

前言
继上一章flink之基础使用之后,这章主要是讲flink关于在程序运行时,如何保证程序的一些信息的保存,以及在出错或者异常之后,如何进行恢复。例如消费kafka的时候,需要记录消费到哪个个位置,然后重启之后继续从之前的位置消费,保证exactly-once语义。又或者一个窗口计算了很多的数据之后,突然挂掉了,再次重启的时候,能保证之前的统计的数据依然存在。
1.state
1.1 stste 官网描述
有状态的函数和运算符在处理单个元素/事件的过程中存储数据,从而使状态成为任何类型的更精细操作的关键构建块。
例如:
- 当应用程序搜索某些事件模式时,状态将存储到目前为止遇到的事件序列。
- 在每分钟/小时/天汇总事件时,状态将保留待处理的汇总。
- 在数据点流上训练机器学习模型时,状态会保留模型参数的当前版本。
- 当需要管理历史数据时,该状态允许有效访问过去发生的事件。
1.2 state 的类型
一般指一个具体的task/operator的状态。State可以被记录存储,在失败的情况下可以恢复数据。
1.2.1 Keyed State
简单来讲,经过了shuffle过程的就是Keyed State,在代码中的体现就是使用了keyBy之后。
1.2.2 Operator State,
没有shuffle的就是Operator State。
托管状态:由Flink框架管理的状态,我们通常使用的就是这种。
原始状态:由用户自行管理状态具体的数据结构,框架在做checkpoint的时候,使用byte[]来读写状态内容,对其内部数据结构一无所知。通常在DataStream上的状态推荐使用托管的状态,当实现一个用户自定义的operator时,会使用到原始状态。但是一般不常用。
1.2.3 state 示例图 及 代码演示
单词计数演示
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> localhost = environment.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = localhost.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String s : value.split(",")) {
out.collect(new Tuple2<>(s, 1));
}
}
}).keyBy(0).sum(1);
sum.print();
environment.execute("WordCount");
}
}
第一次输入
flink,hadoop
程序打印结果
13> (flink,1)
15> (hadoop,1)
第二次输入
flink,hive,hadoop
程序打印结果
2> (hive,1)
13> (flink,2)
15> (hadoop,2)
结论:可以看到,单词数量进行了累加,如果使用过spark就知道,一样的逻辑,在spark是不会出现累加的。
1.3 Keyed State Demo
1.3.1 ValueState
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 同一个key,每接受3条数据,我们就打印输出总和
*/
public class ValueStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, Integer>> source =
env.fromElements(Tuple2.of("A", 2), Tuple2.of("A", 3), Tuple2.of("A", 4),
Tuple2.of("B", 5), Tuple2.of("B", 7), Tuple2.of("B", 9), Tuple2.of("C", 1));
source.keyBy(0)
.flatMap(new ValueStateSum())
.print();
env.execute("ValueStateDemo");
}
}
class ValueStateSum extends RichFlatMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>> {
//其实这就是一个属性
// 来保存你想要保存进去的数据
//我们这里第一个存出现次数 然后存总数 这里的泛形可以使用其他类型
private ValueState<Tuple2<Integer, Integer>> valueStateSun;
/**
* 初始化描述器
* 然后每次从运行环境中获取
*/
@Override
public void open(Configuration parameters) throws Exception {
// 注册状态
ValueStateDescriptor<Tuple2<Integer, Integer>> descriptor = new ValueStateDescriptor<Tuple2<Integer, Integer>>(
"valueStateName", // 状态的名字
Types.TUPLE(Types.STRING, Types.INT)); // 指定状态存储的数据类型
valueStateSun = getRuntimeContext().getState(descriptor);
}
@Override
public void flatMap(Tuple2<String, Integer> element,
Collector<Tuple2<String, Integer>> out) throws Exception {
// 拿到当前的状态
Tuple2<Integer, Integer> currentState = valueStateSun.value();
// 第一次可能里面是空的
if (currentState == null) {
currentState = Tuple2.of(0, 0);
}
// 更新状态中的数量
currentState.f0 += 1;
// 更新状态中的总值
currentState.f1 += element.f1;
// 更新状态
valueStateSun.update(currentState);
if (currentState.f0 >= 3) {
// 输出总数
out.collect(Tuple2.of(element.f0, currentState.f1));
// 清空状态值
valueStateSun.clear();
}
}
}
结果 可以看到按照要求输出了,所以可以按照需求,做自己的个性化处理,这里C不满足3个 所以没有输出。
3> (B,21)
14> (A,9)
1.3.2 ListState
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.shaded.curator.org.apache.curator.shaded.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Collections;
import java.util.List;
/**
* 同一个key,每接受3条数据,我们就打印输出总和
*/
public class ListStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, Integer>> source =
env.fromElements(Tuple2.of("A", 2), Tuple2.of("A", 3), Tuple2.of("A", 4),
Tuple2.of("B", 5), Tuple2.of("B", 7), Tuple2.of("B", 9), Tuple2.of("C", 1));
source.keyBy(0)
.flatMap(new ListStateSum())
.print();
env.execute("ListStateDemo");
}
}
class ListStateSum extends RichFlatMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>> {
//只存入合计
private ListState<Integer> listState;
/**
* 初始化描述器
* 然后每次从运行环境中获取
*/
@Override
public void open(Configuration parameters) throws Exception {
// 注册状态
ListStateDescriptor<Integer> descriptor = new ListStateDescriptor<Integer>("listState", Integer.class);
listState = getRuntimeContext().getListState(descriptor);
}
@Override
public void flatMap(Tuple2<String, Integer> element,
Collector<Tuple2<String, Integer>> out) throws Exception {
// 拿到当前的状态
Iterable<Integer> integers = listState.get();
// 第一次可能里面是空的
if (integers == null) {
listState.addAll(Collections.EMPTY_LIST);
}
// 插入一个元素
listState.add(element.f1);
//更新了之后 需要再获取一下 并转换为集合
List<Integer> list = Lists.newArrayList(listState.get());
if (list.size() >= 3) {
Integer sum = list.stream().reduce((a, b) -> a + b).get();
// 输出总数
out.collect(Tuple2.of(element.f0, sum));
// 清空状态值
listState.clear();
}
}
}
结果是一样的
14> (A,9)
3> (B,21)
1.3.3 mapState
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.shaded.curator.org.apache.curator.shaded.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.List;
import java.util.UUID;
/**
* 同一个key,每接受3条数据,我们就打印输出总和
*/
public class MapStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, Integer>> source =
env.fromElements(Tuple2.of("A", 2), Tuple2.of("A", 3), Tuple2.of("A", 4),
Tuple2.of("B", 5), Tuple2.of("B", 7), Tuple2.of("B", 9), Tuple2.of("C", 1));
source.keyBy(0)
.flatMap(new MapStateSum())
.print();
env.execute("MapStateDemo");
}
}
class MapStateSum extends RichFlatMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>> {
private MapState<String,Integer> mapState;
/**
* 初始化描述器
* 然后每次从运行环境中获取
*/
@Override
public void open(Configuration parameters) throws Exception {
// 注册状态
MapStateDescriptor<String,Integer> descriptor = new MapStateDescriptor<String, Integer>("mapState", String.class,Integer.class);
mapState = getRuntimeContext().getMapState(descriptor);
}
@Override
public void flatMap(Tuple2<String, Integer> element,
Collector<Tuple2<String, Integer>> out) throws Exception {
//这里key随便给 主要保存value的数据即可 然后进行合计
mapState.put(UUID.randomUUID().toString(),element.f1);
Iterable<Integer> values = mapState.values();
List<Integer> list = Lists.newArrayList(values);
if (list.size() >= 3) {
Integer sum = list.stream().reduce((a, b) -> a + b).get();
// 输出总数
out.collect(Tuple2.of(element.f0, sum));
// 清空状态值
mapState.clear();
}
}
}
结果
3> (B,21)
14> (A,9)
1.3.4 ReducingState
/**
* 对指定key进行统计,每次都进行打印输出
*/
public class ReducingStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, Integer>> source =
env.fromElements(Tuple2.of("A", 2), Tuple2.of("A", 3), Tuple2.of("A", 4),
Tuple2.of("B", 5), Tuple2.of("B", 7), Tuple2.of("B", 9), Tuple2.of("C", 1));
source.keyBy(0)
.flatMap(new ReducingStateSum())
.print();
env.execute("ReducingStateDemo");
}
}
class ReducingStateSum extends RichFlatMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>> {
private ReducingState<Integer> reducingState;
/**
* 初始化描述器
* 然后每次从运行环境中获取
*/
@Override
public void open(Configuration parameters) throws Exception {
// 注册状态
ReducingStateDescriptor<Integer> descriptor = new ReducingStateDescriptor<Integer>("reducingState",
new ReduceFunction<Integer>(){ //这里需要给定一个执行reducing的函数
@Override
public Integer reduce(Integer value1, Integer value2) throws Exception {
return value1 + value2;
}
}, Integer.class);
reducingState = getRuntimeContext().getReducingState(descriptor);
}
@Override
public void flatMap(Tuple2<String, Integer> element,
Collector<Tuple2<String, Integer>> out) throws Exception {
reducingState.add(element.f1);
out.collect(Tuple2.of(element.f0,reducingState.get()));
}
}
运行结果
3> (B,5)
14> (A,2)
3> (B,12)
14> (A,5)
3> (B,21)
14> (A,9)
3> (C,1)
1.3.5 AggregatingState
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.AggregatingState;
import org.apache.flink.api.common.state.AggregatingStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 输出打印每个key的所有元素 并按指定分隔符进行分隔
*/
public class AggregatingStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, Integer>> source =
env.fromElements(Tuple2.of("A", 2), Tuple2.of("A", 3), Tuple2.of("A", 4),
Tuple2.of("B", 5), Tuple2.of("B", 7), Tuple2.of("B", 9), Tuple2.of("C", 1));
source.keyBy(0)
.flatMap(new AggregatingStateSum())
.print().setParallelism(1);
env.execute("AggregatingStateDemo");
}
}
class AggregatingStateSum extends RichFlatMapFunction<Tuple2<String, Integer>, Tuple2<String, String>> {
private AggregatingState<Integer, String> aggregatingState;
/**
* 初始化描述器
* 然后每次从运行环境中获取
*/
@Override
public void open(Configuration parameters) throws Exception {
// 注册状态
/* 构造函数 AggregatingStateDescriptor( String name,
AggregateFunction<IN, ACC, OUT> aggFunction,
Class<ACC> stateType)*/
AggregatingStateDescriptor<Integer, String, String> descriptor = new AggregatingStateDescriptor<Integer, String, String>("AggregatingState",
new AggregateFunction<Integer, String, String>() {
//初始化
@Override
public String createAccumulator() {
return "";
}
@Override
public String add(Integer value, String accumulator) {
return accumulator + value + ",";
}
//获取结果
@Override
public String getResult(String accumulator) {
return accumulator;
}
//用于将其他的计算结果进行合并
@Override
public String merge(String a, String b) {
return a + b;
}
}, String.class);
aggregatingState = getRuntimeContext().getAggregatingState(descriptor);
}
@Override
public void flatMap(Tuple2<String, Integer> element,
Collector<Tuple2<String, String>> out) throws Exception {
aggregatingState.add(element.f1);
String str = aggregatingState.get();
//去掉最后的 , 号
str = "list : " + str.substring(0, str.length() - 1) + " end";
out.collect(Tuple2.of(element.f0, str));
}
}
1.3.6 FoldingState (1.4 已弃用)
官网原话: 注意FlinkingState和FoldingStateDescriptor在Flink 1.4中已弃用,以后将完全删除。 请改用AggregatingState和AggregatingStateDescriptor。
1.4 Operator State Demo
1.4.1 ListState
这个直接就是官网的demo 直接复制 然后修改了一下
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.util.ArrayList;
import java.util.List;
/**
* 每2条数据 打印输出一次一次统计
*/
public class OperatorStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, Integer>> dataStreamSource =
env.fromElements(Tuple2.of("A", 2), Tuple2.of("A", 3),
Tuple2.of("B", 5), Tuple2.of("B", 7), Tuple2.of("C", 1));
dataStreamSource
.addSink(new BufferingSink(2)).setParallelism(1);
env.execute("OperatorStateDemo");
}
}
class BufferingSink
implements SinkFunction<Tuple2<String, Integer>>,
CheckpointedFunction {
//阈值
private final int threshold;
private transient ListState<Tuple2<String, Integer>> checkpointedState;
//缓存
private List<Tuple2<String, Integer>> bufferedElements;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
//每一个元素都会调用这个方法
@Override
public void invoke(Tuple2<String, Integer> value, Context contex) throws Exception {
//放入缓存
bufferedElements.add(value);
//判断是否大于阈值
if (bufferedElements.size() == threshold) {
//统计总数
System.out.println(bufferedElements.stream().reduce((a, b) -> Tuple2.of(value.f0,a.f1 + b.f1)).get());
//清除缓存
bufferedElements.clear();
}
}
//快照 也就是对buff里面的数据进行保存
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkpointedState.clear();
for (Tuple2<String, Integer> element : bufferedElements) {
checkpointedState.add(element);
}
}
//初始化或者恢复这个state
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<String, Integer>> descriptor =
new ListStateDescriptor<>(
"buffered-elements",
TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {
}));
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
if (context.isRestored()) {
for (Tuple2<String, Integer> element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}
结果 ,可以看到key为C的没有输出
(A,5)
(B,12)
1.5 State backend
State backend就是指state的数据存储在什么地方,目前Flink支持以下3中
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
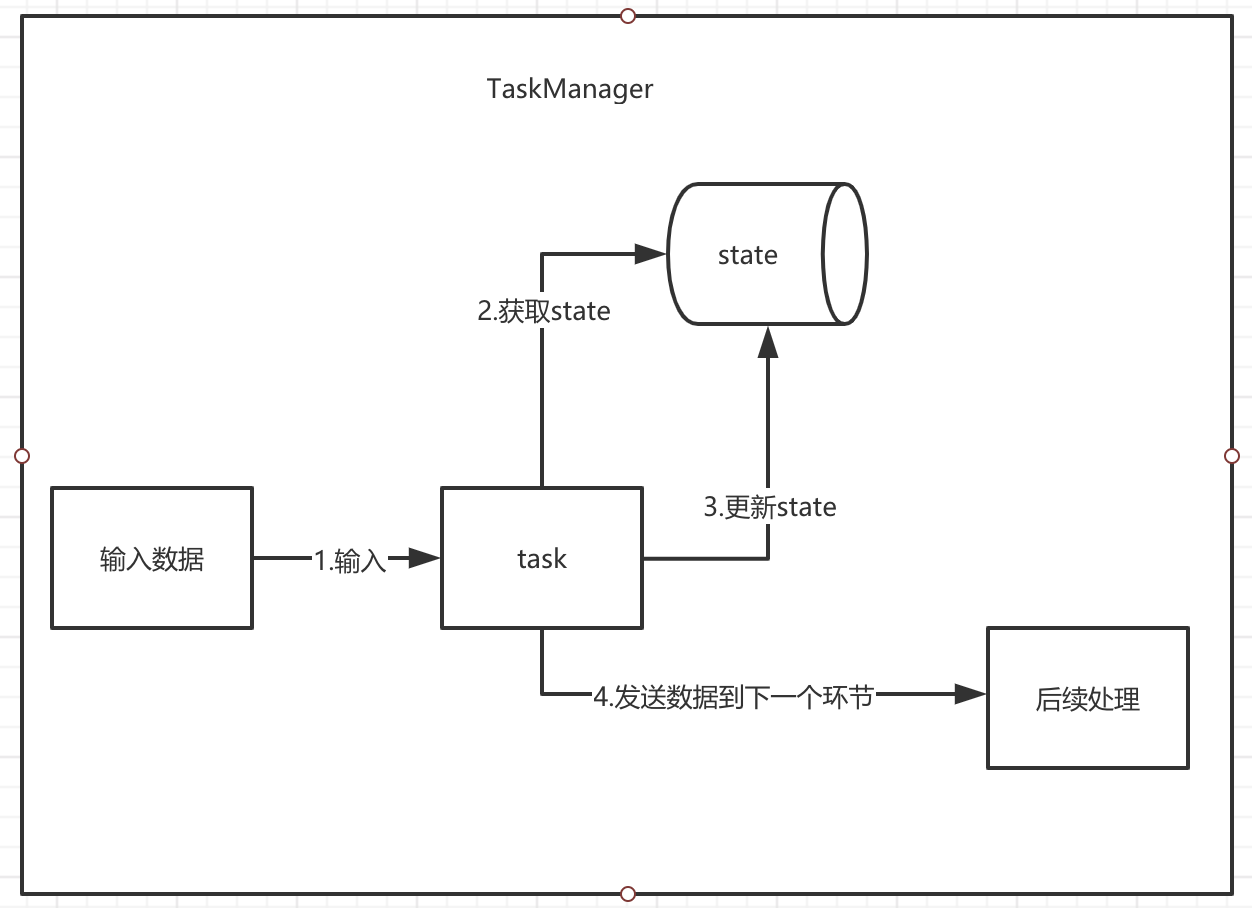
1.5.1 MemoryStateBackend
默认情况下,state的数据在TaskManager的堆中,当需要出发checkpoint的时候,会将数据保存到jobManager的堆内存中。
既然基于内存,意味着快,保存的数据量就不宜太大,并且数据可能会丢失。一般用于开发测试时。
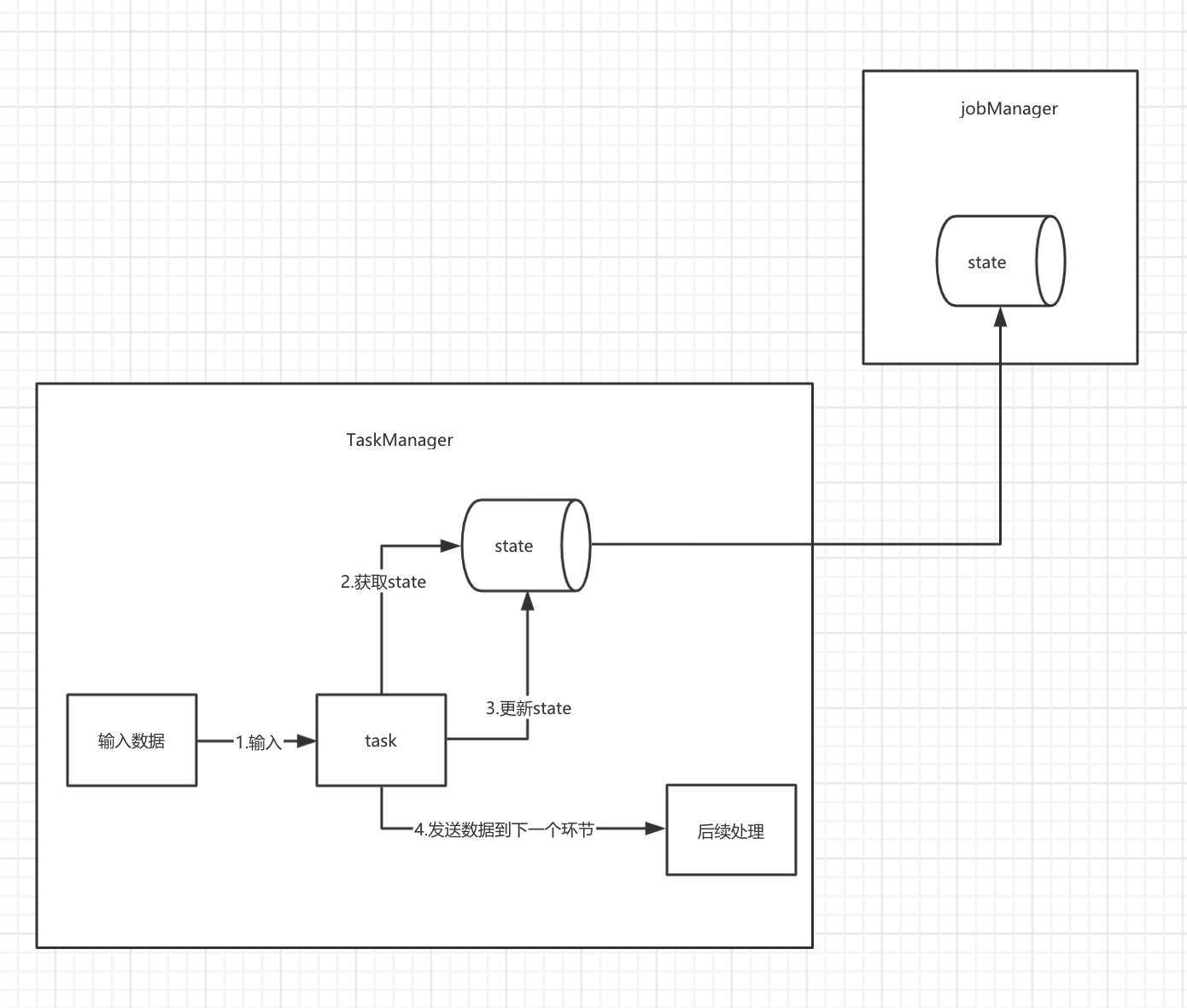
1.5.2 FsStateBackend
state的数据在TaskManager的堆中,当需要出发checkpoint的时候,会将数据保存到HDFS中。
既然保存到hdfs上面,那么数据不会丢失,但是状态大小受TaskManager内存限制(默认支持5M)。
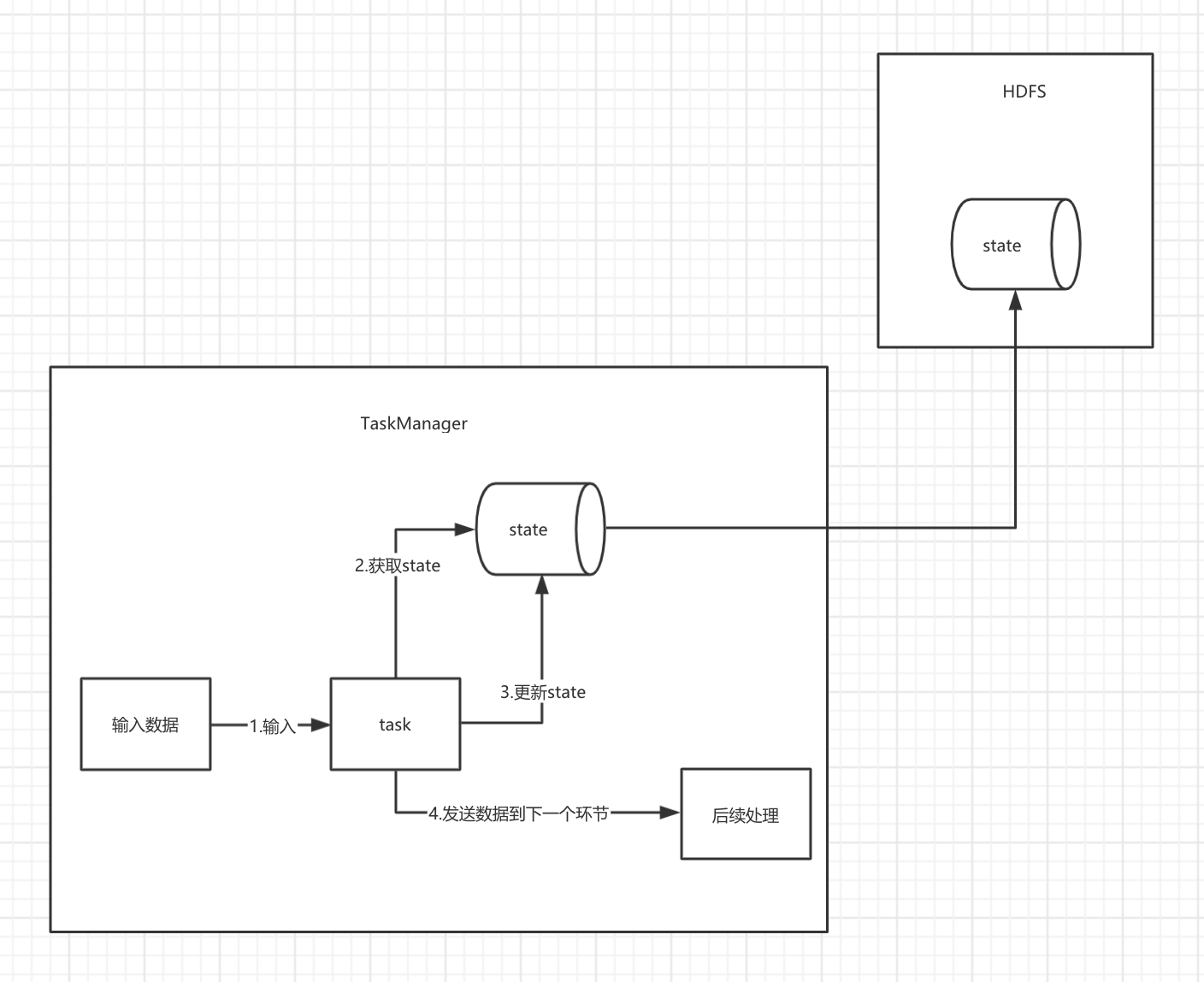
1.5.3 RocksDBStateBackend
有兴趣看去看一下rocksDB中文网。
状态信息存储在 RocksDB 数据库 (key-value 的数据存储服务), 最终保存在本地文件中 checkpoint 的时候将状态保存到指定的文件中 (HDFS 等文件系统)
可以存大量数据,可以保证数据不丢失,公司一般使用这种方式。
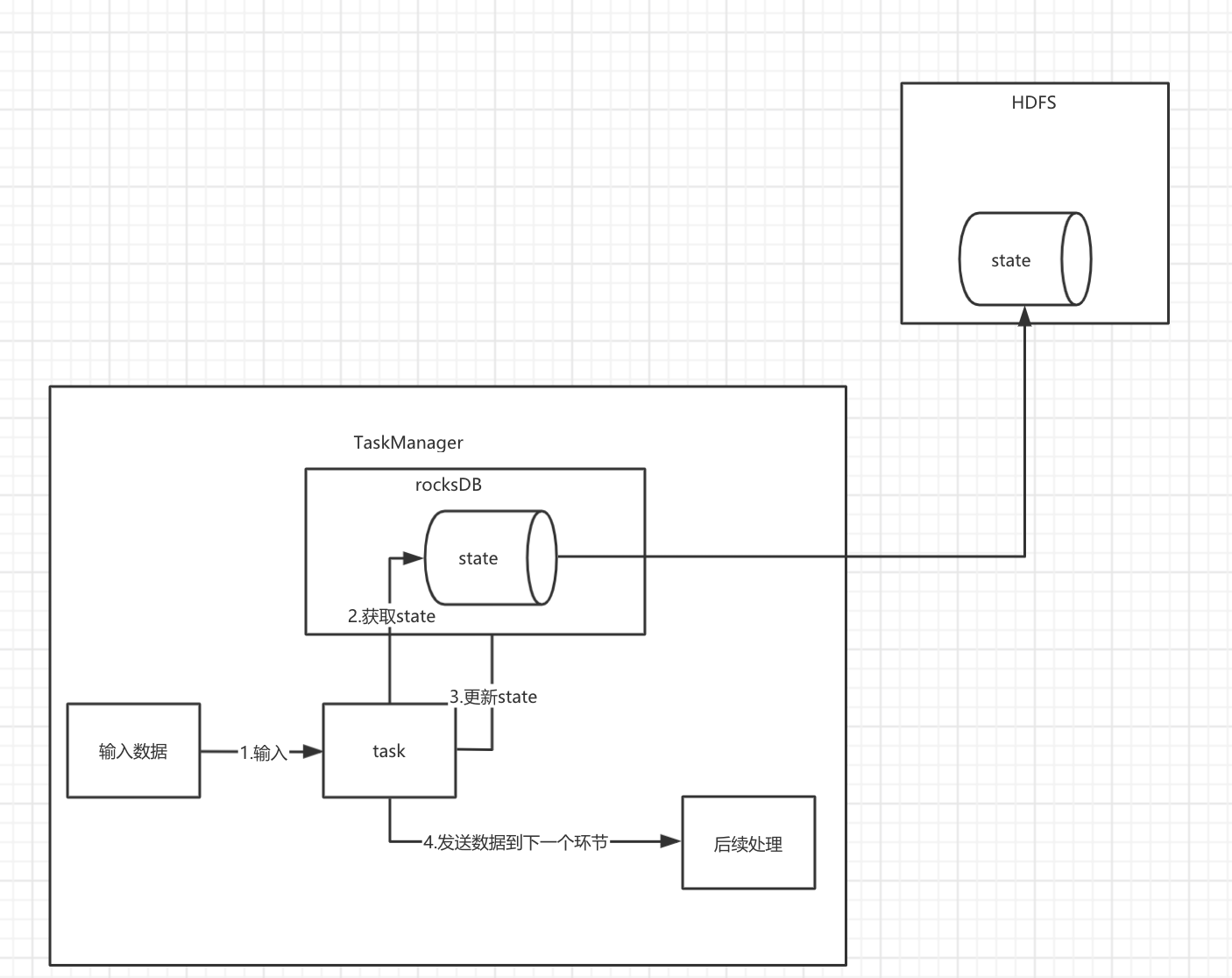
1.5.4 State backend 的使用方式
本地连接hadoop、使用rocksDB需要额外依赖
<!--rocksDB依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!--hadoop 依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
代码中使用 (也可以地址设置为本地磁盘路径,可以看一下效果)
env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new FsStateBackend("hdfs://node2:8020/flink/checkpoints"));
env.setStateBackend(new RocksDBStateBackend("hdfs://node2:8020/flink/checkpoints", true));
也可以选择同一配置,修改flink-conf.yaml
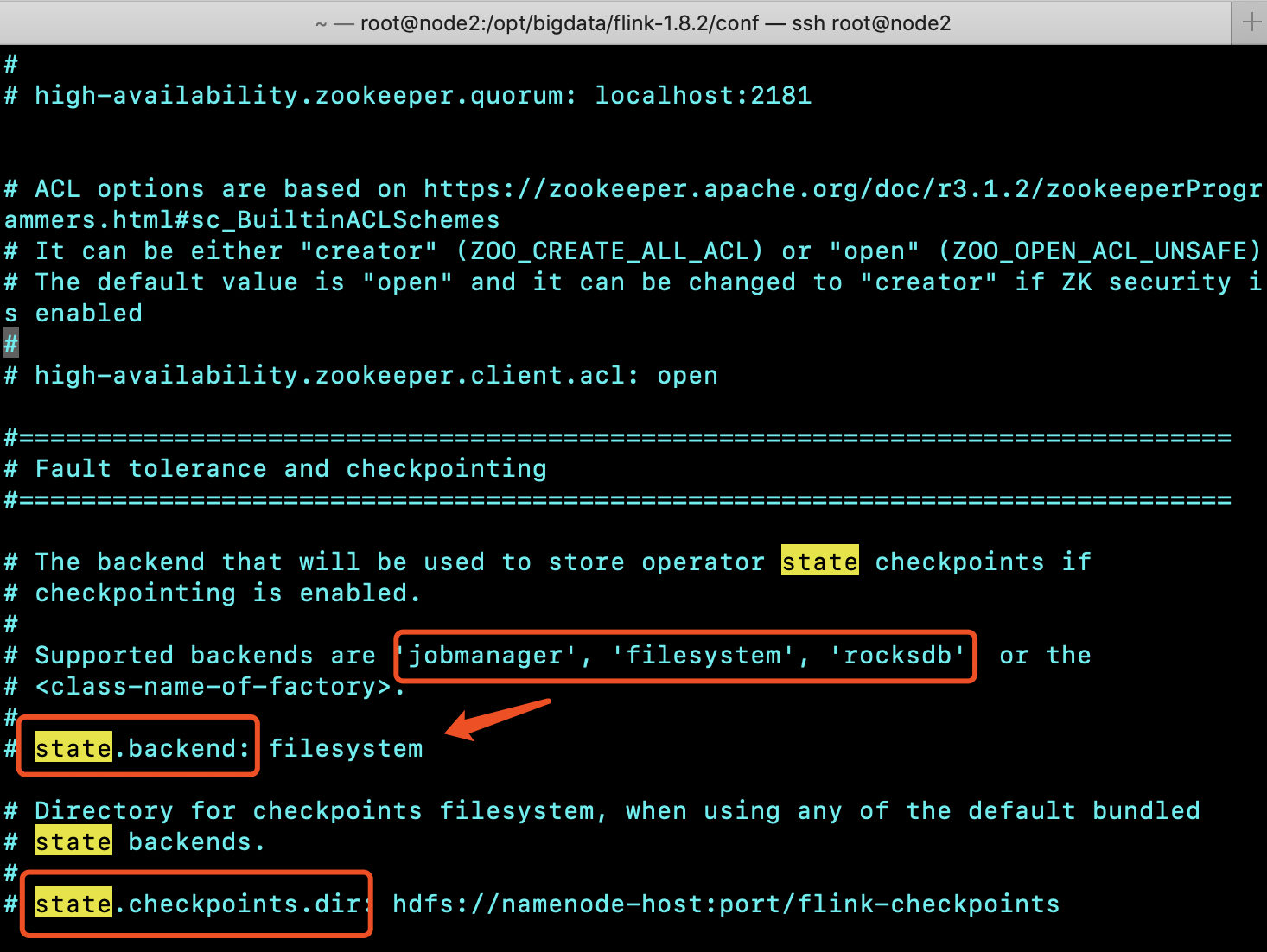
这是stateBacked的实现类
2.checkpoint
应用定时触发,用于保存状态,会过期,内部应用失败重启的时候使用。
2.1 checkpoint 概述
- 为了保证state的容错性,Flink需要对state进行checkpoint。
- Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
- Flink的checkpoint机制可以和持久化存储交互的前提: 持久化的source,它需要支持在一定时间内重放事件。这种sources的典型例子是持久化的消息队列(比如Apache Kafka,RabbitMQ等)或文件系统(比如HDFS,S3,GFS等) 用于state的持久化存储,例如分布式文件系统(比如HDFS,S3,GFS等)。
简单来讲, 经过一定的策略,基于state生成一个快照,储存到分布式文件系统,然后容错恢复的时候,根据相应的checkpoint文件,恢复当时的时间,然后继续做后续处理。
2.2 checkpoint的配置
默认情况下,checkpoint的功能是关闭的,需要开启,开启之后,checkPointMode有两种,Exactly-once和At-least-once,默认的checkPointMode是Exactly-once,Exactly-once对于大多数应用来说是最合适的。At-least-once可能用在某些延迟超低的应用程序。
官网直接拷贝
// 每隔1000 ms进行启动一个检查点
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为exactly-once (默认)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确保检查点之间有至少500 ms的间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 检查点必须在一分钟内完成,没有完成就被丢弃。
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间只允许进行一个检查点
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,checkpoint有多个,可以根据实际需要恢复到指定的Checkpoint。
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//当有新的保存点时,允许作业恢复回退到检查点(这个配置是1.9的flink新增的,我现在代码里面是1.8的,所以用不了这个,想测试的可以改一下版本,我就说怎么没有,尴尬..)
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
3.数据的恢复
3.1 重启策略概述
Flink支持不同的重启策略,以在故障发生时控制作业如何重启,集群在启动时会伴随一个默认的重启策略,在没有定义具体重启策略时会使用该默认策略。
如果在工作提交时指定了一个重启策略,该策略会覆盖集群的默认策略,默认的重启策略可以通过 Flink 的配置文件 flink-conf.yaml 指定。配置参数 restart-strategy 定义了哪个策略被使用。
如果没有启用 checkpointing,则使用无重启 (no restart) 策略。 如果启用了 checkpointing,但没有配置重启策略,则使用固定间隔 (fixed-delay) 策略, 尝试重启次数默认值是:Integer.MAX_VALUE,重启策略可以在flink-conf.yaml中配置,表示全局的配置。也可以在应用代码中动态指定,会覆盖全局配置。
3.2 常用的重启策略
3.2.1 固定间隔 (Fixed delay)
1.代码配置
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 间隔时间
));
2.全局配置 flink-conf.yaml
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
3.2.2 失败率 (Failure rate)
1.代码配置
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 一个时间段内的最大失败次数
Time.of(5, TimeUnit.MINUTES), // 指定一个时间段
Time.of(10, TimeUnit.SECONDS) // 每次重启的间隔时间
));
2.全局配置 flink-conf.yaml
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
3.2.3 无重启 (No restart)
1.应用代码设置
env.setRestartStrategy(RestartStrategies.noRestart());
2.全局配置 flink-conf.yaml
restart-strategy: none
3.3 多checkpoint配置
如果设置了checkpoin,那么默认只保留一个checkpoint,当程序失败时,可以从这个最近的checkpoint来恢复,但是如果我们希望保留多个checkpoint,从某一个checkpoint来进行恢复,那么会更加灵活,比如最近一段时间,数据处理有问题,那么我们希望回到一小时前,或者更早,那么就可以根据之前的checkpoint来进行恢复。
配置 flink-conf.yaml (这个数量很明显跟你所设置的checkpoint的产生的时间间隔有关系)
state.checkpoints.num-retained: 10
3.3 从checkpoint恢复数据
bin/flink run -s hdfs://node2:8020/flink/checkpoints/cc6a5758cf31aad25833d0503e6bd042/chk-132/_metadata flink-job.jar
//web ui 上面也能看,不过一般on yarn的话,任务失败这个界面就看不到了。
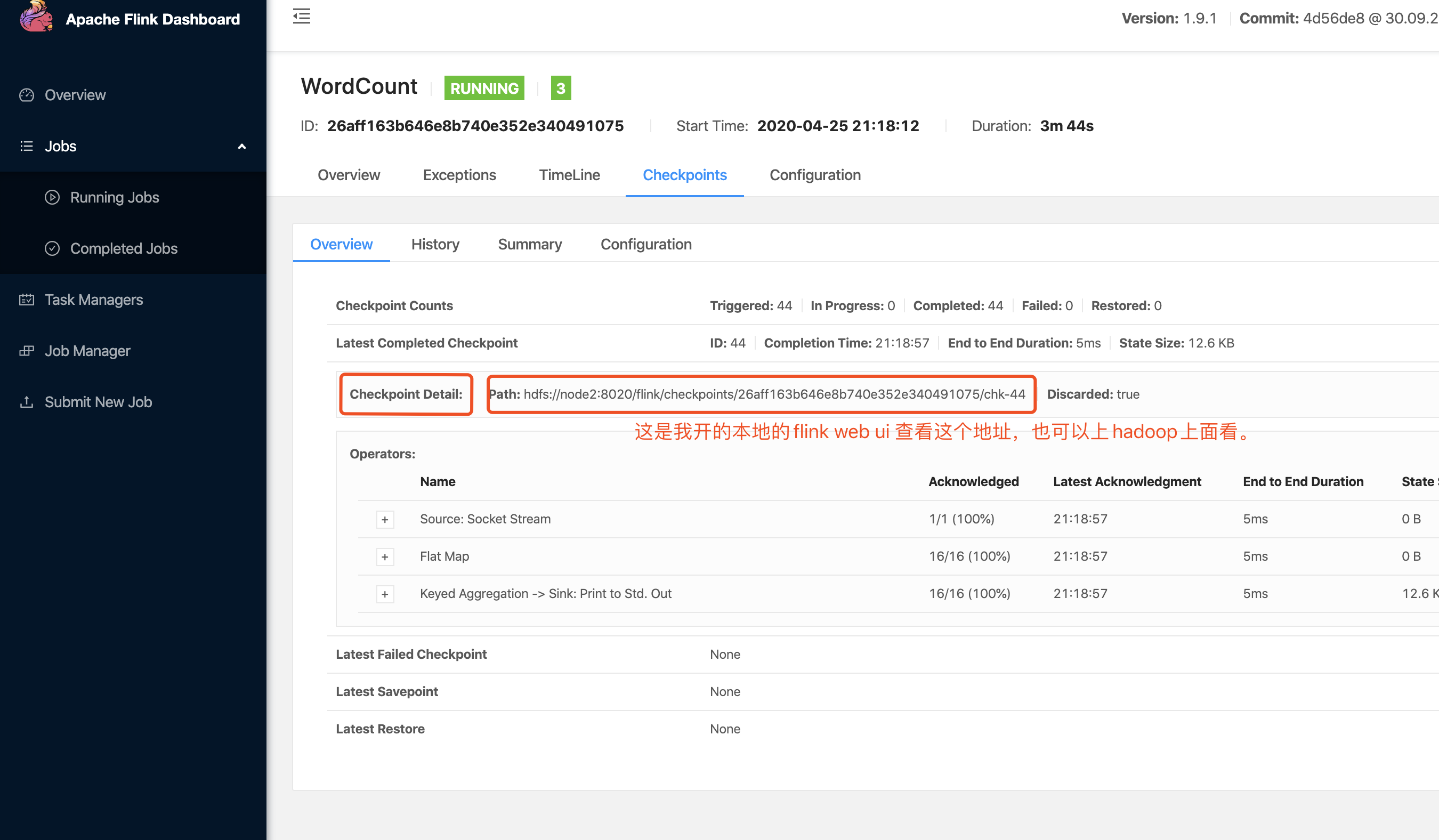
这里可以看一下,官方的Flink Checkpoint问题排查使用指南
3.4 savepoint
3.4.1 savapoint作用
Flink通过Savepoint功能可以做到程序升级后,继续从升级前的那个点开始执行计算,保证数据不中断 全局,一致性快照。可以保存数据源offset,operator操作状态等信息,可以从应用在过去任意做了savepoint的时刻开始继续消费。
用户手动执行,是指向Checkpoint的指针,不会过期,在升级的情况下使用。
这里有一个细节,为了能够在作业的不同版本之间以及 Flink 的不同版本之间顺利升级,我们通过 uid(String) 方法手动的给算子赋予 ID,这些 ID 将用于确定每一个算子的状态范围。如果不手动给各算子指定 ID,则会由 Flink 自动给每个算子生成一个 ID。只要这些 ID 没有改变就能从保存点(savepoint)将程序恢复回来。而这些自动生成的 ID 依赖于程序的结构,并且对代码的更改是很敏感的。因此,建议用户手动的设置 ID。
3.4.2 savapoint使用
1:在flink-conf.yaml中配置Savepoint存储位置,不是必须设置,但是设置后,后面创建指定Job的Savepoint时,可以不用在手动执行命令时指定Savepoint的位置
state.savepoints.dir: hdfs://node2:8020/flink/savepoints
2:触发一个savepoint【直接触发或者在cancel的时候触发】
bin/flink savepoint jobId [targetDirectory] [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
bin/flink cancel -s [targetDirectory] jobId [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
3:从指定的savepoint启动job
bin/flink run -s savepointPath [runArgs]
4.最后关于我使用的端口的问题
由于我在本地连我的hdfs,我本机不认识mycluster,所以我直接连的我当前集群的active NameNode,所以我用的是8020的端口,当在服务器环境操作的时候,可以直接使用mycluster。也就是可以使用9000端口。
这是我集群的配置
9000端口:是fileSystem默认的端口号:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
8020是namenode节点active状态下的端口号
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
到这里就已经结束了,最后的这几个演示起来有点麻烦,所以我就没有亲自演示了。但是贴的都是正确的。然后下一篇呢,就打算演示一下Flink之Event Time、Watermark的使用。
