


欢迎大家继续阅读iOS原理探索系列篇章(后续陆续完善补充)
一、探索背景
在iOS原理探索系列之alloc&init原理探索一文中,我们提到在系统新建对象的时候,会根据相关算法以8为倍数分配,并且在类最终创建的时候,如果内存大小小于16,那么最小也会分配16个字节的内存空间。
那么对象内部的内存到底是怎么排列的,或者是怎么分配的,这就是我这篇需要继续探索的问题。
二、内存对齐
这里我新建了一个带有属性的完整类来说明整个探索过程。
2.1 示例代码
@interface SNCoder : NSObject
@property (nonatomic, copy) NSString *name;
@property (nonatomic, assign) NSInteger age;
@property (nonatomic, copy) NSString *hobby;
@property (nonatomic, assign) long height;
@property (nonatomic, assign) char tag1;
@property (nonatomic, assign) char tag2;
@end
int main(int argc, const char * argv[]) {
@autoreleasepool {
// insert code here...
SNCoder *coder = [SNCoder new];
coder.name = @"Coder";
coder.age = 22;
coder.hobby = @"girl";
coder.height = 190;
coder.tag1 = 'a';
coder.tag2 = 'b';
NSLog(@"%@",coder);
}
return 0;
}
2.2 类的结构
大家都知道类的本质其实是结构体,那么我们可以看下这个SNCoder的内部属性情况,我们把SNCoder转成C++代码看下,可以看到多了一个isa指针。
xcrun -sdk iphonesimulator clang -rewrite-objc SNCoder.m
struct SNCoder_IMPL {
struct NSObject_IMPL NSObject_IVARS;
char _tag1;
char _tag2;
NSString * _Nonnull _name;
NSInteger _age;
NSString * _Nonnull _hobby;
long _height;
};
struct NSObject_IMPL {
Class isa;
};
2.3 LLDB调试说明
接下来我们打印下SNCoder的内存空间来查看具体的内存情况,这里我们需要借助LLDB调试命令:
2.3.1 x + 空格 + 对象
表示以16进制打印对象内存地址(x表示16进制), 因为iOS是小端模式(数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中——反过来存放数据)所以要倒着读数据;
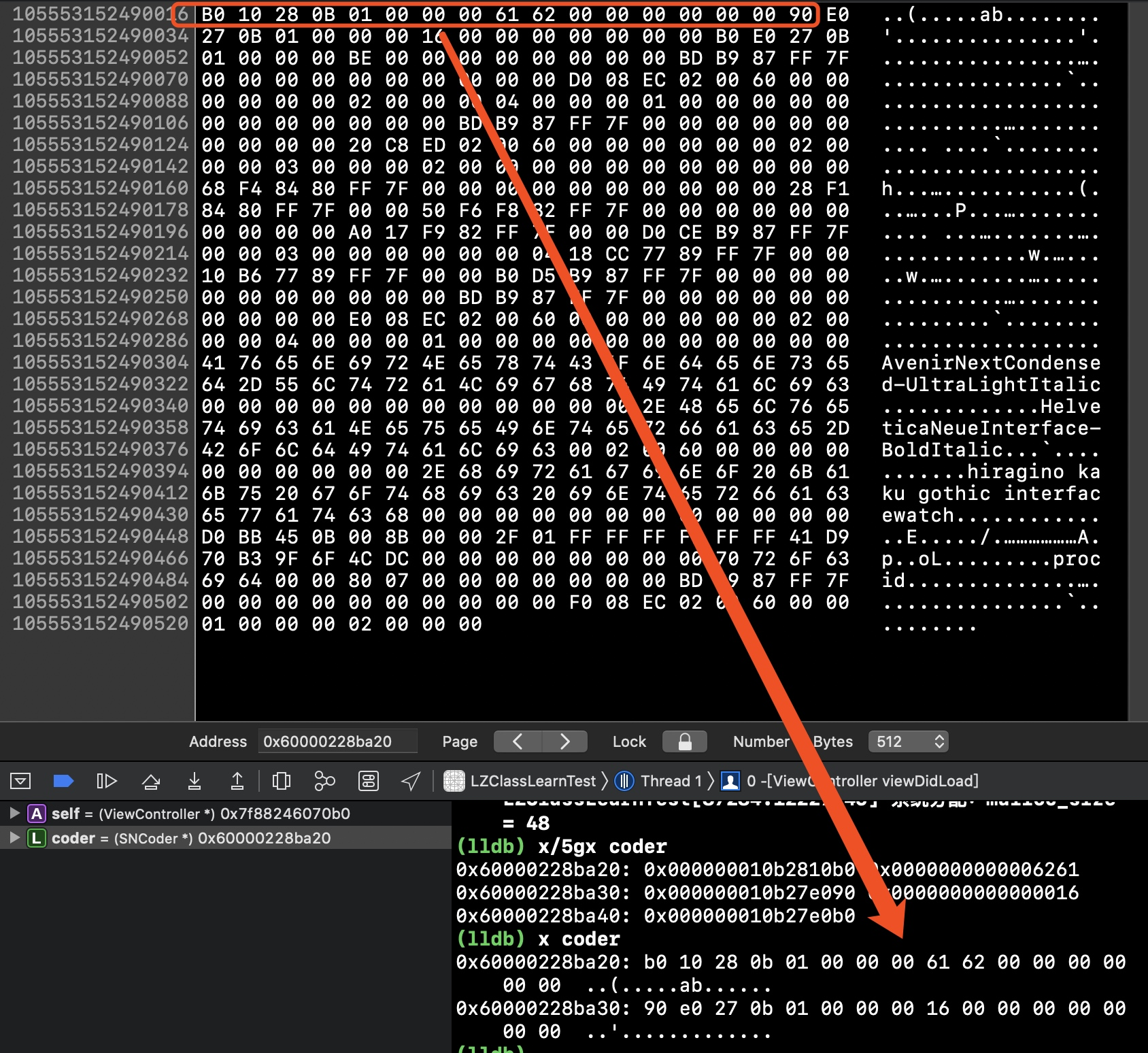
(lldb) x coder
0x60000228ba20: b0 10 28 0b 01 00 00 00 61 62 00 00 00 00 00 00 ..(.....ab......
0x60000228ba30: 90 e0 27 0b 01 00 00 00 16 00 00 00 00 00 00 00 ..'.............
(lldb)
(lldb) po 0x000000010b2810b0 // 打印首地址,即isa
SNCoder
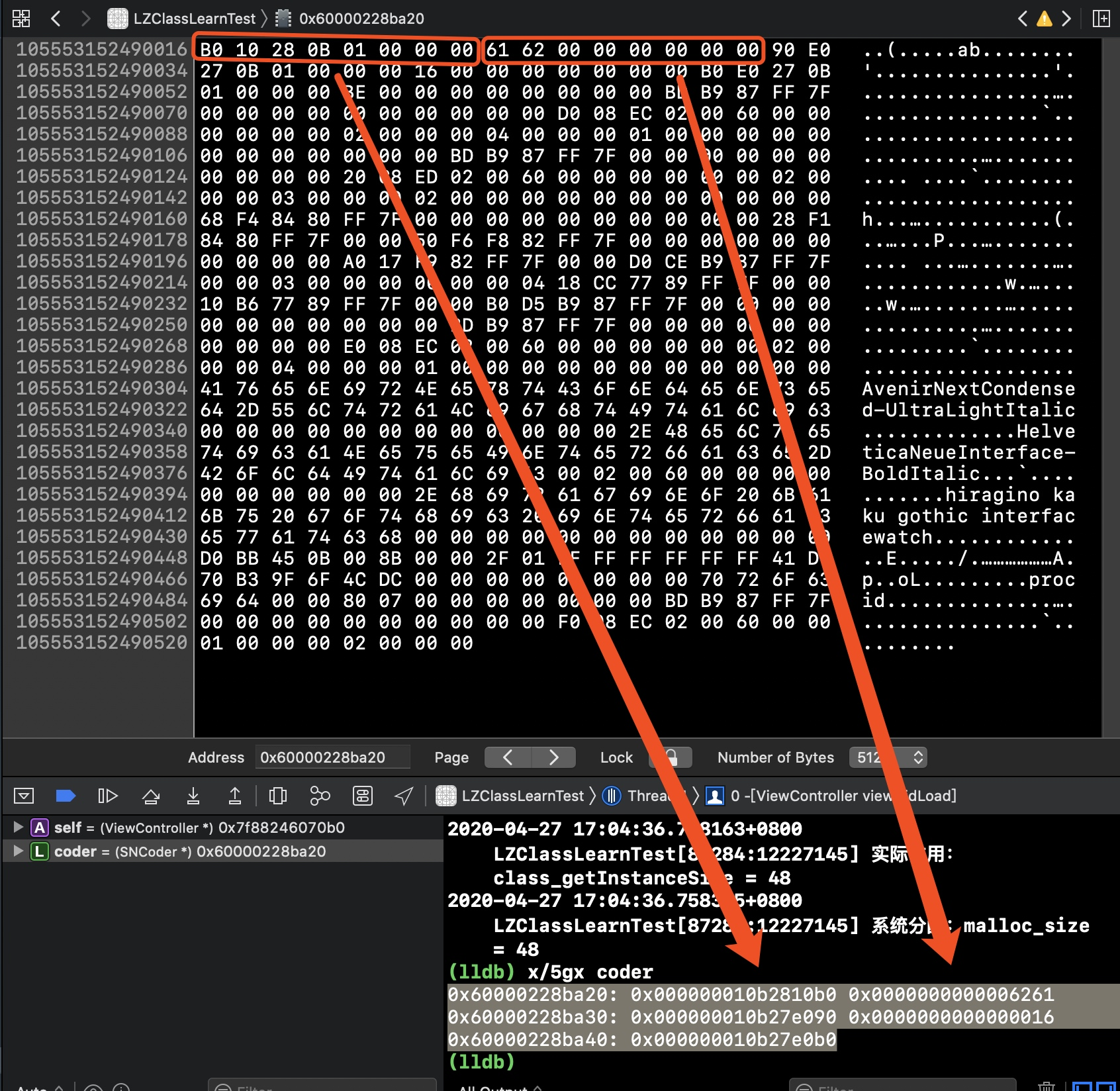
2.3.2 x/(n)gx + 对象
表示输出n个16进制的8字节地址空间(x表示16进制,n表示n个,g表示8字节为单位,等同于x/nxg),这个是为了解决上面的需要倒着读数据的麻烦,如下
// 左边是内存地址,右边两段是内存值
lldb) x/5gx coder
0x60000228ba20: 0x000000010b2810b0 0x0000000000006261
0x60000228ba30: 0x000000010b27e090 0x0000000000000016
0x60000228ba40: 0x000000010b27e0b0
2.3.3 通过xcode工具查看内存地址情况
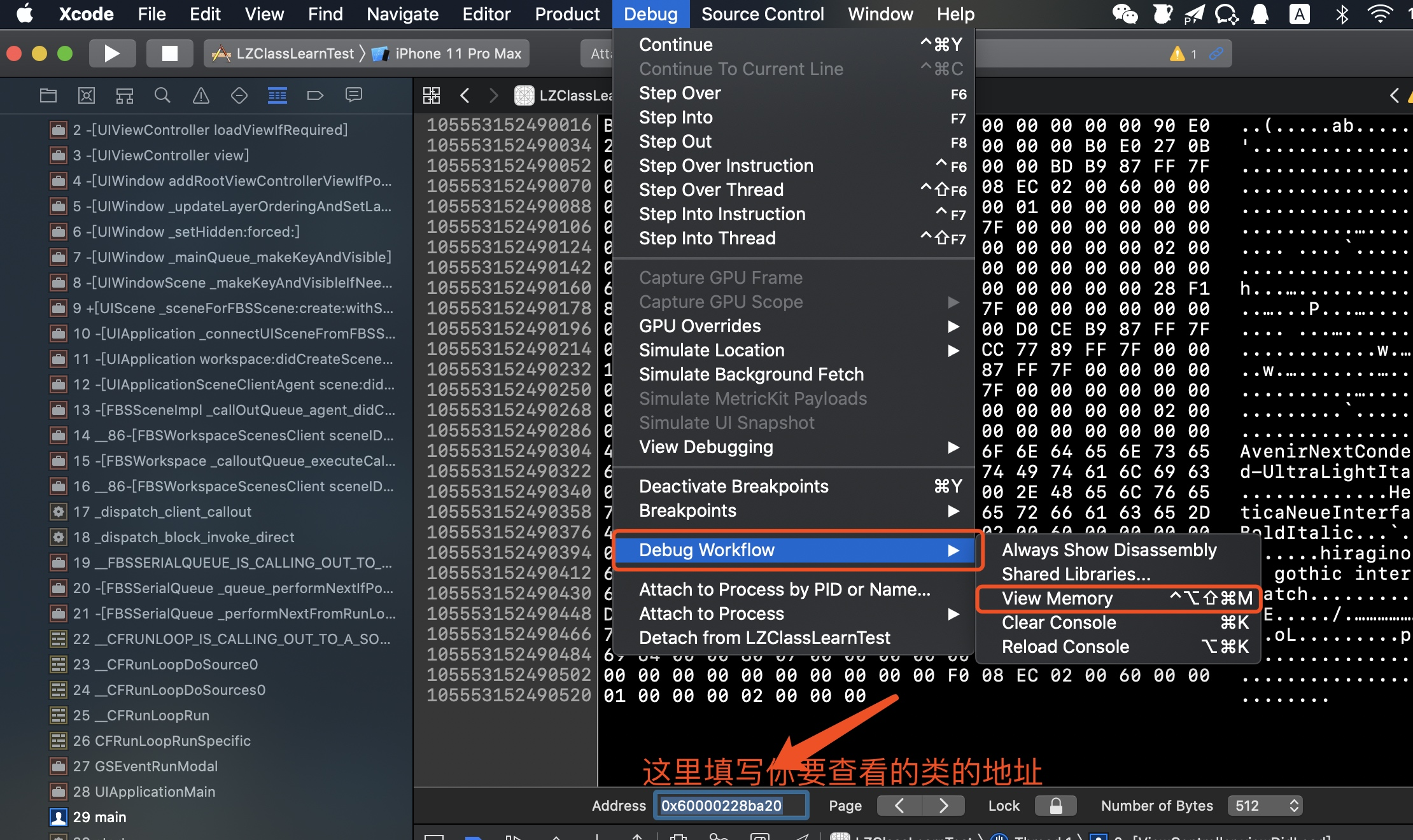
2.3.4 p 与 po
p表示expression——打印对象指针po是expression -O——打印对象本身
(lldb) p 0x00000001043d0038
(long) $10 = 4366073912
(lldb) po 4366073912
girl
2.4 内存对齐原则
2.4.1 二进制重排
二进制重排——将最经常执行的代码或最需要关键执行的代码(如启动阶段的顺序调用)聚合在一起,将无关紧要的代码放在较低的优先级,形成一个更紧凑的__TEXT段
2.4.2 内存优化
如果按照对象默认声明的属性顺序进行内存分配,在进行属性的8字节对齐时会浪费大量的内存空间,所以这里系统会把对象的属性重新排列,以此来最大化利用我们的内存空间——与二进制重排有着异曲同工之妙
2.4.3 内存对齐原则
对象的属性要内存对齐,而对象本身也需要进行内存对齐
- 数据成员对齐原则: 结构(struct)(或联合(union))的数据成员,第 一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要 从该成员大小或者成员的子成员大小
- 结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从 其内部最大元素大小的整数倍地址开始存储
- 收尾工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大 成员的整数倍,不足的要补⻬
2.5 内存对齐示例分析
struct struct1 {
char a; // 1 自动补齐到8
double b; // 8
int c; // 4
short d; // 2
} str1;
struct struct2 {
int c; // 4
double b; // 8
char a; // 1
short d; // 2
} str2;
struct struct3 {
double b; // 8
int c; // 4
char a; // 1
short d; // 2
} str3;
int main(int argc, const char * argv[]) {
@autoreleasepool {
NSLog(@"%lu——%lu——%lu", sizeof(str1), sizeof(str2), sizeof(str3));
}
return 0;
}
打印结果为:24——24——16
2.5.1 分析
已知(64位)char为1字节,double为8字节,int为4字节,short为2字节,内存按照8字节对齐
- 内存对齐原则其实可以简单理解为满足8字节就继续开辟新内存,不满足就可以都放在同一个8字节空间
- 如
str1中的b,因为b本身就需要8字节,所以不能和a共享同样内存空间,所以a单独占据了一个8字节空间,后面的c和d,因为两者是从全新的8字节开始计算的,两者之和不超过8字节,所以他们共用一个8字节,所以最终结果是24; - 如
str2中的c,和str1的a一样,单独占据8个字节,a和d一起占8字节,所以最终结果也是24; - 如
str3中的d,c和a和d因为是从全新的8字节空间开始,且三者之和不超过8字节,所以他们在同一片8字节空间中,最终结果就是16;
2.6 sizeof、class_getInstanceSize、malloc_size分析
NSLog(@"实际占用: class_getInstanceSize = %zd", class_getInstanceSize([SNCoder class]));
NSLog(@"系统分配:malloc_size = %zd", malloc_size((__bridge const void *)(coder)));
NSLog(@"SNCoder类型占用:sizeOf = %zd", sizeof(coder));
2020-03-23 18:43:13.809021+0800 LZClassLearnTest[48575:25140963] 实际占用: class_getInstanceSize = 48
2020-03-23 18:43:14.667750+0800 LZClassLearnTest[48575:25140963] 系统分配:malloc_size = 48
2020-03-23 18:43:15.328555+0800 LZClassLearnTest[48575:25140963] SNCoder类型占用:sizeOf = 8
我们可以通过上面的打印结果看到:
sizeof:它是一个运算符,在编译时就可以获取类型所占内存的大小class_getInstanceSize:依赖于<objc/runtime.h>,返回创建一个实例对象所需内存大小malloc_size:依赖于<malloc/malloc.h>,返回系统实际分配的内存大小- 如果去掉
hobby属性,我们再次打印结果如下:
2020-04-27 16:47:40.114818+0800 LZClassLearnTest[86504:12211963] <SNCoder: 0x600003c5e070>
2020-04-27 16:47:40.114980+0800 LZClassLearnTest[86504:12211963] 实际占用: class_getInstanceSize = 40
2020-04-27 16:47:40.115101+0800 LZClassLearnTest[86504:12211963] 系统分配:malloc_size = 48
2.6.1 疑问点
上面的class_getInstanceSize相信大家都可以根据内存对其原则算出来
isa(8) +
NSString(8) +
int(4) + (由于下一个类型占据8字节,所以这里自动补齐到8字节)
long(8) +
char(1) + char(1) (两个字符类型不足8字节,可以使用一个8字节内存空间)
所以总大小是 40
但是我们看到malloc_size打印出来的是48,这个可能很多人就懵逼了,其实这个是因为对象申请的内存大小和系统开辟的内存大小不一致,这里其实涉及到malloc底层实现导致,所以接下里我们看看malloc的底层分析
三、malloc原理分析
从上一节说到alloc原理,我们可以看到对象在分配内存空间的时候其实发生了如下调用
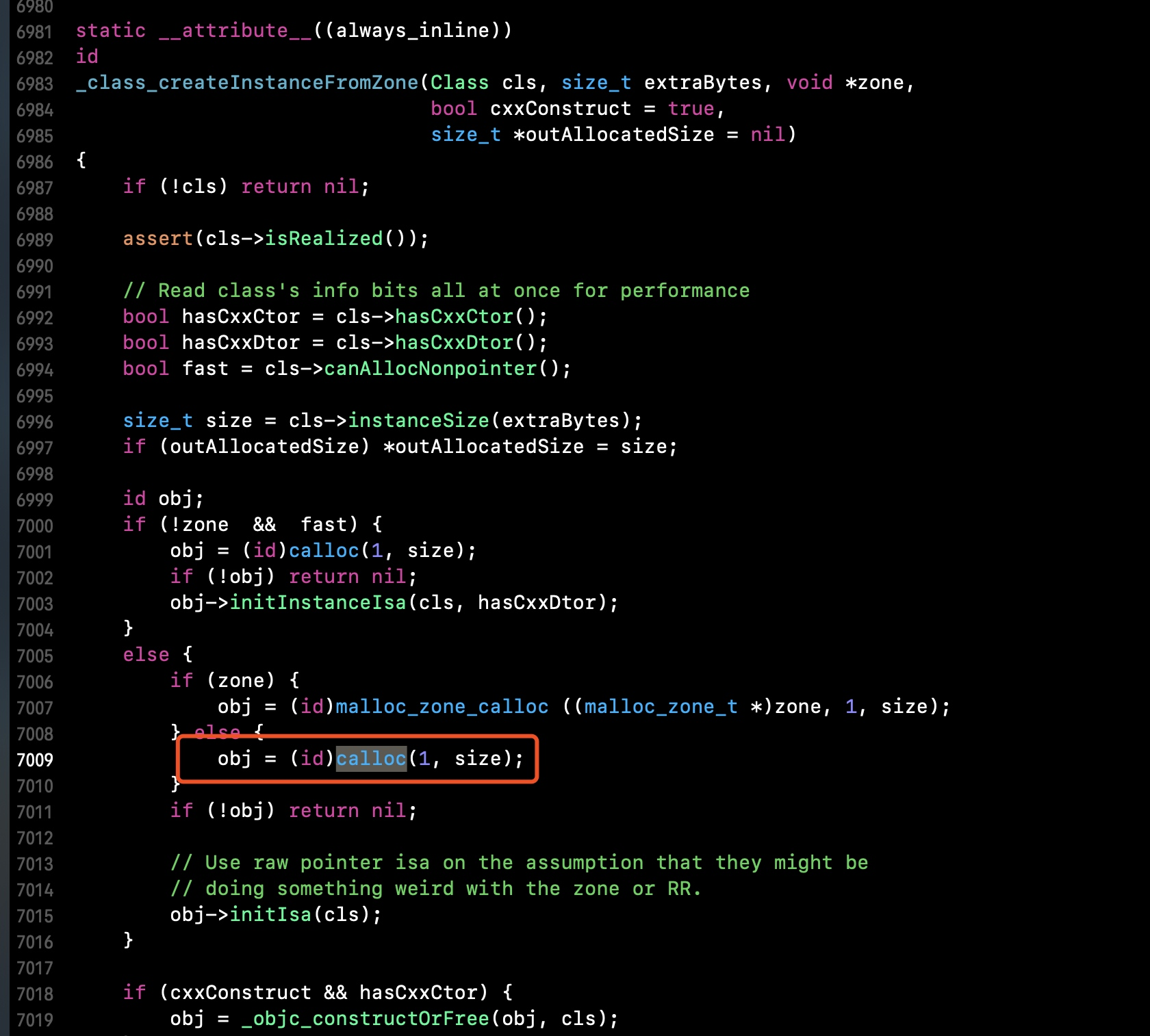
关于内存开辟,alloc在底层申请内存空间时调用了obj = (id)calloc(1, size),之前只有objc源码的我们无从下手,现在我们可以通过libmalloc源码来一探究竟.
3.1 libmalloc源码说明
3.1.1 源码地址
3.1.2 calloc源码分析
我们直接通过调用该函数来探究底层实现,如下
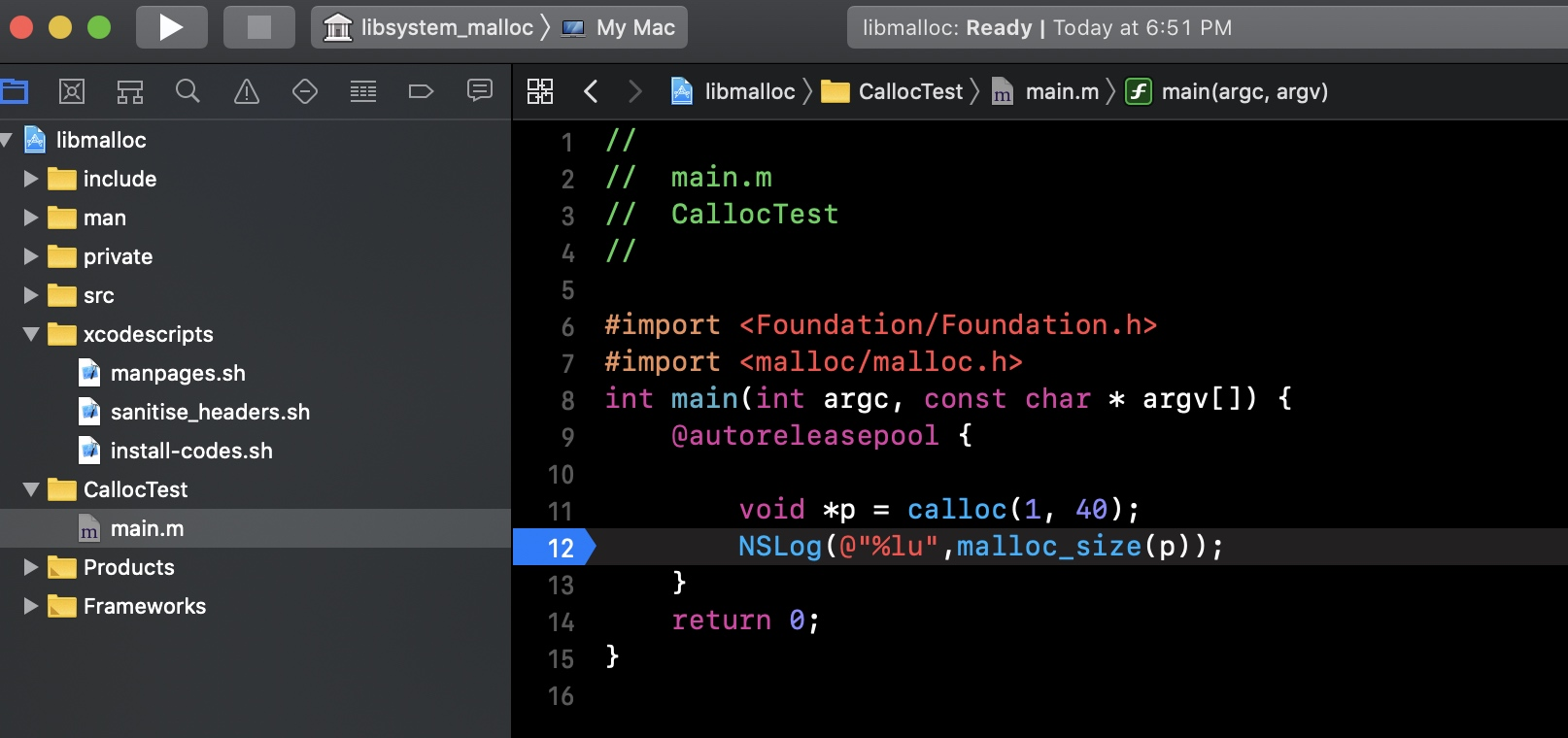
void *
calloc(size_t num_items, size_t size)
{
void *retval;
retval = malloc_zone_calloc(default_zone, num_items, size);
if (retval == NULL) {
errno = ENOMEM;
}
return retval;
}
3.1.2.1 malloc_zone_calloc函数
- 我们再看
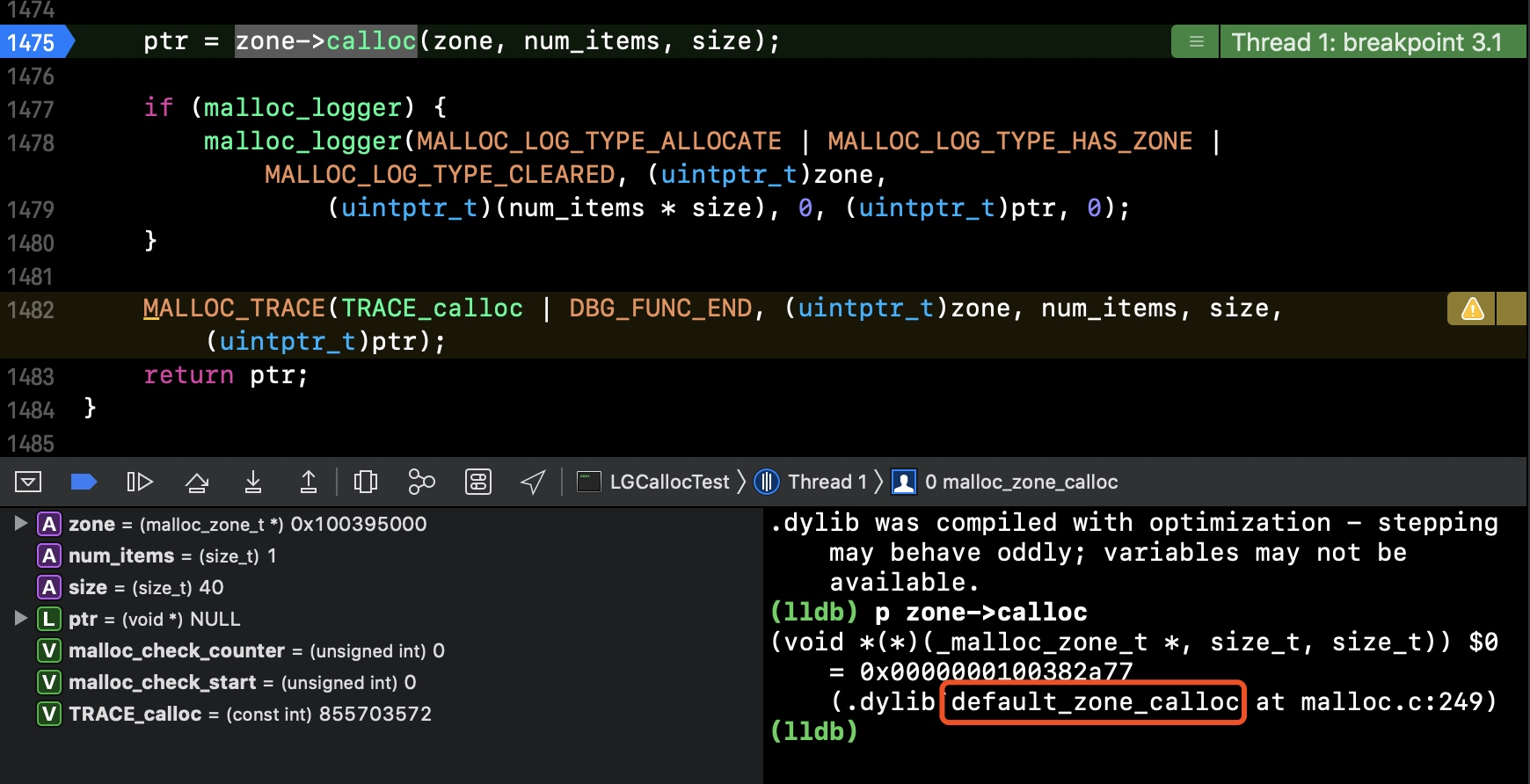
malloc_zone_calloc中的ptr = zone->calloc(zone, num_items, size);这个地方会进入递归,所以我们要想继续看底层实现,可以通过打印函数地址的方式,如下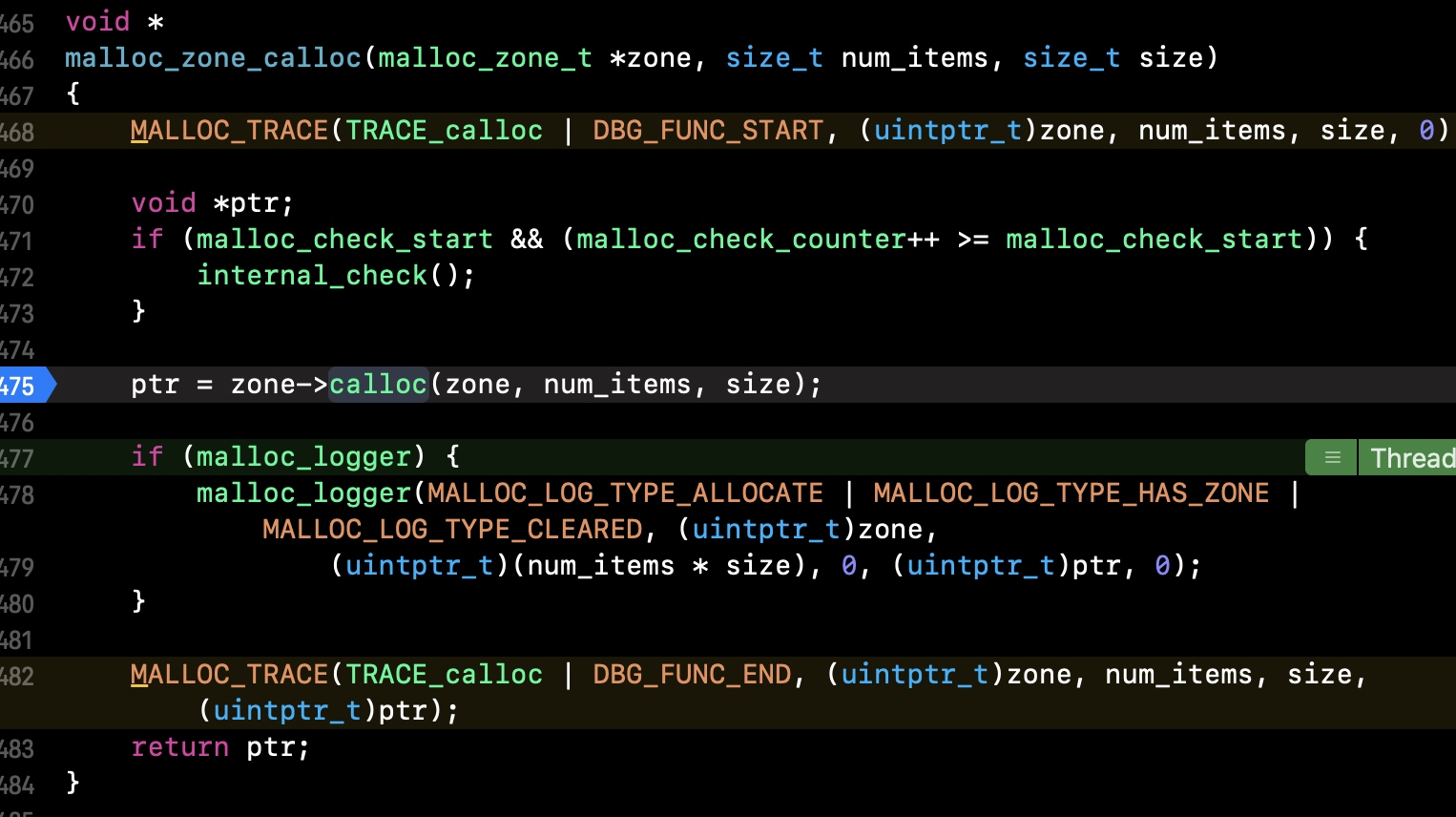
- 我们继续查看
default_zone_calloc函数,继续递归,然后继续打印函数地址,如下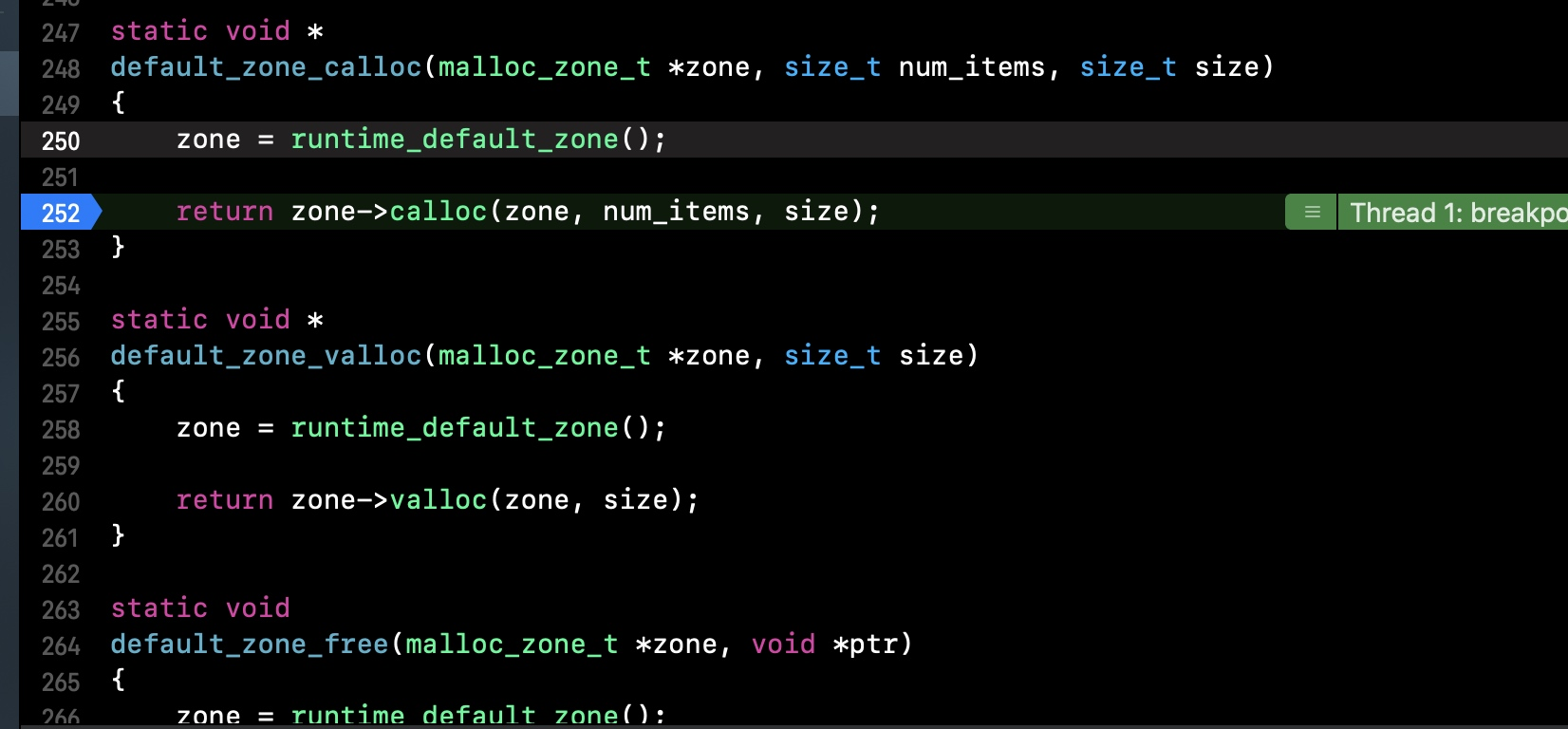
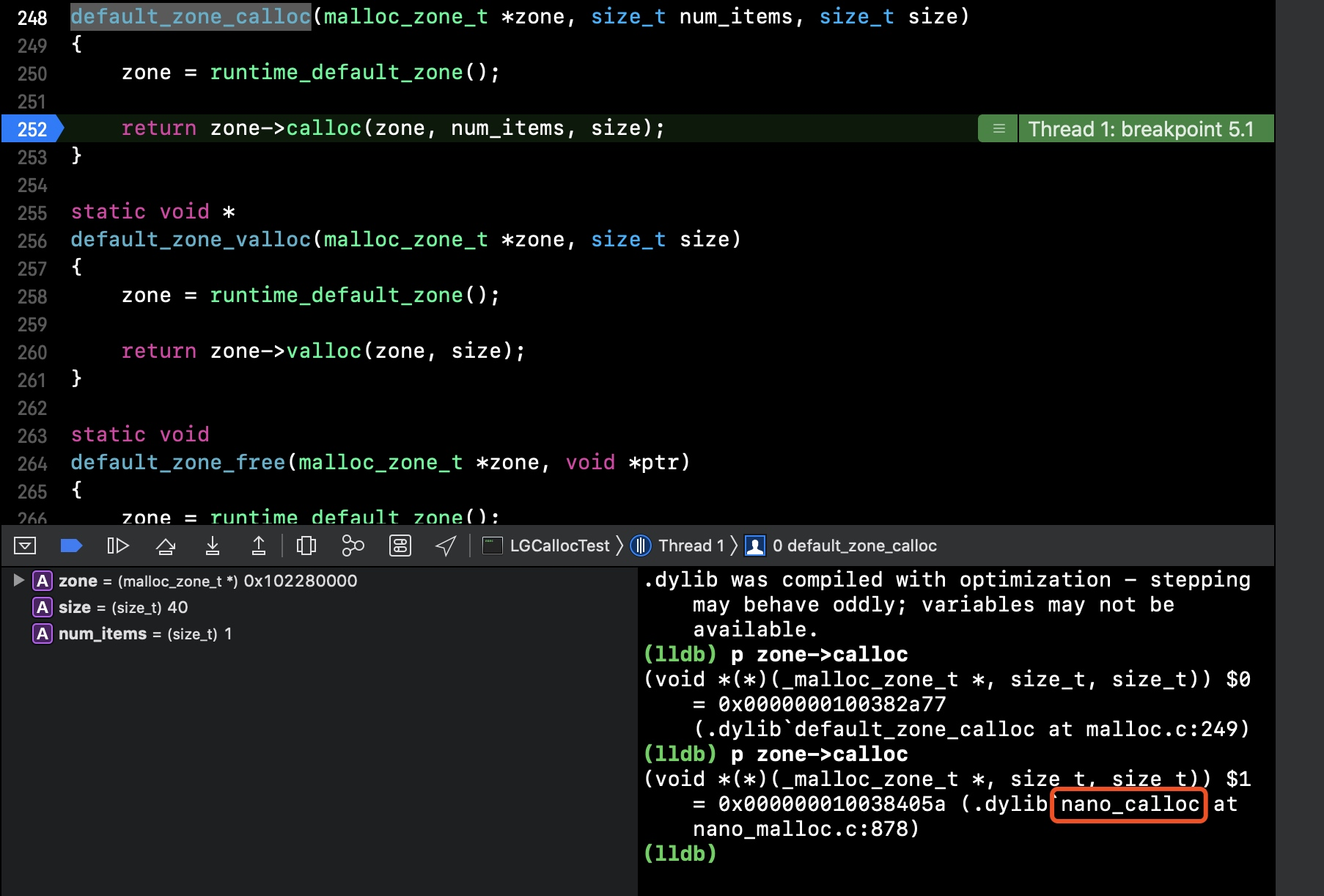
- 查看
nano_calloc函数,如下,按照图中分析,我们最终需要查看的函数是_nano_malloc_check_clear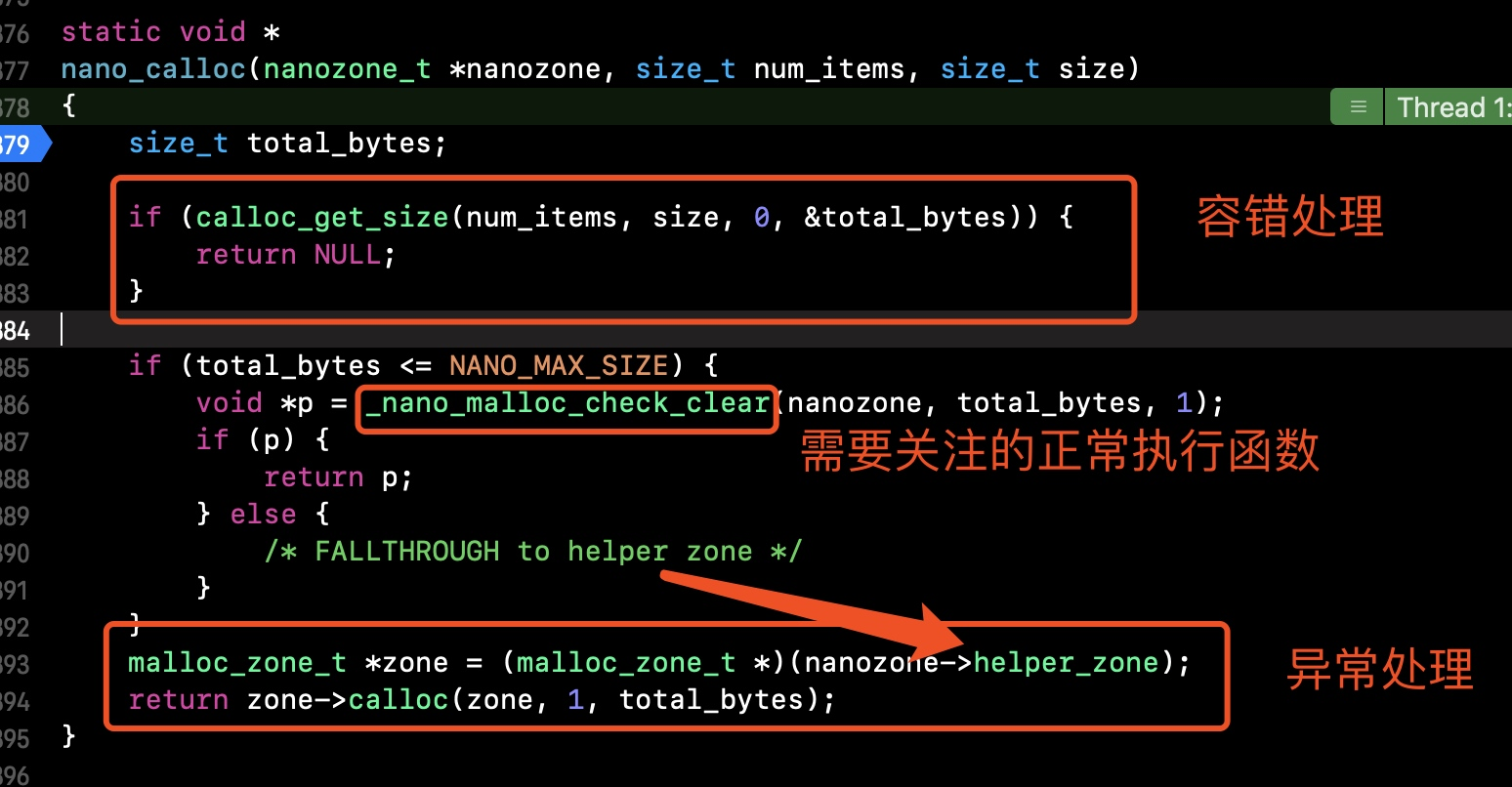
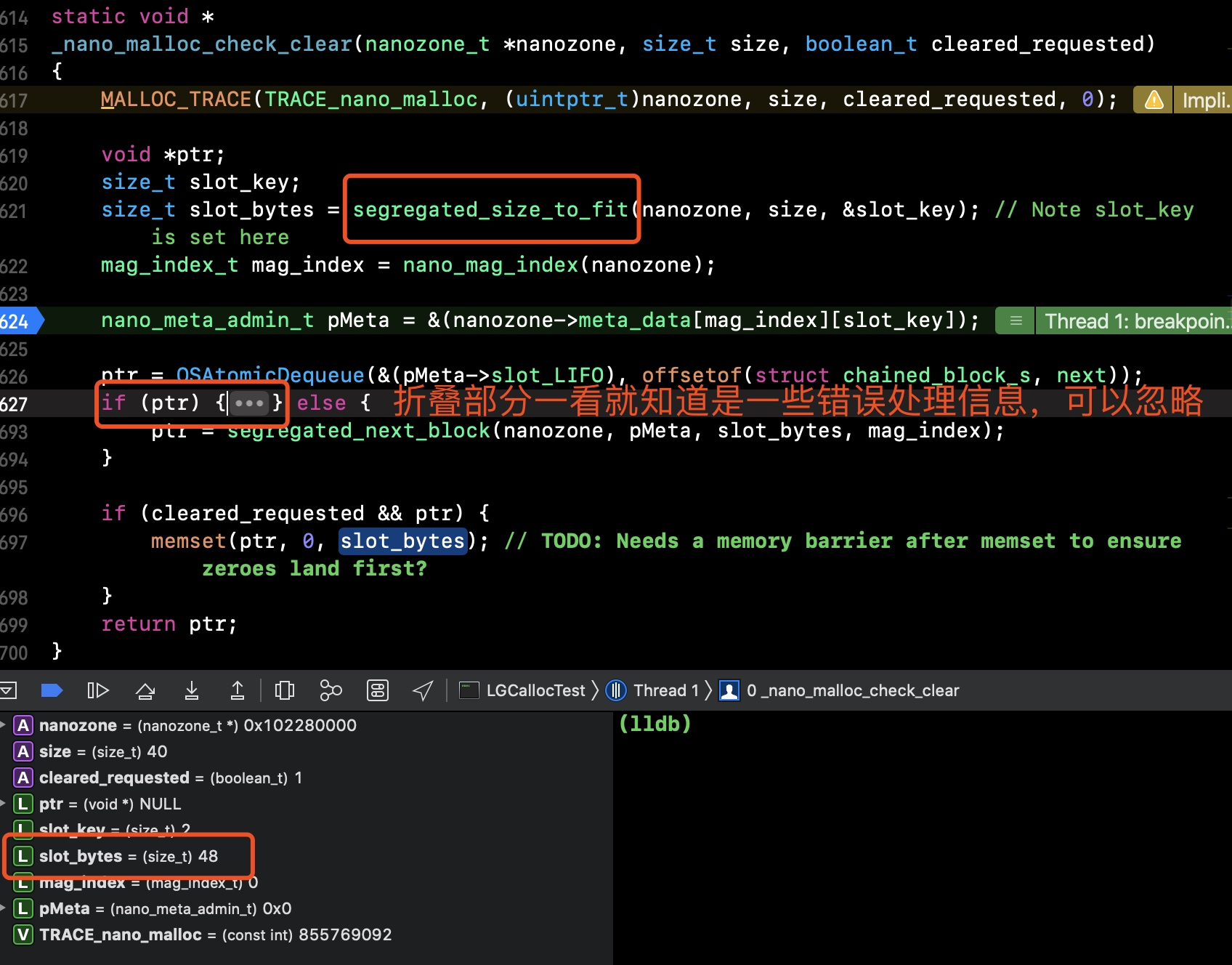
- 从下面的数据信息,我们看到
(size_t) slot_bytes = 48,这就看到我们最终要的结果,所以关键的函数在于计算slot_bytes,即segregated_size_to_fit
- 如上图的算法,可以清晰的看到,系统在创建内存空间的时候是以
16的倍数来创建的,所以我们实际内存为40,系统自动补齐为48
