

卷积神经网络(Convolution Neural Network, CNN)的研究始于20世纪80年代。在此之前,处理图像数据使用的是全连接神经网络,然而全连接层参数太多,直接导致计算速度变慢,而且容易产生过拟合问题。
如果图片大小为100x100x3,第一层隐层的神经元数目为1000,那么这一层的参数就达到了
个!
因此,需要一个更合理的神经网络结构来有效处理图片数据。随着数值计算效率得到巨大提升,CNN处理数字图像数据的巨大潜能被充分发现挖掘。2012年基于CNN的AlexNet模型在ImageNet图像分类竞赛中取得第一名的成绩,其模型准确度领先第二名11%。接着,VGG、GoogLeNet、ResNet也相继被提出。此后,对CNN的深入研究一直在持续。
本篇文章整理了CNN的基本结构及原理,以期读者对CNN有入门级的了解和掌握。
1. CNN结构概览
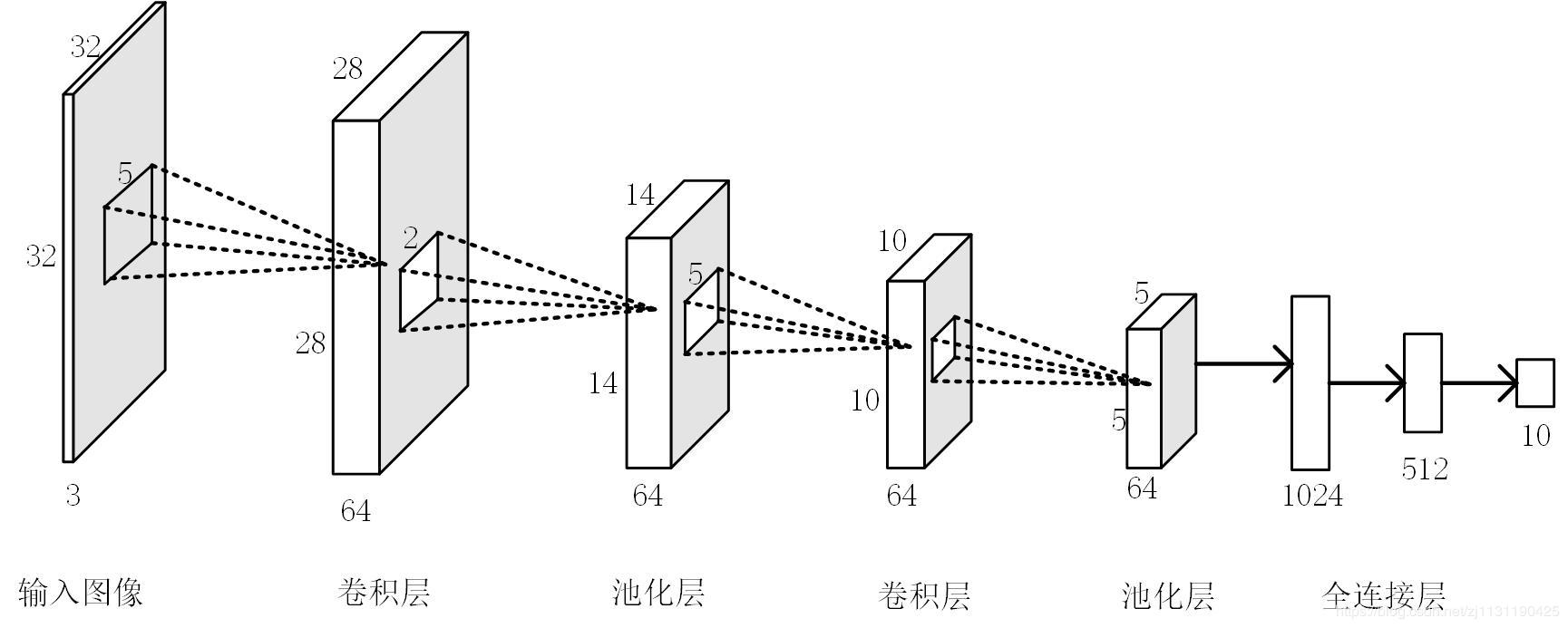
一个完整的CNN包含如下的结构:
- 输入层: 网络的输入,以图像为例,一般代表一张图片的像素矩阵。
- 卷积层: CNN中最为重要的部分。通过卷积操作获取图像的局部区域信息。
- 池化层: 对数据进行降采样(Down Sampling),缩小数据规模,收集关键数据,同时提高计算速度。
- 全连接层: 将学到的特征表示映射到类标签空间,起到分类器的作用。
2. 输入层
表示整个神经网络的输入。在本文中,将以处理图像数据为例。在处理图像时,输入层一般代表一张图像的三维像素矩阵,大小通常为或者
的矩阵,其中这三个维度分别图像的宽度、长度、深度。深度也称为通道数,在彩色图像中有R、G、B三种色彩通道,而黑白图像只有一种色彩通道。
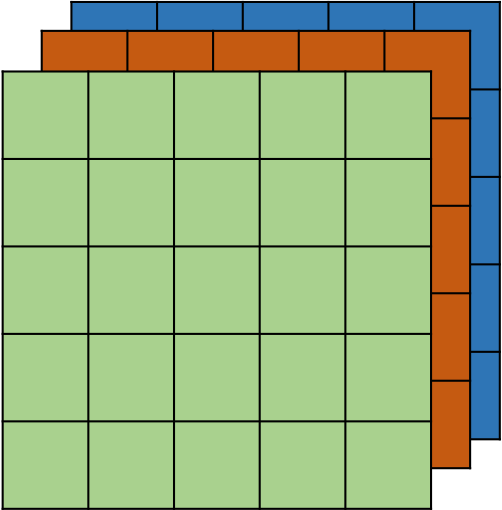
3. 卷积层
卷积层是CNN结构中最重要的部分。它通过卷积操作获取图像的局部区域信息。
3.1 卷积操作
卷积操作通过使用过滤器filter(也称作卷积核),将当前层神经网络上的子节点矩阵转化为下一层神经网络上的一个节点矩阵,得到的矩阵称之为特征图(feature map)。
这里以像素矩阵通道等于1时来了解卷积过程。
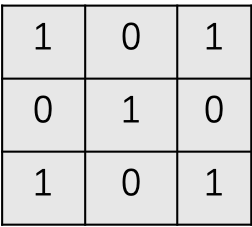
首先,先定义一个的filter,其实是一个矩阵。filter的数值这里是手工设置的。在实际中,这些值是网络的参数,通常是随机初始化后通过网络学习得到的。
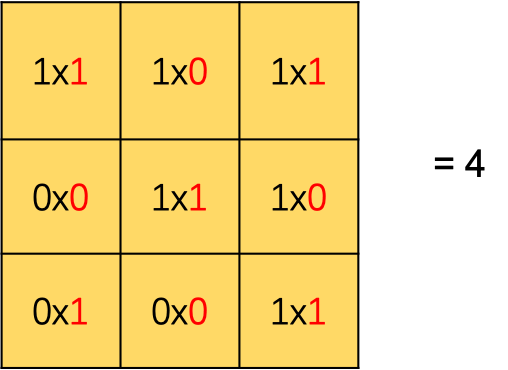
卷积操作就是filter矩阵跟filter覆盖的图片局部区域矩阵(如下图image中的黄色区域)对应的每个元素相乘后累加求和。
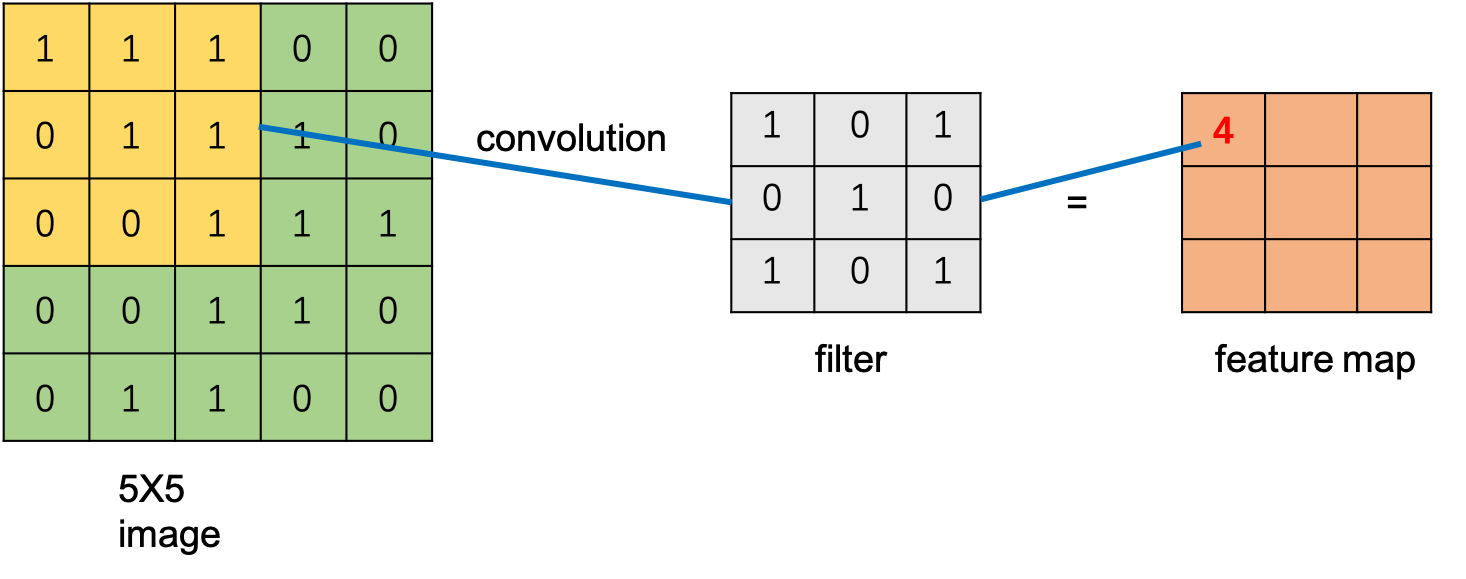
上图中右侧矩阵中的"4"值是是怎么计算得到的呢?下图详细演示了计算过程。其中矩阵中黑色数值是来自输入矩阵对应的局部区域,红色数值是对应的filter矩阵的值。相应元素相乘后再累加即可得到卷积结果。
这么看,卷积操作是不是很简单?
在完成上面的卷积操作后,filter会继续移动,然后再进行卷积操作。一次移动的距离称作步长(Stride)。这里设定步长为1,则向右移动1个单元格,在当前区域继续进行卷积操作,得到卷积值。注意,卷积步长只在输入矩阵的长和宽这两个维度实施。
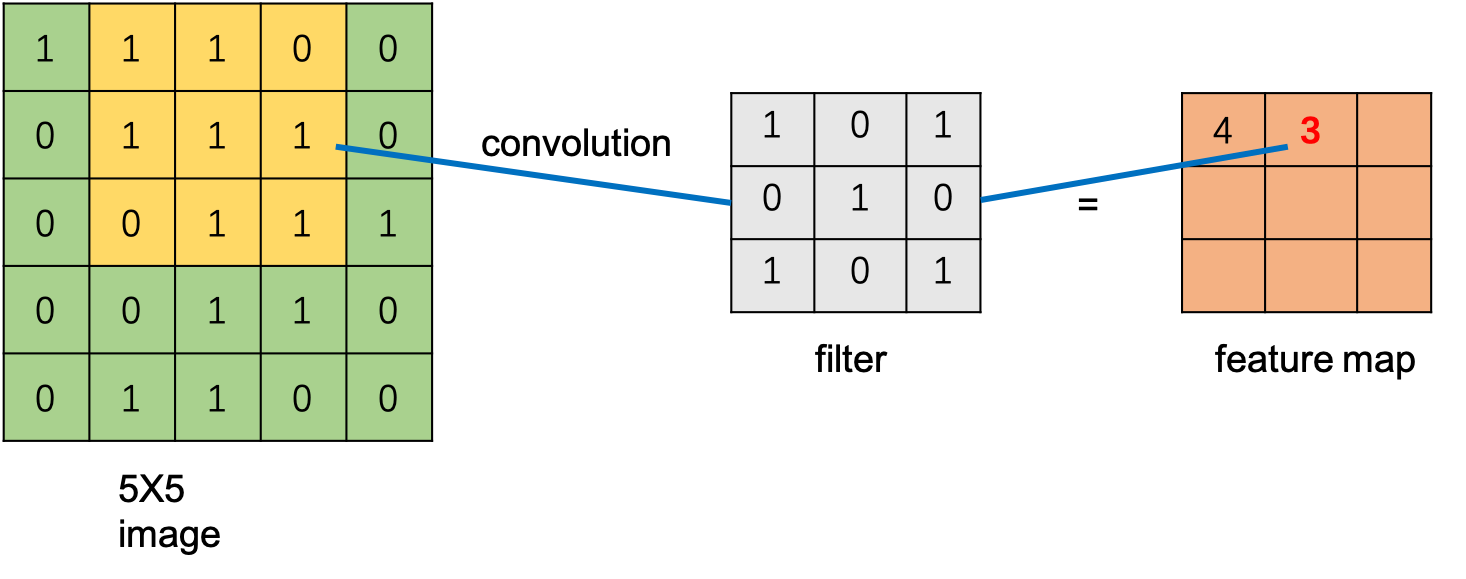
单个filter在输入矩阵上完成卷积的整个动态过程如下图所示。当filter移动到输入矩阵的最右侧时,下一次将向下移动一个步长,同时从最左侧重新开始。可以看到,在卷积过程中,要始终保持filter矩阵在输入矩阵范围内。
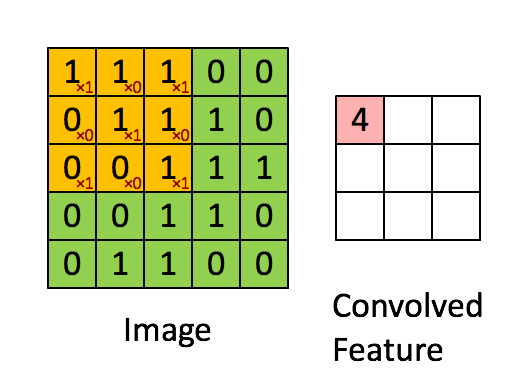
卷积层的操作过程就是将上面的filter矩阵从输入矩阵的左上角一个步长一个步长地移动到右下角。在移动过程中计算每一个卷积值,最终计算得到的矩阵就是特征图(feature map)。
filter为什么能够有效提取特征信息?
- 如果有图片的局部区域跟filter矩阵比较相似,在进行卷积后的输出值会比较大。卷积值越大,就越表明检测到filter对应的物体特征。
- filter的大小只覆盖图片的局部区域,这种局部连接可以让特征只关注其应该关注的部分。这种设计符合人类对物体认知原理的,试想一下,我们在看到一只猫后,其实是记住这只猫各个区域最显著的特征,这样当我们看到一只狗时,就能够根据局部特征区分猫与狗。
- 同一个filter在进行卷积计算时参数是不变的,也被称作权值共享,这样就可以检测不同区域上相同的物体特征。
3.2 多通道输入层
前面内容将输入层简化为单通道结构。在实际应用中,输入层通常通常包含多个矩阵的叠加,也就是多通道结构。
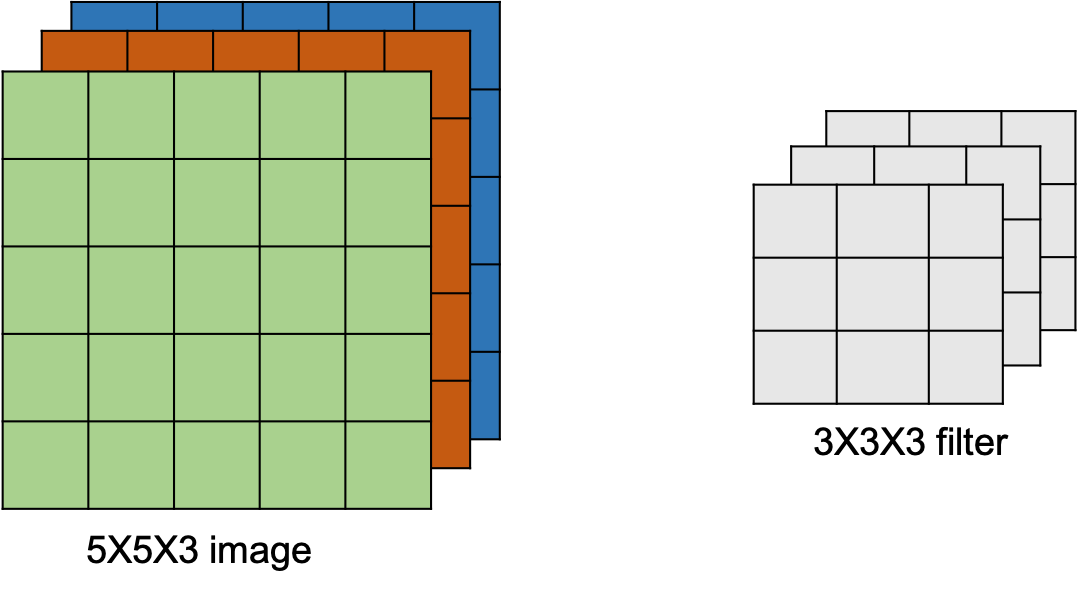
比如,一张彩色图像包含3通道结构。这种情形下,filter的深度由输入矩阵的深度决定。上图中,输入矩阵包含了三个通道的数据,那么filter也会包含三个矩阵。卷积计算过程与之前不同的地方在于,每一层的filter在与对应层的输入矩阵进行卷积后,会接着再把各个层计算的结果相加得到输出值。
假设filter大小为,对应的元素用u表示,输入矩阵的元素用a表示,那么在卷积层的计算过程中,特征图矩阵中第i个节点的取值为:
其中i表示filter在输入矩阵从左上角向右下角根据步长移动时对应的位置信息。
3.3 激活函数
前面计算的卷积值是输入矩阵的线性函数。在实际使用中,引入激活函数,其目的是增加整个网络的非线性表达能力,否则,若干线性操作层的堆叠仍然是线性映射,无法形成复杂函数,也就无法捕获实际应用中非线性特征的表达形式。
常用的激活函数有sigmoid,relu等,则卷积值采用下面公式计算,其中为激活函数。
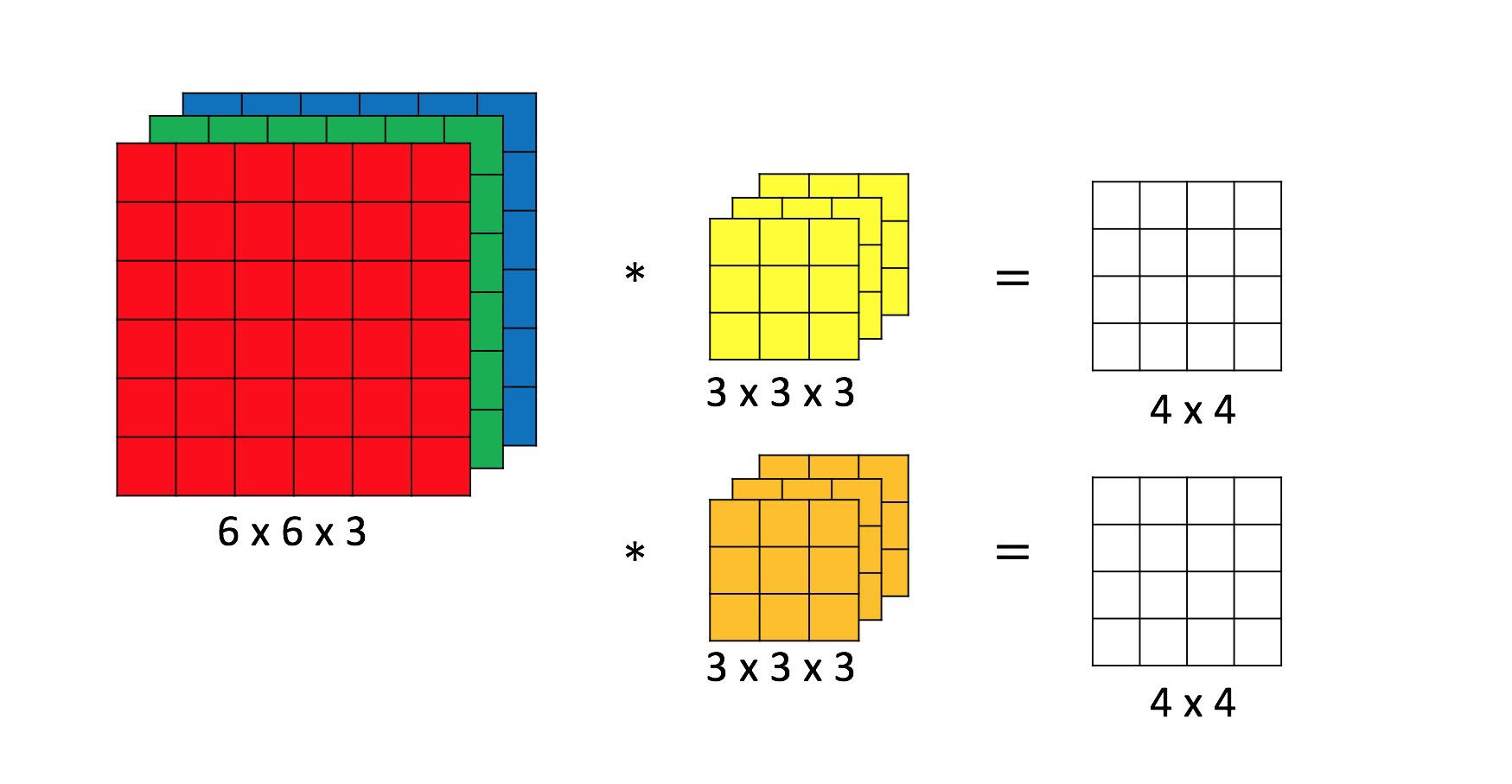
3.4 多filter卷积操作
一个filter可以针对一个特征进行提取。实际中,物体通常会包含多个显著特征,我们通常设置多个filter来提取不同的特征。
例如,我们使用2个filter来进行卷积,就得到2个相同大小的特征图。这些特征图会重新组合成为深度为2的图片,作为下一层卷积的输入。
3.5 Padding
Padding是在输入矩阵数据周围进行数据填充,常用0来填充。当Padding=1时,在矩阵周围填充一圈,当Padding=2时,填充两圈。
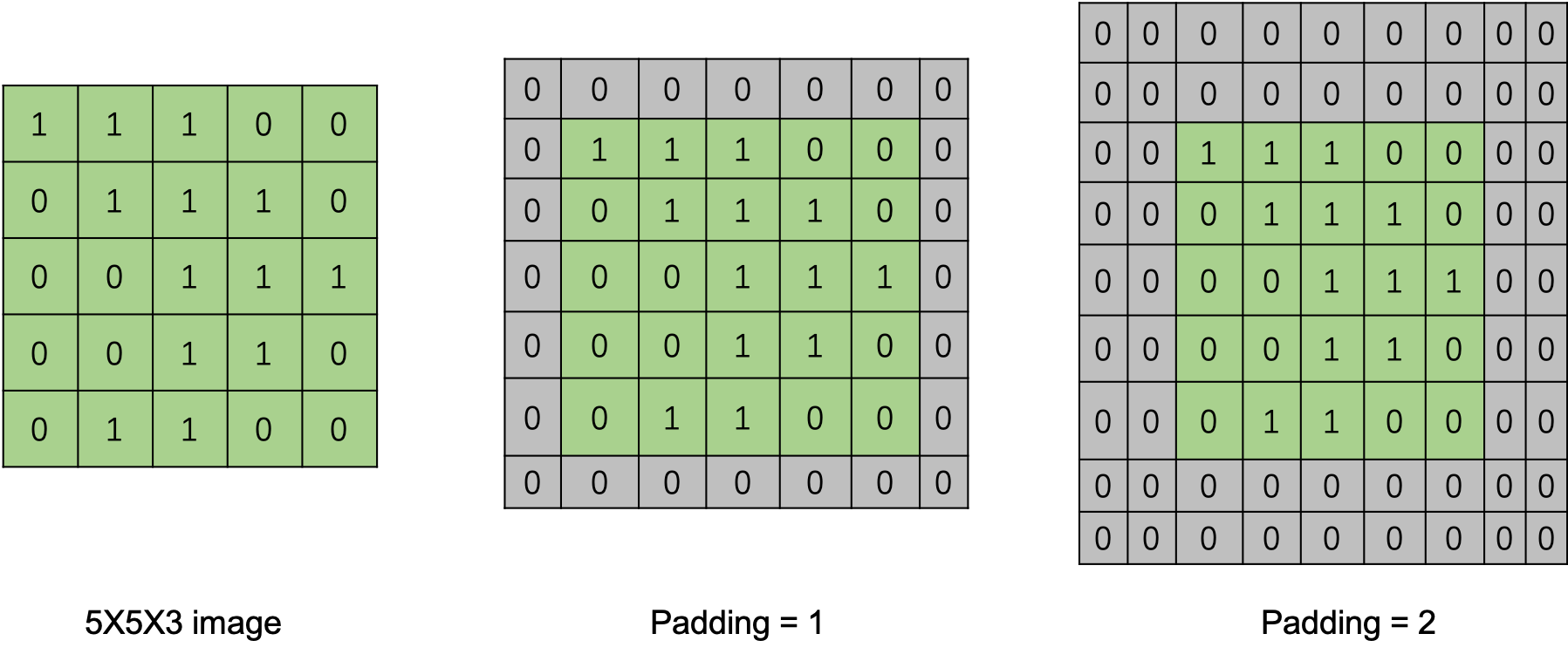
为什么要进行Padding?
- 从卷积的计算过程可知,随着卷积操作的进行,图像会越来越小。特别的,当有多个卷积层,图像变小会特别明显。通过Padding可以适当保持图像大小。
- 卷积过程对图片边缘信息和内部信息的重视程序不一样,边缘信息filter只经过一次,而内部信息会被经过多次。通过Padding操作可以缓解信息处理不平衡的问题。
4. 池化层(Pooling Layer)
池化层的作用是缩小特征图,保留有用信息,得到一个更小的子图来表征原图。池化操作本质上是对图片进行降采样,可以认为是将一张分辨率高的图片转化为分辨率较低的子图,保留的子图不会对图片内容理解产生太大影响。
池化的方式一般有两种:Max Pooling和Average Pooling。
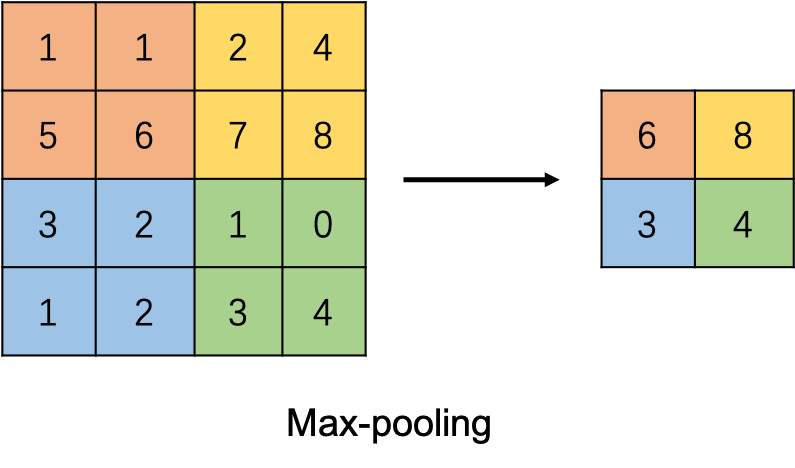
上图中为Max Pooling,首先设定Pooling的大小与步长,然后覆盖到对应格子上面,找出最大值作为输出结果,例如上图Pooling选择2×2,步长选择为2,因此输出就是2×2的维度,每个输出格子都是对应维度上输入的最大值。
如果为Average Pooling,那么就是选择其间的平均值作为输出的值。
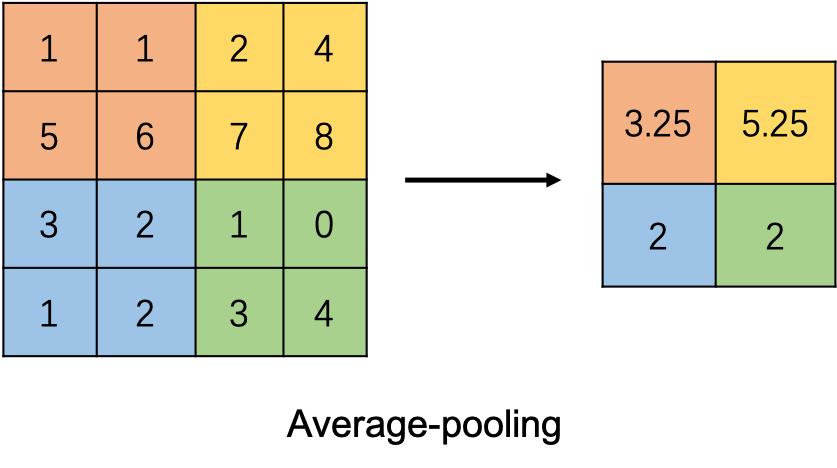
因此从上面的过程我们看到,与卷积操作类似,池化层的计算过程也是通过一个类似filter 的结构上下左右移动来完成的。与卷积操作不同之处在于:
- Pooling矩阵中的计算不是节点的加权和,而是采用更加简单的最大值或者平均值运算。
- Pooling矩阵除了在长和宽两个维度移动之外,它还需要在深度这个维度移动。也就是说,在进行max或者average操作时,只会在同一个矩阵深度上进行,而不会跨矩阵深度进行。
- 池化层本身没有可以训练的参数。
5. 全连接层
在经过多层的卷积层和池化层操作后,一般会有1-2个全连接层,给出最后的分类结果。全连接层在整个卷积神经网络中起到“分类器”的作用,它将学到的特征表示映射到类标签空间。
在实际中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为的卷积;而前层是卷积层的全连接层可以转化为卷积核为
的全局卷积,h和w分别为前层卷积输出结果的高和宽。
在某一个CNN网络中,最后一层卷积层的输出为7 × 7 × 512的特征张量,如果后层是一层含4096个神经元的全连接层时,则可用卷积核为7 × 7 × 512 × 4096的全局卷积来实现全连接运算过程。
对于多分类问题,全连接层后面可以选择softmax,这样我们可以得到样本属于各个类别的概率分布情况。
6. 目标函数
全连接层是将网络特征映射到类标签空间做出预测,目标函数的作用则用来衡量该预测值与真实样本标签之间的误差。交叉熵损失函数和l2损失函数分别是分类问题和回归问题中最为常用的目标函数。
7. 总结
本篇文章介绍了卷积神经网络的基本部件:输入层、卷积层、池化层、全连接层和目标函数。 可以将卷积层和池化层看作自动提取图像特征的操作,经过操作会将图像信息含量更高的特征提取出来。在特征提取完成后,由全连接层给出最后的分类结果。
当前,CNN已广泛应用于图像领域。同时除了图像领域外,CNN也被成功应用于自然语言处理、语音识别等领域。

