

本文阐述内容概览
基础知识
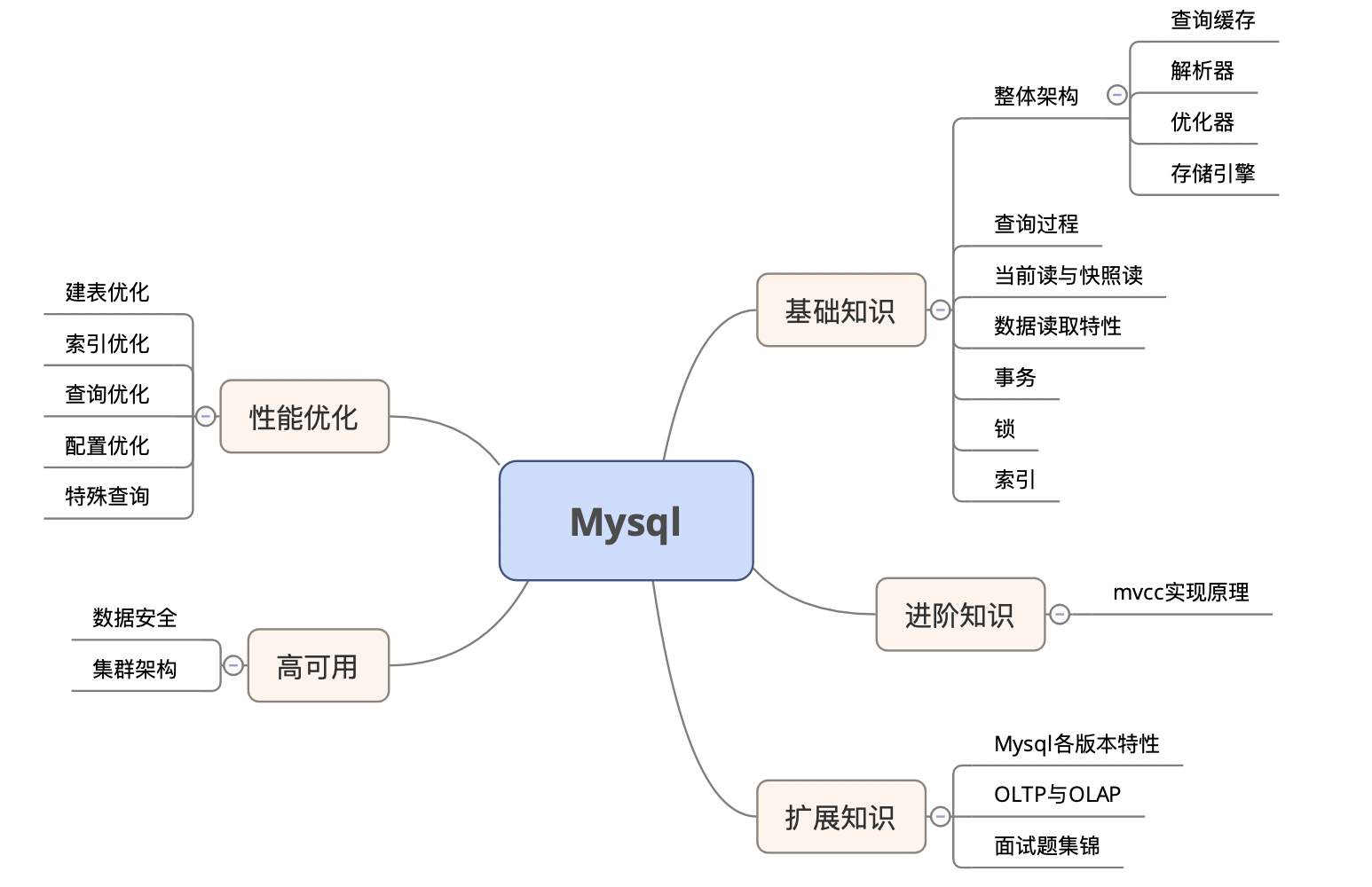
Mysql架构图
Mysql查询过程
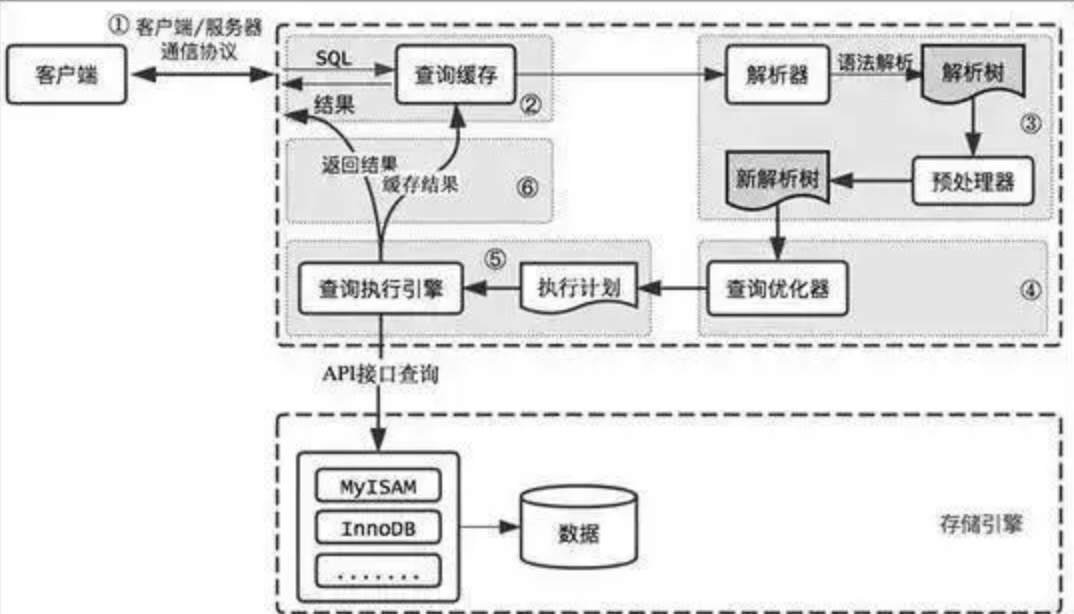
- 客户端连接mysql服务器
- 客户端发送一条查询过服务器
- 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果,否则进入下一阶段【可选】
- 服务器依次进行,词法解析、语法解析、生成解析树、预处理、生成新解析树
- 优化器生成对应查询计划
- 调用存储API完成查询
- 缓存查询结果【可选】
- 将结果返回给客户端
下面顺着Mysql架构图,按照从上往下的顺序,逐步引申出各知识点
连接器
负责跟客户端建立连接,获取权限,维持和管理连接
查询服务器运行时状态 - show status [like 'xxx']
查询系统参数 - show variables [like 'xxx']
查询当前连接状态 - show [full] processlist
具体状态值所代表的含义可以参考 Mysql Show status与Show processlist状态详解
关于连接超时
如果客户端太久没有响应,连接空闲超过wait_timeout(非交互式连接,例如通过jdbc)或 interactive_timeout(交互式连接,例如通过客户端连接)配置的时间后,服务器会主动断开连接,客户端后续再次使用这个连接时会报错,例如 Mysql server has gone away,需要重新连接数据库
解决方案:
1、采用短链接方式
每次查询都主动断开连接,带来的问题是每次重新创建连接带来的系统开销
2、采用长连接方式
达到一定条件后才断开连接,例如查询超过指定次数,创建超过指定时间,带来的问题是内存占用会飙升很快,因为Mysql在执行过程中临时使用的内存管理在连接对象里,需要等待连接断开时才能释放。
那么如何解决这个问题
- 合理控制断开连接的条件,使其即可以适当的复用连接,又可以保持内存不会溢出
- 在mysql 5.7及之后的版本中,适时使用mysql_reset_connection重新初始化连接资源,释放连接
3、使用连接池
通过提前建立好一批连接对象,后续通过并发请求量,请求次数,连接空闲时间等条件控制减少或者增加连接池中的连接对象,当应用需要请求mysql时,先请求连接池获取连接对象,再连接mysql
优点:
- 可以用复用连接对象,避免重新创建和释放连接
- 可以预创建连接对象,一定程序上可以减少并发请求过来时,连接创建的时间(超过预创建的空闲的连接对象数量时,依然要新创建连接对象)
- 管理数据库连接,控制资源的使用,通过队列机制,使的连接数控制在一定水平之下,增强了系统在大量请求下的稳定性
缺点:
- 由于增加了请求连接池获取连接对象的步骤,所以在进考虑单次请求,有可能耗时会更久
引申知识点
连接池工作在客户端,主要目的是管理和复用数据库连接,而mysql服务端从5.6开始,还支持线程池,主要目的是管理和复用服务端处理线程,将服务端线程的最小服务对象从一个连接降低到一条语句,提高了在高连接数下服务端的处理能力,同时通过优先处理持有锁的请求,来避免死锁,扩展阅读 MYSQL线程池总结
查询缓存
在Mysql8.0版本已删除该功能
在Mysql5.7及之前版本中,运行如下
查询缓存在内存中以KV形式存储,Mysql拿到一个请求后,先根据整个SQL(所有部分,大小写敏感)做哈希,去内存中判断是否命中,如果命中,检查一次用户权限,如果没有问题,则直接返回结果
由于数据的写操作将导致缓存失效,同时重建缓存,所以查询缓存是一个双刃剑,不一定能提高性能,最终取决于实际应用中的具体情况,很多时候,弊大于利,若非必要,不建议开启
解析器
主要是做词法解析、语法解析、判断权限、生成解析树
优化器
选择使用的索引,优化查询条件,优化执行顺序 主要是这些工作,可以通过explain查询优化器执行计划。
优化器的结果一定是最优的吗
不是。
优化器是基于最小成本进行优化的,就是说扫描尽可能少的行,但不代表执行时间就是最短的
以下情况可能导致优化选选择错误的执行计划
- 统计信息不准确,mysql是依赖统计信息来计算成本,可以使用analyze table来重新生成统计信息
- 计划中的最小成本和实际执行的成本是不同的,例如某个计划虽然读取的页面更多,但实际成本更小,因为这些页面都是顺序读取的
- mysql不考虑其他并发执行的查询,可能会影响当前查询的速度
- mysql不会考虑不受其控制的操作的成本,例如存储过程和用户自定义函数
如果不是怎么解决
- 添加hint来改变执行计划,例如use index, igonre index, force index等
- 重写查询
- 重新设计表结构
- 添加更合适的索引
存储引擎
InnoDb
- 特性
- MySQL的默认事务型引擎,它被设计用来处理大量的短期(short-lived)事务
- InnoDB是基于聚簇索引建立的,聚簇索引对主键查询有很高的性能。不过它的二级索引(secondary index,非主键索引)中必须包含主键列,所以如果主键列很大的话,其他的所有索引都会很大。因此表上的索引较多的话,主键应当尽可能的小
- InnoDB的存储格式是平台独立的,可以将数据和索引文件从Intel平台复制到Sun SPARC平台或其他平台
- InnoDB通过一些机制和工具支持真正的热备份
- 运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引
- 使用行锁,粒度更小,不会锁定全表,并发处理能力更高
- 适用场景
- 读写请求都比较多的,大多时候的最优选择
- 热备份是必要诉求的
MyISAM
- 特性
- 提供了大量的特性,包括全文索引、压缩、空间函数(GIS)等,但不支持事务
- 使用表锁,不支持行锁
- 适用场景
- 在查询总行数count(*)时有一定优势,其他情况,尽量不选择该引擎
TokuDB
- 特性
- 高压缩比,默认使用zlib进行压缩,尤其是对字符串(varchar,text等)类型有非常高的压缩比,比较适合存储日志、原始数据等。官方宣称可以达到1:12。
- 在线添加索引,不影响读写操作
- HCADER 特性,支持在线字段增加、删除、扩展、重命名操作,(瞬间或秒级完成)
- 支持完整的ACID特性和事务机制
- 非常快的写入性能, Fractal-tree在事务实现上有优势,无undolog,官方称至少比innodb高9倍。
- 数据量可以扩展到几个TB;
- 不会产生索引碎片;
- 适用场景
- 访问频率不高的数据或历史数据归档
- 数据表非常大并且时不时还需要进行DDL操作
Memory
- 特性
- 如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系,那么使用Memory表是非常有用。Memory表至少比MyISAM表要快一个数量级
- Memory表是表级锁,因此并发写入的性能较低。它不支持BLOB或TEXT类型的列,并且每行的长度是固定的,这可能呆滞部分内存的浪费
- 适用场景
- mysql查询过程中创建的临时表使用的就是Memory引擎
以下内容主要讨论innodb引擎的实现
快照读与当前读
Mysql读操作可以分成两类,快照读与当前读
- 快照读
- 读取的是记录数据的可见版本(可能是过期的数据),不用加锁
- 简单select使用该读取方式
- 当前读
- 读取的是记录数据的最新版本,并且当前读返回的记录都会加上锁,保证其他事务不会再并发的修改这条记录
- select ... lock in share mode
- select ... for update
- insert
- update
- delete
- 以上查询将使用当前读
数据读取特性
- 脏读
- A事务读取B事务尚未提交的更改数据,并在这个数据基础上操作
- 如果B事务回滚,那么A事务读到的数据根本不是合法的,称为脏读
- 不可重复读
- 指一个事务范围内两个相同的查询却返回了不同数据
- 这是由于查询时系统中其他事务修改的提交而引起的
- 幻读
- 在两个连续的查找之间一个并发的修改事务修改了查询的数据集,导致这两个查询返回了不同的结果
- 这是由于查询时系统中其他事务新增或者删除记录引起的
事务
事务原则ACID
A: atomicity 原子性 指一个事务中,要么全部成功,要么全部失败
C: consistency 一致性 指数据的可见性,中间状态的数据对外部不可见,只有最初状态和最终状态的数据对外可见
I: isolation 事务的独立性也有称作隔离性,是指两个以上的事务不会出现交错执行的状态.因为这样可能会导致数据不一致,指一个事务提交前,对其他事务是不可见的
D: durability 持久性 指一旦事务提交成功,则其所作的修改就会永久保存到数据库中,即使系统崩溃,修改的数据也不会丢失
事务隔离级别与锁
Read uncommited(未提交读)
事务中的修改,即使未提交,对其他事务也是可见的
一句总结:读取数据一致性在最低级别,只能保证不读物理上损坏的数据,会脏读,会不可重复读,会幻读,从性能上来说也不会比其他级别好太多,很少使用
此级别SELECT不加锁
Read commited(提交读)
一个事务从开始到提交前,所作的任何修改对其他事务不可见
一句总结:读取数据一致性在语句级别,不会脏读,会不可重复读,会幻读 仅能读取到已提交的记录
普通select语句是快照读,不加锁update语句、delete语句、显示加锁的select语句(select … in share mode 或者 select … for update) 等,除了在外键约束检查和重复键检查时会封锁区间,其他情况都只使用记录锁
Repeatable read(可重复读)
在同一个事务中,多次读取同样的记录的结果是一致的(解决了脏读,无法解决幻读,MYSQL默认事务隔离级别)
一句总结:读取数据一致性在事务级别,不会脏读,不会不可重复读,会幻读
从定义上来说是无法解决幻读,但实际情况中,MYSQL通过MVCC和间隙锁解决了幻读问题,具体可以参考下面MVCC实现原理的介绍
普通select语句是快照读,不加锁update语句、delete语句、显示加锁的select语句(select … in share mode 或者 select … for update)则要分情况:
在唯一索引上使用唯一的查询条件,则使用记录锁。如: select * from user where id = 1;其中id建立了唯一索引。
在唯一索引上使用 范围查询条件,则使用间隙锁与临键锁。如: select * from user where id >20;
Serializable(可串行化)
最高的隔离级别,强制事务串行执行,不允许并发,会为读取的每一行数据加锁,可能导致大量的超时和锁竞争,只有再非常需要一致性可以接受没有并发的情况下才使用 一句总结:读取数据一致性在最高级别,事务级别,不会脏读,不会不可重复读,不会幻读
此级别所有select语句都会被隐式加锁:select … in share mode分布式事务(跨库事务)
- 普通事务不允许跨库
- 如果需要跨库可以使用XA事务,在这之前确认开启了XA,检查innodb_support_xa 系统参数,如果值为ON,则表示已开启
- 分布式事务原理
- 分布式事务通常采用2PC协议,全称Two Phase Commitment Protocol,通过2PC协议将提交分成两个阶段
- 阶段一,为准备(prepare)阶段
- 即所有的参与者准备执行事务并锁住需要的资源。参与者ready时,向transaction manager(事务协调者)报告已准备就绪
- 阶段二,为提交阶段(commit)
- 当transaction manager确认所有参与者都ready后,向所有参与者发送commit命令或rollback
- 阶段一,为准备(prepare)阶段
- 关于transaction manager(事务协调者)
- MySQL 在这个XA事务中扮演的是参与者的角色,而不是事务协调者(transaction manager)
- Mysql的XA事务分为外部XA和内部XA
- 外部XA用于跨多MySQL实例的分布式事务,需要应用层作为协调者,通俗的说就是比如我们在PHP中写代码,那么PHP书写的逻辑就是协调者
- 内部XA事务用于同一实例下跨多引擎事务,由Binlog作为协调者,比如在一个存储引擎提交时,需要将提交信息写入二进制日志,这就是一个分布式内部XA事务,只不过二进制日志的参与者是MySQL本身。Binlog作为内部XA的协调者,在binlog中出现的内部xid,在crash recover时,由binlog负责提交。(这是因为,binlog不进行prepare,只进行commit,因此在binlog中出现的内部xid,一定能够保证其在底层各存储引擎中已经完成prepare)
- 分布式事务通常采用2PC协议,全称Two Phase Commitment Protocol,通过2PC协议将提交分成两个阶段
- XA事务基本语法
- XA {START|BEGIN} xid [JOIN|RESUME] 启动xid事务 (xid 必须是一个唯一值; 不支持[JOIN|RESUME]子句)
- XA END xid [SUSPEND [FOR MIGRATE]] 结束xid事务 ( 不支持[SUSPEND [FOR MIGRATE]] 子句)
- XA PREPARE xid 准备、预提交xid事务
- XA COMMIT xid [ONE PHASE] 提交xid事务
- XA ROLLBACK xid 回滚xid事务
- XA RECOVER 查看处于PREPARE 阶段的所有事务
- XA性能问题
- XA的性能很低。一个数据库的事务和多个数据库间的XA事务性能对比可发现,性能差10倍左右。因此要尽量避免XA事务,例如可以将数据写入本地,用高性能的消息系统分发数据。或使用数据库复制等技术。只有在这些都无法实现,且性能不是瓶颈时才应该使用XA。
锁
通常情况下,当访问某张表或者记录的时候,操作者必须先获取锁。
需要写锁还是读锁取决于执行的操作,获取写锁的优先级高于读锁。
但是当读取者已经拿到读锁在查询时,此时有写操作请求获取写锁,由于查询开始后不能中断,因此允许读取者完成操作,此时写锁请求需要等待。
详细信息,查看Mysql 锁总结
索引
进阶知识
MVCC
什么是MVCC
指多版本并发控制,让普通的select语句直接读取指定版本的值,避免加锁,来提高并发请求时的性能,配合行锁机制,在并发请求下,提高了MYSQL的性能
MVCC解决了什么问题
- 做到了读不影响写,写不影响读,提高了并发性能
- 提供了一致性读的功能,避免幻读和不可重复读
什么时候会用到MVCC
在RC和RR隔离级别下,innodb通过快照读方式读取数据时使用
MVCC实现原理
针对MYSQL INNODB的底层实现原理,请查看另一篇文章 Mysql MVCC实现原理
优化
优化
-
查询缓存
- 尽量不开启查询缓存,因为写操作带来的缓存失效,会导致频繁重新缓存,很可能得不偿失
- 除非很少更新的情况下才考虑
-
建表优化
- 范式与反范式
- 范式设计,冗余数据少,插入,更新快,但是查询效率不高,需要关联查询
- 反范式设计,冗余数据多,查询效率高,不需要关联查询,但是更新冗余字段时代价较高,需要同时更新多个表
- 通常都是混用,考虑冗余列更新的频率和执行查询的频率来取舍
- 字段类型选择
- 尽量使用可以正确存储数据的最小数据类型
- 更小的数据类型通常处理速度更快,占用磁盘,内存,CPU缓存也越小
- 例如从小到大tinyint|int|bigint, timstamp|datetime
- 尽量选择简单的数据类型
- 例如整型比字符串操作代价低,运算速度更快
- varchar|char比text字段查询速度快,因为text太大时mysql会在"外部"存储区域存储,行内需要1-4个字节来存储一个指针,指向外部区域,会增加I/O次数
- 相对来说枚举型enum会比字符串节省空间,mysql内部使用一张映射表将枚举型字符串映射为一个整数,而实际存储的是一个整数,但是是否选择enum需要慎重
- enum需要事先定义好集合,后续增加需要改变,在生成环境中可能会导致服务异常或者中断
- 曾经遇到一个场景,线上业务有个表的字段是枚举型,由于业务扩展需要增加新的枚举值,当时在双活架构下,表的数据是实时同步的,如果不停止写入,更改字段的时候,当一边表增加完新的枚举值,另外一边表还没有同步完成时,这时写入的新枚举值同步过去的是一个整数,而未修改的表并不认识,还没有创建该值的映射,会导致错误
- enum内部是按照映射的整数进行排序,而不是字符串进行排序,这点也需要注意
- enum需要事先定义好集合,后续增加需要改变,在生成环境中可能会导致服务异常或者中断
- 尽量避免NULL值
- 如果查询中包含可为NULL的列,对Mysql来说更难优化,因为NULL的列使得索引、索引统计和值比较都更复杂
- 关联列
- 关联列要选择相同的数据类型,最好选择整型
- 建立合适的索引
- 单个查询关联的表最好不要超过12个
- 避免建立过多的列
- Mysql的存储引擎API工作时需要在服务器层和存储引擎层之前通过行缓冲格式拷贝数据,然后在服务器层将缓冲内容解码成各个列,这个过程的操作代价非常高,所以如果过多的列,比如上百个会导致这个问题被放大
- 尽量使用可以正确存储数据的最小数据类型
- 范式与反范式
-
索引优化
- 考虑索引的选择性
- select count(distinct col)/count(col) from table
- 避免创建重复的索引
- 例如 index col1 和 联合索引index (col1,col2) 重复,可以删除 index col1
- 为关联列创建索引
- 提高联合查询性能
- 尽量为关联列选择简单的字段类型,比如
- 联合索引
- 注意联合索引列的顺序
- 如果查询中有某个列的范围查询,其右边的列都无法使用索引优化查找
- 从左往右,不能跳过索引中的列
- 如果不考虑排序和分组,那么将选择性高的列放在左边通常是很好的
- 如果需要排序和分组,那么注意索引的顺序要和排序分组的顺序保持一致
- 注意联合索引列的顺序
- Innodb支持自适应哈希索引
- 当innodb注意到某些索引值被使用的非常频繁时,它会在内存中基于BTREE索引之上创建一个哈希索引,不过这是一个自动的行为,如果有比好可以关闭该功能
- 对于长字段,考虑前缀索引
- 如何创建前缀索引,alter table 表名 add index 索引名 (列名(长度))
- 索引长度要基于列的选择性来设计
- 如何
- select count(distinct 列名)/count(*)as a,COUNT(DISTINCT left(列名,100)) as b, COUNT(DISTINCT left(列名,110)) as c from 表名 通过该方法来计算前缀列的选择性,当b接近a时就是合适的长度
- 避免多个范围查询
- 对于范围条件查询,mysql无法使用后面的其他索引列
- 考虑索引的选择性
-
锁相关优化
- 减少锁竞争
- 批量写入和更新,因为每次操作都需要先获取锁再查询
- 分解关联查询
- 避免死锁
- 尽可能按照相同顺序访问表
- 减少锁竞争
-
查询优化
- 避免不能使用索引的情况
- 保证查询条件中将索引列单独放在=号的左边,例如避免where id + 1 = 5这种写法
- 查询字段上使用函数计算,例如select f1,f2 form t where month(f1)=7
- 字段隐式转换,当索引字段类型和比较的值类型不同时,mysql会执行隐式转换,这个时候也不会使用索引,例如在字段name varchar(32)加上索引 where 条件写入 name = 123是不会利用索引的,因为name是字符串类型,123是整型,改成name = '123'即可使用索引
- 隐式字符编码转换,原因是两个相互关联查询的表的字符集不同,这时也不会使用索引
- not in, <>, IS NULL, IS NOT NULL, like 有前导%
- 避免查询不需要的记录
- 比如必须要的字段
- 比如不需要的行数
- insert
- 尝试批量写入(一次写入10条时比较高效),因为每次插入操作都需要提交到查询关系引擎做解析,优化,为了节省这个步骤,所以批量插入就是一种优化
- 考虑使用replace 语句代替insert语句
- 考虑切分大的查询
- 比如一次性删除大量数据,可以改为多次删除,每次删一小部分,避免锁住资源太长时间,耗尽系统资源,影响其他重要的查询,也可以减少复制的延迟
- 优化联合查询
- 确保连接列的数据类型一致,加上索引,并且注意关联的顺序,例如A表关联B表,如果优化器的顺序是B、A,那么就不会用到B表上的索引,可以结合其他业务情况,如果确定都不会用到,则不需要在B表建立索引
- 子查询
- mysql实现子查询时会将外层表压到子查询中,而不是先执行子查询再执行外部查询,导致性能可能不好
- 如果可能,尽量避免子查询
- 如果需要,可以考虑使用联合查询来代替子查询,但一定要根据实际测试结果进行比较谁更优(5.6开始该点不一定适用,优化器可能可以正确优化子查询了)
- 排序优化
- 当索引的列的顺序和order by子句的顺序完全一致,并且满足索引最左前缀原则,所有的排序方向(都倒序或都正序)都是一样时可以使用索引排序
- 如果是关联查询,则只有当order by子句引用的字段全部为第一个表时,才能使用索引排序
- 注意,如果前导列被指定为常量时,可以不满足索引最左前缀的要求,例如建立联合索引(date,class_id,uid),使用where date='2020-02-22' order by class_id asc, uid asc时可以使用索引排序
- 在这里,in也算是范围查询,不能算作常量
- 分组优化
- group by 指定的所有列是索引的一个最左前缀,并且没有其它的列
- 如果在选择列表 select list 中存在聚集函数,只能使用 min() 和 max() 两个聚集函数,并且指定的是同一列(如果 min() 和 max() 同时存在),这一列必须在索引中,且紧跟着 group by 指定的列
- 如果查询中存在除了 group by 指定的列之外的索引其他部分,那么必须以常量的形式出现(除了min() 和 max() 两个聚集函数)
- 比如 select c1,c3 from t1 group by c1,c2 不能使用松散索引扫描。而 select c1,c3 from t1 where c3 = 3 group by c1,c2 可以使用松散索引扫描。
- 上述索引不包括前缀索引
- 避免不能使用索引的情况
-
配置优化
- innodb_buffer_pool_size
- Innodb最重要的参数
- 用于缓存索引和数据的内存大小
- 如果是一个专用DB服务器,那么他可以占到内存的70%-80%
- 如果你的数据比较小,那么可分配是你的数据大小+10%左右做为这个参数的值
- innodb_buffer_pool_instances
- buffer pool 被划分为多个缓存实例的数量, 为固定值,不动态变更。当较多数据加载到内存时, 使用多缓存实例能减少缓存争用情况。
- 当 innodb_buffer_pool_size 大于 1GB 时, innodb_buffer_pool_instances 默认为 8。如有更多buffer pool, 平均每个instances 至少1GB
- innodb_page_size
- innodb_page_size 默认 16kb, 数据存储页, 应与操作系统块大小一致(同 innodb_log_write_ahead_size)。 对于 SSD 更小的页可能更好。innodb_page_size 为32k and 64k 时, 行长度最大为 16000 bytes, 且不支持 ROW_FORMAT=COMPRESSED
- innodb_additional_mem_pool
- 用来存放Innodb的内部目录
- 这个值不用分配太大,系统可以自动调。不用设置太高,通常比较大数据设置16M够用了
- innodb_log_file_size
- 指定在一个日志组中,每个log的大小
- 结合innodb_buffer_pool_size设置其大小,25%-100%。避免不需要的刷新
- 这个值分配的大小和数据库的写入速度,事务大小,异常重启后的恢复有很大的关系。一般取256M可以兼顾性能和recovery的速度
- innodb_log_files_in_group
- 指定你有几个日值组
- 分配原则:一般我们可以用2-3个日值组。默认为两个
- innodb_flush_logs_at_trx_commit
- 控制事务的提交方式,也就是控制log的刷新到磁盘的方式
- 这个参数只有3个值(0,1,2).默认为1
- 0:log buffer中的数据将以每秒一次的频率写入到log file中,且同时会进行文件系统到磁盘的同步操作,但是每个事务的commit并不会触发任何log buffer 到log file的刷新或者文件系统到磁盘的刷新操作;
- 1:(默认为1)在每次事务提交的时候将logbuffer 中的数据都会写入到log file,同时也会触发文件系统到磁盘的同步;
- 2:事务提交会触发log buffer 到log file的刷新,但并不会触发磁盘文件系统到磁盘的同步。此外,每秒会有一次文件系统到磁盘同步操作。
- 这个参数的设置对Innodb的性能有很大的影响,所以在这里给多说明一下。
- 当这个值为1时:innodb 的事务LOG在每次提交后写入日值文件,并对日值做刷新到磁盘。这个可以做到不丢任何一个事务。
- 当这个值为2时:在每个提交,日志缓冲被写到文件,但不对日志文件做到磁盘操作的刷新,在对日志文件的刷新在值为2的情况也每秒发生一次。但需要注意的是,由于进程调用方面的问题,并不能保证每秒100%的发生。从而在性能上是最快的。但操作系统崩溃或掉电才会删除最后一秒的事务。
- 当这个值为0时:日志缓冲每秒一次地被写到日志文件,并且对日志文件做到磁盘操作的刷新,但是在一个事务提交不做任何操作。mysqld进程的崩溃会删除崩溃前最后一秒的事务。
- 从以上分析,当这个值不为1时,可以取得较好的性能,但遇到异常会有损失,所以需要根据自已的情况去衡量
- InnoDB_lock_wait_timeout
- 这个参数自动检测行锁导致的死锁并进行相应处理,但是对于表锁导致的死锁不能自动检测默认值为50秒
- Innodb_io_capacity
- 这个参数刷新脏页数量和合并插入数量,改善磁盘IO处理能力
- innodb_buffer_pool_size
-
特殊查询
- count(*)与count(col)
- 当需要统计行数时最好使用count(*), count(col)并不会统计col字段为NULL的行
- limit分页
- 当limit偏移量很大时,性能急剧下降,例如limit 100000,10 mysql会查询100010行数据,然后抛弃前面100000条
- 通过覆盖索引和延迟关联来优化该查询
- 例如将select film_id,description from sakila.film order by title limit 50000,10改为
- select film.film_id,film.description from sakila.film inner join (select film_id from sakila.film order by title limit 50000,10) as lim using(film_id)
- count(*)与count(col)
高可用
数据安全
集群架构
扩展知识
