

作者:Tom Hardy
Date:2020-2-18
公众号【3D视觉工坊】:主要关注3D视觉算法、SLAM、vSLAM、计算机视觉、深度学习、自动驾驶、图像处理以及技术干货分享
运营者和嘉宾介绍:运营者来自国内一线大厂的算法工程师,深研3D视觉、vSLAM、计算机视觉、点云处理、深度学习、自动驾驶、图像处理、三维重建等领域,特邀嘉宾包括国内外知名高校的博士硕士,旷视、商汤、百度、阿里等就职的算法大佬,欢迎一起交流学习
前言
三维数据通常可以用不同的格式表示,包括深度图像、点云、网格和体积网格。点云表示作为一种常用的表示格式,在三维空间中保留了原始的几何信息,不需要任何离散化。因此,它是许多场景理解相关应用(如自动驾驶和机器人)的首选表示。近年来,深度学习技术已成为计算机视觉、语音识别、自然语言处理、生物信息学等领域的研究热点,然而,三维点云的深度学习仍然面临着数据集规模小、维数高、非结构化等诸多挑战三维点云。在此基础上,本文对基于点云数据下的深度学习方法最新进展做了详解,内容包括三维形状分类、三维目标检测与跟踪、三维点云分割三大任务。
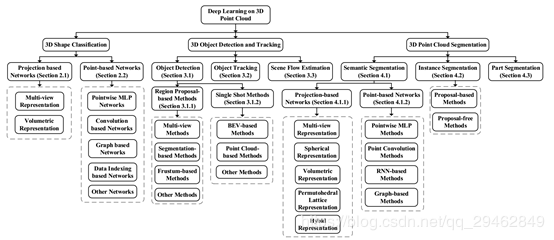
3D点云形状识别
这些方法通常先学习每个点的embedding,然后使用聚集方法从整个点云中提取全局形状embedding,最后通过几个完全连接的层来实现分类。基于在每个点上进行特征学习的方法,现有的3D形状分类可分为基于投影的网络和point-based的网络。基于投影的方法首先将一个非结构化点云投影到一个中间正则表示中,然后利用建立良好的二维或三维卷积来实现形状分类。相比之下,基于点的方法直接作用于原始点云,而无需任何体素化或投影。基于点的方法没有引入显式的信息丢失,并且越来越流行。
基于投影的方法
这些方法首先将三维物体投影到多个视图中,提取相应的视图特征,然后融合这些特征进行精确的物体识别。如何将多个视图特征聚合为一个有区别的全局表示是一个关键的挑战。该类方法主要包括:
- MVCNN
- MHBN
- Learning relationships for multi-view 3D object recognition
- Volumetric and multi-view CNNs for object classification on 3D data
- GVCNN: Groupview convolutional neural networks for 3D shape recognition
- Dominant set clustering and pooling for multi-view 3D object recognition
- Learning multi-view representation with LSTM for 3D shape recognition and retrieval
除此之外,还有一些对3D点云进行volumetric representation,主要包括:
- VoxNet
- 3D shapenets: A deep representation for volumetric shapes
- OctNet: Learning deep 3D representations at high resolutions
- OCNN: Octree-based convolutional neural networks for 3D shape analysis
- Pointgrid: A deep network for 3d shape understanding
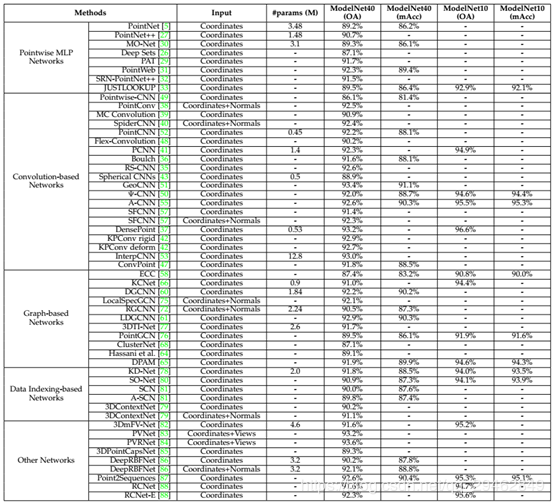
Point-based网络
根据用于每个点特征学习的网络体系结构,该类方法可分为逐点MLP、卷积方式、基于Graph、基于数据索引的网络和其他典型网络。网络汇总如下表所示:
3D点云目标检测与跟踪
3D目标检测
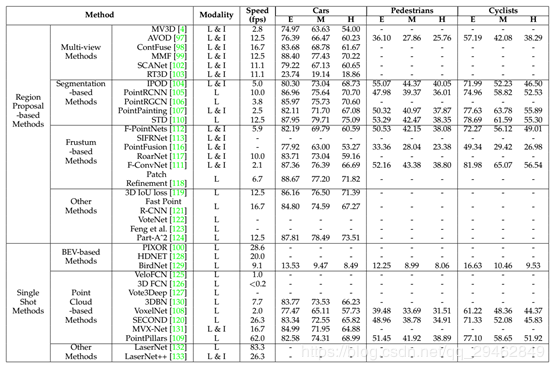
三维目标检测的任务是精确地定位给定场景中所有感兴趣的目标。类似于图像中的目标检测,三维目标检测方法可以分为两类:region proposal-based methods 和 single shot methods。
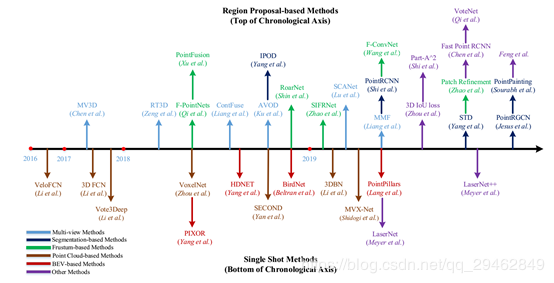
针对region proposal-based methods:这些方法首先提出几个可能包含对象的区域(也称为proposal),然后提取区域特征来确定每个proposal的类别标签。根据它们的proposal生成方法,这些方法可以进一步分为三类:基于多视图的方法、基于分割的方法和基于frustum的方法。
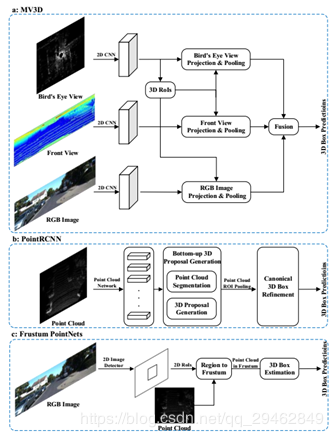
针对single shot methods:这些方法直接预测类别概率,并使用单级网络回归物体的三维bounding box。这些方法不需要region proposal和后处理。因此,它们可以高速运行,非常适合实时应用。根据输入数据的类型,又可以分为两类:基于BEV(投影图)的方法和基于点云的方法。
两种方式的网络汇总:
3D目标跟踪
给定对象在第一帧中的位置,对象跟踪的任务是估计其在随后帧中的状态。由于三维目标跟踪可以利用点云中丰富的几何信息,因此有望克服二维图像跟踪所面临的遮挡、光照和尺度变化等缺点。 主要方法包括:
- Leveraging shape completion for 3D siamese tracking
- Context-aware correlation filter tracking
- Efficient tracking proposals using 2D-3D siamese networks on lidar
- Complexer-YOLO: Real-time 3D object detection and tracking on semantic point clouds
除了上述方式,还有一些基于光流思想的跟踪算法。类似于二维视觉中的光流估计,已有多种方法开始从点云序列中学习有用信息(如三维场景流、空间临时信息),主要包括:
- Flownet3D: Learning scene flow in 3D point clouds
- FlowNet3D++: Geometric losses for deep scene flow estimation
- HPLFlowNet: Hierarchical permutohedral lattice flownet for scene flow estimation on large-scale point clouds
- PointRNN: Point recurrent neural network for moving point cloud processing
- MeteorNet: Deep learning on dynamic 3D point cloud sequences Just go with the flow: Self-supervised scene flow estimation
3D点云分割
三维点云分割需要了解全局几何结构和每个点的细粒度细节。根据分割粒度,三维点云分割方法可分为三类:语义分割(场景级)、实例分割(对象级)和部件分割(部件级)。
语义分割
语义分割是基于场景级别,主要包括基于投影和基于点的方法。
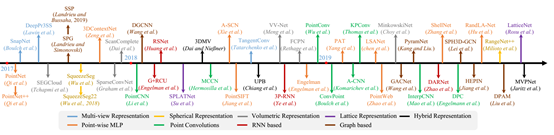
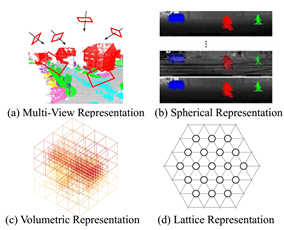
针对投影方式的分割算法:主要包括Multi-view Representation、Spherical Representation、Volumetric Representation、Permutohedral Lattice Representation、Hybrid Representation五种方式,下图对近期的分割网络进行了汇总:
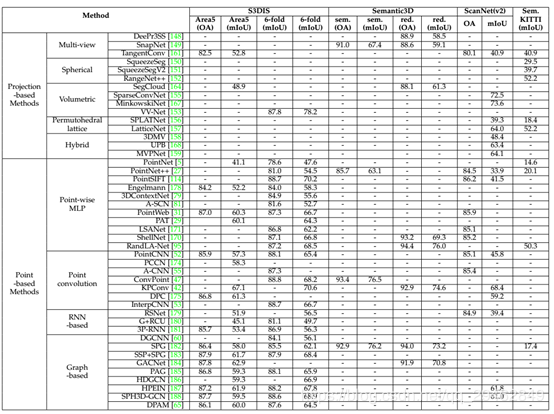
针对基于point方式的分割算法:基于点的网络直接作用于不规则点云。然而,点云是无秩序的、非结构化的,直接应用标准CNN是不可行的。为此,提出了开创性的PointNet来学习使用共享MLP的逐点特征和使用对称池函数的全局特征。基于该思想,后期的方法大致可以分为点MLP方法、点卷积方法、基于RNN的方法和基于图的方法。针对近期point-based分割网络,下表进行了详细的汇总:
实例分割
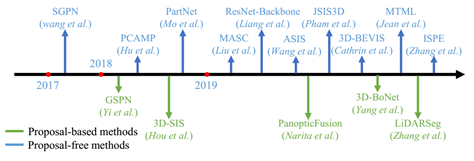
与语义分割相比,实例分割更具挑战性,因为它需要对点进行更精确、更精细的推理。特别是,它不仅要区分语义不同的点,而且要区分语义相同的实例。总的来说,现有的方法可以分为两类: 基于proposal的方法和proposal-free的方法。
基于proposal的方式将实例分割问题转化为两个子任务:三维目标检测和实例掩码预测。而基于proposal-free的方式没有对象检测模块,相反,这类方法通常将实例分割视为语义分割之后的后续聚类步骤。特别地,大多数现有的方法是基于假设属于相同实例的点应该具有非常相似的特征。因此,这些方法主要集中在鉴别特征学习和点分组两个方面。两种方式的网络汇总如下所示:
部件分割(Part Segmentation)
三维形状的部件分割有两个难点。首先,具有相同语义标签的形状零件具有较大的几何变化和模糊性。其次,该方法对噪声和采样应该具有鲁棒性。现有算法主要包括:
- VoxSegNet: Volumetric CNNs for semantic part segmentation of 3D shapes
- 3D shape segmentation with projective convolutional networks
- SyncSpecCNN: Synchronized spectral CNN for 3D shape segmentation
- 3D shape segmentation via shape fully convolutional networks
- CoSegNet: Deep co-segmentation of 3D shapes with group consistency loss
