

系列文章
- [ CodeWar ] - 001:过滤重复字符
- [ CodeWar ] - 002:最大和最小值
- [ CodeWar ] - 003:判断质数
- [ CodeWar ] - 004:处理数组元素
- [ CodeWar ] - 005:用户分组
- [ CodeWar ] - 006:数组比对
- [ CodeWar ] - 007:找不同
- [ CodeWar ] - 008:分割字符串
- [ CodeWar ] - 009:哈希标签生成器
- [ CodeWar ] - 010:大数相加
- [ CodeWar ] - 011:最短路径
- [ CodeWar ] - 012:rgb 转 hex
- [ CodeWar ] - 013:解析化学式
题目
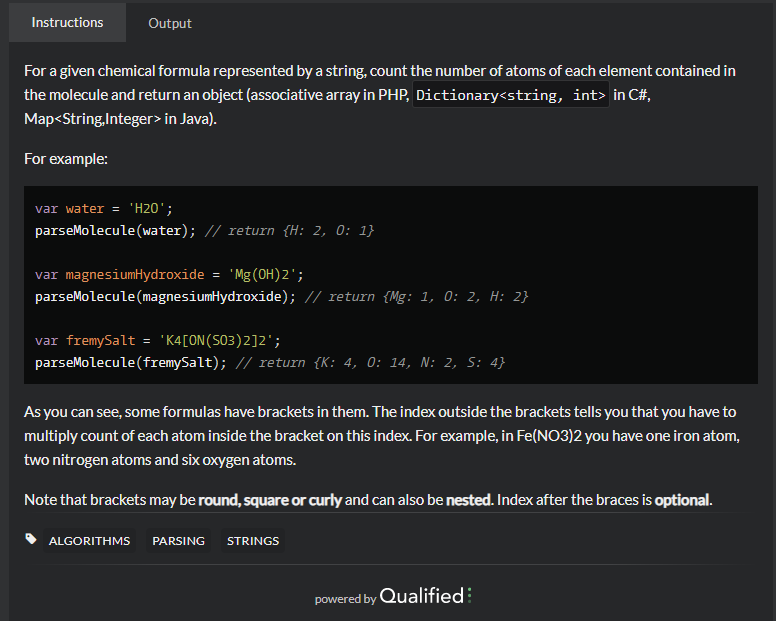
需求:
- 输入为一个化学式,要求解析其中每个元素的数量
解析
不得不说这道题确实有些难度,废话不多说,下面来分析一下思路:
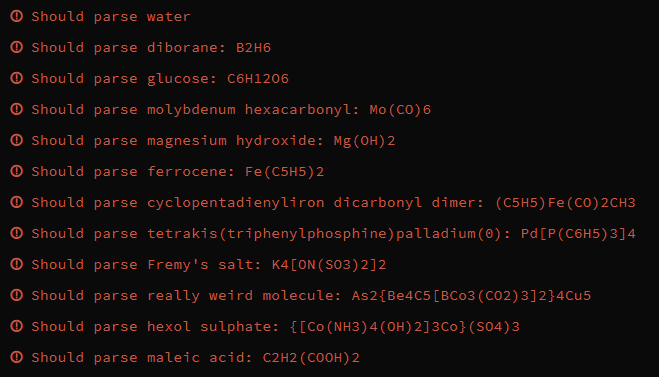
从测试用例可以看出,表达式满足一下形式:
CcN{Cc[Cc(CcC)N]N}N
注:c:字母,n:数字
而我们知道,括号之间是乘法(即 A[B(C)3]2 => A: 1, B: 2, C: 6),所以这里显然应该通过括号进行分组。
那么具体应该如何分组呢?
这里我们可以借助于正则和二维数组:
- 通过正则匹配:
大小写字母及数字,{[(,}]) - 将最外层的字母和数字写进数组的第一层
- 一旦遇到
{[(则给数组新增一层,然后重复上一步 - 一旦遇到
}])则根据其后的数字将本层拆散合并进上一层中
通过上述算法,我们就可以得到一个形如:
[A, A, B, B, B, C, C, ...]
的数组,之后通过 reduce 即可计算出每个元素的数量:
function parseMolecule(formula) {
let group,
token,
ele,
num,
stack = [[]],
reg = /([\{\[\(]|[\)\]\}]|[A-Z][a-z]?)(\d*)/g,
regLetter = /^[A-Z]/,
regBracket = /[\{\[\(]/
while ((token = reg.exec(formula))) {
ele = token[1]
num = token[2] || 1
if (regLetter.test(ele)) {
while (num--) stack.push([...stack.pop(), ele])
} else if (regBracket.test(ele)) {
stack.push([])
} else {
group = stack.pop()
while (num--) stack.push([...stack.pop(), ...group])
}
}
return stack[0].reduce((count, key) => {
count[key] = (count[key] || 0) + 1
return count
}, {})
}
优化
事实上,上述代码虽然看起来比较复杂,但逻辑已经相当清晰了。
那么到底还能怎么优化呢?
同样还是分组的思路,不过这里我们不是通过二维数组,而是将带有括号的部分直接提取出来,然后重复替换成一个新的字符串。
比如:
A(BC2)2 => ABC2BC2
这样,我们对变形后的字符串再次分组匹配:将数字和元素分组,就可以统计元素的数量了:
const parseMolecule = (formula) => {
const ret = {},
regBra = /[\[\(\{]([a-z0-9]+)[\]\)\}]([0-9]+)/gi,
regEle = /([A-Z][a-z]?)([0-9]+)?/g
while (formula !== (formula = formula.replace(regBra, (f, e, n) => e.repeat(n))));
formula.replace(regEle, (f, e, n) => (ret[e] = (ret[e] || 0) + +(n || 1)))
return ret
}
