

一、增加参数
还是以上次的计算过程为例。(本部分在上次的基础上扩展为函数,实现快速调用。后续将BP网络封装成“类”,并举实际例子探索BP神经网络的应用。实际上这也是我当时学习BP神经网络的过程,先自己写一段代码,然后逐渐扩展,最终形成一个比较实用的代码)
已知一个BP神经网络,学习率为0.9,当前的训练样本为x={1,0,1},预期的分类标号为1,当前网络的权重和阈值如表,描述一次迭代过程。
| 0.2 | -0.3 | 0.4 | 0.1 | -0.5 | 0.2 | -0.3 | -0.2 | -0.4 | 0.2 | 0.1 |
前面讲述了单次的迭代过程,本次增加参数,实现循环迭代,达到满意效果后停止循环。
#参数设置
def parameter():
net_max_time=2000 #最大迭代次数
net_goal=0.00001 #目标误差
net_lr=0.9 #学习率
return net_max_time,net_goal,net_lr
激活函数仍采用sigmoid函数。
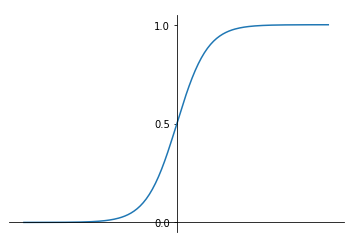
#sigmoid函数
def sigmoid(num1,num2):
return 1/(1+np.exp(num2-num1)) #正向传播所得数值与神经元阈值有相减操作
输入数据仍采用简易的矩阵表示,实际上在用于实例中并不方便,封装为类时会采用稍微复杂的矩阵表示,本程序只用于方便理解。
#输入
x=np.array([[1,0,1]]).T
#目的结果
y=np.array([[1]]).T
#初始权值和阈值
w1=np.array([[0.2,-0.3],
[0.4,0.1],
[-0.5,0.2]])
w2=np.array([[-0.3,-0.2]])
b=np.array([[-0.4,0.2,0.1]]).T
均方误差
均方误差的作用已经体现在计算梯度的过程中。而本代码中是为了直观地观察到均方误差的递减过程。
#均方误差
def error(v, y):
E=(v[-1]-y)**2/2 #本代码中,整个网络输出结果只有一个,因此可以直接选取输出v中的最后一个值
return E
接下来进入BP的迭代过程。
1.信号的正向传播
#信号正向传播
def Forward_Calculation(x,w1,w2,b):
m1,n1=np.shape(w1)
v=[]
for i in range(n1):
v.append(sigmoid(w1[:,i].dot(x),b[i])) #输入层至隐含层
v.append(sigmoid(w2.dot(v),b[-1])) #隐含层至输出层
return list(v)
2.反向计算局部梯度
#反向计算局部梯度
def Back_Calculation(y,w1,w2,b,v):
m2,n2=np.shape(w2)
gra=[]
gra.append(v[-1]*(1-v[-1])*(y-v[-1])) #输出层至隐含层
for j in range(n2)[::-1]:
gra.append(v[j]*(1-v[j])*gra[0]*w2[0][j])
gra.reverse() #矩阵反转
return list(gra)
3.更新权值和阈值
#更新权值和阈值
def Update_Values(x,w1,w2,b,v,gra,net_lr):
m1,n1=np.shape(w1)
m2,n2=np.shape(w2)
m3,n3=np.shape(b)
#更新权值
for i in range(m2):
for j in range(n2):
w2[i][j]=w2[i][j]+net_lr*v[j]*gra[-1]
for i in range(m1):
for j in range(n1):
w1[i][j]=w1[i][j]+net_lr*x[i]*gra[j]
#更新阈值
b[-1]=b[-1]-net_lr*gra[-1]
for i in range(m3-1):
b[i][0]=b[i][0]-net_lr*gra[i]
return w1,w2,b
主要函数都已写出,开始写训练函数。训练函数中包含整个迭代过程、计算均方误差、判断均方误差是否低于目标误差。
#训练
def train(x,y,w1,w2,b,net_max_time,net_goal,net_lr):
m,n=np.shape(x)
error_value_list=[]
for time in range(net_max_time): #迭代次数
error_number=[]
for i in range(n): #数据集中的样本
v=Forward_Calculation(x[:,i],w1,w2,b) #正向传播
gra=Back_Calculation(y[:,i],w1,w2,b,v) #反向计算梯度
w1,w2,b=Update_Values(x[:,i],w1,w2,b,v,gra,net_lr) #更新权值和阈值
#计算均方误差
for j in range(n):
E=error(v, y)
error_number.append(E)
error_value=np.sum(error_number)/(n+1)
if (time+1)%10==0: #提醒作用
print("第{}轮训练".format(time+1))
print(error_value)
error_value_list.append(error_value)
if error_value<=net_goal: #当误差低于目标值时退出训练
break
draw_error(list(error_value_list)) #绘制误差曲线
print("共进行了{}次迭代".format(time+1))
训练函数中调用了“绘制误差曲线”的函数,绘制误差曲线需要根据均方误差列表error_value_list使用matplotlib包绘制。
#绘制误差曲线
def draw_error(error_value):
plt.xlabel("number of times")
plt.ylabel("error")
plt.plot(error_value, 'r-')
plt.show()
绘制的误差曲线如下:
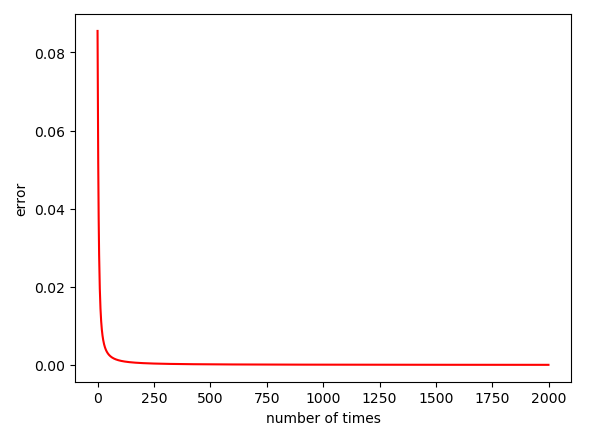
由上图可看出,训练至100次左右时,误差不再发生明显变化。
训练完成后,神经网络“学”到的东西,蕴涵在权值与阈值中。
训练样本为x={1,0,1},输出值为0.98843845,非常接近分类标号1。
后续:BP神经网络(三)
