

1.this的理解
this 是执行上下文中的一个属性,它指向最后一次调用这个方法的对象。在实际开发中,this 的指向可以通过四种调用模式来判断。
- 1.第一种直接调用函数,当一个函数不是一个对象的属性时,直接作为函数来调用时,this 指向全局对象。
- 2.第二种是对象.方法调用模式,如果一个函数作为一个对象的方法来调用时,this 指向这个对象。
- 3.第三种是构造器调用模式,如果一个函数用 new 调用时,函数执行前会新创建一个对象,this 指向这个新创建的对象。
- 4.第四种是 apply 、 call 和 bind 调用模式--显式绑定,这三个方法都可以显示的指定调用函数的 this 指向。其中 apply 方法接收两个参数:一个是 this 绑定的对象,一个是参数数组。call 方法接收的参数,第一个是 this 绑定的对象,后面的其余参数是传入函数执行的参数。也就是说,在使用 call() 方法时,传递给函数的参数必须逐个列举出来。bind 方法通过传入一个对象,返回一个 this 绑定了传入对象的新函数。这个函数的 this 指向除了使用 new 时会被改变,其他情况下都不会改变。
这四种方式,使用构造器调用模式的优先级最高,然后是 apply 、 call 和 bind 调用模式,然后是方法调用模式,然后是函数调用模式。
2.this几种绑定机制:
- 全局上下文/默认绑定
- 直接调用函数
- 隐式绑定:对象.方法的形式调用
- DOM事件绑定(特殊)
- new构造函数绑定
- 箭头函数
- 显式绑定
1. 全局上下文/默认绑定
函数没有调用时,全局上下文默认this指向window, 严格模式下指向undefined。
2.直接调用函数
比如:
let obj = {
a: function() {
console.log(this);
}
}
let func = obj.a;
func();
复制代码这种情况是直接调用。this相当于全局上下文的情况。
3. 隐式绑定:对象.方法的形式调用
如果函数调用时,前面存在调用它的对象,那么this就会隐式绑定到这个对象上,称为隐式绑定;如果函数调用前存在多个对象,this指向距离调用自己最近的一个对象;还是刚刚的例子,我如果这样写:
obj.a();
复制代码
//this的隐式绑定
function fn(){ console.log(this.name)
};
let obj = {
name:'听风',
func:fn
};
obj.func()//听风
如果函数调用前存在多个对象,this指向距离调用自己最近的对象,比如这样:
function fn() {
console.log(this.name);
};
let obj = {
name: '行星飞行',
func: fn,
};
let obj1 = {
name: '听风是风',
o: obj
};
obj1.o.func() //行星飞行
//那如果我们将obj对象的name属性注释掉,现在输出什么呢?
function fn() {
console.log(this.name);
};
let obj = {
func: fn,
};
let obj1 = {
name: '听风是风',
o: obj
};
obj1.o.func() //??
这里输出undefined,大家千万不要将作用域链和原型链弄混淆了,obj对象虽然obj1的属性,但它两原型链并不相同,并不是父子关系,由于obj未提供name属性,所以是undefined。
这就是对象.方法的情况,this指向这个对象;
关于隐式丢失具体例子,可参考:www.cnblogs.com/echolun/p/1…;
关于this的练习题:www.cnblogs.com/echolun/p/1…
4. DOM事件绑定
onclick和addEventerListener中 this 默认指向绑定事件的元素。
IE比较奇异,使用attachEvent,里面的this默认指向window。
5. new+构造函数
此时构造函数中的this指向实例对象。
6. 箭头函数?
箭头函数没有this, 因此也不能绑定。里面的this会指向当前最近的非箭头函数的this,找不到就是window(严格模式是undefined)。比如:
let obj = {
a: function() {
let do = () => {
console.log(this);
}
do();
}
}
obj.a(); // 找到最近的非箭头函数a,a现在绑定着obj, 因此箭头函数中的this是obj
复制代码优先级: new > call、apply、bind > 对象.方法 > 直接调用。
显式绑定 > 隐式绑定 > 默认绑定
new绑定 > 隐式绑定 > 默认绑定
7.显式绑定:call/apply/bind的差别,有什么应用?
call/apply/bind可以显式绑定,三者的不同?
1.call、apply与bind都用于改变this绑定,但call、apply在改变this指向的同时还会执行函数,而bind在改变this后是返回一个全新的boundFunction绑定函数,这也是为什么上方例子中bind后还加了一对括号 ()的原因。
2.bind属于硬绑定,会返回一个新函数;返回的 boundFunction 的 this 指向无法再次通过bind、apply或 call 修改,所以在执行绑定函数的时候,this的指向和形参在bind方法执行的时候已经确定了,无法再次改变;call与apply的绑定只适用当前调用,调用完就没了,下次要用还得再次绑。
3.call与apply功能完全相同,唯一不同的是call方法接受的是一个参数列表,第一个参数指向this,其余参数都被包裹在一个数组中,在函数执行时通过形参传入;
fn.call(this, arg1, arg2, ...);
而apply方法的形参是一个数组,除了第一个参数作为this指向外,其他参数都被包裹在一个数组中;
fn.apply(this, [arg1, arg2, ...]);
在传参的情况下,call的性能要高于apply,因为apply在执行时还要多一步解析数组;
apply和call是函数应用,指定this的同时也将方法执行,但是bind不同,只负责绑定this并返回一个新方法,不会执行;
应用:
1.我们都知道Math.max()方法能取到一组数字中的最大值,比如:
Math.max(1, 10); //10
Math.min(1, 10); //1那我们如何利用此方法求数组中最大最小呢,这里就可以利用apply的特性了:
Math.max.apply(null, [1, 2, 10]); //10
Math.max.min(null, [1, 2, 10]); //1在非严格模式下,当我们让this指向null,或者undefined时,this本质上会指向window,不过这里的null就是一个摆设,我们真正想处理的其实是后面的数组。
2.在考虑兼容情况下怎么判断一个对象是不是数组吗?再或者是不是一个函数?利用Object.prototype.toString()结合call方法就能解决这个问题:
let a = [];
let b = function () {};
Object.prototype.toString.call(a) === "[object Array]";//true
Object.prototype.toString.call(b) === "[object Function]";//true参考:www.cnblogs.com/echolun/p/1…
2.new的原理以及实现
原理:
new的实现原理:
- 以构造器的prototype属性为原型,创建新的对象;
- 将this(也就是上面创建的新对象)和调用参数传给构造器,执行
- 如果构造器没有手动返回对象,那么就返回第一步创建的新对象,如果有,就舍去第一步创建的新对象,返回手动的return的对象;
实现:
//构造器函数
let Parent = function(name,age){
this.name=name;
this.age=age;
};
Parent.prototype.sayName=function(){
console.log(this.name);
};
//定义new
let newMethod = function(Parent,...arg){
//1.使用构造器的prototype属性为原型,创建新的对象;
let child = Object.create(Parent.prototype);
//2.将this和调用参数传递给构造器并且执行;使用apply,改变构造函数this指向到新建的对象,
//这样child就可以访问到构造函数parent中的属性和方法了;
let result = Parent.apply(child,arg);
//3.如果构造器没有手动返回对象,则返回第一步的对象;
return typeof result === 'object' ? result : child;
}
//创建实例,将构造函数Parent与形参作为参数传入
const child = newMethod(Parent, 'echo', 26);
child.sayName() //'echo';
3.JSON.stringify()和JSON.parse()区别
json.stringify()的作用是将js对象转换为JSON字符串,json.parse()是将JSON字符串转换为一个对象;需要注意的是,JSON.parse()方法转换的JSON字符串必须符合JSON格式,也就是键值都必须使用双引号包裹;例如:a = '["1","2"]'是正确的,b = “[‘1’,‘2’]”是不对的,不满足JSON格式;
JSON.stringify()的几种妙用:
- 可以判断数组是否包含某些对象,或者判断对象是不是相等的;
//判断数组是否包含某对象
let data = [
{name:'echo'},
{name:'听风是风'},
{name:'天子笑'},
],
val = {name:'天子笑'};
JSON.stringify(data).indexOf(JSON.stringify(val)) !== -1;//true
//判断两数组/对象是否相等
let a = [1,2,3],
b = [1,2,3];
JSON.stringify(a) === JSON.stringify(b);//true
//存
function setLocalStorage(key,val){
window.localStorage.setItem(key,JSON.stringify(val));
};
//取
function getLocalStorage(key){
let val = JSON.parse(window.localStorage.getItem(key));
return val;
};
//测试
setLocalStorage('demo',[1,2,3]);
let a = getLocalStorage('demo');//[1,2,3]使用JSON.stringify()和JSON.parse()来实现深拷贝;
//深拷贝
function deepClone(data) {
let _data = JSON.stringify(data),
dataClone = JSON.parse(_data);
return dataClone;
};
//测试
let arr = [1,2,3],
_arr = deepClone(arr);
arr[0] = 2;
console.log(arr,_arr)//[2,2,3] [1,2,3]JSON.stringify()与toString()的区别
var arr = [1,2,4];
console.log(arr.toString()); // 1,2,4
alert(JSON.stringify(arr));
console.log(JSON.stringify(arr)); // [1,2,4]
4.执行上下文,变量对象,作用域链
执行上下文:
有三类:全局执行上下文:只有一个,浏览器中的全局对象就是window对象,this指向这个全局对象;函数执行上下文:存在很多个,只有在函数被调用的时候才会被创建,每次调用函数都会创建一个新的执行上下文;Eval函数执行上下文;
执行栈:
执行栈,具有后进先出的结构,用来存储在代码执行期间创建的所有执行上下文;
首次运行js代码的时候,就会创建一个全局执行上下文并且Push到当前的执行栈中,每当发生函数调用的时候,引擎都会为这个函数创建一个新的函数执行上下文并且Push到当前执行栈的栈顶;
根据执行栈LIFO规则,当栈顶函数运行完成后,其对应的函数执行上下文将会从执行栈中Pop出,上下文控制权将移到当前执行栈的下一个执行上下文。
执行上下文的创建:
分为两个阶段:1.创建阶段;2.执行阶段;
创建阶段:确定this的值;词法环境组件被创建(一般存储**函数声明和变量let,const的绑定);变量环境组件被创建(存储变量var);
变量提升的原因:在创建阶段,函数声明存储在环境中,而变量会被设置为 undefined(在 var 的情况下)或保持未初始化(在 let 和 const 的情况下)。所以这就是为什么可以在声明之前访问 var 定义的变量(尽管是 undefined ),但如果在声明之前访问 let 和 const 定义的变量就会提示引用错误的原因。这就是所谓的变量提升。
作用域链
含义:当访问一个变量时,解释器首先会在当前作用域查找标识符,如果没有找到,就去父作用域找,直到找到这个变量;
作用域链和原型继承查找时的区别:如果去查找一个普通对象的属性,但是在当前对象和它的原型中都找不到,就会返回undefined;但是查找的属性在作用域链中不存在的话就会抛出ReferenceError;
作用域链的顶端是全局对象,在全局环境中定义的变量会绑定到全局对象中;
5.闭包的理解
定义
闭包就是能够读取其他函数内部变量的函数,其实就是利用了作用域链向上查找的特点。作用:读取函数内部变量,让这些变量的值一直保持在内存中。
特性
- 函数内再嵌套函数
- 内部函数可以引用外层的参数和变量
- 参数和变量不会被垃圾回收机制回收
对闭包的理解:js的特殊之处在一,(js的作用域链结构,子对象会一级级向上寻找所有父对象的变量,所以父对象的所有变量对子对象都是可见的,反之不成立)函数内部可以直接读取全局变量,而在函数外部就无法读取函数内的局部变量,那有时候需要得到函数内的局部变量,就可以使用闭包:在函数的内部,再定义一个函数;
闭包产生的本质就是:当前环境中存在指向父级作用域的引用;
使用闭包有两个好处:一个使读取函数内部的变量,另一个就是让这些变量始终保持在内存中;
闭包的另一个用处:封装对象的私有属性和私有方法(在函数内部才能访问到的变量)
function Person(name){
var _age;
function setAge(n){
_age = n;
}
function getAge(){
return _age;
}
return {
name:name,
getAge:getAge,
setAge:setAge
};
}
var p1 = Person('张三')
p1.setAge(25);
p1.getAge()在函数Person()的内部变量_age,通过闭包getAge和setAge,变成了返回对象p1的私有变量。
闭包表现形式
- 返回一个函数(也就是让当前环境中存在父级作用域的引用)
function f1() {
var a = 2
function f2() {
console.log(a);//2
}
return f2;
}
var x = f1();
x();上面这个例子,这里的x会拿到父级作用域中的变量,输出2,因为在当前环境中,含有对f2的引用,f2恰恰引用了window、f1和f2的作用域。因此f2可以访问到f1的作用域的变量。
2.作为函数参数传递:
var a = 1;
function foo(){
var a = 2;
function baz(){
console.log(a);
}
bar(baz);
}
function bar(fn){
// 这就是闭包
fn();
}
// 输出2,而不是1
foo();3.在定时器、事件监听、Ajax请求、跨窗口通信、Web Workers或者任何异步中,只要使用了回调函数,实际上就是在使用闭包。
以下的闭包保存的仅仅是window和当前作用域。
// 定时器
setTimeout(function timeHandler(){
console.log('111');
},100)
// 事件监听
$('#app').click(function(){
console.log('DOM Listener');
})var a = 2;
(function IIFE(){
// 输出2
console.log(a);
})();闭包的应用
解决下面循环输出的问题:
for(var i = 1; i <= 5; i ++){
setTimeout(function timer(){
console.log(i)
}, 0)
}
为什么会全部输出6?如何改进,让它输出1,2,3,4,5?
因为setTimeout为宏任务,由于JS中单线程eventLoop机制,在主线程同步任务执行完后才去执行宏任务,因此循环结束后setTimeout中的回调才依次执行,但输出i的时候当前作用域没有,往上一级再找,发现了i,此时循环已经结束,i变成了6。因此会全部输出6。
解决方法:
1、利用IIFE(立即执行函数表达式)当每次for循环时,把此时的i变量传递到定时器中
for(var i = 1;i <= 5;i++){
(function(j){
setTimeout(function timer(){
console.log(j)
}, 0)
})(i)
}
2、给定时器传入第三个参数, 作为timer函数的第一个函数参数
for(var i=1;i<=5;i++){
setTimeout(function timer(j){
console.log(j)
}, 0, i)
}
3、使用ES6中的let
for(let i = 1; i <= 5; i++){
setTimeout(function timer(){
console.log(i)
},0)
}
let使JS发生革命性的变化,让JS有函数作用域变为了块级作用域,用let后作用域链不复存在。
闭包的缺点
- 外层函数每次运行,都会生成一个新的闭包,而这个闭包又会保留外层函数的内部变量,所以内存消耗很大。因此不能滥用闭包,否则会造成网页的性能问题。
- 闭包会产生一个经典的问题:多个子函数的[[scope]](该属性是指父级变量和作用域链,也就是包含了父级的scope和自身活动对象)都指向父级,完全共享,因此当父级变量对象被修改时,所有子函数都受到影响;
- 但是闭包不会造成内存泄漏:闭包只是一个绑定了执行环境的函数而已;
回归到主要矛盾上,为什么会流传闭包会导致内存泄露!因为IE浏览器早期的垃圾回收机制,有 bug。
- IE浏览器中使用完闭包之后,依然回收不了闭包里面引用的变量。
- 在IE浏览器中,由于BOM和DOM中的对象是使用C++以COM对象的方式实现的,而COM对象的垃圾收集机制采用的是引用计数策略。在基于引用计数策略的垃圾回收机制中,如果两个对象之间形成了循环引用,那么这两个对象都无法被回收,但循环引用造成的内存泄露在本质上也不是闭包造成的。
6.常见的内存泄漏以及避免
百度百科:内存泄漏是指程序中己动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
js程序员:内存泄露是指你用不到(访问不到)的变量,依然占居着内存空间,不能被再次利用起来。
1.意外的全局变量:
Js处理未定义变量的方式比较宽松:未定义的变量会在全局对象创建一个新变量。在浏览器中,全局对象是window。
function foo(arg) {
bar = "this is a hidden global variable"; //等同于window.bar="this is a hidden global variable"
this.bar2= "potential accidental global";//这里的this 指向了全局对象(window),等同于window.bar2="potential accidental global"
}解决方法:在JavaScript程序中添加,开启严格模式'use strict',可以有效地避免上述问题。
注意:那些用来临时存储大量数据的全局变量,确保在处理完这些数据后将其设置为null或重新赋值。与全局变量相关的增加内存消耗的一个主因是缓存。缓存数据是为了重用,缓存必须有一个大小上限才有用。高内存消耗导致缓存突破上限,因为缓 存内容无法被回收。
2.循环引用
在js的内存管理环境中,对象 A 如果有访问对象 B 的权限,叫做对象 A 引用对象 B。引用计数的策略是将“对象是否不再需要”简化成“对象有没有其他对象引用到它”,如果没有对象引用这个对象,那么这个对象将会被回收 。
let obj1 = { a: 1 }; // 一个对象(称之为 A)被创建,赋值给 obj1,A 的引用个数为 1
let obj2 = obj1; // A 的引用个数变为 2
obj1 = 0; // A 的引用个数变为 1
obj2 = 0; // A 的引用个数变为 0,此时对象 A 就可以被垃圾回收了但是引用计数有个最大的问题: 循环引用。
function func() {
let obj1 = {};
let obj2 = {};
obj1.a = obj2; // obj1 引用 obj2
obj2.a = obj1; // obj2 引用 obj1
}当函数 func 执行结束后,返回值为 undefined,所以整个函数以及内部的变量都应该被回收,但根据引用计数方法,obj1 和 obj2 的引用次数都不为 0,所以他们不会被回收。要解决循环引用的问题,最好是在不使用它们的时候手工将它们设为空。上面的例子可以这么做:
obj1 = null;
obj2 = null;3.被遗忘的计时器和回调函数
let someResource = getData();
setInterval(() => {
const node = document.getElementById('Node');
if(node) {
node.innerHTML = JSON.stringify(someResource));
}
}, 1000);上面的例子中,我们每隔一秒就将得到的数据放入到文档节点中去。但在 setInterval 没有结束前,回调函数里的变量以及回调函数本身都无法被回收。那什么才叫结束呢?就是调用了 clearInterval。如果回调函数内没有做什么事情,并且也没有被 clear 掉的话,就会造成内存泄漏。不仅如此,如果回调函数没有被回收,那么回调函数内依赖的变量也没法被回收。上面的例子中,someResource 就没法被回收。同样的,setTiemout 也会有同样的问题。所以,当不需要 interval 或者 timeout 时,最好调用 clearInterval 或者 clearTimeout。
4.DOM泄漏
在js中对DOM操作是非常耗时的。因为JavaScript/ECMAScript引擎独立于渲染引擎,而DOM是位于渲染引擎,相互访问需要消耗一定的资源。 而IE的DOM回收机制便是采用引用计数的,以下主要针对IE而言的。
a.没有清理的DOM元素引用
var refA = document.getElementById('refA');
document.body.removeChild(refA);
// #refA不能回收,因为存在变量refA对它的引用。将其对#refA引用释放,但还是无法回收#refA解决办法:refA = null;
b.给DOM对象添加的属性是一个对象的引用:
var MyObject = {};
document.getElementById('myDiv').myProp = MyObject;解决方法:
在window.onunload事件中写上: document.getElementById('myDiv').myProp = null;
c.DOM对象与JS对象相互引用:
function Encapsulator(element) {
this.elementReference = element;
element.myProp = this;
}
new Encapsulator(document.getElementById('myDiv'));解决方法: 在onunload事件中写上: document.getElementById('myDiv').myProp = null;
d.给DOM对象用attachEvent绑定事件:
function doClick() {}
element.attachEvent("onclick", doClick);解决方法: 在onunload事件中写上: element.detachEvent('onclick', doClick);
e.从外到内执行appendChild。这时即使调用removeChild也无法释放:
var parentDiv = document.createElement("div");
var childDiv = document.createElement("div");
document.body.appendChild(parentDiv);
parentDiv.appendChild(childDiv);解决方法: 从内到外执行appendChild:
var parentDiv = document.createElement("div");
var childDiv = document.createElement("div");
parentDiv.appendChild(childDiv);
document.body.appendChild(parentDiv);5.js的闭包
闭包在IE6下会造成内存泄漏,但是现在已经无须考虑了。值得注意的是闭包本身不会造成内存泄漏,但闭包过多很容易导致内存泄漏。闭包会造成对象引用的生命周期脱离当前函数的上下文,如果闭包如果使用不当,可以导致环形引用(circular reference),类似于死锁,只能避免,无法发生之后解决,即使有垃圾回收也还是会内存泄露。
6.console
控制台日志记录对总体内存配置文件的影响可能是许多开发人员都未想到的极其重大的问题。记录错误的对象可以将大量数据保留在内存中。注意,这也适用于:
1)、 在用户键入 JavaScript 时,在控制台中的一个交互式会话期间记录的对象。2)、由 console.log 和 console.dir 方法记录的对象。
7.js内存机制
基本类型
--->栈内存(不包含闭包中的变量),这些类型在内存中分别占有固定大小的空间,通过按值来访问;
引用类型
--->堆内存,因为引用类型的值的大小是不固定的,因此不能保存到栈内存中,栈中存放的是这个对象的访问地址;在查询引用类型的变量时,先从栈中读取内存地址,再通过地址找到堆中的值,称为按引用访问;
对于系统栈来说,它的功能除了保存变量之外,还有创建并切换函数执行上下文的功能;如果用栈来存储比基本类型更加复杂的对象数据,那么切换上下文的开销会变得很大;
闭包中的变量并不保存在栈内存中,而是保存在堆内存中;
以下数据类型存储在栈中:
- boolean
- null
- undefined
- number
- string
- symbol
- bigint
而所有的对象数据类型存放在堆中。
值得注意的是,对于赋值操作,原始类型的数据直接完整地复制变量值,对象数据类型的数据则是复制引用地址。
8.垃圾回收
内存回收:
js中存在自动垃圾收集的机制,垃圾收集器会每隔一段时间就执行一次释放操作,找出那些不再继续使用的值,然后释放它的内存;
- 局部变量和全局变量的销毁
- 局部变量:局部作用域中,当函数执行完毕,局部变量也就没有存在的必要了,因此垃圾收集器很容易做出判断并回收。
- 全局变量:全局变量什么时候需要自动释放内存空间则很难判断,所以在开发中尽量避免使用全局变量。
- 以Google的V8引擎为例,V8引擎中所有的JS对象都是通过堆来进行内存分配的;
- 初始分配:当声明变量并赋值时,V8引擎就会在堆内存中分配给这个变量。
- 继续申请:当已申请的内存不足以存储这个变量时,V8引擎就会继续申请内存,直到堆的大小达到了V8引擎的内存上限为止。
- V8引擎对堆内存中的JS对象进行分代管理;
- 新生代:存活周期较短的JS对象,如临时变量、字符串等。
- 老生代:经过多次垃圾回收仍然存活,存活周期较长的对象,如主控制器、服务器对象等。
原理
找出那些不再使用的变量,然后释放其占用的内存。为此,垃圾收集器会按照固定的时间间隔(或代码执行中预定的收集时间),周期性的执行这一操作。
垃圾回收算法
- 引用计数:定义内存不再使用的标准很简单,就是看一个对象是否有指向它的引用。如果没有其他对象指向它了,说明该对象已经不再需要了;但是有一个致命的问题,就是循环引用;如果两个对象相互引用,尽管他们已经不再使用,但是垃圾回收器不会进行回收,最终会导致内存泄漏;
- 标记清除(常用):当变量进入到环境的时候,将这个变量标记为“进入环境”;从逻辑上讲,永远不能释放进入环境的变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为“离开环境”。
- 垃圾回收器创建了一个“roots”列表;roots通常是代码中的全局变量的引用;js中,window对象是一个全局变量,被当作root;
- 垃圾回收器创建了一个“roots”列表。roots 通常是代码中全局变量的引用。JavaScript 中,“window” 对象是一个全局变量,被当作 root 。window 对象总是存在,因此垃圾回收器可以检查它和它的所有子对象是否存在(即不是垃圾);
- 所有的 roots 被检查和标记为激活(即不是垃圾)。所有的子对象也被递归地检查。从 root 开始的所有对象如果是可达的,它就不被当作垃圾;
- 所有未被标记的内存会被当做垃圾,收集器现在可以释放内存,归还给操作系统了;
现代的垃圾回收器改良了算法,但是本质是相同的:可达内存被标记,其余的被当作垃圾回收
】
9.v8引擎的垃圾回收机制
js存储对象类型的数据是通过堆进行空间分配的,当我们构造一个对象进行赋值操作的时候,其实相应的内存已经分配到了堆上。你可以不断的这样创建对象,让 V8 为它分配空间,直到堆的大小达到上限。
那么,V8 为什么要给它设置内存上限?明明我的机器大几十G的内存,只能让我用这么一点?
原因是由两个因素共同决定的,一个是JS单线程的执行机制;另一个是JS的垃圾回收机制的限制;
首先js是单线程运行的,意味着一旦进入到垃圾回收,那么其它的各种运行逻辑都要暂停; 另一方面垃圾回收其实是非常耗时间的操作,在这么长的时间内,我们的JS代码执行会一直没有响应,造成应用卡顿,导致应用性能和响应能力直线下降。因此,V8 做了一个简单粗暴的选择,那就是限制堆内存,也算是一种权衡的手段,因为大部分情况是不会遇到操作几个G内存这样的场景的。
新生代内存的回收
V8把堆内存分成了两部分处理:新生代内存和老生代内存;新生代就是临时分配的内存,存活时间短;老生代就是常驻内存,存活时间长;V8的堆内存,就是两个内存之和;
首先将新生代内存空间一分为二:
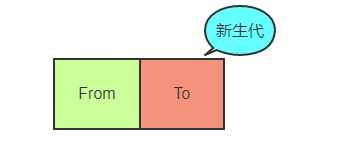
其中From部分表示正在使用的内存,To 是目前闲置的内存。
当进行垃圾回收时,V8 将From部分的对象检查一遍,如果是存活对象那么复制到To内存中(在To内存中按照顺序从头放置的),如果是非存活对象直接回收即可。
当所有的From中的存活对象按照顺序进入到To内存之后,From 和 To 两者的角色对调,From现在被闲置,To为正在使用,如此循环。
老生代内存回收:
那么新生代中的变量如果经过多次回收后依然存在,那么就会被放入到老生代内存中,这种现象就叫晋升。
发生晋升其实不只是这一种原因,我们来梳理一下会有那些情况触发晋升:
- 已经经历过一次 Scavenge 回收。
- To(闲置)空间的内存占用超过25%。
现在进入到老生代的垃圾回收机制当中,老生代中累积的变量空间一般都是很大的,当然不能用Scavenge算法啦,浪费一半空间不说,对庞大的内存空间进行复制岂不是劳民伤财?
对于老生代的垃圾回收机制,采用的策略:
第一步,进行标记-清除,主要分为标记阶段和清除阶段。首先会遍历堆中的所有对象,对它们做上标记,然后对于代码环境中使用的变量以及被强引用的变量取消标记,剩下的就是要删除的变量了,在随后的清除阶段对其进行空间的回收;
当然这又会引发内存碎片的问题,存活对象的空间不连续对后续的空间分配造成障碍。老生代又是如何处理这个问题的呢?
第二步,整理内存碎片。V8 的解决方式非常简单粗暴,在清除阶段结束后,把存活的对象全部往一端靠拢。
增量标记:
由于js是单线程的机制,V8在进行垃圾回收的时候,会不可避免地阻塞业务逻辑地执行,如果老生代的垃圾回收任务很重,耗时会很严重,影响应用的性能;
于是采用了增量标记的方案:将一口气完成的标记任务分为很多小的部门完成,每做完一个小的部分就"歇"一下,就js应用逻辑执行一会儿,然后再执行下面的部分,如果循环,直到标记阶段完成才进入内存碎片的整理上面来。经过增量标记之后,垃圾回收过程对JS应用的阻塞时间减少到原来了1 / 6, 可以看到,这是一个非常成功的改进。
10.js创建对象的几种方式
第一种:Object构造函数创建
var Person = new Object();
Person.name = 'Nike';
Person.age = 29;这行代码创建了Object引用类型的一个新实例,然后把实例保存在变量Person中。
第二种:使用对象字面量表示法
var Person = {};//相当于var Person = new Object();
var Person = {name:'Nike';age:29;}对象字面量是对象定义的一种简写形式,目的在于简化创建包含大量属性的对象的过程。第一种和第二种方式创建对象的方法其实都是一样的,只是写法上的区别不同
在介绍第三种的创建方法之前,我们应该要明白为什么还要用别的方法来创建对象,也就是第一种,第二种方法的缺点所在:它们都是用了同一个接口创建很多对象,会产生大量的重复代码,就是如果你有100个对象,那你要输入100次很多相同的代码。那我们有什么方法来避免过多的重复代码呢,就是把创建对象的过程封装在函数体内,通过函数的调用直接生成对象。
第三种:使用工厂模式创建对象
function createPerson(name,age,job){
var o = new Object();
o.name = name;
o.age = age;
o.job = job;
o.sayName = function(){
alert(this.name);
};
return o;
}
var person1 = createPerson('Nike',29,'teacher');
var person2 = createPerson('Arvin',20,'student');在使用工厂模式创建对象的时候,我们都可以注意到,在createPerson函数中,返回的是一个对象。那么我们就无法判断返回的对象究竟是一个什么样的类型。于是就出现了第四种创建对象的模式。
第四种:使用构造函数创建对象
function Person(name,age,job){
this.name = name;
this.age = age;
this.job = job;
this.sayName = function(){
alert(this.name);
}
}
var person1 = new Person('Nike',29,'teacher');
var person2 = new Person('Arvin',20,'student');对比工厂模式,我们可以发现以下区别:
1.没有显示地创建对象
2.直接将属性和方法赋给了this对象
3.没有return语句
4.终于可以识别的对象的类型。对于检测对象类型,我们应该使用instanceof操作符,我们来进行自主检测:
alert(person1 instanceof Object);//ture
alert(person1 instanceof Person);//ture
alert(person2 instanceof Object);//ture
alert(person2 instanceof Object);//ture同时我们也应该明白,按照惯例,构造函数始终要应该以一个大写字母开头,而非构造函数则应该以一个小写字母开头。
那么构造函数确实挺好用的,但是它也有它的缺点:
就是每个方法都要在每个实例上重新创建一遍,方法指的就是我们在对象里面定义的函数。如果方法的数量很多,就会占用很多不必要的内存。于是出现了第五种创建对象的方法
第五种:原型创建对象模式
function Person(){}
Person.prototype.name = 'Nike';
Person.prototype.age = 20;
Person.prototype.job = 'teacher';
Person.prototype.sayName = function(){
alert(this.name);
};
var person1 = new Person();
person1.sayName();使用原型创建对象的方式,可以让所有对象实例共享它所包含的属性和方法。
如果是使用原型创建对象模式,请看下面代码:
function Person(){}
Person.prototype.name = 'Nike';
Person.prototype.age = 20;
Person.prototype.jbo = 'teacher';
Person.prototype.sayName = function(){
alert(this.name);
};
var person1 = new Person();
var person2 = new Person();
person1.name ='Greg';alert(person1.name); //'Greg' --来自实例
alert(person2.name); //'Nike' --来自原型当为对象实例添加一个属性时,这个属性就会屏蔽原型对象中保存的同名属性。
这时候我们就可以使用构造函数模式与原型模式结合的方式,构造函数模式用于定义实例属性,而原型模式用于定义方法和共享的属性
第六种:组合使用构造函数模式和原型模式
解决了方法不能共享,引用类型改变的问题;
function Person(name,age,job){
this.name =name;
this.age = age;
this.job = job;
}
Person.prototype = {
constructor:Person,
sayName: function(){
alert(this.name);
};
}
var person1 = new Person('Nike',20,'teacher');11.原型、原型链
原型、构造函数、实例
原型(prototype):一个简单的对象,用于实现对象的属性继承。(js中,每当定义一个函数数据类型的时候,都会带有一个prototype的属性,这个属性指向函数的原型对象)
构造函数:当函数经过new调用后就成为了构造函数,并返回一个全新的实例;
实例:由构造函数创建并返回的,这个实例对象有一个__proto__属性,该属性指向构造函数的原型对象;并且通过constructor指向构造函数;
例如://实例:const instance = new Object()
实例是instance;构造函数时Object;构造函数有一个prototype的属性指向原型;
Javascript函数的prototype
每一个函数,无论是内置的还是自定义的,在创建的时候,就会内建一个prototype属性,被称为原型,只有function才有,其他的对象没有;
我们创建的每个函数都有一个 prototype(原型)属性,这个属性是一个指针,指向一个对象,而这个对象的用途是包含可以由特定类型的所有实例共享的属性和方法。如果按照字面意思来理解,那么prototype 就是通过调用构造函数而创建的那个对象实例的原型对象。使用原型对象的好处是可以让所有对象实例共享它所包含的属性和方法;
而任何一个prototype都有一个内置的constructor属性(function类型),指向了这个prototype的所属函数——也就是说,任何一个对象,都可以通过constructor属性访问其构造函数。
原型链:
js对象通过__proto__指向父类对象(创建该对象的构造函数的原型),直到指向Object对象为止,这样就形成了一个原型链;
- 对象的hasOwnProperty()来检查对象自身中是否含有该属性;
- 使用in检查对象中是否含有某个属性的时候,如果对象中没有但是原型链中有,也会返回true;
- 属性查找机制: 当查找对象的属性时,如果实例对象自身不存在该属性,则沿着原型链往上一级查找,找到时则输出,不存在时,则继续沿着原型链往上一级查找,直至最顶级的原型对象Object.prototype,如还是没找到,则输出undefined;
- 属性修改机制: 只会修改实例对象本身的属性,如果不存在,则进行添加该属性,如果需要修改原型的属性时,则可以用: b.prototype.x = 2;但是这样会造成所有继承于该对象的实例的属性发生改变。
判断一个属性是实例对象上的还是其原型对象上的?
1. obj.hasOwnProperty(‘属性名’) 用于检查给定的属性是否存在于当前实例对象中,(而不是实例原型中)。如果是返回true,如果不是返回 false。
2. in 操作符用来判断某个属性属于某个对象,可以是对象的直接属性,也可以是通过prototype继承的属性。如:(属性名 in 对象) ,不管属性是原型的还是实例的,只要存在就会返回ture;否则返回false。 所以用两者结合,就可以判断某个属性是否是原型上的属性
12.js继承的几种方式
继承的原理
还是跟原型链有关。每个函数都有个原型对象,这个对象用来存储通过这个函数所创建的所有实例的共有属性和方法。在读取某个对象属性的时候,从实例开始,如果实例有就返回,如果没有就找原型对象,找到了就返回。通过实例只能访问原型对象里的值,但是不能修改。这就实现了继承。
ES5继承
构造函数、原型和实例的关系:每一个构造函数都有一个原型对象,每一个原型对象都有一个指向构造函数的指针,而每一个实例都包含一个指向原型对象的内部指针,
原型链实现继承
基本思想:利用原型让一个引用类型继承另一个引用类型的属性和方法,即让原型对象等于另一个类型的实例
基本模式:
1 function SuperType(){ 2 this.property = true; 3 } 4 SuperType.prototype.getSuperValue = function(){ 5 return this.property; 6 }; 7 function SubType(){ 8 this.subproperty = false; 9 } 10 \\继承了SuperType 11 SubType.prototype = new SuperType(); 12 13 SubType.prototype.getSubValue = function(){ 14 return this.subproperty; 15 }; 16 var instance = new SubType(); 17 alert(instance.getSuperValue()); \\true最终结果:instance指向SubType的原型,SubType的原型又指向SuperType的原型,getSuperValue()方法任然在SuperType.prototype中,但property则位于SubType.prototype中,这是因为property是一个实例属性,而getSuperValue是一个原型方法。此时,instance.constructor指向的是SuperType。
注意事项:
别忘记默认的原型,所有的引用类型都继承自Object,所有函数的默认原型都是Object的实例,因此默认原型里都有一个指针,指向object.prototype
谨慎地定义方法,给原型添加方法的代码一定要放在替换原型的语句之后,不能使用对象字面量添加原型方法,这样会重写原型链
原型链继承的问题
最主要的问题来自包含引用类型值的原型,它会被所有实例共享
第二个问题是,创造子类型的实例时,不能向超类型的构造函数中传递参数
借用构造函数
基本思想:在子类型构造函数的内部调用超类型构造函数,通过使用apply()和call()方法可以在将来新创建的对象上执行构造函数
1 function SuperType(){ 2 this.colors = ["red","blue","green"]; 3 } 4 5 function SubType(){ 6 \\借调了超类型的构造函数 7 SuperType.call(this); 8 } 9 10 var instance1 = new SubType(); 11 \\["red","blue","green","black"] 12 instance1.colors.push("black"); 13 console.log(instance1.colors); 14 15 var instance2 = new SubType(); 16 \\["red","blue","green"] 17 console.log(instance2.colors);通过call或者apply方法,我们实际上是在将来新创建的SubType实例的环境下调用了SuperType构造函数。这样一来,就会在新SubType对象上执行SuperType函数中定义的所有对象初始化代码,因此,每一个SubType的实例都会有自己的colors对象的副本
优势:
传递参数
1 function Supertype(name){ 2 this.name = name; 3 } 4 5 function Subtype(){ 6 Supertype.call(this,'Annika'); 7 this.age = 21; 8 } 9 10 var instance = new Subtype; 11 console.log(instance.name); \\Annika 12 console.log(instance.age); \\29缺点:
方法都在构造函数中定义,函数无法复用
在超类型中定义的方法,子类型不可见,结果所有类型都只能使用构造函数模式
组合继承
基本思想:将原型链和借用构造函数技术组合到一起。使用原型链实现对原型属性和方法的继承,用借用构造函数模式实现对实例属性的继承。这样既通过在原型上定义方法实现了函数复用,又能保证每个实例都有自己的属性
1 function Supertype(name){ 2 this.name = name; 3 this.colors = ["red","green","blue"]; 4 } 5 6 Supertype.prototype.sayName = function(){ 7 console.log(this.name); 8 }; 9 10 function Subtype(name,age){ 11 \\继承属性 12 Supertype.call(this,name); 13 this.age = age; 14 } 15 16 \\继承方法 17 Subtype.prototype = new Supertype(); 18 Subtype.prototype.constructor = Subtype; 19 Subtype.prototype.sayAge = function(){ 20 console.log(this.age); 21 }; 22 23 var instance1 = new Subtype('Annika',21); 24 instance1.colors.push("black"); 25 \\["red", "green", "blue", "black"] 26 console.log(instance1.colors); 27 instance1.sayName(); \\Annika 28 instance1.sayAge(); \\21 29 30 var instance2 = new Subtype('Anna',22); 31 \\["red", "green", "blue"] 32 console.log(instance2.colors); 33 instance2.sayName(); \\Anna 34 instance2.sayAge(); \\22缺点:无论在什么情况下,都会调用两次超类型构造函数,一次是在创建子类型原型的时候,一次是在子类型构造函数的内部
原型式继承
基本思想:不用严格意义上的构造函数,借助原型可以根据已有的对象创建新对象,还不必因此创建自定义类型,因此最初有如下函数:
1 function object(o){ 2 function F(){} 3 F.prototype = o; 4 return new F(); 5 }从本质上讲,object()对传入其中的对象执行了一次浅复制
1 var person = { 2 name:'Annika', 3 friendes:['Alice','Joyce'] 4 }; 5 6 var anotherPerson = object(person); 7 anotherPerson.name = 'Greg'; 8 anotherPerson.friendes.push('Rob'); 9 10 var yetAnotherPerson = object(person); 11 yetAnotherPerson.name = 'Linda'; 12 yetAnotherPerson.friendes.push('Sophia'); 13 14 console.log(person.friends); //['Alice','Joyce','Rob','Sophia'] 15 在这个例子中,实际上相当于创建了person的两个副本。
ES5新增Object.create规范了原型式继承,接收两个参数,一个用作新对象原型的对象和(可选的)一个为新对象定义额外属性的对象,在传入一个参数的情况下,Object.create()和object()行为相同。
1 var person = { 2 name:'Annika', 3 friendes:['Alice','Joyce'] 4 }; 5 6 var anotherPerson = object.create(person,{ 7 name:{ 8 value:"Greg" 9 } 10 }); 11 12 \\用这种方法指定的任何属性都会覆盖掉原型对象上的同名属性 13 console.log(anotherPerson.name); \\Greg用处:创造两个相似的对象,但是包含引用类型的值的属性始终会共享响应的值
寄生式继承
基本思想:寄生式继承是与原型式继承紧密相关的一种思路,它创造一个仅用于封装继承过程的函数,在函数内部以某种方式增强对象,最后再返回对象。
1 function createAnother(original){ 2 \\通过调用函数创建一个新对象 3 var clone = object(original); 4 \\以某种方式来增强对象 5 clone.sayHi = fuction(){ 6 alert("Hi"); 7 }; 8 \\返回这个对象 9 return clone 10 }这个例子中的代码基于 person 返回了一个新对象——anotherPerson。新对象不仅具有 person的所有属性和方法,而且还有自己的 sayHi()方法。
- 新的对象中不仅具有original的所有属性和方法,而且还有自己的sayHi()方法。
- 寄生式继承在主要考虑对象而不是自定义类型和构造函数的情况下非常有用。
- 由于寄生式继承为对象添加函数不能做到函数复用,因此效率降低。
缺点:使用寄生式继承来为对象添加函数,会因为做不到函数复用而降低效率,这个与构造函数模式类似
寄生组合式继承
基本思想:通过借用构造函数来继承属性,通过原型链的混成形式来继承方法,不必为了指定子类型的原型而调用超类型的构造函数,只需要超类型的一个副本。本质上,就是使用寄生式继承来继承超类型的原型,然后再将结果指定给子类型的原型
function object(o) { function F(){} F.prototype = o; return new F(); } 1function inheritPrototype(Subtype,supertype){ 2 var prototype = object(supertype); \\创建对象 3 prototype.constructor = subtype; \\增强对象 4 subtype.prototype = prototype; \\指定对象 5 }因此,前面的例子可以改为如下的形式
1 function Supertype(name){ 2 this.name = name; 3 this.colors = ["red","green","blue"]; 4 } 5 6 Supertype.prototype.sayName = function(){ 7 console.log(this.name); 8 }; 9 10 function Subtype(name,age){ 11 \\继承属性 12 Supertype.call(this,name); 13 this.age = age; 14 } 15 16 \\继承方法,这一句,替代了组合继承中的SubType.prototype= new SuperType() 17 inheritPrototype(Subtype,Supertype); 18 19 Subtype.prototype.sayAge = function(){ 20 console.log(this.age); 21 };优点:只调用了一次supertype构造函数,因此避免在subtype.prototype上创建不必要的,多余的属性,与此同时,原型链还能保持不变,还能正常使用instanceof 和isPrototypeOf(),因此,寄生组合式继承被认为是引用类型最理想的继承范式。
在inheritPrototype()函数中所做的事:
在inheritPrototype函数中用到了原型式继承中的object()方法,将超类型的原型指定为一个临时的空构造函数的原型,并返回构造函数的实例。
此时由于构造函数内部为空(不像SuperType里面有实例属性),所以返回的实例也不会自带实例属性,这很重要!因为后面用它作为SubType的原型时,就不会产生无用的原型属性了,借调构造函数也就不用进行所谓的“重写”了。
然后为这个对象重新指定constructor为SubType,并将其赋值给SubType的原型。这样,就达到了将超类型构造函数的实例作为子类型原型的目的,同时没有一些从SuperType继承过来的无用原型属性。
inheritPrototype函数接收两个参数:子类型构造函数和超类型构造函数。
1. 创建超类型原型的副本。
2. 为创建的副本添加constructor属性,弥补因重写原型而失去的默认的constructor属性
3. 将新创建的对象(即副本)赋值给子类型的原型
这种方法只调用了一次SuperType构造函数,instanceof 和isPrototypeOf()也能正常使用。
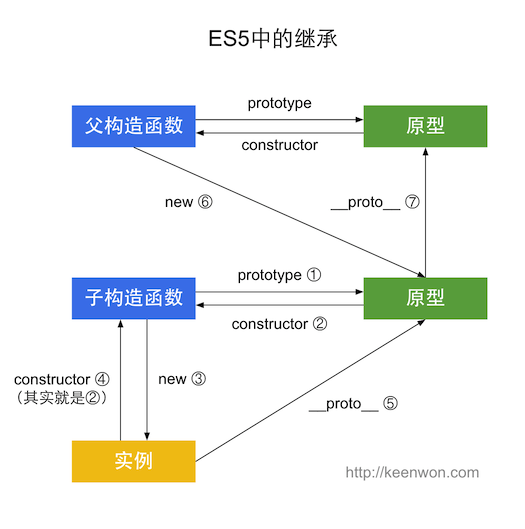
总结:
ES5的继承可以用下图来概括:
ES6继承
es6的继承主要要注意的是class的继承。
基本用法:Class之间通过使用extends关键字,这比通过修改原型链实现继承,要方便清晰很多
1 class Colorpoint extends Point {
2 constructor(x,y,color){
3 super(x,y); //调用父类的constructor(x,y)
4 this.color = color
5 }
6 toString(){
7 //调用父类的方法
8 return this.color + ' ' + super.toString();
9 }
10 }
子类必须在constructor方法中调用super方法,否则新建实例时会报错。这是因为子类没有自己的this对象,而是继承父类的this对象,然后对其进行加工,如果不调用super方法,子类就得不到this对象。因此,只有调用super之后,才可以使用this关键字。
prototype 和__proto__
一个继承语句同时存在两条继承链:一条实现属性继承,一条实现方法的继承
1 class A extends B{}
2 A.__proto__ === B; //继承属性
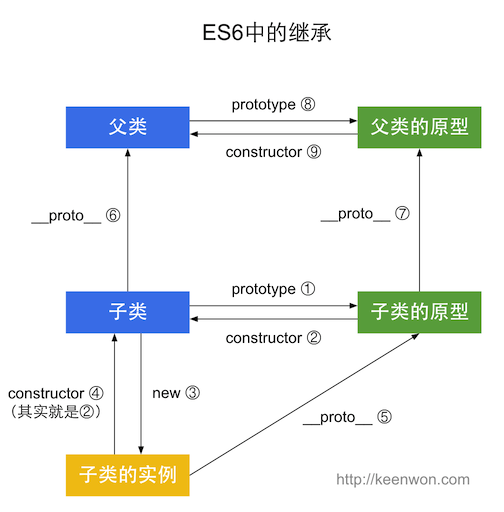
3 A.prototype.__proto__ == B.prototype;//继承方法总结:
ES6的继承可以用下图来概括:
13.事件是什么?IE 与火狐的事件机制有什么区别? 如何阻止冒泡?
1.事件是用户操作网页时发生的交互动作,比如 click/move, 事件除了用户触发的动作外,还可以是文档加载,窗口滚动和大小调整。事件被封装成一个 event 对象,包含了该事件发生时的所有相关信息( event 的属性)以及可以对事件进行的操作( event 的方法)。
2.事件处理机制:IE 支持事件冒泡、Firefox 同时支持两种事件模型,也就是:事件冒泡和事件捕获。
3.event.stopPropagation() 或者 ie 下的方法 event.cancelBubble = true;
14.三种事件模型是什么?
事件是用户操作网页时发生的交互动作或者网页本身的一些操作,现代浏览器一共有三种事件模型。
- 第一种事件模型是最早的 DOM0 级模型,这种模型不会传播,所以没有事件流的概念,但是现在有的浏览器支持以冒泡的方式实现,它可以在网页中直接定义监听函数,也可以通过 js 属性来指定监听函数。这种方式是所有浏览器都兼容的。
- 第二种事件模型是 IE 事件模型,在该事件模型中,一次事件共有两个过程,事件处理阶段,和事件冒泡阶段。事件处理阶段会首先执行目标元素绑定的监听事件。然后是事件冒泡阶段,冒泡指的是事件从目标元素冒泡到 document,依次检查经过的节点是否绑定了事件监听函数,如果有则执行。这种模型通过 attachEvent 来添加监听函数,可以添加多个监听函数,会按顺序依次执行。
- 第三种是 DOM2 级事件模型,在该事件模型中,一次事件共有三个过程,第一个过程是事件捕获阶段。捕获指的是事件从 document 一直向下传播到目标元素,依次检查经过的节点是否绑定了事件监听函数,如果有则执行。后面两个阶段和 IE 事件模型的两个阶段相同。这种事件模型,事件绑定的函数是 addEventListener,其中第三个参数可以指定事件是否在捕获阶段执行。
15.事件委托是什么?
事件委托本质上是利用了浏览器事件冒泡的机制。因为事件在冒泡过程中会上传到父节点,并且父节点可以通过事件对象获取到
目标节点,因此可以把子节点的监听函数定义在父节点上,由父节点的监听函数统一处理多个子元素的事件,这种方式称为事件代理。
使用事件代理我们可以不必要为每一个子元素都绑定一个监听事件,这样减少了内存上的消耗。并且使用事件代理我们还可以实现事件的动态绑定,比如说新增了一个子节点,我们并不需要单独地为它添加一个监听事件,它所发生的事件会交给父元素中的监听函数来处理。
16.IE和DOM事件流的区别
事件流:描述的是从页面中接收事件的顺序;
事件流种类:
- 事件冒泡流(IE事件流):事件开始时由最具体的元素(文档中嵌套最深的那个节点)接收,然后逐级向上传播到较为不具体的节点(文档)
- 事件捕获流(Netscape事件流):不太具体的节点最先接收到事件,而最具体的节点应该最后接收到事件(在事件到达预定目标之前捕获到)
- DOM事件流:事件流包括三个阶段,事件捕获阶段,处于目标阶段,事件冒泡阶段。首先发生的是事件捕获,为截获事件提供了机会;然后是实际的目标接收事件;最后是冒泡阶段,可以在这个阶段对事件做出响应。
IE和DOM事件流的区别:
1.执行顺序不一样
<body>
<div>
<button id = 'btn'>点击<button>
</div>
</body>三种事件流分别是:
冒泡型事件模型(IE事件流): button->div->body
捕获型事件模型(Netscape事件流): body->div->button
DOM事件模型: body->div->button->button->div->body (先捕获后冒泡)
2.事件侦听函数的区别:
IE使用: [Object].attachEvent("事件名称", fnHandler); //绑定函数
[Object].detachEvent("事件名称", fnHandler); //移除绑定DOM使用:
[Object].addEventListener("事件名称", fnHandler, bCapture); //绑定函数
[Object].removeEventListener("事件名称", fnHandler, bCapture); //移除绑定
bCapture参数用于设置事件绑定的阶段,true为捕获阶段,false为冒泡阶段。添加DOM2事件绑定:
①IE8之前,使用.attachEvent("onclick",函数);
②IE8之后,使用.addEventListener("click",函数,true/false);
参数三:false(默认)表示事件冒泡,传入true表示事件捕获。
③兼容所有浏览器的处理方式:
var btn=document.getElementById("btn1");
if(btn.attachEvent){btn.attachEvent("onclick",func1);//事件,事件需要执行的函数IE8可以
}else{
btn.attachEventListener("click",func1);
}3.DOM事件名称没有on;IE事件名称有on;
4.this的指向不同;
DOM事件可以在一个DOM元素上绑定多个事件处理器,this关键字仍然指向被绑定的DOM元素;IE下利用attachEvent注册的处理函数调用时this指向不再是先前注册事件的元素,这时的this为window对象;
17.js事件循环是什么?
单线程:
单线程就是任务是串行的,后一个任务需要等待前一个任务的执行,这就可能出现长时间的等待;但由于类似ajax网络请求、setTimeout时间延迟、DOM事件的用户交互等,这些任务并不消耗 CPU,是一种空等,资源浪费,因此出现了异步。
事件循环
因为js是单线程的,因此在执行过程中不断的将执行上下文中的任务压入执行栈中去执行,首先进行程序中的同步任务,自上而下执行,当遇到异步任务是将其挂起放在任务队列的末尾,不会阻碍同步任务的向下执行。
当所有同步任务执行完毕之后,会将任务队列里的微任务提取出来压入执行栈中执行,同时若遇到宏任务将其放置于宏任务队列末尾,当微任务执行完毕后,会从宏任务队列中压入一个任务进入执行栈中,同时判断宏任务中是否有微任务,再下次抽取宏任务前执行微任务队列,再进行下一次事件循环。
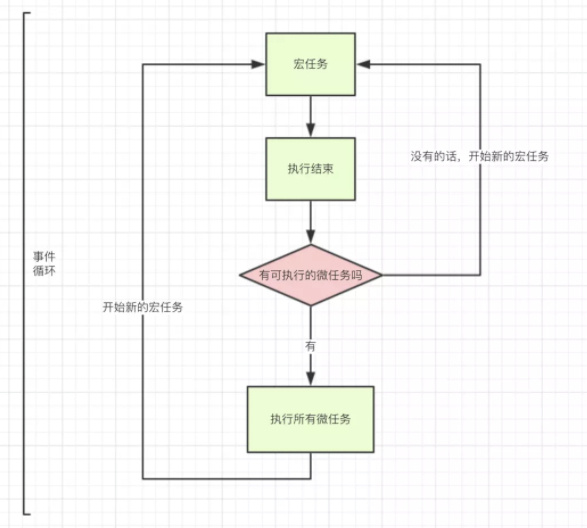
宏任务
script(整体代码)、setTimeout、setInterval、UI 渲染、 I/O、postMessage、 MessageChannel、setImmediate(Node.js 环境)
微任务
Promise、 MutaionObserver、process.nextTick(Node.js环境)
事件循环参考:segmentfault.com/a/119000001…;
事件循环练习参考:blog.csdn.net/qq_39539687…
主要参考:木易杨和神三元博客;muyiy.cn/blog/1/1.4.…
