

代码分割 Code Splitting
在最开始的时候,webpack都是将所有的代码打包到一个文件中,但是当项目过大的时候,页面所需要加载的时间就会变长,这个时候我们就需要Code Splitting对文件进行分块,实现代码的按需加载。
接下来我们来看看下面两种方式:
当用第一种方式的时候, 我们需要等打包文件加载完成之后,才会去实现文件里面的逻辑,再将页面展示出来。那么这样带来的问题是什么呢,有一个问题想必大家都很清楚,那就是打包文件很大,加载时间很长。
那还有一个问题是什么呢,我们都知道,lodash是一个第三方库,我们不会随便去修改它,但是业务逻辑是经常会被改变的。假设我们修改了业务代码,那我们就需要重新去加载打包中的js文件,才能获取到最新的代码,显示最新的内容。因为业务代码和第三方库都在同一个文件中,所以lodash相应的也要被重新加载。
index.js
// 同步逻辑
// 第一种方式
// 首次访问页面的时候, 加载main.js 2mb
// 当业务逻辑发生变化时 又要加载main.js 2mb的内容
import _ from 'lodash' //假设1mb
// 业务逻辑 1mb
console.log(_.join(['a','d','c'], "***"));
// 中间省略几千行代码....
console.log(_.join(['a','b','c'], "***"));
第二种方式我们将上面代码拆分成了两个文件main.js和lodash.js,我们将不需要修改的第三方库拎出来放在一个单独的文件中,当页面业务逻辑发生变化的时候,只需要加载main.js页面就可以了。
这种动态加载的方式就能提升我们页面展示的速度,相应的也提高了性能。
index.js
// 第二种方式
// main.js被拆成lodash.js(1Mb), main.js(1mb)
// 当业务逻辑发生变化时,只要加载main.js即可(1MB)
// 业务逻辑 1mb
console.log(_.join(['a','d','c'], "***"));
console.log(_.join(['a','b','c'], "***"));
lodash.js
// 加载了lodash,然后将lodash挂载到了全局上面
import _ from 'lodash'; //1mb
window._ = _
webpack插件帮助代码自动拆分
Code Splitting其实本质上是和webpack没有任何关系的,但为什么只要一说到webpack,我们在很多时候都能听到webpack里面有Code Splitting呢?这是因为webpack里面有一些插件可以非常容易的帮助我们实现Code Splitting。
在webpack4里面有一个插件splitChunksPlugin,这个插件直接与webpack做了捆绑,不需要安装,直接就可以拿来用了。这样的话我们进行代码分割就非常容易了。
同步代码分割
我们先将之前的lodash.js和index.js合并,然后我们在webpack.config.js里面配置一个optimization:
optimization: {
splitChunks: {
chunks: 'all'
}
}
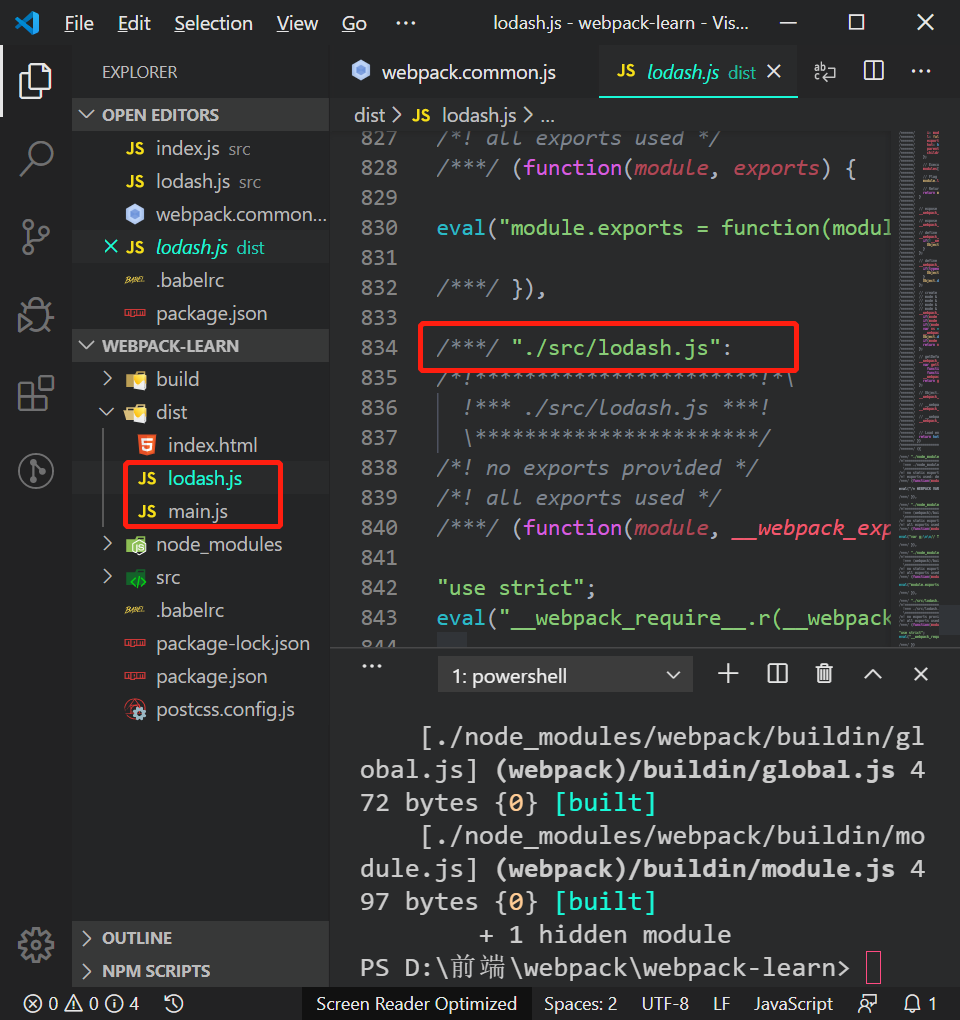
我们重新对代码进行打包,查看dist目录:
我们能看见,只要做一个非常简单的配置,就能实现代码分割,完全不需要我们再手动进行文件的拆分。
异步代码的分割
上面我们说的是同步加载。那么接下来我们看看异步加载吧!
// 异步加载lodash
function getComponent() {
return import('lodash').then(({default: _}) => {
const element = document.createElement('div')
element.innerHTML = _.join(["linna", "mao"], '-')
})
}
getComponent().then(element => {
document.body.appendChild(element)
})
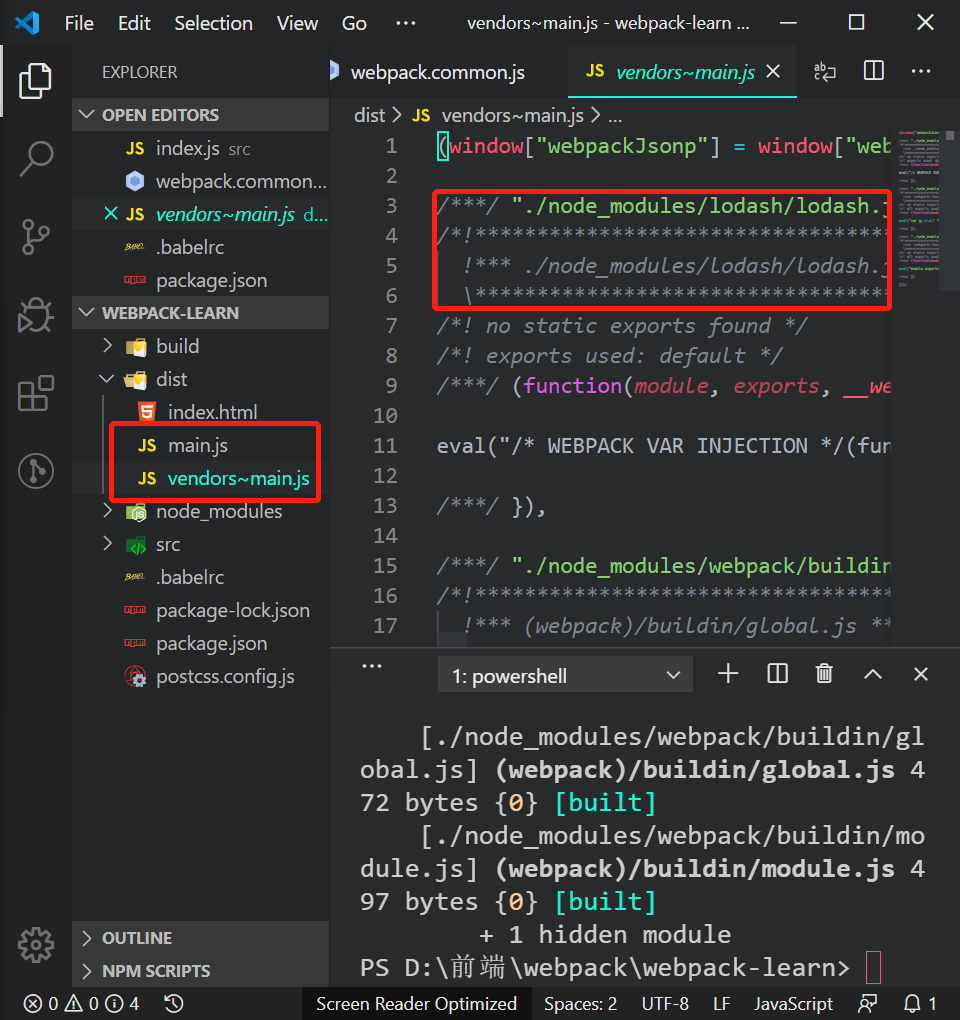
如果大家实践过的话,就知道即便我们不在webpack.config.js中配置optimization,异步载入的组件也会自动打包再一个单独的文件中。
SplitChunksPlugin配置详解
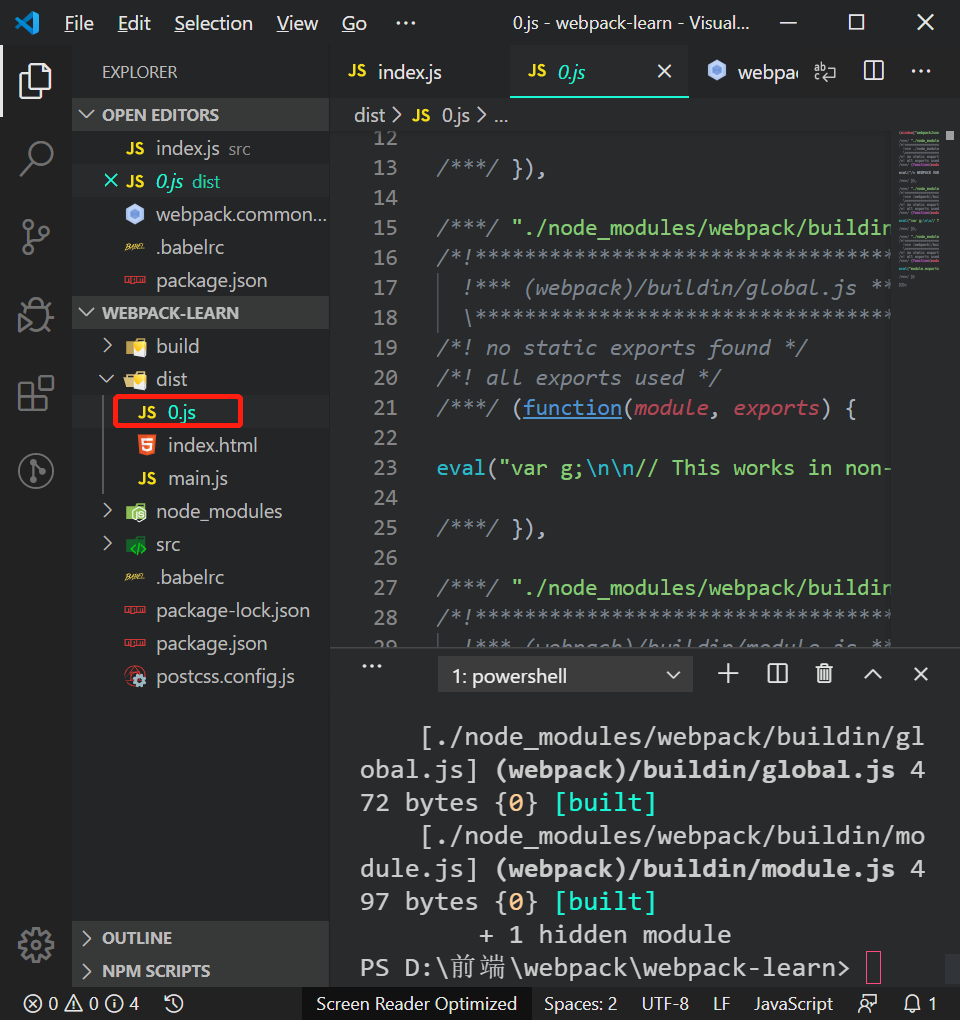
从上图中我们可以看到,异步代码分割中,dist目录中打包生成的文件是一个0.js,这个0是Code Splitting产生的一个id的值。
如果我们想要将它改成我们可以识别的名字,我们就可以在上面异步代码的第一个参数前面添加/*webpackChunkName:"lodash"*/,这个是在异步加载组件中存在的一个magic comment(语法注释)。
magic comment只能在官方动态加载组件的插件使用
//详细代码看异步代码中的index.js
return import(/*webpackChunkName:"lodash"*/'lodash').then(({default: _})
打包后我们可以看到vendors~lodash.js,那么为什么会在lodash前面添加vendors呢?这里我们就需要去看我们的配置了,官方文件中在optimization中会有一个默认配置
splitChunks: {
chunks: "async",
minSize: 30000,
minChunks: 1,
maxAsyncRequests: 5,
maxInitialRequests: 3,
automaticNameDelimiter: '~',
name: true,
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10
},
default: {
priority: -20,
reuseExistingChunk: true
}
}
}
其中:
更多详解参考官网split-chunks-plugin
- chunks:默认配置
aysnc的意思是对异步代码进行分割,这就是为什么在之前代码中异步代码分割不需要进行配置的原因。 - minSize:引入的模块的大小大于30000才能进行代码分割。
- minChunks:当模块被引用了至少1次的时候进行代码分割。
- maxAsyncRequests:同时加载的模块数最多是5个。如果加载模块超出了五个,那就加载前五个,后面的就不会再进行代码分割了。
- maxInitialRequests:入口文件引入的库最多能分割成3个代码文件。
- automaticNameDelimiter:文件生成时候,组和文件名之间的连接,就像之前我们说到的
vendors~lodash.js。 - name: 默认为true,打包生成的文件,取名的时候让
cacheGroup里的名字有效。 - cacheGroup: 相当一个缓存组。
- 当引入的模块在
node_modules中的时候,符合vendors,就会在分割文件中添加前缀vendors,当有多个node_modules模块时候,就会将所有引用模块先进行缓存,最后的时候一起打包成vendors文件。 - 当
index.js引入一个自己写的js文件,它就找到cacheGroup,不符合vendors的时候,就会进入default中,这个时候打包文件的前缀就会有default。 - priority:
default中所有的模块都是符合的,当一个模块既符合vendors又符合default的时候,那么priority的值越大,优先级越高。 - reuseExistingChunk: 如果一个模块已经被打包过,再打包的时候就会忽略这个模块,直接使用之前被打包过的模块。
- 当引入的模块在
注:此文为本人学习过程中的笔记记录,如果有错误或者不准确的地方请大佬多多指教~
