

摘要
在这篇文章中,我将从MySQL为什么需要主从复制开始讲起,然后会提到MySQL复制的前提,bin log。
在这里会说明三种格式的bin log分别会有什么优缺点。
随后会讲到主从延迟方面的问题,我将从几个角度出发,提供一些可能造成延迟的思路。
1 为什么需要复制
MySQL内建的复制功能是构建大型,高性能应用程序的基础。随着目前并发量的增加,单机的MySQL渐渐没有办法承担这些请求,所以MySQL服务器也需要进行扩展。
MySQL的复制功能不仅可以提高可用性,还能用作灾备,数据仓库等。
2 如何复制
说到复制,那么问题的关键就在于数据从主库复制到从库时间需要多少,准确度能有多高。
对于MySQL来说,复制使用的是bin log。
对于bin log相信你不会陌生,我们在聊到MySQL的“两阶段提交”的时候有说到这个。
也就是说,MySQL会将主库记录的bin log发送到从库中,然后从库按照bin log的内容,“重放一遍”主库执行过的操作,达到主从同步的目的。
在这里我们先详细说一说bin log记录了什么。
2.1 SBR(statement-based replication)
在这种模式下,bin log会完整的记录下所执行的SQL语句。也就是说,如果使用了statement格式的bin log的话,主库执行的SQL语句就会在从库中完整的再执行一遍。
可是,这样的做法,是有可能导致主从不一致的。
例如下面这样的语句:
delete from t where a >= 1 and b => 2 limit 1;
这样的语句在从库中就不一定能够实现跟主库一样的效果。因为我们不能够确定在从库中是否走的跟主库是同样的索引,所查找的第一条数据,是不是跟主库一样的,也就可能删除的数据不是同一行。
又或者主库执行的SQL语句里面有一些锁相关的语句,也可能会造成主从不一致的问题。
但是要注意的是,NOW()函数是可以被正确执行的,因为在bin log语句中会记录时间戳。
也就是说,基于statement模式,在上下文不同的时候,是有可能造成数据不一致的。
至于其他的不安全情况,可以参考官方文档,这里不展开介绍。
2.2 RBR(row-based replication)
既然statement模式下会造成数据不一致,那么有没有一种模式是上下文无关的呢?
所以就有了row模式。
在这个模式中,bin log中只记录了所操作的行的修改情况,会精确到某一行。
比如你更新了某一行,在bin log中就会记录在id等于多少多少,某某字段等于多少多少的行中,将某个字段的值从A改成了B。
甚至是删除操作,都会记录删除了id等于多少,A字段等于多少,B字段等于多少的一行数据。
听到这里你可能会觉得很方便,也很精确,主从不再会发生不一致的情况了。甚至于删库了都不需要跑路了,只需要查看bin log就能恢复相应的数据了。
但是使用row模式同样会有一些问题。比如你在主库执行了delete from t where id < 10000这么一行sql语句,如果使用statement格式,在bin log内记录只有这么一条,但是如果你使用的是row模式,那么就需要记录10000条数据,占用很大的空间。
2.3 MBR(mixd-based replication)
于是就有了mixd模式。
混合了以上两种模式的优点,MySQL会在没有歧义的时候使用statement格式,在有歧义的时候使用row格式。
3 复制的具体过程
上面介绍了bin log的作用,以及bin log的组成形式,在这一章中我们聊一聊整个的复制流程。
我们拿《高性能MySQL》中的图来解释:
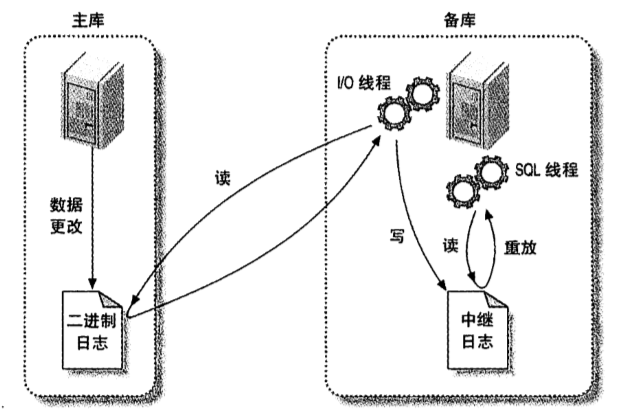
这里涉及到了有三个线程:
-
Binlog dump thread
这个线程在MySQL主库中,负责读取bin log中的内容,并将这些内容推送到从库IO进程中。 -
I/O thread
这个线程在MySQL从库中,负责跟主库建立一条长连接,并且将读取到的bin log数据保存到从库的中继日志(relay log)中。 -
SQL thread
这个线程也是在MySQL的从库中,负责读取中继日志中的内容,然后执行这些语句,将对数据的修改应用到从库中。
简单的来讲,就是主库经过两阶段提交后,把修改内容保存在了bin log中,然后把这个bin log发送给从库,让从库也执行一次,以达到同步的目的。
而这里采用了中继日志的原因是从库消费bin log的速度和主库生产bin log的速度是不一致的,所以需要一个中继日志作为缓冲。
4 复制可能造成的问题
在MySQL复制的过程中,经常出现的问题是延迟。
-
假设我们把主库一个事务提交后
bin log落盘的时间点设为t1 -
把从库接受到主库新事务写的
bin log并写入relay log的时间节点设为t2 -
把从库执行完这个新的事务的时间节点设为t3
那么执行一条事务,从库的延迟可以认为是(t3 - t1)。
也就是说,如果我们需要分析造成主从延迟的原因,应该从两个方面考虑:传输过程,以及从库消费relay log的速度。
4.1 网络问题
网络确实可能会造成主从延迟,比如主库或者从库的带宽打满,又或者是主库的bin log被设置成了row格式,导致有大量的数据需要传输,造成了主库的bin log没有及时的同步到从库中,导致了主从的延迟。
4.2 机器性能
但是除了网络,更多的是从库的消费速度,跟不上主库的生产速度。
这方面有很多原因,比如可能从库的机器配置低于主库,因为会有人觉得既然是备库,没什么请求,就把备库配置在了比较差的机器上面。
又或者在是后台的数据分析,将CPU打满。
总之,如果在从库中需要有大量的查询分析操作,需要考虑多个从库。
4.3 大事务
如果主库执行了一条耗时很长的事务,那么这条事务发送到从库中,可能也需要执行这么长的时间。而这个时候,从库是没有办法继续消费新的relay log的。这就造成了主从延迟。
4.4 锁
我们之前提到过了,不仅仅写数据会加锁,使用“当前读”,也一样可能会加锁。
所以,如果在从库上执行了一些诸如select ... for update,或者一些DDL语句,可能也会造成从库加锁,导致主从延迟。
4.5 并发
在我们上面的介绍中,SQL线程是单线程的,所以,如果能够让SQL线程可以并发消费,那么主从延迟就可以大幅度的降低了。
关于MySQL的并发复制策略,MySQL5.6开始已经正式支持了,本文不详细解释。
写在最后
首先,谢谢你能看到这里。
这一篇的文章,其实说的内容不多,大多都是一些理论性质的内容,目的是能够对MySQL的主从复制有一些大体上的了解,并且知道对于延迟方面的问题,应该从哪个方向去考虑。
至于其他更具体的操作、如何调优,以及更深的原理,我想在今后的《进阶篇》来提到。
并且,《MySQL 入门》系列到这里就完结了。希望这五篇的内容能够给你带来一些帮助,能够让你对MySQL的了解更深一些。
当然了,在学习MySQL的过程中,我可能也会有一些错误的理解,如果有哪里是不对的,希望你能指出,谢谢你!
PS:如果有其他的问题,也可以在公众号找到我,欢迎来找我玩~

