

强化学习智能体(agent)
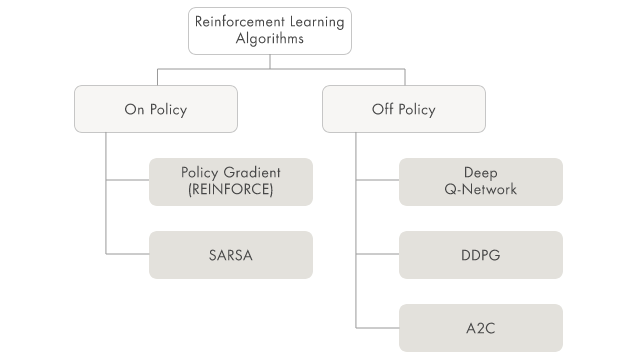
强化学习算法
Deep Q-Network Agents
| Observation Space | Action Space |
|---|---|
| Continuous or discrete | discret |
During training, the agent:
-
Updates the critic properties at each time step during learning.
-
Explores the action space usingepsilon-greedy exploration.
-
Stores past experience using a circular experience buffer. The agent updates the critic based on a mini-batch of experiences randomly sampled from the buffer.
Critic Function
a DQN agent maintains two function approximators:
- Critic Q(S,A) — The critic takes observation S and action A as inputs and outputs the corresponding expectation of the long-term reward.
- Target critic Q'(S,A) — To improve the stability of the optimization, the agent periodically updates the target critic based on the latest critic parameter values.
Both Q(S,A) and Q'(S,A) have the same structure and parameterization.
Agent Creation
Training Algorithm
update their critic model at each time step.
