

In a nutshell, RL is the study of agents and how they learn by trial and error. It formalizes the idea that rewarding or punishing an agent for its behavior makes it more likely to repeat or forego that behavior in the future.
近期在业务上尝试了一些RL相关的技术,相对于深度学习,RL在知乎上资料明显偏少。分享一些优秀的资料给有兴趣的同学。
RL有很多新的概念,最核心的四元组:
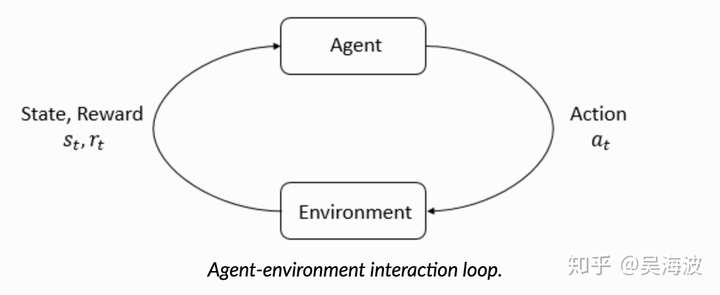
: Action space : A State space : S Reward: R : S × A × S → R Transition : P :S × A → S
以及我们常说的Value-base和Policy-base、model-base和model-free、stochastic policy和deterministic policy等等。下图能更好的描述:
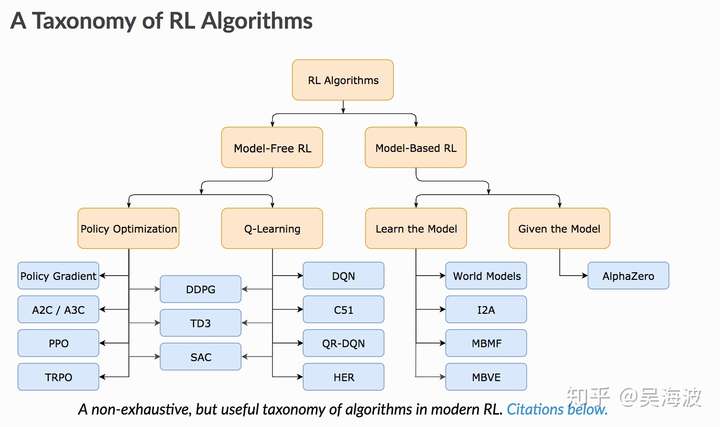
一上来就看Sutton的大作容易迷失在知识的海洋中。在面对一个未知领域时,如果能从一个麻雀虽小五脏俱全的demo开始入手,怎么容易的多。缩短学习过程和反馈的路径,有助于提高学习效率。
首推莫烦的RL教程 非常通俗易懂的入门教程,覆盖了目前RL的主要算法,从最简单的Q Learning开始,到DQN、PPO以及后面的Actor-critic算法,而最关键的是每一篇都很短。
通过动手实现一个个demo,快速熟悉常用的RL算法,比如,一个常见的RL大概有以下几个部分:
class DeepQNetwork:
def init # 初始化
def _build_net(self): #创建一个网络来预估action或者其他
def store_transition(self, s, a, r, s_):
# 存储训练过程中的表现
def choose_action(self, observation):
# 如何选择一个action
def learn(self):
# 参数如何更新同时,结合OpenAI的Spinning up的教程,特别是他的Introduction部分:http://spinningup.openai.com/en/latest/spinningup/rl_intro.html
1. Key Concept in RL
2. Kinds of RL Algorithms
3. Intro to Policy Optimization
仔细的去理解RL中的核心概念。
一些关键点
Whatever the choice of return measure (whether infinite-horizon discounted, or finite-horizon undiscounted), and whatever the choice of policy, the goal in RL is to select a policy which maximizes expected return when the agent acts according to it.
RL的问题,最终要去思考怎么定义采取动作后的reward和最大reward的差异,以及我们用什么方法更新参数。
在Q Learning中,有一张大表,记录了所有state对应action的value,我们需要做的是通过样本学习表中每个单元格的value,让reward最大。
在大多数情况下,这个表会大的不可接受。在DQN中,用一个NN去替代了查表的操作。再通过experience reply解决机器学习要求独立同分布的问题,用固定参数的方式,一个网络输出Q估计和Q现实,二者的diff作为loss去更新参数。
另一种思路是直接优化policy,还是用NN去输出policy。问题转化为如何更新NN的参数,分为stochastic和deterministic,其中stochastic需要采样,计算量更大,比如PPO。而大神David Silver在14年的论文Deterministic Policy Gradient Algorithms(DPG)证明了DPG的策略梯度公式,其后的DDPG更是大行其道。
自然而然的,出现了融合Value和policy的思想的算法。Actor-critic算法,其中Actor代表了Policy Gradient,而Critic代表了Value base的。其中代表算法为A3C,是目前state of art的算法之一。
进阶资料
走完上面的路程之后,只是简单过了遍概念。接着要老老实实的去啃Sutton的大作,结合David Silver的课,有助于消化。同时,还要深入到实际工作中在业务上落地。
最后,引用下侯捷老师的一段话,与诸君共勉:
作为一个好的学习者,背景不是重点,重要的是,你是否具备正确的学习态度,起步固然可以从轻松小品开始,但如果碰上大部头巨著就退避三舍、逃之夭夭,面对任何技术只求快餐速成,学语言却从来不写程序,那就绝对没有成为高手乃至专家的一天。 有些人学习,自练就一身钢筋铁骨,可以在热带丛林中披荆斩棘,在莽莽草原中追奔逐北。有些人的学习,既未习惯大部头书,也为习惯严谨格调,更未习惯自修勤学,是温室里的一朵花,没有自立自强的本钱。
参考
https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/
https://zhuanlan.zhihu.com/p/25239682
http://spinningup.openai.com/en/latest/spinningup/rl_intro3.html
