

概述
(1)LinkedList底层采用的双向链表结构使它在链表头部和尾部的插入和删除操作的效率较高,而其他位置的效率较低,而它实现了Deque接口,表示它具有队列的特性;
(2)LinkedList支持空值和重复值
(3)LinkedList不是线程安全的,但通过调用静态类Collections类中的synchronizedList方法来使它变得线程安全:
List list=Collections.synchronizedList(new LinkedList());
继承体系和成员属性
继承体系
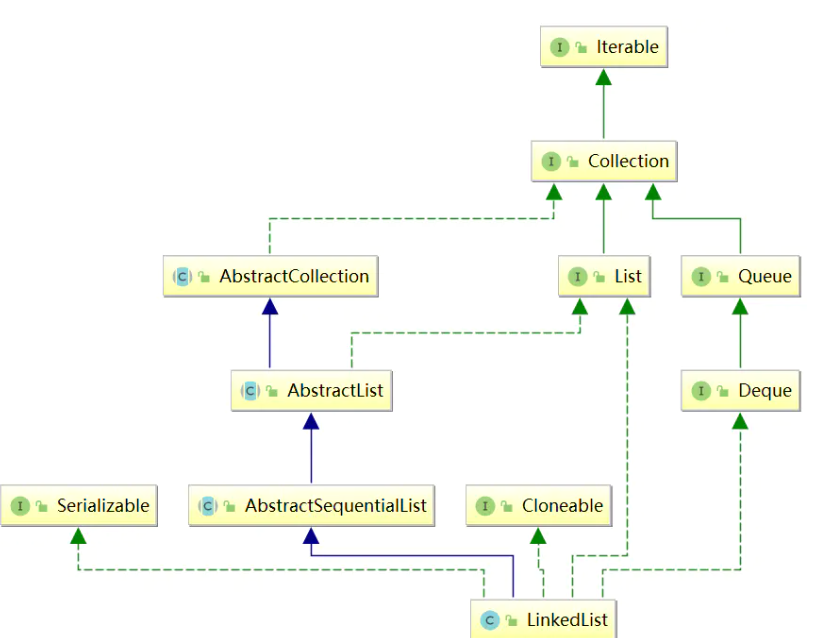
成员属性
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
//记录链表的实际元素个数
transient int size = 0;
//链表的首结点
transient Node<E> first;
//链表的尾节点
transient Node<E> last;
private static class Node<E> {
E item; //结点值
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
构造方法
public LinkedList() {}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
主要方法
add方法
addLast方法
该方法将添加的节点作为尾节点,然后更新节点的指向。
public void addLast(E e) {
linkLast(e);
}
void linkLast(E e) {
//获得当前链表的尾节点
final Node<E> l = last;
//创建一个新的结点,它将作为链表的新尾节点
final Node<E> newNode = new Node<>(l, e, null);
//更新尾节点的引用
last = newNode;
//若原链表的尾节点为null,则将头节点引用指向这个新的结点
if (l == null)
first = newNode;
//将链表的原尾节点的后继节点指向新尾节点newNode
else
l.next = newNode;
size++;
modCount++;
}
addFirst方法
该方法将将新添加的节点设置为头节点,然后更新链表中节点之间的指向。
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
//获取当前链表头节点
final Node<E> f = first;
//创建一个新节点,其前驱结点为null,后继结点为当前的全局首结点
final Node<E> newNode = new Node<>(null, e, f);
//更新全局头结点引用
first = newNode;
//如果原头结点为null,尾结点last指向新建的结点
if (f == null)
last = newNode;
//否则原头节点的前驱结点为newNode
else
f.prev = newNode;
size++;
modCount++;
}
add(int index, E element)方法
该方法将在index位置的前面插入 元素值为E的节点
public void add(int index, E element) {
//检查index是否在[0, size]范围内
checkPositionIndex(index);
//index等于size,就在尾部插入新节点,
if (index == size)
linkLast(element);
//否则就在指定index处插入结点,先找到index处的结点
else
linkBefore(element, node(index));
}
// Node类的根据下标查找节点方法
Node<E> node(int index) {
//如果index在链表的前半部分
if (index < (size >> 1)) {
//则从头节点开始遍历链表
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//否则从尾节点倒序遍历链表
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
void linkBefore(E e, Node<E> succ) {
//succ是指定位置处的结点,pred是其前驱节点
final Node<E> pred = succ.prev;
//创建期望放入的结点,该节点要放在pred节点和succ节点之间
final Node<E> newNode = new Node<>(pred, e, succ);
//更新index处结点的前驱结点引用
succ.prev = newNode;
//若指定位置结点的前驱结点为null,即在头部插入结点,则新节点作为头节点
if (pred == null)
first = newNode;
//不为null,那么它的后继结点就是新的结点
else
pred.next = newNode;
size++;
modCount++;
}
remove方法
removeFirst方法和pollFirst方法
这两个方法都是删除队列首元素,主要区别在于当头节点为null时,前者会抛异常,后者返回null
// remove的时候如果没有元素抛出异常
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
// poll的时候如果没有元素返回null
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
//获取头结点的元素值
final E element = f.item;
//获取头结点的后继结点
final Node<E> next = f.next;
//删除头节点中存放的元素item和后继结点
f.item = null;
f.next = null; // help GC
//更新头节点引用
first = next;
//若原链表只有一个结点,那么尾节点也是null了
if (next == null)
last = null;
//否则将新头节点的前驱结点设置为null
else
next.prev = null;
size--;
modCount++;
// help GC
return element;
}
removeLast方法和pollLast方法
移除队尾元素,并返回移除的元素同样有两种方法:
// remove的时候如果没有元素抛出异常
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
// poll的时候如果没有元素返回null
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
// 删除尾节点
private E unlinkLast(Node<E> l) {
final E element = l.item;
final Node<E> prev = l.prev;
// 清空尾节点的内容,协助GC
l.item = null;
l.prev = null; // help GC
// 让原尾节点的前置节点成为新的尾节点
last = prev;
// 如果原链表只有一个元素,则把first置空
if (prev == null)
first = null;
else // 否则把前置节点的next置为空
prev.next = null;
// 更新size和modCount
size--;
modCount++;
return element;
}
删除头尾之间的节点
remove(int index)方法删除指定下标的节点,并返回删除值。
// 删除中间节点
public E remove(int index) {
// 检查是否越界
checkElementIndex(index);
// 删除指定index位置的节点
return unlink(node(index));
}
// 删除指定节点x
E unlink(Node<E> x) {
// x的元素值
final E element = x.item;
// x的前置节点
final Node<E> next = x.next;
// x的后置节点
final Node<E> prev = x.prev;
// 如果前置节点为空,说明x是首节点,则x的后继节点作为新头结点
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
// 如果后置节点为空,说明是x是尾节点,则x的前驱结点作为新尾节点
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
// 清空x的元素值,协助GC
x.item = null;
size--;
modCount++;
// 返回删除的元素
return element;
}
在删除节点时,这三个操作都将指向下一节点的地址next指针/指向上一节点的地址pre都置为null,源码中的注释表示这有助于GC。
如何理解注释中说明的GC?
LinkedList<?> list = new LinkedList();
//iterator持有list头结点引用
ListIterator<?> iterator = list.listIterator(0);
list.removeFirst();
//list及其所有节点都会被GC
list = null;
/*
我们以删除头结点为例
假如没有f.next = null,那么由于iterator引用了头结点,
而头结点的next还指向这些节点。则其他节点不会被GC,只有当iterator被
GC了才会被GC。
*/
查找
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// Node类的根据下标查找节点方法
Node<E> node(int index) {
//如果index在链表的前半部分
if (index < (size >> 1)) {
//则从头节点开始遍历链表
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//否则从尾节点倒序遍历链表
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
遍历
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned;
private Node<E> next;
private int nextIndex;
private int expectedModCount = modCount;
ListItr(int index) {
//
next = (index == size) ? null : node(index);
nextIndex = index;
}
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
//省略其他方法
}
