

在《都2020年了你还不知道Svelte》这个系列里,我们将会介绍 Svelte 框架的基本用法、特性、优缺点、基本原理和源码分析。
目录
- 第一篇 👉 《都2020年了你还不知道Svelte(1)—— 初识Svelte》
- 第二篇 👉 《都2020年了你还不知道Svelte(2)—— 更新渲染原理》
- 第三篇 👉 《都2020年了你还不知道Svelte(3)—— 脏值检测、DOM更新》(未完待续)
- 第四篇 👉 《都2020年了你还不知道Svelte(4)—— 长列表处理》(未完待续)
- 第五篇 👉 《都2020年了你还不知道Svelte(5)—— 初探编译原理》(未完待续)
- 第六篇 👉 《都2020年了你还不知道Svelte(6)—— 实现一个Svelte 编译器》(未完待续)
相比于 Vue、React, Svelte 更新渲染过程非常简单,简单到,你只需要看完这篇就可以彻底的弄懂。
整体更新渲染流程
Svelte 是如何更新数据,渲染结果的呢?Svelte 整体的更新渲染流程是怎么样子的呢?
接下来,我们将编译一个最简单的例子,深入Svelte 的每一行源码。
例子的代码:
<main>
<div>
{name}
</div>
<button on:click={onClick}>click</button>
</main>
<script>
let name = 'hello'
function onClick() {
name = name + 's'
}
</script>
上面代码: 当点击按钮时,name 变量会更新,同时渲染到DOM节点上,那么这神奇的一切背后发生了什么?一共经历了哪些阶段?
我梳理了 Svelte 打包后代码的整体流程,发现还是比较简单的,用画图表示如下:
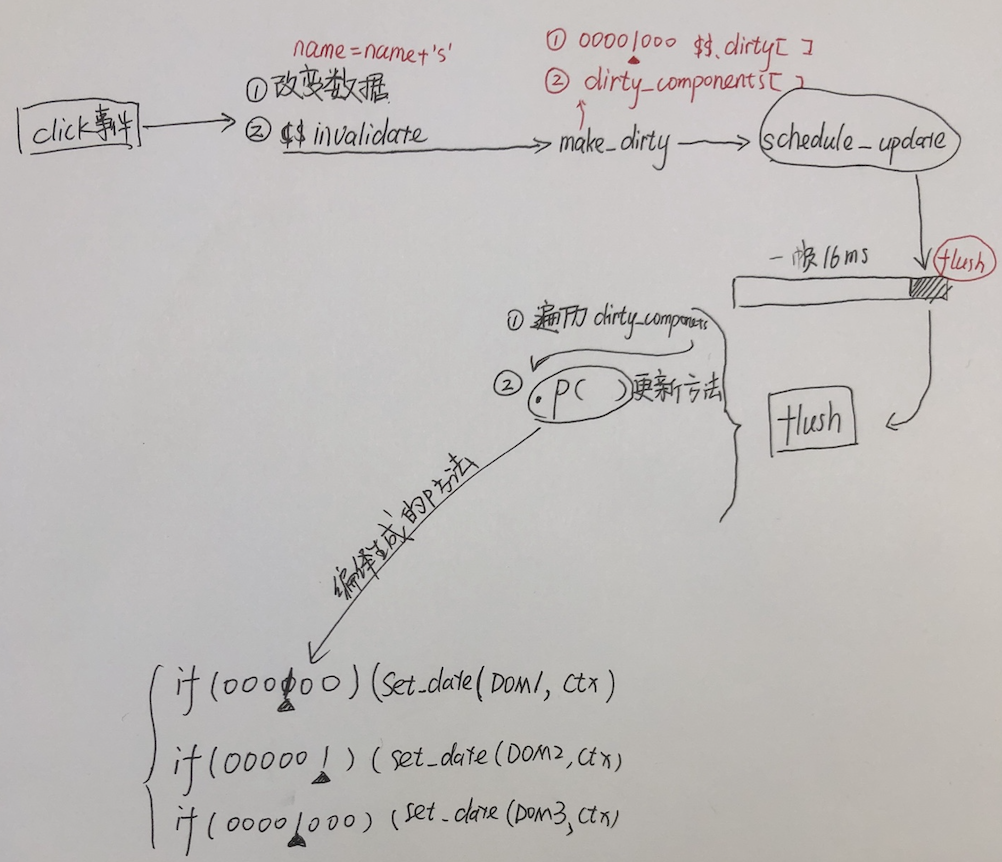
这里需要注意的是,虽然
svelte声称自己无运行时代码,但并不意味着,打包出来的产物完全不会加入其他代码。svelte还是会打包进去一些工具性的代码,相比于 react 和 vue, 代码体积还是会小很多。
-
click事件发生之后,会发生两件事情: 1. name 变量被修改:name=name + s2. 调用?invalidate方法。 -
?invalidate方法又调用了make_dirty方法,make_dirty是记住已经脏的数据,里面做了两件事情,比较复杂,后面会讲到。 -
数据弄脏之后,不是立马更新,而是
schedule_update()方法把flush回调推到16ms一帧的最后去执行。 -
flush被执行时,遍历所有的diry_components中的组件,调用他们的.p()方法。.p()方法是编译生成的,里面有一个神奇的 if 判断,如果走进判断体,则调用setData方法更新DOM节点
看上去一头雾水?没关系,只需要有一个大致的印象,下面会详细的介绍每一个过程
click 事件发生后
首先,我们在浏览器里面执行的并不是我们写的代码,而是 Svelte 编译修改之后的。
增加了一个instance 方法,如下:
function instance(?self, ?props, ?invalidate) {
let name = "hello";
let handleClick = () => {
?invalidate(0, name = name + "s");
};
return [name, handleClick];
}
handleClick 方法里面的逻辑被改写了,先是对 name 重新赋值(name = name + "s"),然后加入对 ?invalidate() 方法的调用。
?invalidate
?invalidate 方法也是编译生成,删掉其他无关紧要的逻辑之后,只剩下下面的逻辑:
function ?invalidate(i, value) {
make_dirty(component, i);
}
也就是调用 make_dirty() 方法
make_dirty
make_dirty 方法做了两件事情把当前组件弄脏: 1. 把当前的compoent 推到 dirty_components 数组中 2. 通过二进制的值来记录脏数据,目的是为了节省内存。
function make_dirty(component, i) {
// 如果 component.?.dirty[0]
if (component.?.dirty[0] === -1) {
// dirty_components 记录了,脏组件
dirty_components.push(component);
schedule_update();
component.?.dirty.fill(0);
}
// 下面代码的原理是,通过二进制的值来记录脏数据
// 不要尝试看懂,下面会讲
component.?.dirty[(i / 31) | 0] |= (1 << (i % 31));
}
之后,调用了 schedule_update()
schedule_update
schedule_update 的作用是,把一个 flush 的方法放到一个 Promise.then 里面:
function schedule_update() {
resolved_promise.then(flush);
}
背后其实是,让 flush 方法在这一帧的微任务被执行的时候执行
一帧 16ms 之内发生的任务的顺序
-
响应用户输入事件(scroll / click / key)
-
Javascript执行 -
requestAnimation/Intersection Observer cb -
布局 Layout
-
绘制 Paint
-
如果
16ms还有盈余,调用requestIdleCallback,若没有,会被饿死,通过第二个参数指定一个到时必处理 -
宏任务 (
setTimeout/MessageChannel.onMessage) -
微任务 (
Promise.then())
flush
flush 方法里面的逻辑是:遍历所有的diry_components 中的组件,调用update 方法,update 方法里面,最后调用了组件的 .p() 方法。 .p() 方法是编译生成的,
function flush() {
// 如果正在 flushing , 就退出
if (flushing) {
return;
}
flushing = true;
do {
for (let i = 0; i < dirty_components.length; i += 1) {
const component = dirty_components[i];
update(component.?);
}
flushing = false;
}
function update(?) {
// 先假设 ?.fragment 都不是 null
if (?.fragment !== null) {
?.update();
// ~~~~~~~~~~~~~~~ before_update 生命周期 ~~~~~~~~~~~~~~~
run_all(?.before_update);
const dirty = ?.dirty;
// 所有必须的 更新,必须要更新了,调用 p 方法
?.fragment && ?.fragment.p(?.ctx, dirty);
// ~~~~~~~~~~~~~ after_update 生命周期 ~~~~~~~~~~~~~~~
?.after_update.forEach(add_render_callback);
}
}
.p 方法
.p 方法核心功能,就是用最新的数据来更新DOM节点,大概长下面这样:
p(ctx, [dirty]) {
// & 是位运算
if (dirty & 1) {
// set_data 就是把 dom 节点的 data 值更新
set_data(t1, ctx[0])
};
if (dirty & 1) {
set_data(t3, ctx[0])
};
},
set_data 就是封装了 DOM 的原生方法(比如说 innerHtml),把 DOM 节点更新。
上面神奇的 if 判断,就是判断脏数据是否会影响到对应的DOM节点,如果是,则精准的更新那一个DOM节点。p 方法之所以知道更新哪一个DOM节点,是因为这个方法在编译的过程中,就通过 AST 等手段记录了 DATA 和 DOM 节点的对应关系, 下小节会详细介绍。
整体流程小节
你可能还是一头雾水,最大的困惑在于Svelte 是如何根据脏数据更新DOM节点的。为了彻底理解这块的逻辑,请务必要看下面这一小节。
Svelte 脏数据更新DOM 原理
任何一个现代前端框架,都需要记住哪些数据更新了,把更新了的数据视为脏数据,然后根据脏数据计算出最新的dom状态。
Svelte使用 位掩码(bitMask) 的技术来跟踪哪些值是脏的,即自组件最后一次更新以来,哪些数据发生了哪些更改。
位掩码是一种将多个布尔值存储在单个整数中的技术,一个比特位存放一个数据是否变化,一般1表示脏数据,0 表示是干净数据。
用大白话来讲,你有A、B、C、D 四个值,那么二进制0000 0001 表示第一个值A 发生了改变,0000 0010 表示第二个值 B 发生了改变,0000 0100 表示第三个值 C 发生了改变,0000 1000 表示第四个 D 发生了改变。
这种表示法,可以最大程度的利用空间。为啥这么说呢?
比如说,十进制数字3 就可以表示 A、B是脏数据。先把十进制数字3, 转变为二进制 0000 0011。
从左边数第一位、第二位是1,意味着第一个值A 和第二个值B是脏数据;其余位都是0,意味着其余数据都是干净的。
JS 的限制
但是,js 的二进制有31位限制(32位,减去1位用来存放符号)。
也就是说,如果 Svelte 采用二进制位存储的方法,那么只能在一个 Svelte 组件中存 31个数据。
但肯定不能这样,对吧?
Svelte 采用数组来存放,数组中一项是二进制31 位的比特位。假如超出31 个数据了,超出的部分放到数组中的下一项 。
这个数组就是 component.?.dirty 数组,二进制的1 位表示该对应的数据发生了变化,是脏数据,需要更新;二进制的0 位表示该对应的数据没有发生变化,是干净的。
一探究竟 component.?.dirty
上文中,我们说到 component.?.dirty 是数组,具体这个数组长什么样呢?
我们模拟一个 Svelte 组件,这个 Svelte 组件会修改33个数据。
我们打印出每一次make_dirty 之后的component.?.dirty , 如下面所示:
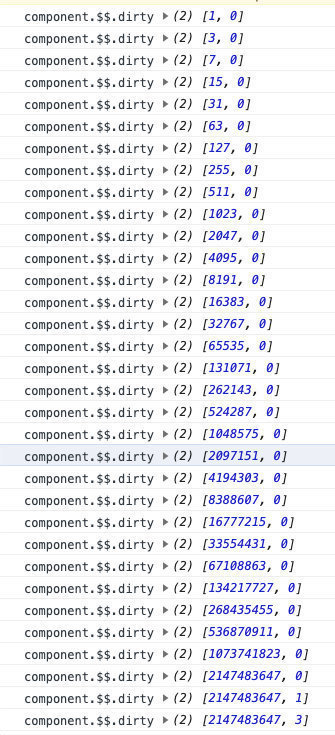
wtf ?? 看上去,根本找不出一些规律。
Svelte 正是用 component.?.dirty 的数组中看似无规律的数字来表示有哪些数据需要更新的。
如果我们把上面数组中的值,都十进制转为二进制来,再来观察一下:

上面数组中的每一项中的每一个比特位,如果是1,则代表着该数据是否是脏数据。如果是脏数据,则意味着更新。
-
第一行
["0000000000000000000000000000001", "0000000000000000000000000000000"], 表示第一个数据脏了,需要更新第一个数据对应的dom节点 -
第二行
["0000000000000000000000000000011", "0000000000000000000000000000000"], 表示第一个、第二个数据都脏了,需要更新第一个,第二个数据对应的dom节点。 -
……
当一个组件内,数据的个数,超出了31的数量限制,就数组新增一项来表示。
如何设置为脏数据
原理上,设置为脏数据,比较简单,就是把 component.?.dirty 数组二进制对应的比特位设置为1
如果你不想了解具体的代码, 下面这一小节《如何设置为脏数据》可以先不看,== 比较复杂。
只需要了解,设为脏数据,就是
component.?.dirty数组二进制对应的比特位设置为1svelte 作者通过一系列位操作符来做到这一点
实际上,这段逻辑对应的源码非常精炼和复杂,就下面一行代码:
component.?.dirty[(i / 31) | 0] |= (1 << (i % 31));
上面的代码是啥意思呢?把指定bit位上代表的记为脏数据
i 表示ctx中第几个变量, 1 表示第一个变量,2 表示第二个变量。
(i/31)|0 啥意思?
i/31 表示用 i 来除31, (i/31) |0 相当于是对(i/31)的结果取整。
如果你觉得很不好理解,可以简单的理解为 Math.floor(i/31) ,也就是对 i/31 的结果取整。
component.?.dirty[(i/31)|0] 啥意思 ?
component.?.dirty[(i / 31) | 0] 表示component.?.dirty 的第几项,也就是,i 对应的数组,落在component.?.dirty数组中哪一项。
还记得我们的component.?.dirty 变为二进制之后长什么样子吗?
// component.?.dirty
["0000000000000000000000000000001", "0000000000000000000000000000000"]
i如果超出了31个位数限制,会在component.?.dirty 数组中增加一项。
1 <<(i%31) 啥意思?
先讨论 << 的计算规则。 <<左移的规则就是转为二进制的每一位都向左移动一位,末尾补0。
比如说3 << 2 计算过程是,把 3 变成二级制后,所有位数左移2位。
下面是3 << 2 具体的计算过程:
3 的二进制表示为 0000 0011
所有位数左移2位变为 0000 1100
转变为十进制后为 12( 相当于 3 * 4, 也就是变大了 2 的2次方倍 )
可以这么理解,二级制后所有位数左移n位, 其效果相当于 << 左边数 ,会被放大2的n次方
假设 i 为 3 , 也就是ctx 中第三个数据发生了改变,1 << (3%31) 计算出的结果是 8, 转变为二进制后是 1000。
|= 啥意思?
Operator: x |= y
Meaning: x = x | y
|= 是按位或赋值运算符, 运算过程是使用两个操作数的二进制,对它们执行按位或运算,并将结果赋值给变量。
注意哦。
我们最初的代码是这样的:
component.?.dirty[(i / 31) | 0] |= (1 << (i % 31));
为了好理解,可以改写成下面这个样子:
let item = component.?.dirty[(i / 31) | 0]
item = item | (1 << (i % 31));
上文说过,假设 i 为 3, 1 << (i % 31) 计算为 8, 二进制表示为 0000000000000000000000000001000
假如 item 二进制表示为 0000000000000000000000000000001,| 按位或计算后,从右开始第4位设置为 1。
也就是说, 将指定的那一位位设置为1,无论其值之前是多少。
【如何设置为脏数据】小节
总之这一小节,你只需要了解到,svelte 作者通过一顿 js位操作符的操作, 把脏数据在 component.?.dirty 的二进制上对应的位置设置为1。
更新哪些DOM节点
上面一个小节,我们知道了, Svelte 会用 component.?.dirty 数组存储第几个是脏数据。
那么,有了脏数据之后,svelte就会在一帧16ms的微任务调用更新DOM节点的方法。更新DOM节点的方法,最终会调用一个p 方法 在 p 方法 被调用之前,svelte 并不知道要具体更新哪些dom节点。
p 方法的作用只有一个,就是判断出需要更新的dom节点,并且调用dom原生的方法更新之。
为了测试,我们模拟一个svelte 组件,这个svelte 组件会修改33个数据,通过svelte 提供的特别好的在线 repl 工具,可以方便的看到编译出来的产物,如下图所示:
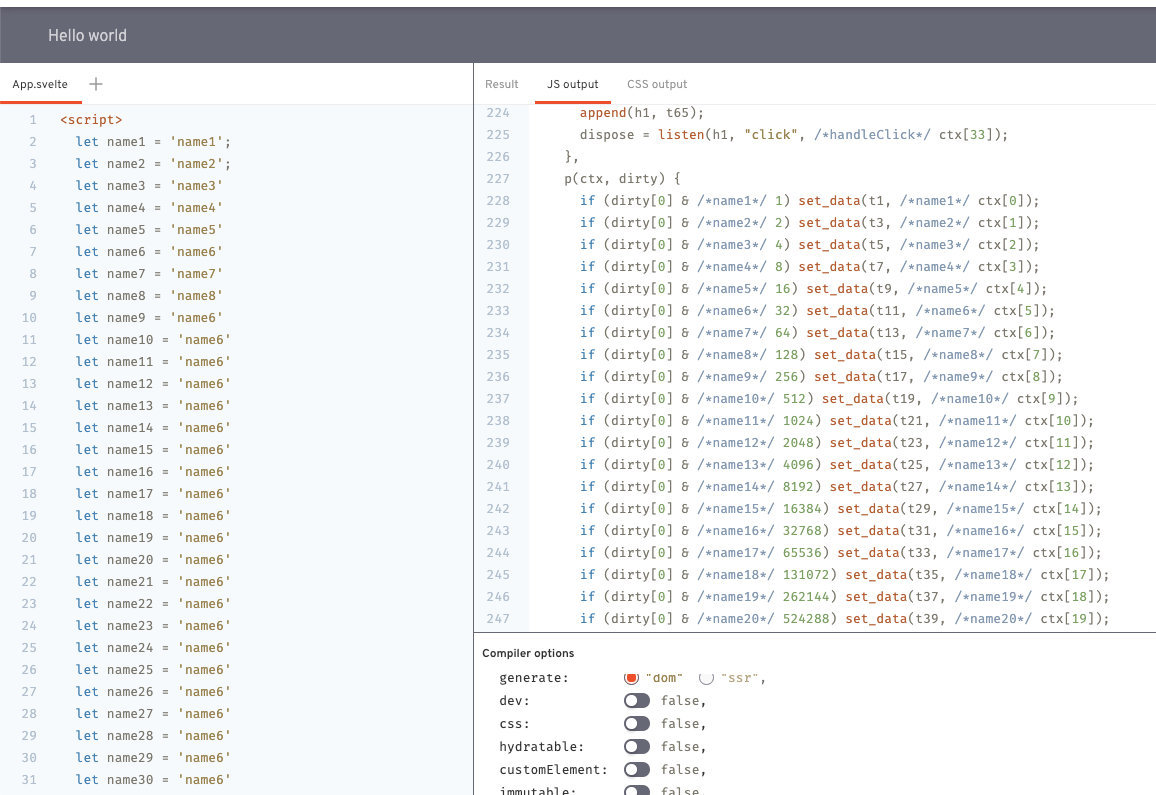
编译出来的p 方法如下,大概长这个样子, 因为我们没有开启代码压缩,所以看起来代码有很多:
p(ctx, dirty) {
if (dirty[0] & /*name1*/ 1) set_data(t1, /*name1*/ ctx[0]);
if (dirty[0] & /*name2*/ 2) set_data(t3, /*name2*/ ctx[1]);
if (dirty[0] & /*name3*/ 4) set_data(t5, /*name3*/ ctx[2]);
if (dirty[0] & /*name4*/ 8) set_data(t7, /*name4*/ ctx[3]);
if (dirty[0] & /*name5*/ 16) set_data(t9, /*name5*/ ctx[4]);
if (dirty[0] & /*name6*/ 32) set_data(t11, /*name6*/ ctx[5]);
if (dirty[0] & /*name7*/ 64) set_data(t13, /*name7*/ ctx[6]);
if (dirty[0] & /*name8*/ 128) set_data(t15, /*name8*/ ctx[7]);
if (dirty[0] & /*name9*/ 256) set_data(t17, /*name9*/ ctx[8]);
if (dirty[0] & /*name10*/ 512) set_data(t19, /*name10*/ ctx[9]);
if (dirty[0] & /*name11*/ 1024) set_data(t21, /*name11*/ ctx[10]);
if (dirty[0] & /*name12*/ 2048) set_data(t23, /*name12*/ ctx[11]);
if (dirty[0] & /*name13*/ 4096) set_data(t25, /*name13*/ ctx[12]);
if (dirty[0] & /*name14*/ 8192) set_data(t27, /*name14*/ ctx[13]);
if (dirty[0] & /*name15*/ 16384) set_data(t29, /*name15*/ ctx[14]);
if (dirty[0] & /*name16*/ 32768) set_data(t31, /*name16*/ ctx[15]);
if (dirty[0] & /*name17*/ 65536) set_data(t33, /*name17*/ ctx[16]);
if (dirty[0] & /*name18*/ 131072) set_data(t35, /*name18*/ ctx[17]);
if (dirty[0] & /*name19*/ 262144) set_data(t37, /*name19*/ ctx[18]);
if (dirty[0] & /*name20*/ 524288) set_data(t39, /*name20*/ ctx[19]);
if (dirty[0] & /*name21*/ 1048576) set_data(t41, /*name21*/ ctx[20]);
if (dirty[0] & /*name22*/ 2097152) set_data(t43, /*name22*/ ctx[21]);
if (dirty[0] & /*name23*/ 4194304) set_data(t45, /*name23*/ ctx[22]);
if (dirty[0] & /*name24*/ 8388608) set_data(t47, /*name24*/ ctx[23]);
if (dirty[0] & /*name25*/ 16777216) set_data(t49, /*name25*/ ctx[24]);
if (dirty[0] & /*name26*/ 33554432) set_data(t51, /*name26*/ ctx[25]);
if (dirty[0] & /*name27*/ 67108864) set_data(t53, /*name27*/ ctx[26]);
if (dirty[0] & /*name28*/ 134217728) set_data(t55, /*name28*/ ctx[27]);
if (dirty[0] & /*name29*/ 268435456) set_data(t57, /*name29*/ ctx[28]);
if (dirty[0] & /*name30*/ 536870912) set_data(t59, /*name30*/ ctx[29]);
if (dirty[0] & /*name31*/ 1073741824) set_data(t61, /*name31*/ ctx[30]);
if (dirty[1] & /*name32*/ 1) set_data(t63, /*name32*/ ctx[31]);
if (dirty[1] & /*name33*/ 2) set_data(t65, /*name33*/ ctx[32]);
}
我们一起来看,但其实一分析,发现这一坨代码很好理解:有 33 个if 判断,如果判断为true,就调用 setData。
上面代码中的 dirty 变量,其实就是component.?.dirty 数组,上文中我们介绍过了,回顾一下二进制大概长这个样子:
// dirty === component.?.dirty
["0000000000000000000000000000001", "0000000000000000000000000000000"]
上面代码中的 ctx 对象存放了数据,而且都是最新的数据:ctx[0] 表示第一个数据,ctx[1] 表示第二个数据……
上面代码中的set_data 方法,封装了更新 DOM 节点的原生方法,把ctx 中存放的最新的数据,更新到dom节点上。
还是一头雾水不要慌,我们拿上面代码里第4行举例子:
if (dirty[0] & /*name3*/ 4) set_data(t5, /*name3*/ ctx[2]);
if 判断值是 dirty[0] & 4 。dirty存放了哪些数据是脏数据,这里的4 看似是无规律的数字,转化为二进制之后变成了 0000 0100(从左到右第三位是 1), 也就是 表示第三个数据脏数据。
这里的 if 判断条件是:拿 dirty[0] ( 0000000000000000000000000000001)和4 (4 转变为二进制是 0000 0100)做按位并 操作。那么我们可以思考一下了,这个按位并 操作什么时候会返回 1 呢?
只有当4 转变为二进制是 0000 0100的第三位是 1 ,同时 dirty[0] 的二进制的第三位也是1 时, 才会返回 1。 换句话来说, dirty[0] 的二进制的第三位也是1 ,意味着第三个数据是脏数据。简单来说,只要第三个数据是脏数据,就会走入到这个if 判断中,执行 set_data(t5, /*name3*/ ctx[2]), 更新 t5 这个 DOM 节点。
当我们分析到这里,已经看出了一些眉目,让我们站在更高的一个层次去看待这 30多行代码: 它们其实是保存了这33个变量 和 真实DOM 节点之间的对应关系,哪些变量脏了,Svelte 会走入不同的if 体内直接更新对应的DOM节点,而不需要复杂 Virtual DOM DIFF 算出更新哪些DOM节点;
这 30多行代码,是Svelte 编译了我们写的Svelte 组件之后的产物,在Svelte 编译时,就已经分析好了,数据 和 DOM 节点之间的对应关系,在数据发生变化时,可以非常高效的来更新DOM节点
【更新哪些DOM节点】小节
一个前端框架,不管是vue还是 react 更新了数据之后,需要考虑更新哪个dom节点,也就是,需要知道,脏数据和待更新的真实dom之间的映射。
vue, react 是通过 virtualDom 来 diff 计算出更新哪些dom节点更划算。
而svelte dom 是把数据和真实dom之间的映射关系,在编译的时候就通过AST等算出来,保存在p 函数中。
至于,Svelte 的脏值检测、如何封装更新DOM的方法,将会在下一个小节介绍。
最后,字节跳动大量招人人人人!!
字节跳动(杭州|北京|上海)大量招人。福利超级棒,薪资水平秒BAT。上班不打卡、每天下午茶、免费零食无限供应、免费三餐(我念下菜单,大闸蟹鲍鱼扇贝海鲜烤鱼片黑椒牛柳咖喱牛肉麻辣小龙虾)。 免费健身房、入职配16寸顶配最新mbp、每月还有租房房补。 这次真的机会多多,年后研发人数要扩招n倍,技术氛围好,大牛多,加班少,还犹豫什么?快发简历到下方邮箱,就现在!
仅仅是一小部的JD, 更多的欢迎加微信~
前端部分JD
-
高级前端(北京)👉 job.toutiao.com/s/WXjEDn
-
前端跨端应用(北京)👉 job.toutiao.com/s/WXBG1s
-
前端实习生(北京)👉 job.toutiao.com/s/WXBqne
-
前端实习生(杭州)👉 job.toutiao.com/s/WXM4oX
-
高级前端(杭州)👉 job.toutiao.com/s/WXfj3x
-
高级前端(上海)👉 job.toutiao.com/s/WX88rF
JAVA 部分JD
- JAVA(北京)👉 job.toutiao.com/s/WX2wPC
持续招聘大量前端、服务端、客户端、测试、产品,实习社招都阔以
加微信 dujuncheng1,可以聊天聊地聊人生,请注明来自掘金以及要投递哪里的岗位

