

索引的数据结构
Mysql 支持两种数据类型的索引,Hash和B+Tree

根据Mysql官方文档描述,InnoDB和MyISAM支持BTREE,MEMORY/HEAP和NDB支持HASH和BTREE
为什么选择B+Tree数据结构存储索引
在聊B+Tree之前,我们先说下HASH
HASH
HASH表是通过一个哈希算法随机计算出对应的数组下标,但是可能不同值的经过哈希算法后,算出相同的数组下标,这时就出现哈希冲突,传统做法是在产生哈希冲突的地方使用一个链表存储所有的冲突值,后续通过遍历链表中的值来匹配
-
无序哈希表
- 基础哈希表的特点,可以快速的精确查询,但是不支持范围查询,因为他本身是无序的,如果需要范围查询,则需要扫描全表
- 所以无序HASH比较适合做Key-Value类型的存储
-
有序哈希表
- 如果想HASH表支持快速的范围查询,那么可以考虑做成有序哈希表,但是这样会来带一个问题,为了保持有序,在新增,删除,修改数据后需要改变他的结构,挪动其他元素,成本很高
- 所以有序Hash比较适合存储很少或者不用更新的静态数据,只做查询,比如去年的银行流水,交易记录,历史订单等
那么有没有一种数据结构,可以兼容精确查询和范围查询,都提供较好的查询/修改速度呢,下面聊下为什么选择B+Tree
B+Tree
先来说下几个相关的数据结构,二叉树,平衡二叉树,B树
- 二叉树和平衡二叉树
- 因为相同的数据量,二叉树的树高太高,查询的成本太高,所以不适合做索引
- B树
- B树的节点存储的是数据加索引
- 因为B树中一个节点可以存储多个元素,所以相同数据量下,树高较低,查询更快
- B+树
- B+树是B树的一个变形,非叶子节点只保存索引,不保存实际的数据,叶子节点同时保存索引和数据
- 优缺点
- B+树只需要查询所有节点(索引),B树查询索引和数据。虽然可能第一个就找到,但在极端情况下,需要全查询索引和数据,不如B+树稳定
- 因为B+树节点只有索引,占位更少,所以B+树的硬盘空间更少,io的读写代价更低
- 关于一个节点多大比较合适
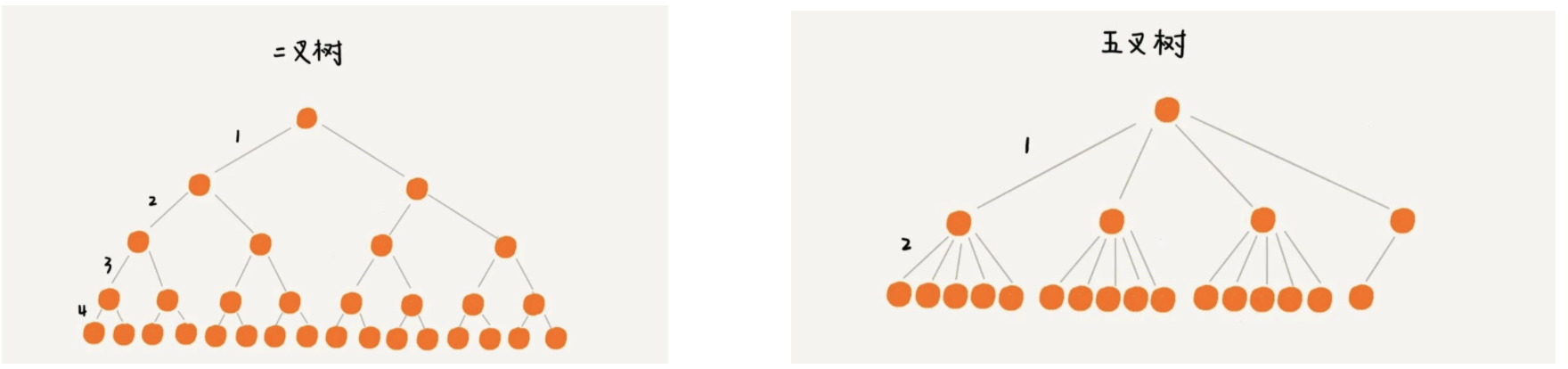
- 因为理论上树的节点存储的数据越多,整体树的度(高度)就越低,I/O的次数就越少,那么是不是存储的数据越多越好呢
- 不是,因为操作系是按数据页大小来访问硬盘的,每次 IO 只读取一个数据页大小的数据,如果要读取的数据大于一个数据页,则会导致多次 IO。因此我们要尽量让每个节点的数据大小刚好等于一个数据页大小,即每访问一个节点只需一次 IO
- 关于叶子节点分裂与合并
- 参考文章 B+树索引结构解析
索引类型
PRIMARY KEY(主键索引)
一种特殊的唯一索引,不允许有空值
UNIQUE(唯一索引)
索引列的值必须唯一,但允许有空值
INDEX(普通索引)
最基本的索引,没有任何限制
FULLTEXT(全文索引)
全文检索是对大数据文本进行索引,在建立的索引中对要查找的单词进行进行搜索,定位哪些文本数据包括要搜索的单词。
通过关键字的匹配来进行查询过滤,那么就需要基于相似度的查询,而不是原来的精确数值比较,是搜索引擎的关键技术
但是大多数时候还是不太建议使用Mysql的全文索引,如果需要的话可以考虑专业的搜索引擎存储,例如ElasticSearch
注意事项
- 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引
- 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引
- 5.7.6 开始支持中文分析
- 只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引
- 全文索引比 like + % 快 N 倍,但是可能存在精度问题
联合索引
多个索引组合使用,依照最左前缀匹配进行匹配
最左前缀匹配原则
非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整
索引的优缺点
优点
加快查询速度
缺点
由于需要维护索引,会降低写操作的速度,包括insert|update|delete
运行时,索引会缓存在内存中,过多的索引会导致内存消耗较大
索引会占用一定的磁盘空间
聚集索引
定义
数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引
特点
Mysql里,Primary Key就是聚集索引
叶子节点就是对应的数据节点,存储了所有列的数据,所以如果根据主键索引查询,只需查询一次就可以拿到全部列的数据
非聚集索引
定义
该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引
特点
Mysql里,除了主键索引外都是非聚集索引,包括INDEX, UNIQUE, FULLTEXT
数据和索引分开存储,索引带有指针指向数据的存储位置
根据非聚集索引查询时,如果查询列中包含了该索引没有覆盖的列,那么还要进行第二次的查询,查询节点上对应的数据行的数据
