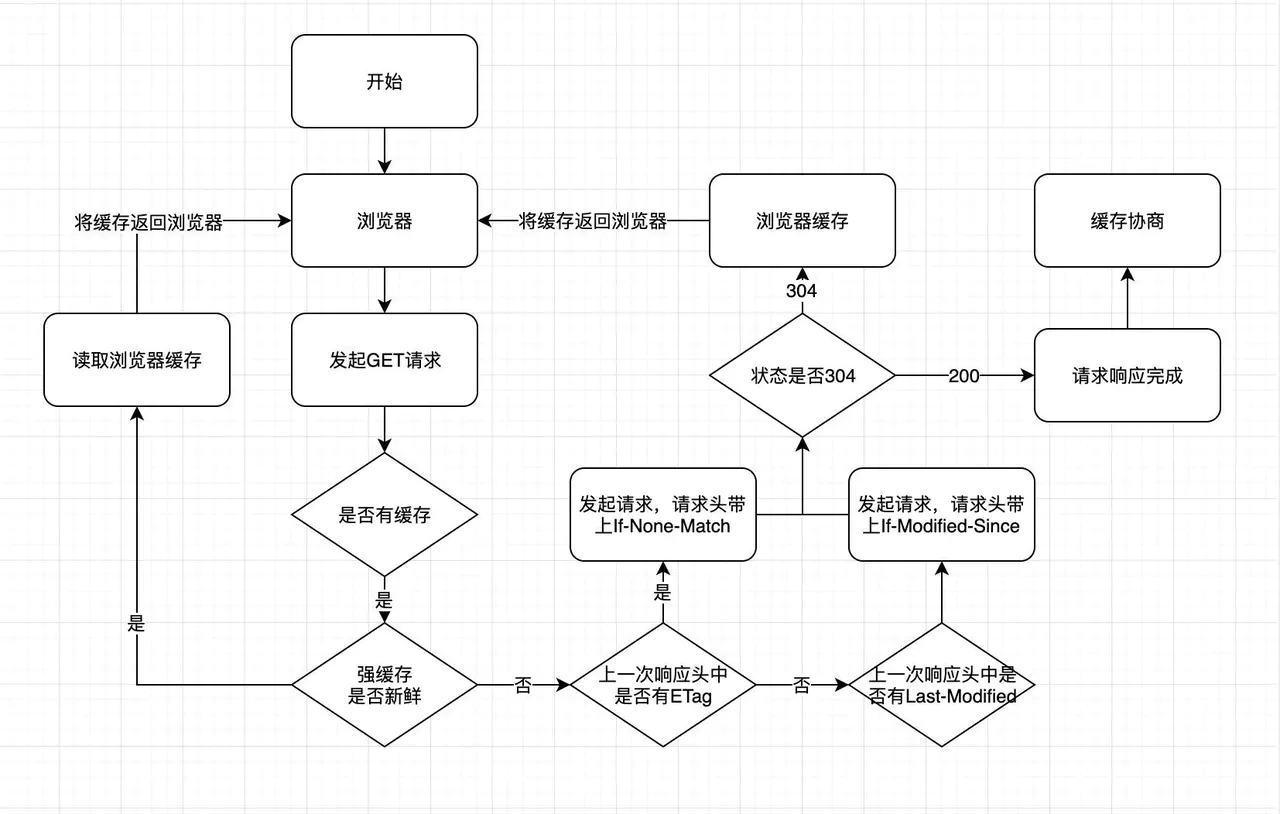
- 强缓存 含义: 所谓强缓存就是只要在有效时间内,无需请求服务器,直接使用缓存信息。 相关字段: Expires 服务器绝对时间,每次会与系统时间进行比较 Cache-Control max-age = 3600 相对时间, 优先级比Expires高 Pragma Pragma 只有一个属性值,就是 no-cache不使用强缓存,在 3 个头部属性中的优先级最高。
- 协商缓存 含义: 浏览器知道本地缓存了信息,但是不知道信息是否可用,是否过期,于是会请求一下缓存是否可用。 相关字段: Last-Modified:上次修改时间/If-Modified-Since:请求返回的是否修改的时间
Last-Modified/If-Modified-Since 的值代表的是文件的最后修改时间,第一次请求服务端会把资源的最后修改时间放到 Last-Modified 响应头中,第二次发起请求的时候,请求头会带上上一次响应头中的 Last-Modified 的时间,并放到 If-Modified-Since 请求头属性中,服务端根据文件最后一次修改时间和 If-Modified-Since 的值进行比较,如果相等,返回 304 ,并加载浏览器缓存。
Etag/If-None-Match:
ETag/If-None-Match 的值是一串 hash 码,代表的是一个资源的标识符,当服务端的文件变化的时候,它的 hash码会随之改变,通过请求头中的 If-None-Match 和当前文件的 hash 值进行比较,如果相等则表示命中协商缓存。ETag 又有强弱校验之分,如果 hash 码是以 "W/" 开头的一串字符串,说明此时协商缓存的校验是弱校验的,只有服务器上的文件差异(根据 ETag 计算方式来决定)达到能够触发 hash 值后缀变化的时候,才会真正地请求资源,否则返回 304 并加载浏览器缓存。
- ETag/If-None-Match 的出现主要解决了 Last-Modified/If-Modified-Since 所解决不了的问题:
如果文件的修改频率在秒级以下,Last-Modified/If-Modified-Since 会错误地返回 304 如果文件被修改了,但是内容没有任何变化的时候,Last-Modified/If-Modified-Since 会错误地返回 304 ,上面的例子就说明了这个问题
参考地址: juejin.cn/post/684490…
错误监控类
我们需要了解3个问题:
- 前端错误的分类
- 错误的捕获方式
- 上报错误的基本原理
错误分类
分为即时错误(代码错误)和资源加载错误。
错误的捕获方式
即时错误的捕获方式
1)try catch 2) window.onerror
window.onerror = function (msg, url, lineNo, columnNo, error) {
var string = msg.toLowerCase();
var substring = "script error";
if (string.indexOf(substring) > -1){
alert('Script Error: See Browser Console for Detail');
} else {
var message = [
'Message: ' + msg,
'URL: ' + url,
'Line: ' + lineNo,
'Column: ' + columnNo,
'Error object: ' + JSON.stringify(error)
].join(' - ');
alert(message);
}
return false;
};
资源加载错误
1)object.onerror()
var img =document.getElementById('#img');
img.onerror = function() {
// 捕获错误
}
- performance.getEntries() 浏览器获取网页时,会对网页中每一个对象(脚本文件、样式表、图片文件等等)发出一个HTTP请求。而通过window.performance.getEntries方法,则可以以数组形式,返回这些请求的时间统计信息,每个数组成员均是一个PerformanceResourceTiming对象
(function () {
// 浏览器不支持,就算了!
if (!window.performance && !window.performance.getEntries) {
return false;
}
var result = [];
// 获取当前页面所有请求对应的PerformanceResourceTiming对象进行分析
window.performance.getEntries().forEach((item) => {
result.push({
'url': item.name,
'entryType': item.entryType,
'type': item.initiatorType,
'duration(ms)': item.duration
});
});
// 控制台输出统计结果
console.table(result);
})();
- Error 事件捕获。
window.addEventListener("error",function(ev){ console.log('捕获',ev)// 捕获错误 },true);
捕获错误事件,记住第三个参数必须是true,这样才能才捕获阶段触发。默认为false,当捕获阶段报错,后续就终止了,不存在在冒泡阶段捕获到。
上报错误的基本原理
- 采用ajax通信方式上报
- 使用img对象上报
<script type="text/javascript">
(new Image()).src = "http://xunmengren.work/fghj?ll=05678"
</script>
跨域js的运行错误捕获
- 想获取其他域下的js错误需要在script标签里添加crossorigin属性
- 服务器端要设置header('Access-Control-Allow-Origin: *') 或者 指定域名
算法类
未完待续。。。
