

前言
继上一篇Flink的state、checkpoint、savepoint之后,这一篇主要是演示Flink的Event Time、Watermark的使用。
到现在也写了好几篇了,感觉写的不太好,好像就平铺直述的感觉,可能还是没什么写这东西的天分,就当做是记录吧。如果有什么不足与问题,欢迎评论交流。
1.1 TimeWindow
像这种代码,大家应该都很熟悉了,但是主要是为了下面介绍process,做一个铺垫。这个其实是一种窗口,后面会详细介绍。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
//每隔5秒统计最近10秒的数据
public class TimeWindowDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lc = env.socketTextStream("localhost", 8888);
lc.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = value.split(",");
for (String s : split) {
collector.collect(Tuple2.of(s,1));
}
}
}).keyBy(0).timeWindow(timeWindow(Time.seconds(10),Time.seconds(5))).sum(1).print().setParallelism(1);
env.execute("TimeWindowDemo");
}
}
1.2 process
process 要求继承一个ProcessWindowFunction抽象类,并且要求实现process方法。
import org.apache.commons.lang.time.FastDateFormat;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class TimeWindowDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//在控制台输入hive hbase
DataStreamSource<String> lc = env.socketTextStream("localhost", 8888);
lc.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = value.split(",");
for (String s : split) {
collector.collect(Tuple2.of(s,1));
}
}
}).keyBy(0).timeWindow(Time.seconds(10),Time.seconds(5))
.process(new ProcessWindownImpl())
.print().setParallelism(1);
env.execute("TimeWindowDemo");
}
/**
* IN, OUT, KEY, W
* IN:输入的数据类型
* OUT:输出的数据类型
* Key:key的数据类型(在Flink里面,String用Tuple表示)
* W:Window的数据类型
*/
public static class ProcessWindownImpl extends ProcessWindowFunction<Tuple2<String,Integer>,Tuple2<String,Integer>, Tuple, TimeWindow> {
FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
/**
* 当一个window触发计算的时候会调用这个方法
* @param tuple key
* @param context operator的上下文
* @param elements 指定window的所有元素
* @param out 用户输出
*/
@Override
public void process(Tuple tuple, Context context, Iterable<Tuple2<String, Integer>> elements,
Collector<Tuple2<String, Integer>> out) {
System.out.println("当前时间:"+ format.format(System.currentTimeMillis()));
System.out.println("Window的处理时间:"+ format.format(context.currentProcessingTime()));
System.out.println("Window的开始时间:"+ format.format(context.window().getStart()));
System.out.println("Window的结束时间:"+ format.format(context.window().getEnd()));
int sum = 0;
for (Tuple2<String, Integer> ele : elements) {
sum += 1;
}
// 输出单词出现的次数
out.collect(Tuple2.of(tuple.getField(0), sum));
}
}
}
结果,可以看到这里的窗口打印的时间,是5秒产生一个窗口,。每一个窗口都有当时的数据,并且进行了打印。
当前时间: 18:22:40
Window的处理时间: 18:22:40
Window的开始时间: 18:22:30
Window的结束时间: 18:22:40
(hive,1)
当前时间: 18:22:45
当前时间: 18:22:45
Window的处理时间: 18:22:45
Window的处理时间: 18:22:45
Window的开始时间: 18:22:35
Window的开始时间: 18:22:35
Window的结束时间: 18:22:45
Window的结束时间: 18:22:45
(hive,1)
(hbase,1)
根据5秒一个窗口,那么每隔5秒生成一个窗口,统计10秒,其实就是窗口的范围大小,开始时间和接受时间相差10秒,处理时间等于结束时间,
1.3 Time的种类
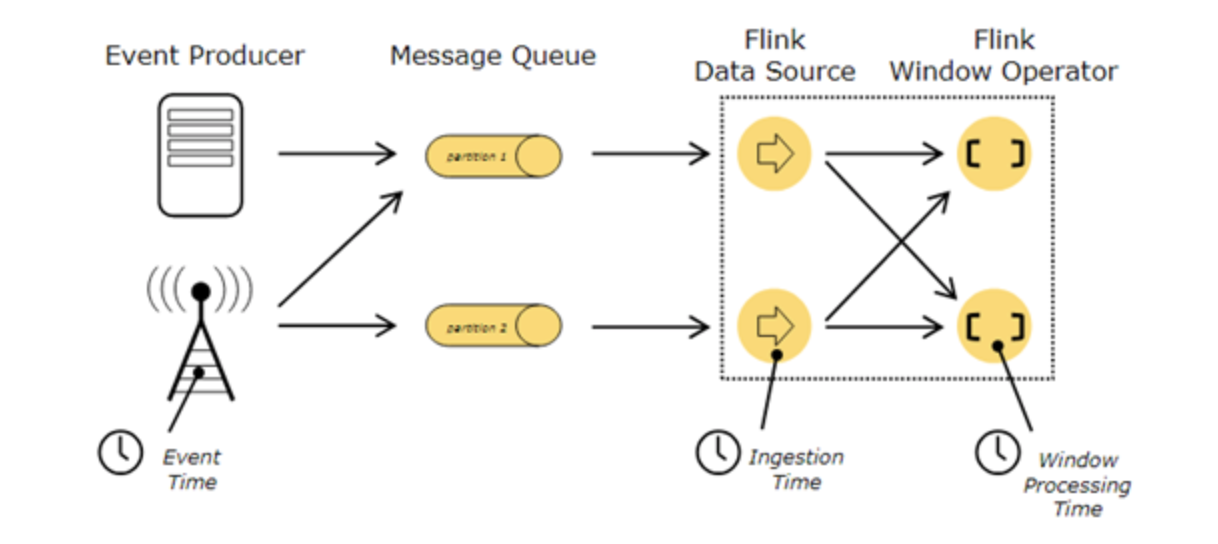
看图可知,一共有3种时间,数据从产生-> 进入队列 -> 进入Flink -> 进入窗口 -> ...
- Event Time: 就是事件产生的时间,比如订单的生成时间,运单的创建时间。
- Ingestion Time: 就是事件进入到Flink的时间。
- processing Time: 事件被处理的时的当前系统的时间
既然如此,那我们就需要考虑一个问题,当我们针对业务进行统计的时候,例如统计1个小时内,一共产生了多少条订单,那我们应该使用什么样的时间呢?
如果消息都是有序的,那么我们可能什么都不需要做,但是真实情况并不是这样的,考虑到消息在很可能因为网络或者其他原因,导致无序、延迟、甚至丢失,那么我们就需要根据不同情况,做不同的调整,丢失的话,我们可能在程序里面不太好处理,但是无序、以及一定程度的延时,我们是可以通过Flink提供的一些方法,来进行挽救的。
1.3.1 当窗口数据有序
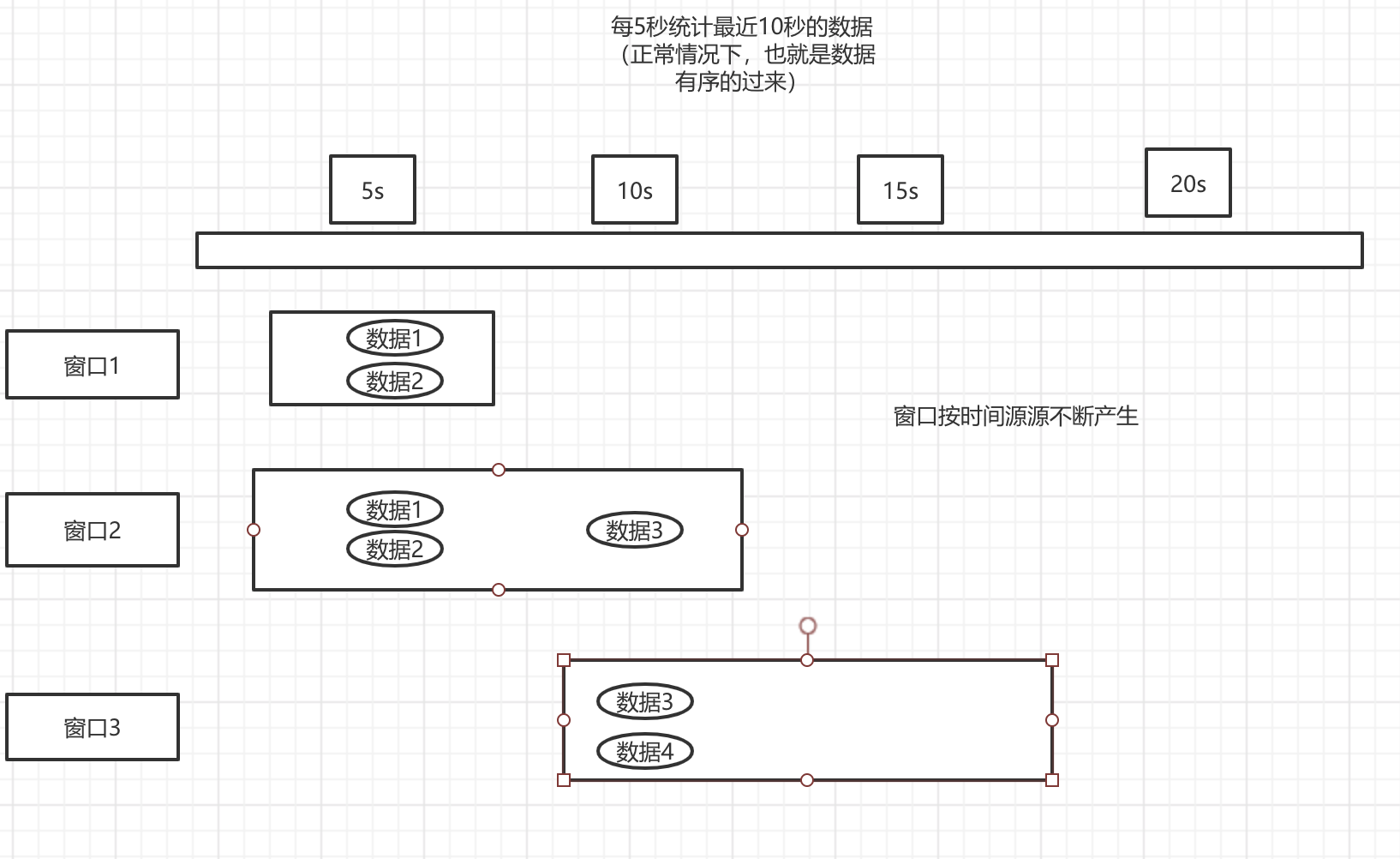
我们将之前的代码改造一下,模拟发送数据,先看一下图,感受一下。
import org.apache.commons.lang.time.FastDateFormat;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.util.concurrent.TimeUnit;
public class WindowDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//使用自定义source 来模拟产生数据
DataStreamSource<String> lc = env.addSource(new SourceFunction<String>() {
FastDateFormat dateFormat = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void run(SourceContext<String> out) throws Exception {
// 我们控制一下 秒数是10的倍数的时候 进行发送
String currTime = String.valueOf(System.currentTimeMillis());
while (Integer.valueOf(currTime.substring(currTime.length() - 4)) > 100) {
currTime = String.valueOf(System.currentTimeMillis());
continue;
}
System.out.println("开始发送事件的时间:" + dateFormat.format(System.currentTimeMillis()));
//第一个窗口 生成2条数据
out.collect("hadoop," + dateFormat.format(System.currentTimeMillis()));
out.collect("hadoop," + dateFormat.format(System.currentTimeMillis()));
// 睡眠 5秒发送一个 第二个窗口
TimeUnit.SECONDS.sleep(5);
out.collect("hadoop," + dateFormat.format(System.currentTimeMillis()));
// 睡眠7秒 在发送一个 第三个窗口
TimeUnit.SECONDS.sleep(7);
out.collect("hadoop," + dateFormat.format(System.currentTimeMillis()));
TimeUnit.SECONDS.sleep(300);
}
@Override
public void cancel() {
}
});
lc.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = value.split(",");
for (String s : split) {
collector.collect(Tuple2.of(s, 1));
}
}
}).keyBy(0).timeWindow(Time.seconds(10), Time.seconds(5))
.process(new ProcessWindownImpl())
.print().setParallelism(1);
env.execute("WindowDemo");
}
/**
* IN, OUT, KEY, W
* IN:输入的数据类型
* OUT:输出的数据类型
* Key:key的数据类型(在Flink里面,String用Tuple表示)
* W:Window的数据类型
*/
public static class ProcessWindownImpl extends ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple, TimeWindow> {
//这是一个线程安全的时间格式化器
FastDateFormat format = FastDateFormat.getInstance("HH:mm:ss");
/**
* 当一个window触发计算的时候会调用这个方法
*
* @param tuple key
* @param context operator的上下文
* @param elements 指定window的所有元素
* @param out 输出
*/
@Override
public void process(Tuple tuple, Context context, Iterable<Tuple2<String, Integer>> elements,
Collector<Tuple2<String, Integer>> out) {
// System.out.println("当前时间:" + format.format(System.currentTimeMillis()));
// System.out.println("Window的处理时间:" + format.format(context.currentProcessingTime()));
// System.out.println("Window的开始时间:" + format.format(context.window().getStart()));
// System.out.println("Window的结束时间:" + format.format(context.window().getEnd()));
int sum = 0;
for (Tuple2<String, Integer> ele : elements) {
sum += 1;
}
// 输出单词出现的次数
out.collect(Tuple2.of(tuple.getField(0), sum));
}
}
}
运行结果 可以看到 结果和我们的图,是是一致的
开始发送事件的时间:10:57:50
//第一个窗口
(hadoop,2)
(10:57:50,2)
(10:57:55,1)
//第二个窗口
(hadoop,3)
(10:57:50,2)
//第三个窗口
(hadoop,2)
(10:58:02,1)
(10:57:55,1)
像这种有序的情况,我们什么都不需要做,然后总会有不正常的时候,
1.3.2 当窗口数据无序
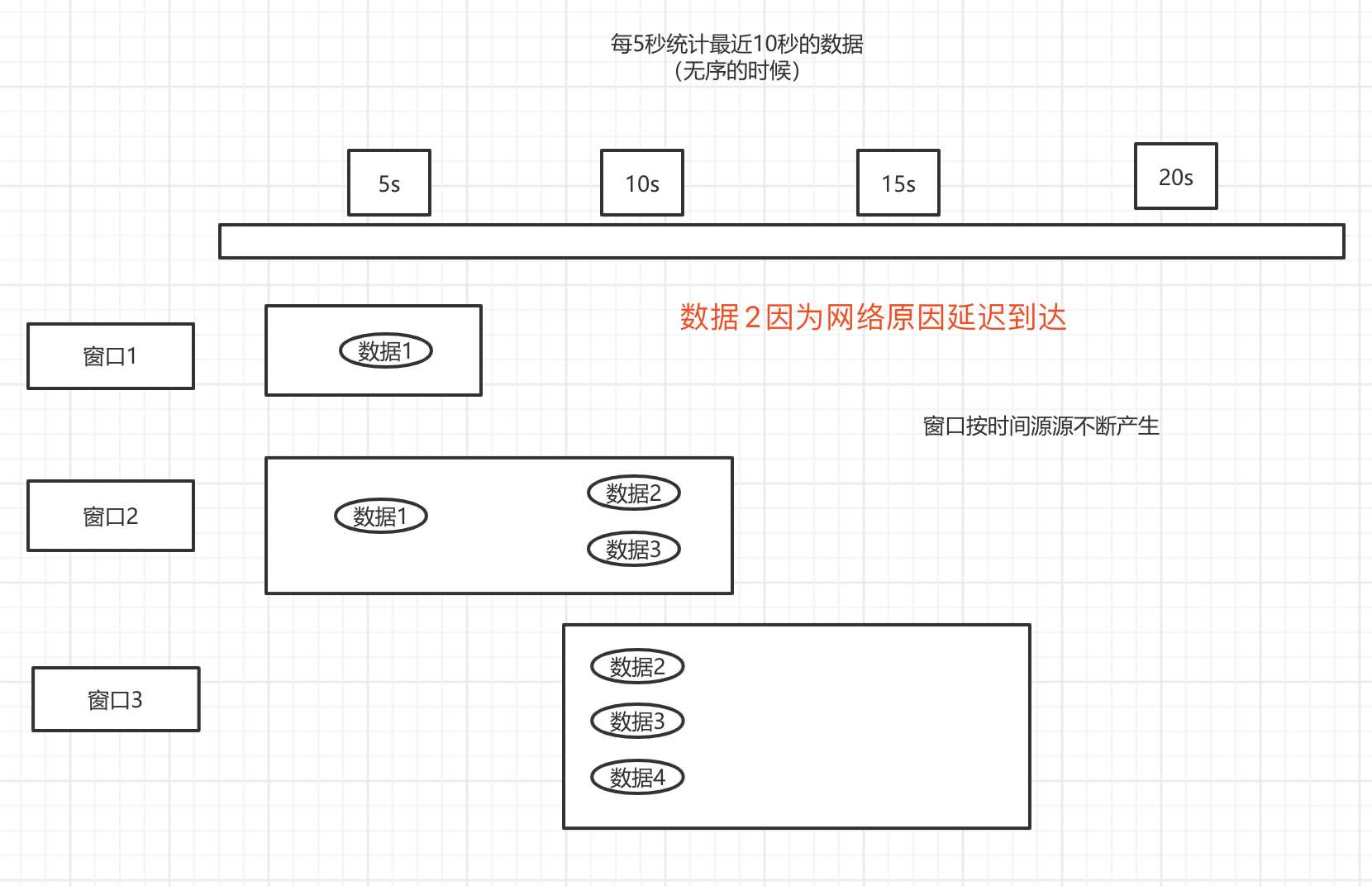
看图
package juejinDemo.window;
import org.apache.commons.lang.time.FastDateFormat;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.util.concurrent.TimeUnit;
/**
* 无序
*/
public class WindowDemo2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//使用自定义source 来模拟产生数据
DataStreamSource<String> lc = env.addSource(new SourceFunction<String>() {
FastDateFormat dateFormat = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void run(SourceContext<String> out) throws Exception {
// 我们控制一下 秒数是10的倍数的时候 进行发送
String currTime = String.valueOf(System.currentTimeMillis());
while (Integer.valueOf(currTime.substring(currTime.length() - 4)) > 100) {
currTime = String.valueOf(System.currentTimeMillis());
continue;
}
System.out.println("开始发送事件的时间:" + dateFormat.format(System.currentTimeMillis()));
//第一个窗口 生成2条数据
out.collect("hadoop," + dateFormat.format(System.currentTimeMillis()));
//这个事件产生了,但是由于网络原因 没有发送出去,这里需要一点想象空间。
String event = "hadoop," + dateFormat.format(System.currentTimeMillis());
// 睡眠 5秒发送一个 第二个窗口
TimeUnit.SECONDS.sleep(5);
out.collect("hadoop," + dateFormat.format(System.currentTimeMillis()));
//在第二个窗口的这个时候 之前的数据终于发送出去了
out.collect(event);
// 睡眠7秒 在发送一个 第三个窗口
TimeUnit.SECONDS.sleep(7);
out.collect("hadoop," + dateFormat.format(System.currentTimeMillis()));
TimeUnit.SECONDS.sleep(300);
}
@Override
public void cancel() {
}
});
lc.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = value.split(",");
for (String s : split) {
collector.collect(Tuple2.of(s, 1));
}
}
}).keyBy(0).timeWindow(Time.seconds(10), Time.seconds(5))
.process(new ProcessWindownImpl())
.print().setParallelism(1);
env.execute("WindowDemo2");
}
/**
* IN, OUT, KEY, W
* IN:输入的数据类型
* OUT:输出的数据类型
* Key:key的数据类型(在Flink里面,String用Tuple表示)
* W:Window的数据类型
*/
public static class ProcessWindownImpl extends ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple, TimeWindow> {
//这是一个线程安全的时间格式化器
FastDateFormat format = FastDateFormat.getInstance("HH:mm:ss");
/**
* 当一个window触发计算的时候会调用这个方法
*
* @param tuple key
* @param context operator的上下文
* @param elements 指定window的所有元素
* @param out 输出
*/
@Override
public void process(Tuple tuple, Context context, Iterable<Tuple2<String, Integer>> elements,
Collector<Tuple2<String, Integer>> out) {
// System.out.println("当前时间:" + format.format(System.currentTimeMillis()));
// System.out.println("Window的处理时间:" + format.format(context.currentProcessingTime()));
// System.out.println("Window的开始时间:" + format.format(context.window().getStart()));
// System.out.println("Window的结束时间:" + format.format(context.window().getEnd()));
int sum = 0;
for (Tuple2<String, Integer> ele : elements) {
sum += 1;
}
// 输出单词出现的次数
out.collect(Tuple2.of(tuple.getField(0), sum));
}
}
}
结果(由于输出的问题,有时候会没有我下面这样子,这么整齐,其实我的也没有这么一眼就能看出效果,我排列了一下),可以看到 数据的结果和图片显示一致。
开始发送事件的时间:11:17:30
//窗口1
(hadoop,1)
(11:17:30,1)
//窗口2
(hadoop,3)
(11:17:35,1)
(11:17:30,2)
//窗口3
(hadoop,3)
(11:17:42,1)
(11:17:30,1)
(11:17:35,1)
可以看到,这个时候数据就已经乱了,第一个窗口的数据由于延迟到达,导致第3个窗口的数据多了一条,这个时候做的统计肯定是不准确的。
1.3.3 使用Event Time 处理无序
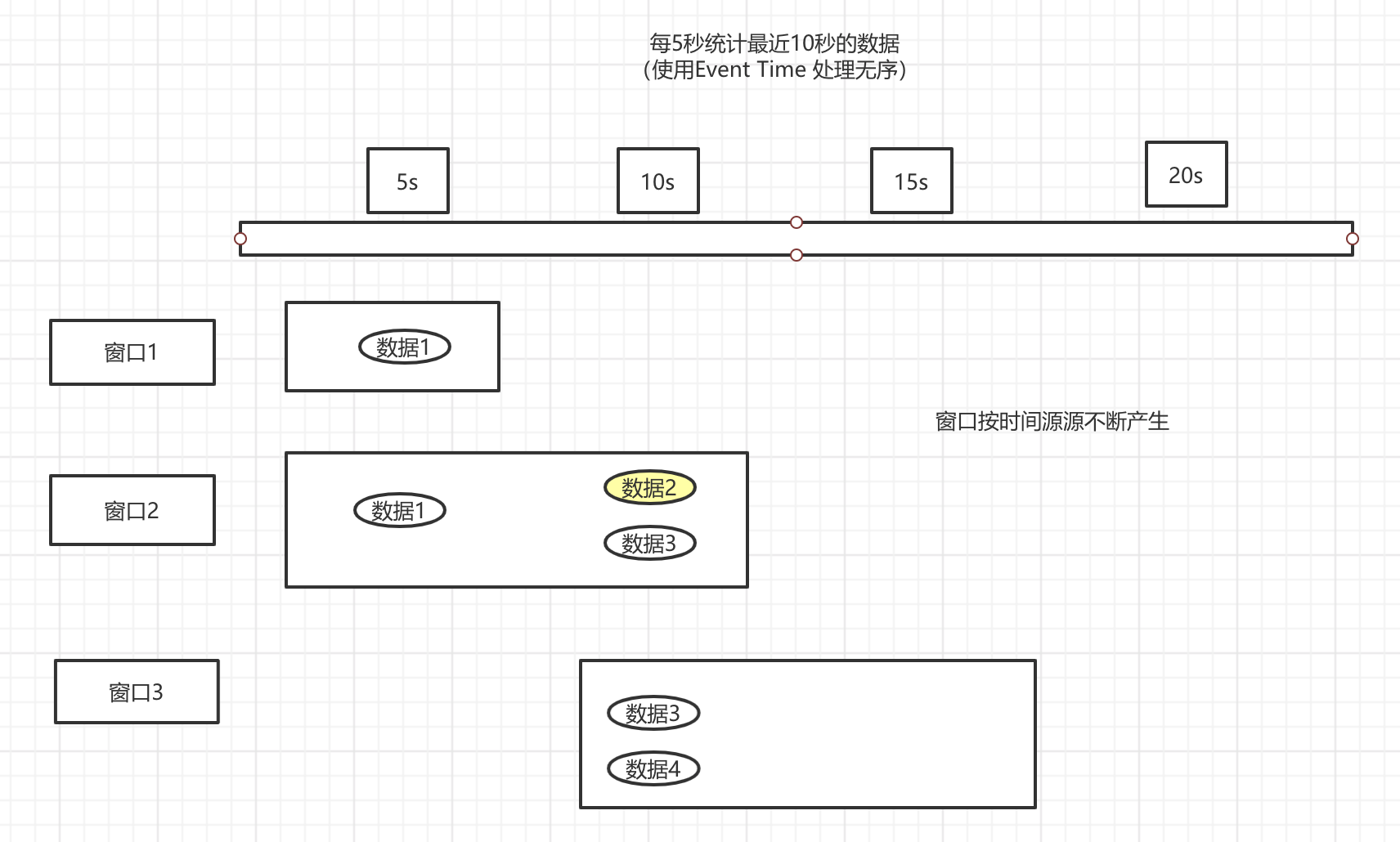
原理就是根据事件的时间,与窗口的时间进行判断,判断是否属于这个窗口。看图
import org.apache.commons.lang.time.FastDateFormat;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import javax.annotation.Nullable;
import java.util.concurrent.TimeUnit;
/**
* 处理无序
*/
public class WindowDemo3 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.设置时间类型
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//使用自定义source 来模拟产生数据
DataStreamSource<String> lc = env.addSource(new SourceFunctionImpl());
lc.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] split = value.split(",");
//这里我们将时间放进去
if (split != null) {
collector.collect(Tuple2.of(split[0], Long.valueOf(split[1])));
}
}
}).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarksImpl()).keyBy(0)
.timeWindow(Time.seconds(10), Time.seconds(5))
.process(new ProcessWindownImpl())
.print().setParallelism(1);
env.execute("WindowDemo3");
}
/**
* IN, OUT, KEY, W
* IN:输入的数据类型
* OUT:输出的数据类型
* Key:key的数据类型(在Flink里面,String用Tuple表示)
* W:Window的数据类型
*/
public static class ProcessWindownImpl extends ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Integer>, Tuple, TimeWindow> {
//这是一个线程安全的时间格式化器
FastDateFormat format = FastDateFormat.getInstance("HH:mm:ss");
/**
* 当一个window触发计算的时候会调用这个方法
*
* @param tuple key
* @param context operator的上下文
* @param elements 指定window的所有元素
* @param out 输出
*/
@Override
public void process(Tuple tuple, Context context, Iterable<Tuple2<String, Long>> elements,
Collector<Tuple2<String, Integer>> out) {
// System.out.println("当前时间:" + format.format(System.currentTimeMillis()));
// System.out.println("Window的处理时间:" + format.format(context.currentProcessingTime()));
// System.out.println("Window的开始时间:" + format.format(context.window().getStart()));
// System.out.println("Window的结束时间:" + format.format(context.window().getEnd()));
int sum = 0;
for (Tuple2<String, Long> ele : elements) {
sum += 1;
}
// 输出单词出现的次数
out.collect(Tuple2.of(tuple.getField(0), sum));
}
}
//自定义的source
public static class SourceFunctionImpl implements SourceFunction<String> {
FastDateFormat dateFormat = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void run(SourceContext<String> out) throws Exception {
// 我们控制一下 秒数是10的倍数的时候 进行发送
String currTime = String.valueOf(System.currentTimeMillis());
while (Integer.valueOf(currTime.substring(currTime.length() - 4)) > 100) {
currTime = String.valueOf(System.currentTimeMillis());
continue;
}
System.out.println("开始发送事件的时间:" + dateFormat.format(System.currentTimeMillis()));
//第一个窗口 生成2条数据
out.collect("hadoop," + System.currentTimeMillis());
//这个事件产生了,但是由于网络原因 没有发送出去,这里需要一点想象空间。
String event = "hadoop," + System.currentTimeMillis();
//为了更好的看到效果 设置长一点
// 睡眠 7秒发送一个 第二个窗口
TimeUnit.SECONDS.sleep(7);
out.collect("hadoop," + System.currentTimeMillis());
//在第二个窗口的这个时候 之前的数据终于发送出去了
out.collect(event);
// 睡眠7秒 在发送一个 第三个窗口
TimeUnit.SECONDS.sleep(7);
out.collect("hadoop," + System.currentTimeMillis());
TimeUnit.SECONDS.sleep(300);
}
@Override
public void cancel() {
}
}
/**
* 泛形是输入的数据类型
*
*/
public static class AssignerWithPeriodicWatermarksImpl implements AssignerWithPeriodicWatermarks<Tuple2<String,Long>> {
//水位 后面再说
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(System.currentTimeMillis());
}
//从event 里面获取事件事件
@Override
public long extractTimestamp(Tuple2<String, Long> element, long previousElementTimestamp) {
return element.f1;
}
}
}
结果,可以看到,第三个窗口的数据,正常了,但是第一个窗口的数据,由于延迟,根本没有进去,导致计算不准确。
(hadoop,1)
(hadoop,3)
(hadoop,2)
2.1 Watermark
2.1.1 使用WaterMark机制解决无序
其实就是让这个窗口再等一等,就好像出去参加旅游团一样,虽然约定了9点出发,但是总有人会迟到,那么就会等一等,等待这些迟到的人到达,所以数据的迟到,我们也可以等一下,在这个迟到的范围内,只要数据到达,那么数据就可以被收集到。
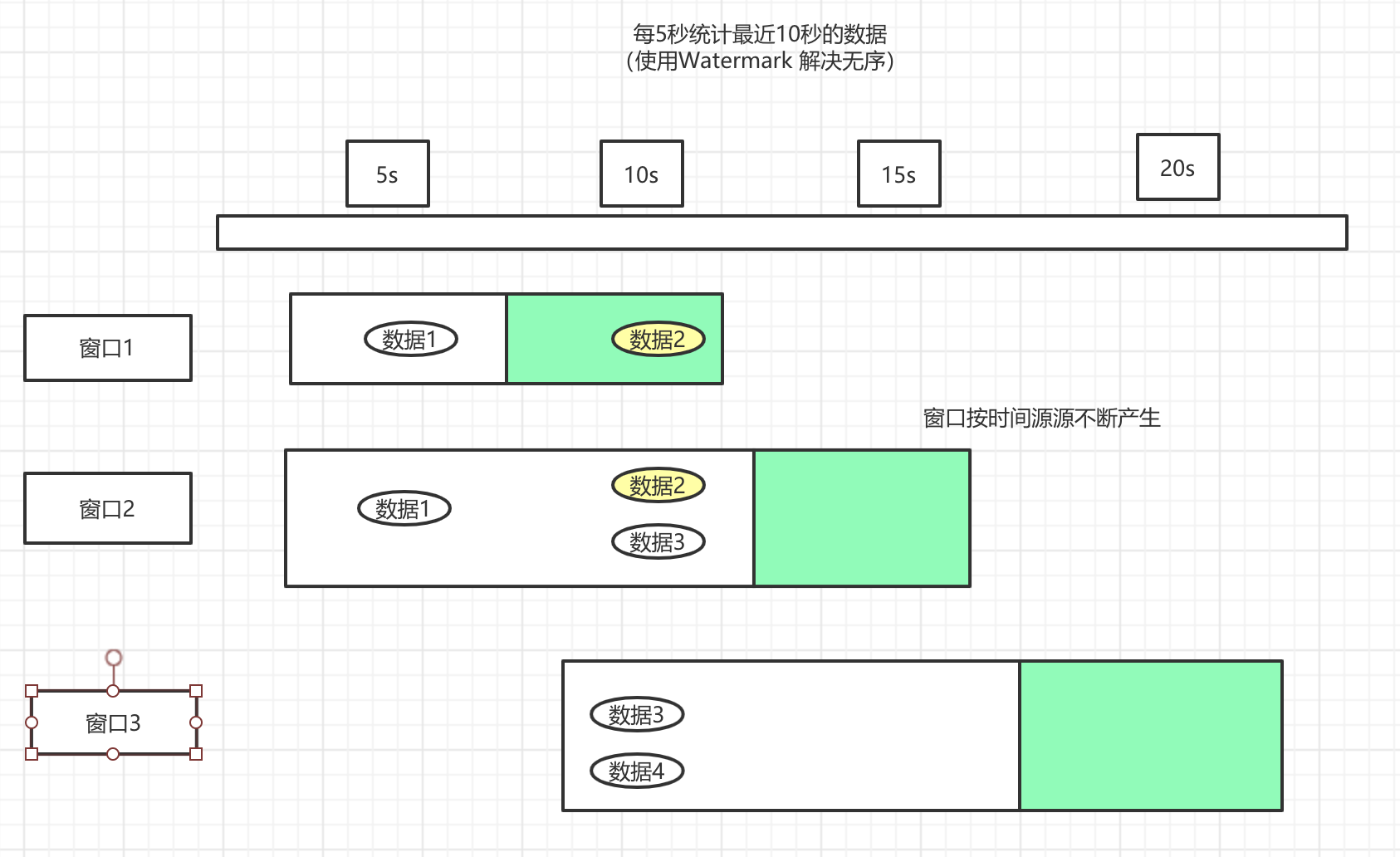
/**
* watermark 解决无序
*/
public class WindowDemo4 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.设置时间类型
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//使用自定义source 来模拟产生数据
DataStreamSource<String> lc = env.addSource(new SourceFunctionImpl());
lc.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] split = value.split(",");
//这里我们将时间放进去
if (split != null) {
collector.collect(Tuple2.of(split[0], Long.valueOf(split[1])));
}
}
}).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarksImpl()).keyBy(0)
.timeWindow(Time.seconds(10), Time.seconds(5))
.process(new ProcessWindownImpl())
.print().setParallelism(1);
env.execute("WindowDemo4");
}
/**
* IN, OUT, KEY, W
* IN:输入的数据类型
* OUT:输出的数据类型
* Key:key的数据类型(在Flink里面,String用Tuple表示)
* W:Window的数据类型
*/
public static class ProcessWindownImpl extends ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Integer>, Tuple, TimeWindow> {
//这是一个线程安全的时间格式化器
FastDateFormat format = FastDateFormat.getInstance("HH:mm:ss");
/**
* 当一个window触发计算的时候会调用这个方法
*
* @param tuple key
* @param context operator的上下文
* @param elements 指定window的所有元素
* @param out 输出
*/
@Override
public void process(Tuple tuple, Context context, Iterable<Tuple2<String, Long>> elements,
Collector<Tuple2<String, Integer>> out) {
// System.out.println("当前时间:" + format.format(System.currentTimeMillis()));
// System.out.println("Window的处理时间:" + format.format(context.currentProcessingTime()));
// System.out.println("Window的开始时间:" + format.format(context.window().getStart()));
// System.out.println("Window的结束时间:" + format.format(context.window().getEnd()));
int sum = 0;
for (Tuple2<String, Long> ele : elements) {
sum += 1;
}
// 输出单词出现的次数
out.collect(Tuple2.of(tuple.getField(0), sum));
}
}
//自定义的source
public static class SourceFunctionImpl implements SourceFunction<String> {
FastDateFormat dateFormat = FastDateFormat.getInstance("HH:mm:ss");
@Override
public void run(SourceContext<String> out) throws Exception {
// 我们控制一下 秒数是10的倍数的时候 进行发送
String currTime = String.valueOf(System.currentTimeMillis());
while (Integer.valueOf(currTime.substring(currTime.length() - 4)) > 100) {
currTime = String.valueOf(System.currentTimeMillis());
continue;
}
System.out.println("开始发送事件的时间:" + dateFormat.format(System.currentTimeMillis()));
//第一个窗口 生成2条数据
out.collect("hadoop," + System.currentTimeMillis());
//这个事件产生了,但是由于网络原因 没有发送出去,这里需要一点想象空间。
String event = "hadoop," + System.currentTimeMillis();
//为了更好的看到效果 设置长一点
// 睡眠 7秒发送一个 第二个窗口
TimeUnit.SECONDS.sleep(7);
out.collect("hadoop," + System.currentTimeMillis());
//在第二个窗口的这个时候 之前的数据终于发送出去了
out.collect(event);
// 睡眠7秒 在发送一个 第三个窗口
TimeUnit.SECONDS.sleep(7);
out.collect("hadoop," + System.currentTimeMillis());
TimeUnit.SECONDS.sleep(300);
}
@Override
public void cancel() {
}
}
/**
* 泛形是输入的数据类型
*/
public static class AssignerWithPeriodicWatermarksImpl implements AssignerWithPeriodicWatermarks<Tuple2<String, Long>> {
//我们这是水位的时间减少 10 秒
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(System.currentTimeMillis() - 10000);
}
//从event 里面获取事件事件
@Override
public long extractTimestamp(Tuple2<String, Long> element, long previousElementTimestamp) {
return element.f1;
}
}
}
结果,可以看到,数据终于正确了,这里还有一个问题,就如旅游一样,迟到的人,我们等了1个小时还没有到,那么我们只能出发了,那这些迟到太久的人怎么办?,当然是记录下来,然后退钱呗。具体如何记录迟到太久的数据,下面演示。
开始发送事件的时间:12:24:20
(hadoop,2)
(hadoop,3)
(hadoop,2)
2.1.2 WaterMark的定义
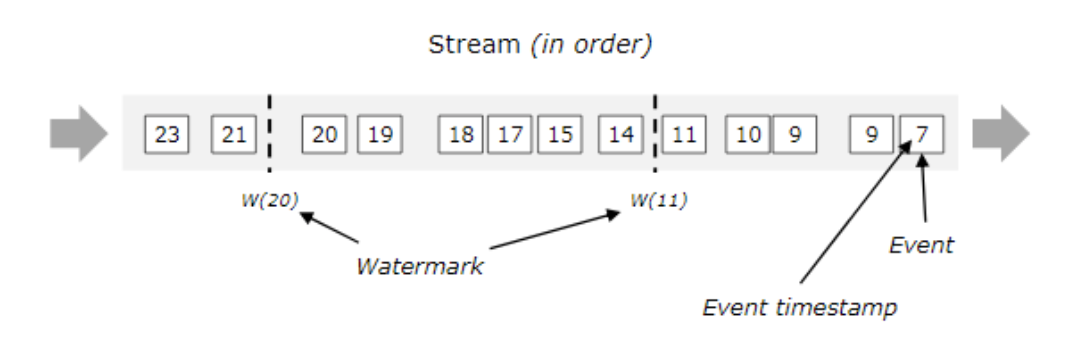
流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的。虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络延迟等原因,导致乱序的产生,特别是使用kafka的话,多个分区的数据无法保证有序。所以在进行window计算的时候,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark,watermark是用于处理乱序事件的。watermark可以翻译为水位线
有序的流的watermarks
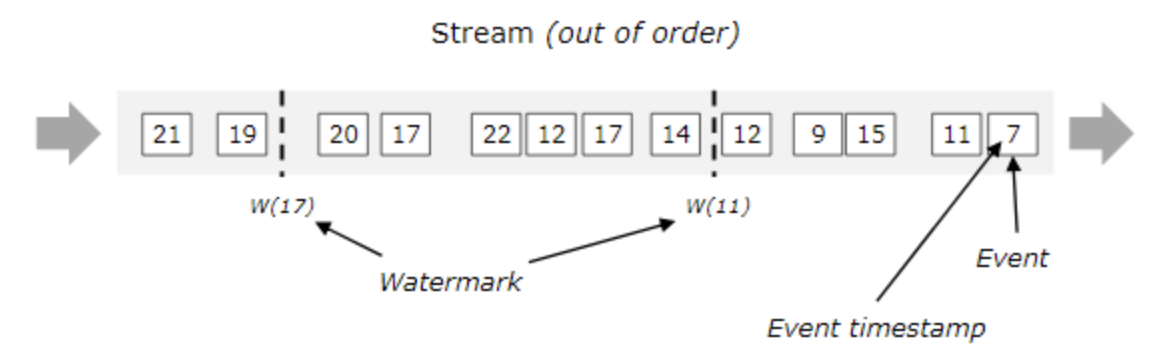
无序的流的watermarks
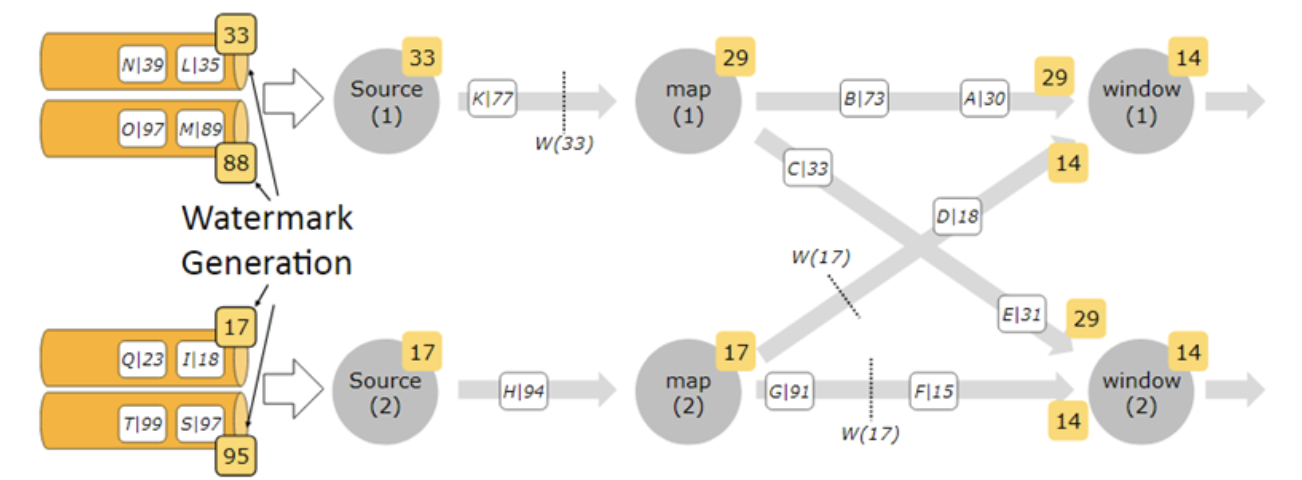
多并行度流的watermarks
简单来讲就是,多个并行度中,取最小的watermark,单并行度中去最大的watermark。
2.1.3 配置waterMark产生的周期
默认是每200毫秒产生一次
env.getConfig().setAutoWatermarkInterval(1000);
2.1.4 窗口的计算与WaterMark的关系
import org.apache.commons.lang.time.FastDateFormat;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import javax.annotation.Nullable;
/**
* watermark 解决无序
*/
public class WindowDemo5 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.设置时间类型
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置水位产生的周期
env.getConfig().setAutoWatermarkInterval(1000);
//使用自定义source 来模拟产生数据
DataStreamSource<String> lc = env.socketTextStream("localhost",8888);
lc.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] split = value.split(",");
//这里我们将时间放进去
if (split != null) {
collector.collect(Tuple2.of(split[0],System.currentTimeMillis()));
}
}
}).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarksImpl()).keyBy(0)
.timeWindow(Time.seconds(5), Time.seconds(5))
.process(new ProcessWindownImpl())
.print().setParallelism(1);
env.execute("WindowDemo5");
}
/**
* IN, OUT, KEY, W
* IN:输入的数据类型
* OUT:输出的数据类型
* Key:key的数据类型(在Flink里面,String用Tuple表示)
* W:Window的数据类型
*/
public static class ProcessWindownImpl extends ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Integer>, Tuple, TimeWindow> {
//这是一个线程安全的时间格式化器
FastDateFormat format = FastDateFormat.getInstance("HH:mm:ss");
/**
* 当一个window触发计算的时候会调用这个方法
*
* @param tuple key
* @param context operator的上下文
* @param elements 指定window的所有元素
* @param out 输出
*/
@Override
public void process(Tuple tuple, Context context, Iterable<Tuple2<String, Long>> elements,
Collector<Tuple2<String, Integer>> out) {
System.out.println("当前时间:" + format.format(System.currentTimeMillis()));
System.out.println("Window的处理时间:" + format.format(context.currentProcessingTime()));
System.out.println("Window的开始时间:" + format.format(context.window().getStart()));
System.out.println("Window的结束时间:" + format.format(context.window().getEnd()));
int sum = 0;
for (Tuple2<String, Long> ele : elements) {
sum += 1;
}
// 输出单词出现的次数
out.collect(Tuple2.of(tuple.getField(0), sum));
}
}
/**
* 泛形是输入的数据类型
*/
public static class AssignerWithPeriodicWatermarksImpl implements AssignerWithPeriodicWatermarks<Tuple2<String, Long>> {
FastDateFormat dateFormat = FastDateFormat.getInstance("HH:mm:ss");;
private long currentMaxEventTime = 0L;
private long maxOutOfOrderness = 10000;
public AssignerWithPeriodicWatermarksImpl() {
}
public AssignerWithPeriodicWatermarksImpl(long maxOutOfOrderness) {
this.maxOutOfOrderness = maxOutOfOrderness;
}
//我们这是水位的时间减少 10 秒
@Nullable
@Override
public Watermark getCurrentWatermark() {
long watermark = System.currentTimeMillis();
System.out.println("水位产生---" + dateFormat.format(watermark));
return new Watermark(watermark - maxOutOfOrderness);
}
//从event 里面获取事件事件 这里需要修改一下,
@Override
public long extractTimestamp(Tuple2<String, Long> element, long previousElementTimestamp) {
long currentElementEventTime = element.f1;
//这里是为了防止乱序的时候,可能中间的数据的时间,会覆盖最新的数据的事件时间
currentMaxEventTime = Math.max(currentMaxEventTime, currentElementEventTime);
return currentElementEventTime;
}
}
}
结果如下,想完全描述清楚,比较麻烦,我这边就简单演示一下,然后直接解释。
为什么说使用Watermark结合EventTime,可以解决窗口统计时的数据的乱序,因为,窗口触发的时需要满足2个条件,
- watermark >= window_end_time(窗口结束时间).
- 在窗口的区间中有数据存在,左闭右开的区间。通过获取事件时间,确保数据属于当前窗口
水位产生---16:59:24
水位产生---16:59:25
当前时间:16:59:25
Window的处理时间:16:59:25
Window的开始时间:16:59:20
Window的结束时间:16:59:25
(hadoop,2)
水位产生---16:59:26
水位产生---16:59:27
水位产生---16:59:28
水位产生---16:59:29
水位产生---16:59:30
水位产生---16:59:31
水位产生---16:59:32
水位产生---16:59:33
水位产生---16:59:34
水位产生---16:59:35
当前时间:16:59:35
Window的处理时间:16:59:35
Window的开始时间:16:59:30
Window的结束时间:16:59:35
(hadoop,2)
水位产生---16:59:36
水位产生---16:59:37
2.1.5 处理迟到太多的数据
之前上面就讲过,对于迟到太久的数据,我们要进行另外的处理,因为窗口不能一直等待。
- 直接丢弃,这个是默认的处理方式,也就是不做任何处理
- allowedLateness 指定允许数据延迟的时间
//这个其实就是 当正常窗口(包含水位)触发之后,如果在配置的时间内,还有数据过来,那么,就会再一次触发一次计算。
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarksImpl(10)).keyBy(0)
.timeWindow(Time.seconds(5), Time.seconds(5))
.allowedLateness(Time.seconds(2))
.process(new ProcessWindownImpl())
.print().setParallelism(1);
- sideOutputLateData 收集迟到的数据
我这里就不跑了,有兴趣可以自己测试一下,收集迟到的数据,在最后对一些结果数据进行修正。
/**
* 收集迟到太久的数据
*/
public class SideOutputLateDataDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.设置时间类型
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置水位产生的周期
env.getConfig().setAutoWatermarkInterval(1000);
// 保存迟到的,会被丢弃的数据
OutputTag<Tuple2<String, Long>> sideOutputLateData =
new OutputTag<Tuple2<String, Long>>("late-date"){};
//使用自定义source 来模拟产生数据
DataStreamSource<String> lc = env.socketTextStream("localhost",8888);
SingleOutputStreamOperator<Tuple2<String, Integer>> result = lc.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] split = value.split(",");
//这里我们将时间放进去
if (split != null) {
collector.collect(Tuple2.of(split[0], System.currentTimeMillis()));
}
}
}).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarksImpl(10)).keyBy(0)
.timeWindow(Time.seconds(5), Time.seconds(5))
// .allowedLateness(Time.seconds(2))
.sideOutputLateData(sideOutputLateData)
.process(new ProcessWindownImpl());
result.print().setParallelism(1);
DataStream<Tuple2<String, Long>> sideOutput = result.getSideOutput(sideOutputLateData);
SingleOutputStreamOperator<Object> map = sideOutput.map(new MapFunction<Tuple2<String, Long>, Object>() {
@Override
public Object map(Tuple2<String, Long> stringLongTuple2) throws Exception {
//这里对迟到太久的数据作相应的操作
return stringLongTuple2;
}
});
map.print();
env.execute("sideOutputLateDataDemo");
}
/**
* IN, OUT, KEY, W
* IN:输入的数据类型
* OUT:输出的数据类型
* Key:key的数据类型(在Flink里面,String用Tuple表示)
* W:Window的数据类型
*/
public static class ProcessWindownImpl extends ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Integer>, Tuple, TimeWindow> {
//这是一个线程安全的时间格式化器
FastDateFormat format = FastDateFormat.getInstance("HH:mm:ss");
/**
* 当一个window触发计算的时候会调用这个方法
*
* @param tuple key
* @param context operator的上下文
* @param elements 指定window的所有元素
* @param out 输出
*/
@Override
public void process(Tuple tuple, Context context, Iterable<Tuple2<String, Long>> elements,
Collector<Tuple2<String, Integer>> out) {
System.out.println("当前时间:" + format.format(System.currentTimeMillis()));
System.out.println("Window的处理时间:" + format.format(context.currentProcessingTime()));
System.out.println("Window的开始时间:" + format.format(context.window().getStart()));
System.out.println("Window的结束时间:" + format.format(context.window().getEnd()));
int sum = 0;
for (Tuple2<String, Long> ele : elements) {
sum += 1;
}
// 输出单词出现的次数
out.collect(Tuple2.of(tuple.getField(0), sum));
}
}
/**
* 泛形是输入的数据类型
*/
public static class AssignerWithPeriodicWatermarksImpl implements AssignerWithPeriodicWatermarks<Tuple2<String, Long>> {
FastDateFormat dateFormat = FastDateFormat.getInstance("HH:mm:ss");;
private long currentMaxEventTime = 0L;
private long maxOutOfOrderness = 10000;
public AssignerWithPeriodicWatermarksImpl() {
}
public AssignerWithPeriodicWatermarksImpl(long maxOutOfOrderness) {
this.maxOutOfOrderness = maxOutOfOrderness;
}
//我们这是水位的时间减少 10 秒
@Nullable
@Override
public Watermark getCurrentWatermark() {
long watermark = System.currentTimeMillis() - maxOutOfOrderness;
System.out.println("水位产生---" + dateFormat.format(watermark));
return new Watermark(watermark);
}
//从event 里面获取事件事件 这里需要修改一下,
@Override
public long extractTimestamp(Tuple2<String, Long> element, long previousElementTimestamp) {
long currentElementEventTime = element.f1;
//这里是为了防止乱序的时候,可能中间的数据的时间,会覆盖最新的数据的事件时间
currentMaxEventTime = Math.max(currentMaxEventTime, currentElementEventTime);
return currentElementEventTime;
}
}
}
最后
关于Event Time、Watermark的使用的就介绍玩了,之前还打算把窗口也丢进来,然后偷个懒就放弃了,下一篇Flink之窗口的使用。
