

4.3 浏览器外:使用Node.js更快地训练模型
在上一节中,我们在浏览器中训练了一个convnet,它达到了99.0%的测试准确性。在本节中,我们将创建一个功能更强大的卷积网络,该卷积网络将为我们提供更高的测试准确性,约为99.5%。但是,提高准确性是要付出代价的:模型在训练和推理期间消耗了大量的内存和计算量。在训练过程中,成本的增加更为明显,因为训练涉及反向传播,与推理所需的正向运行相比,反向传播的计算量更大。在大多数Web浏览器环境中,较大的convnet太重且太慢而无法训练。
4.3.1 使用tfjs-node的依赖项并导入
进入TensorFlow.js的Node.js版本!它在后端环境中运行,不受任何资源限制(如浏览器选项卡的限制)影响。TensorFlow的Node.js的CPU版本(以下简称tfjs-node )直接使用以C ++编写并由TensorFlow的主要Python版本使用的多线程数学运算。如果您的计算机上安装了支持CUDA的GPU,则tfjs-node也可以使用以CUDA编写的GPU加速的数学内核,从而获得更大的速度提升。
增强型MNIST卷积网络的代码位于tfjs-examples的mnist-node目录中。如我们在示例中看到的,您可以使用以下命令来访问代码:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples / mnist-node
与前面的示例的不同之处在于mnist-node示例将在终端而不是Web浏览器中运行。要下载依赖项,请使用命令yarn。
在package.json文件中可以看到依赖项@ tensorflow / tfjs-node。将@ tensorflow / tfjs-node声明为依赖项后,yarn会自动将C ++共享库(在Linux,Mac或Windows系统上分别名为libtensorflow.so,libtensorflw.dylib或libtensorflow.dll)下载到node_modules目录中供TensorFlow.js使用。
一旦yarn命令运行完毕,您可以使用以下命令开始模型训练:
node main.js
已经安装了yarn后,node二进制文件在您的文件路径上可用(如果需要更多信息,请参阅附录A3)。 上面的工作流程将使您能够在CPU上训练增强型convnet。如果您的工作站和笔记本电脑内部具有启用CUDA的GPU,您还可以在GPU上训练模型。涉及的步骤是:
- 为您的GPU安装正确版本的NVIDIA驱动程序
- 安装NVIDIA CUDA工具包。该库可在NVIDIA GPU系列上实现通用并行计算。
- 安装CuDNN,这是NVIDIA基于CUDA构建的用于高性能深度学习算法的库(有关步骤1-3的更多详细信息,请参阅附录A3)
- 在package.json中,将@ tensorflow / tfjs-node依赖项替换为@ tensorflow / tfjs-node-gpu,但保持相同的版本号,因为这两个软件包同步发布。
- 再次运行yarn,将下载共享库,其中包含供TensorFlow.js使用的CUDA数学运算。
- 在main.js中,用require('@tensorflow/tfjs-node-gpu')替换require('@tensorflow/tfjs-node');
- 再次开始训练node main.js 如果正确完成了这些步骤,则您的模型将在CUDA GPU上运行,其训练速度通常是CPU版本(tfjs-node)可获得的速度的五倍。与在浏览器中训练相同模型相比,使用tfjs-node的CPU或GPU版本进行训练要快得多。
4.3.2 在tfjs-node中为MNIST训练增强的convnet
一旦训练在20个时期内完成,该模型应显示出约99.6%的最终测试(即评估)准确性,这优于我们在第4.2节中结果的99.0%。那么,这种基于node的模型与基于浏览器的模型之间的区别是什么,为什么导致准确性的提高?如果您使用数据训练数据在tfjs-node和浏览器版本TensorFlow.js中训练相同的模型,则应该获得相同的结果(效果或随机权重初始化除外)。要回答此问题,让我们看一下基于node的模型的定义。该模型在文件model.js中构建,该文件由main.js导入。
代码4.5 在Node.js中为MNIST定义更大的convnet
const model = tf.sequential();
model.add(tf.layers.conv2d({
inputShape: [28, 28, 1],
filters: 32,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.conv2d({
filters: 32,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2]}));
model.add(tf.layers.conv2d({
filters: 64,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.conv2d({
filters: 64,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2]}));
model.add(tf.layers.flatten());
model.add(tf.layers.dropout({rate: 0.25}));
model.add(tf.layers.dense({units: 512, activation: 'relu'}));
model.add(tf.layers.dropout({rate: 0.5}));
model.add(tf.layers.dense({units: 10, activation: 'softmax'}));
model.summary();
model.compile({
optimizer: 'rmsprop',
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
该模型的摘要如下:
_________________________________________________________________
Layer (type) Output shape Param #
=================================================================
conv2d_Conv2D1 (Conv2D) [null,26,26,32] 320
_________________________________________________________________
conv2d_Conv2D2 (Conv2D) [null,24,24,32] 9248
_________________________________________________________________
max_pooling2d_MaxPooling2D1 [null,12,12,32] 0
_________________________________________________________________
conv2d_Conv2D3 (Conv2D) [null,10,10,64] 18496
_________________________________________________________________
conv2d_Conv2D4 (Conv2D) [null,8,8,64] 36928
_________________________________________________________________
max_pooling2d_MaxPooling2D2 [null,4,4,64] 0
_________________________________________________________________
flatten_Flatten1 (Flatten) [null,1024] 0
_________________________________________________________________
dropout_Dropout1 (Dropout) [null,1024] 0
_________________________________________________________________
dense_Dense1 (Dense) [null,512] 524800
_________________________________________________________________
dropout_Dropout2 (Dropout) [null,512] 0
_________________________________________________________________
dense_Dense2 (Dense) [null,10] 5130
=================================================================
Total params: 594922
Trainable params: 594922
Non-trainable params: 0
_________________________________________________________________
我们的tfjs-node模型和基于浏览器的模型之间的主要区别是:
- 基于node的模型具有四个conv2d层,比基于浏览器的模型多一层
- 与基于浏览器的模型(100)中的对应层相比,基于node的模型中的隐藏密集层具有更多的单元(512)。
- 总体而言,基于node的模型的权重参数约为基于浏览器的模型的18倍
- 基于node的模型在扁平层和稠密层之间插入了两个dropout层
上面列出的差异1-3使基于node的模型比基于浏览器的模型具有更高的容量。它们也使基于node的模型过于占用内存和计算量,无法在浏览器中进行训练。正如我们在第3章了解到的那样,更大的模型容量会带来更大的过度拟合风险。差异4(即包含dropout层)可以缓解过度拟合的风险。
利用dropout层减少过度拟合
Dropout层是您在本章中遇到的另一个新的TensorFlow.js图层类型。这是减少深度神经网络过度拟合的最有效且广泛使用的方法之一。其功能可以简单描述:
- 在训练阶段(即Model.fit()调用期间),它将输入张量中元素的一部分随机设置为零(即“丢弃”),结果便是输出张量。就本示例而言,丢弃层仅具有一个配置参数:丢弃率(例如,代码清单4.5中所示的两个rate字段)。例如,假设将丢弃层配置为具有0.25的丢弃率,输入张量是值为[0.7,-0.3、0.8,-0.4]的一维张量,则输出张量可以为[0.7,-0.3、0.0 ,例如0.4],即随机选择了输入张量的25%并将其设置为值0。在反向传播期间,此随机置零会类似地影响丢弃层上的梯度张量。
- 在推理期间(即Model.predict()和Model.evaluate调用),丢弃层不会随机在张量输入元素进行至零。取而代之的,输入只是为输出进行传递而没有更改(即映射)。
下面的图4.11展示了一个带有2D输入张量的丢弃层在训练和测试时是如何工作的。
图4.11 丢弃层的工作方式示意图。在此示例中,输入张量为2D,形状为[4,2]。丢弃层的rate配置为0.25,这导致在训练阶段随机选择输入张量的25%(即八分之二)并将其设置为零。在推断阶段,该层充当普通的直通层。
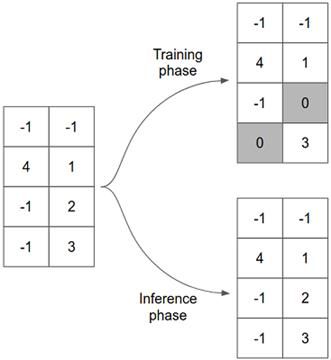
如此简单的算法是解决过度拟合的最有效方法之一,这似乎很奇怪。为什么行得通?丢弃算法(神经网络算法中的一种)的发明者Geoff Hinton说,他受到一些银行用来防止员工欺诈机制的启发。用他自己的话说:
“我去了银行。出纳员不断变化,我问其中一个为什么。他说他不知道,但是他们四处走动。我认为这一定是因为需要员工之间的合作才能成功欺骗银行。这使我意识到,在每个示例中随机删除神经元的不同子集将防止串谋,从而减少过度拟合。”
为了将其纳入深度学习的术语中,在层的输出值中引入噪声会破坏偶然性模式,这种偶然性模式对于数据的真实模式而言并不重要(Hinton称为“阴谋”)。在本章结尾的练习3中,您应该尝试从model.js中基于node的convnet中删除两个丢弃层,再次训练模型,并查看其训练,验证和评估精度如何发生变化。
下面的代码清单4.6显示了我们用来训练和评估增强型convnet的关键代码。如果将此处的代码与清单4.2中的代码进行比较,则可以理解两个代码块之间的相似性。两者均以Model.fit()和Model.evaluate()调用为中心。语法和样式相同,不同之处在于如何在不同的用户界面(即终端与浏览器)上呈现或显示损耗值,准确性值和训练进度。
这显示了TensorFlow.js的重要功能,TensorFlow.js是一个跨越前端和后端的JavaScript深度学习框架: 就模型的创建和训练而言,无论您是使用Web浏览器还是使用Node.js,在TensorFlow.js中编写的代码都是相同的。
代码4.6 在tfjs-node中训练和评估增强convnet
await model.fit(trainImages, trainLabels, {
epochs,
batchSize,
validationSplit
});
const {images: testImages, labels: testLabels} = data.getTestData();
const evalOutput = model.evaluate(testImages, testLabels);
console.log('\nEvaluation result:');
console.log(
` Loss = ${evalOutput[0].dataSync()[0].toFixed(3)}; `+
`Accuracy = ${evalOutput[1].dataSync()[0].toFixed(3)}`);
4.3.3从Node.js保存模型并在浏览器中加载模型
训练模型会消耗CPU和GPU资源,并且需要一些时间。您不想丢掉训练的果实。如果不保存模型,则下次运行main.js时必须从头开始。本节显示了训练后如何保存模型以及如何将保存的模型导出为磁盘上的文件(称为“检查点”或“工件”)。我们还将展示如何在浏览器中导入检查点,将其重构为模型并将其用于推理。
main.js中main()函数的最后一部分由节省模型的代码组成:
代码4.7 将训练好的模型保存到tfjs-node的文件系统中。
if (modelSavePath != null) {
await model.save(`file://${modelSavePath}`);
console.log(`Saved model to path: ${modelSavePath}`);
}
文件系统上的目录。该方法采用单个参数,该参数是以方案file:// 开头的URL字符串。注意,因为我们使用的是tfjs-node,所以可以将模型保存在文件系统上。TensorFlow.js的浏览器版本还提供了model.save()API,但无法直接访问机器的本机文件系统,因为出于安全原因,浏览器禁止这样做。如果我们在浏览器中使用TensorFlow.js,则必须使用非文件系统保存目标(例如浏览器的本地存储和IndexedDB)。这些对应于file:// 以外的URL方案。
model.save()是一个异步函数,因为它通常涉及文件或网络IO。因此,我们在save()调用中使用了await。假设modelSavePath的值为/ tmp / tfjs-node-mnist,在model.save()调用完成之后,您可以检查目录的内容:
ls -lh / tmp / tfjs-node-mnist
可能会打印如下文件列表:
-rw-r--r-- 1 user group 4.6K Aug 14 10:38 model.json
-rw-r--r-- 1 user group 2.3M Aug 14 10:38 weights.bin
在那里,您可以看到两个文件:
- model.json是一个JSON文件,其中包含已保存的模型拓扑。这里所谓的“拓扑”包括组成模型的层的类型,它们各自的配置参数(例如,用于conv2d层的过滤器和用于丢弃层的速率),以及各层连接彼此的方式。对于MNIST卷积网络而言,连接很简单,因为它是一个顺序模型。连接模式较少的模型,也可以使用model.save()将其保存到磁盘。 除了模型拓扑外,model.json还包含模型权重的清单。该部分列出了模型所有权重的名称,形状和数据类型,以及存储权重值的位置。这将我们带到第二个文件:weights.bin。
- 顾名思义,weights.bin是一个二进制文件,用于存储模型的所有权重值。它是平坦的二进制流,没有划分各个权重的开始和结束位置。该“元信息”在model.json中的JSON对象的权重清单部分中可用。
要使用tfjs-node加载模型,可以使用tf.loadLayersModel()方法,指向model.json文件的位置(示例代码中未显示)
const loadedModel = await tf.loadLayersModel('file:///tmp/tfjs-node-mnist');
tf.loadLayersModel()通过反序列化model.json中保存的拓扑数据来重构模型。然后,tf.loadLayersModel()使用model.json中的清单读取weights.bin 中的二进制权重值,并将模型的权重强制设置为这些值。
像model.save()一样,tf.loadLayersModel()是异步的,因此我们在此处调用await。一旦调用返回,从所有意图和目的来看,loadedModel对象等效于使用清单4.5和4.6中的JavaScript代码创建和训练的模型。您可以通过调用其summary()方法来打印该模型的效果,通过调用其predict()方法来使用其执行推理,通过使用validate()方法来评估其准确性,甚至可以使用fit()方法对其进行重新训练。如果需要,还可以再次保存模型。当我们在第5章中讨论转移学习时,重新训练和保存已加载模型的工作流程将很重要。
上一段中所说的内容也适用于浏览器环境。您保存的文件可用于重构网页中的模型。重构后的模型支持完整的tf.LayersModel工作流程,但需要注意的是,如果您重新训练整个模型,由于增强的卷积网络很大,因此它将特别缓慢且效率低下。在tfjs-node和浏览器中加载模型之间唯一的根本不同是,在浏览器中应使用file://以外的URL方案。通常,您可以将model.json和weights.bin文件作为静态资产文件放置在HTTP服务器上。假设您的主机名是localhost,并且文件在服务器路径my / models /下显示;您可以使用以下行在浏览器中加载模型:
const loadedModel =await tf.loadLayersModel('http:///localhost/my/models/model.json');
在浏览器中处理基于HTTP的模型加载时,tf.loadLayersModel()在后台调用浏览器的内置访存函数。因此,它具有以下功能和特性:
- 同时支持http:#和https:#。
- 支持相对服务器路径。实际上,如果使用相对路径,则可以省略URL的http://或https://部分。例如,如果您的网页位于服务器路径my / index.html上,而模型的JSON文件位于my / models / model.json上,则可以使用相对路径model / model.json,即
const loadedModel = await tf.loadLayersModel('models/model.json');
- 要为HTTP / HTTPS请求指定其他选项,应使用tf.io.browserHTTPRequest()方法代替字符串参数。例如,要在模型加载期间包括凭证和标头,可以执行以下操作:
const loadedModel = await tf.loadLayersModel(tf.io.browserHTTPRequest(
'http://foo.bar/path/to/model.json',
{credentials: 'include', headers: {'key_1': 'value_1'}}));
4.4 语音识别:在音频数据上应用卷积
到目前为止,我们已经展示了如何使用卷积网络执行计算机视觉任务。但是人类的感知不仅仅是视觉。音频是感知数据的重要形式,可以通过浏览器API进行访问。如何识别语音和其他声音的内容和含义?值得注意的是,卷积不仅可用于计算机视觉,而且还可以极大地帮助与音频相关的机器学习。
在本章中,您将看到如何使用类似于为MNIST构建的convnet来解决相对简单的音频任务。任务是将语音录音的简短片段分类为20个左右的单词类别。该任务比您在诸如Amazon Echo和Google Home之类的设备中可能看到的那种语音识别更为简单。这些语音识别系统比本示例中使用的词汇量更大的词汇量。同样,他们处理由多个连续发音的单词组成的连接语音,而我们的示例处理一次发音的单词。因此,我们的示例没有资格作为“语音识别器”,而是更准确地描述为“单词识别器”或“语音命令识别器”。但是,我们的示例仍然具有实际用途(例如,免提用户界面和可访问性功能)。同样,此示例中体现的深度学习技术实际上构成了更高级的语音识别系统的基础[70]。
4.4.1 频谱图:将声音表示为图像
像在任何深度学习应用程序中一样,如果您想了解模型的工作原理,则需要首先了解数据。要了解音频卷积网络是如何工作的,我们首先需要看一下如何将声音表示为张量。回忆高中物理时,声音是气压变化的模式。麦克风拾取气压变化并将其转换为电信号,然后可以通过计算机的声卡将其数字化。现代的Web浏览器具有WebAudio API,该API与声卡对话并提供对数字化音频信号的实时访问(在用户许可的情况下)。因此,从JavaScript程序员的角度来看,声音是实数值数组。在深度学习中,此类数字数组通常表示为一维张量。
一些读者可能会想知道:我们看到的那种卷积如何处理一维张量?他们不是应该对至少二维的张量进行操作吗?convnet的关键层(包括conv2d和maxPooling2d)利用2D空间中的空间关系。事实证明,声音可以表示为一种特殊的图像形式,称为频谱图。频谱图不仅可以将卷积应用于声音,而且还具有深度学习以外的理论依据。
如图4.12所示,频谱图是2D数字数组,可以将其显示为与MNIST图像几乎相同的灰度图像。的水平尺寸是时间,垂直一个是频率。频谱图的每个垂直切片都是短时间窗口内的声音频谱。频谱是将声音分解为不同的频率成分,可以将其大致理解为不同的“音高”。正如可以将棱镜将光分为多种颜色一样,可以通过称为傅立叶变换的数学运算将声音分解为多种频率。因此,简而言之,频谱图描述了声音的频率内容如何在多个连续的短时间窗口(通常为20毫秒)内变化。
由于以下原因,频谱图是声音的合适表示。首先,它节省了空间:频谱图中的浮点数数量通常比原始波形中的浮点数数量少几倍。其次,从广义上讲,声谱图与听力在生物学中的工作方式相对应。内耳内部称为耳蜗的解剖结构实质上执行了傅里叶变换的生物学形式。它将声音分解成不同的频率,然后由不同的听觉神经元集合拾取。第三,语音的声谱图表示使不同类型的语音更易于彼此区分。图4.12中的示例语音频谱图显示了这一点:元音和辅音在其频谱图中均具有不同的定义模式。几十年前,在机器学习被广泛采用之前,从事语音识别的人们实际上是在尝试手工制作规则,以从频谱图中检测出不同的元音和辅音。深度学习为我们节省了手工制作的麻烦。
图4.12 语音“zero”和“yes”的示例频谱图。频谱图是声音的联合时频表示。您可以将频谱图视为以图像表示的声音。沿时间轴的每个切片(即图像的一列)都是时间上的一小段瞬间(帧);沿着频率轴的每个切片(即图像的一行)对应于特定的狭窄频率范围(音高)。图像每个像素处的值表示给定时间点在给定频率仓中声音的相对能量。绘制以上的频谱图,使较深的灰色阴影对应于更高的能量。不同的语音具有不同的定义特征。例如,诸如“ z”和“ s”之类的稳定辅音的特征在于准稳态能量集中在2-3 kHz以上的频率上。元音(如“ e”和“ o”)的特征在于频谱低端(<3 kHz)的水平条纹(即能量峰)。这些能量峰值在声学中称为“共振峰”。不同的元音具有不同的共振峰频率。不同的语音的所有这些鲜明特征都可以被深层的卷积网络用于单词识别。
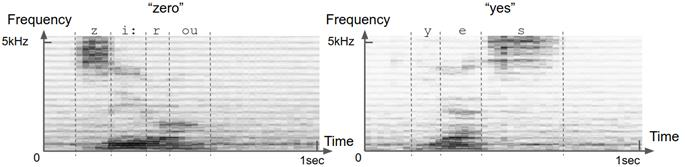
但是,两个数据集之间也存在一些明显的差异。首先,语音命令数据集中的录音有些嘈杂。在图4.12的示例频谱图中,可以看到不属于语音的暗像素斑点。其次,语音命令数据集中的每个声谱图的尺寸为43 * 232,与单个MNIST图像的28 * 28尺寸相比明显更大。频谱图的大小在时间和频率维度之间是不对称的。这些差异将由我们将在音频数据集上使用的卷积网络反映出来。
定义和训练语音命令convnet的代码位于tfjs-models存储库中。您可以使用以下命令访问代码:
git clone https://github.com/tensorflow/tfjs-models.git
cd speech-commands/training/browser-fft
模型的创建和编译封装在model.ts中的createModel函数中。
代码4.8 Convnet用于对语音命令的频谱图进行分类
function createModel(inputShape: tf.Shape, numClasses: number) {
const model = tf.sequential();
model.add(tf.layers.conv2d({
filters: 8,
kernelSize: [2, 8],
activation: 'relu',
inputShape
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
model.add(
tf.layers.conv2d({filters: 32, kernelSize: [2, 4], activation: 'relu'}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
model.add(
tf.layers.conv2d({filters: 32, kernelSize: [2, 4], activation: 'relu'}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
model.add(
tf.layers.conv2d({filters: 32, kernelSize: [2, 4], activation: 'relu'}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [1, 2]}));
model.add(tf.layers.flatten());
model.add(tf.layers.dropout({rate: 0.25}));
model.add(tf.layers.dense({units: 2000, activation: 'relu'}));
model.add(tf.layers.dropout({rate: 0.5}));
model.add(tf.layers.dense({units: numClasses, activation: 'softmax'}));
model.compile({
loss: 'categoricalCrossentropy',
optimizer: tf.train.sgd(0.01),
metrics: ['accuracy']
});
model.summary();
return model;
}
我们的音频convnet的拓扑看起来很像MNIST convnet。顺序模型从conv2d层与maxPooling2d层几个重复模块开始。模型的卷积池部分在平坦层结束,在平坦层后面添加了多层感知器(MLP)。MLP具有两个密集层。隐藏的密集层具有relu激活,而最后一层(输出)由适合分类任务的softmax激活。编译该模型以使用categoricalCrosssentropy作为损失函数,并在训练和评估期间发出准确性度量。这与MNIST卷积网络完全相同,因为两个数据集都涉及多类别分类。音频卷积网络还显示出与MNIST有所不同的一些有趣之处。特别是,conv2d层的kernelSize属性是矩形(例如[2,8])而不是正方形。选择这些值以匹配频谱图的非正方形形状,这些频谱图的频率维度大于时间维度。
要训练模型,您需要首先下载语音命令数据集。该数据集源自Google Brain团队的工程师Pete Warden收集的语音命令数据集[71]。它已转换为浏览器专用的频谱图格式。
curl -fSsL https://storage.googleapis.com/learnjs-data/speech-commands/speech-commands-data-v0.02-browser.tar.gz -o speech-commands-data-v0.02-browser.tar.gz &&
tar xzvf speech-commands-data-v0.02-browser.tar.gz
这些命令将下载并提取语音命令数据集的浏览器版本。提取数据后,您可以使用以下命令开始训练过程:
Yarn
yarn train speech-commands-data-browser/ /tmp/speech-commands-model/
yarn train命令的第一个参数指向训练数据的位置。以下参数指定了将保存模型的JSON文件以及权重文件和元数据JSON文件的路径。就像我们训练增强型MNIST卷积网络一样,音频卷积网络的训练发生在tfjs-node中,有可能利用GPU。因为数据集和模型的大小大于MNIST卷积,所以训练将花费更长的时间(约数小时)。如果您拥有CUDA GPU,并稍微更改命令以使用tfjs-node-gpu代替默认的tfjs-node(仅在CPU上运行),则可以大大提高培训速度。为此,只需在上面的命令中添加标志“ --gpu”,即
yarn train --gpu speech-commands-data-browser/ /tmp/speech-commands-model/
训练结束后,模型应达到大约94%的最终评估(测试)准确性。 训练后的模型将保存在上述命令参数所指定的路径上。就像我们使用tfjs-node训练的MNIST卷积网络一样,保存的模型可以加载到浏览器中进行投放。但是,您需要熟悉WebAudio API,才能从麦克风获取数据并将其预处理为模型可以使用的格式。为方便起见,我们编写了一个包装器类,该类不仅加载经过训练的音频卷积网络,而且还负责数据的提取和预处理。如果您对音频数据输入管道的机制感兴趣,则可以在tfjs-model git存储库中的“speech-commands/src”文件夹下研究基础代码。可通过npm以名称“ @ tensorflow-models / speech-commands”使用包装器。下面的代码清单显示了包装器类如何用于在浏览器中执行语音命令字的在线识别的示例。 在tfjs-models存储库的speech-commands / demo文件夹中,您可以找到有关如何使用该软件包的较简单的示例。要克隆并运行演示,请在speech-commands目录下运行以下命令:
git clone https://github.com/tensorflow/tfjs-models.git
cd tfjs-models/speech-commands
yarn && yarn publish-local
cd demo
yarn && yarn link-local && yarn watch
yarn watch命令将在您的默认Web浏览器中自动打开一个新选项卡。为了查看语音命令识别器的运行情况,请确保您的机器已准备好麦克风(大多数笔记本电脑都准备好了)。每次识别词汇表中的单词时,它将实时的与包含该单词的频谱图一起显示在屏幕上。因此,这是由WebAudio API和深度卷积神经网络提供支持的基于浏览器的单词识别。当然,它没有能力识别带有语法的关联语音。这将需要能够处理顺序信息的其他类型的神经网络构造块的帮助。我们将在第8章中访问这些内容。
代码4.9 @ tenosrflow-models / speech-commands模块的用法示例
import * as SpeechCommands from '@tensorflow-models/speech-commands';
const recognizer = SpeechCommands.create('BROWSER_FFT');
console.log(recognizer.wordLabels());
recognizer.listen(result => {
let maxIndex;
let maxScore = -Infinity;
result.scores.forEach((score, i) => {
if (score > maxScore) {
maxIndex = i;
maxScore = score;
}
});
console.log(`Detected word ${recognizer.wordLabels()[maxIndex]}`);
}, {
probabilityThreshold: 0.75
});
setTimeout(() => recognizer.stopStreaming(), 10e3);
4.5 摘要
- 卷积神经网络(convnet)从输入图像中提取2D空间特征,并具有堆叠的conv2d和maxPooling2d层的层次结构。
- conv2d层是多通道可调空间滤波器。它们具有局部性和参数共享的特性,这使其成为功能强大的特征提取器和有效的表示形式转换。
- maxPooling2d层通过在固定大小的窗口内计算最大值来减小输入图像张量的大小,从而实现更好的位置不变性。
- 卷积网络的conv2d-maxPooling2d“塔”通常以平坦层结束,其后是由致密层组成的多层感知器(MLP),用于分类或回归任务。
- 由于资源有限,该浏览器仅适用于训练小型模型。要训练更大的模型,建议使用tfjs-node,即TensorFlow.js的Node.js版本。tfjs-node可以使用与TensorFlow的Python版本所使用的相同的CPU和GPU并行化内核。
- 更大的模型容量会带来更大的过度拟合风险。可以通过在convnet中添加丢弃层来改善过度拟合的情况。丢弃层在训练过程中将输入元素的给定部分随机归零。
- 卷积不仅对计算机视觉任务有用。当音频信号表示为频谱图时,可以在其上应用卷积以实现良好的分类精度。
4.6 练习
- 用于在浏览器中对MNIST图像进行分类的convnet(代码清单4.1)具有两组conv2d和maxPooling2d层。修改代码以将数量减少到一组。回答以下问题:
- 这如何影响卷积网络可训练参数的总数?
- 这如何影响训练速度?
- 这对卷积网络训练后获得的最终准确性有何影响?
- 此练习类似于上面的练习1。但是,与其尝试使用conv2d-maxPooling2d层组的数量,不如在代码清单4.1中尝试使用convnet的多层感知器部分中的密集层的数量。如果删除第一个密集层并仅保留第二个(输出)层,参数总数,训练速度和最终精度将如何变化?
- 从mnist节点中的卷积网络中删除dropout层(代码清单4.5),并查看训练过程和最终测试准确性如何。为什么会这样呢?这说明什么?
- 作为使用tf.browser.fromPixels()方法从网页的与图像和视频相关的元素中提取图像数据的一种做法,请尝试以下操作:
-
通过使用img 标签,使用tf.browser.fromPixels()获得表示彩色JPG图像的张量。
a. tf.browser.fromPixels()返回的图像张量的高度和宽度是多少?什么决定高度和宽度?b. 使用tf.image.resizeBilinear()将图像调整为100 * 100(高*宽)的固定尺寸
c. 改用替代调整大小函数tf.image.resizeNearestNeighbor()。您能发现这两个调整大小函数的结果之间有什么区别吗?
-
创建一个HTML画布并使用诸如rect()之类的函数在其中绘制一些任意形状。或者,如果愿意,可以使用d3.js和three.js等更高级的库在其中绘制更复杂的2D和3D形状。然后,使用tf.browser.fromPixels()从画布获取图像张量数据。
-
