

1. 不要什么都放到state中
只要这个数据不会影响到UI的变化,也就是数据变化不会引起UI变化,都没必要放到state中。 一个基本原则是,能放到文法作用域的,能放到this里的,都不要放到state中
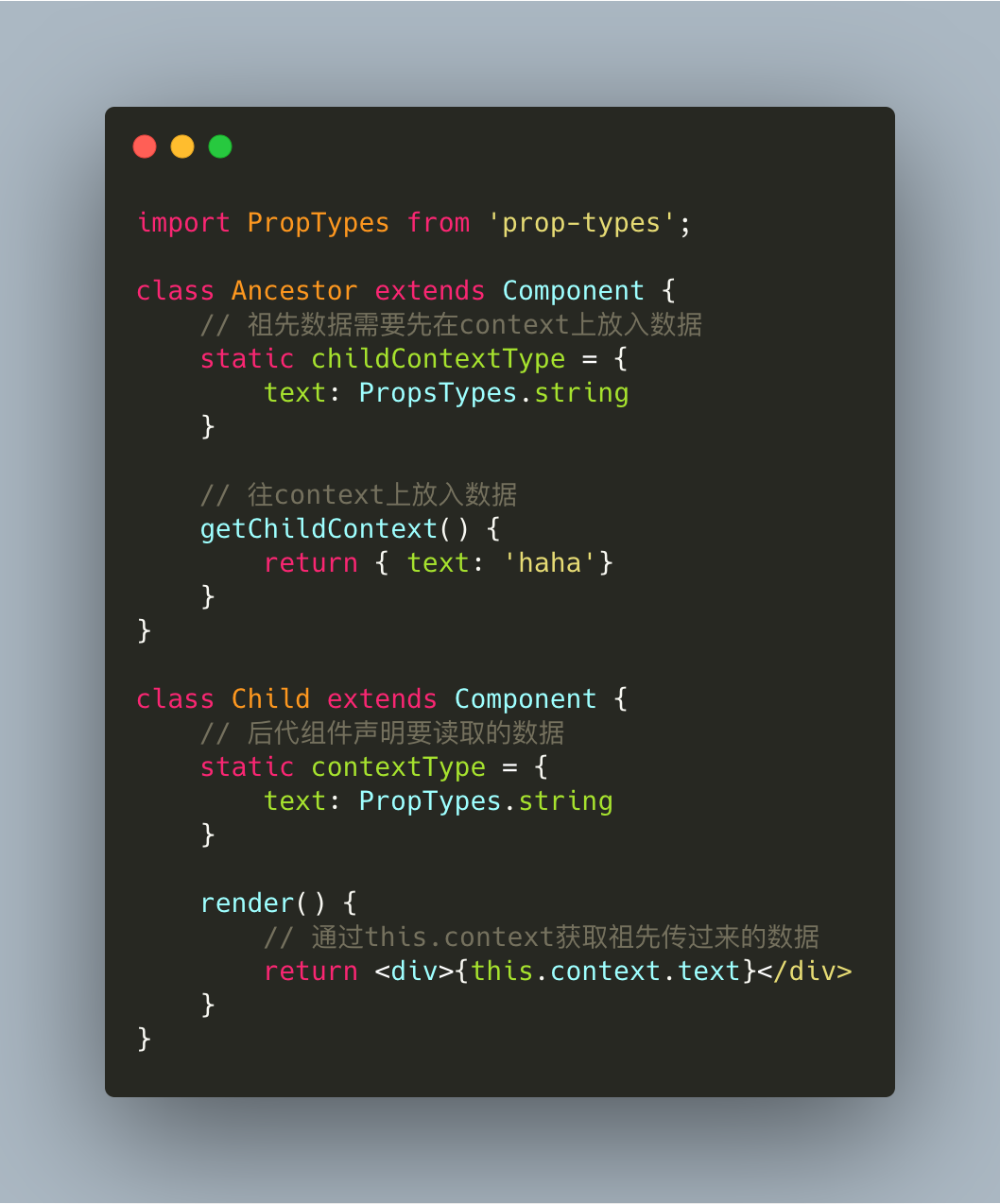
2. 爷孙组件可以通过context来省去层层传递的麻烦,并且通过双向声明控制了数据的可见性。缺点也明显,不加以节制容易造成混乱与重名覆盖。
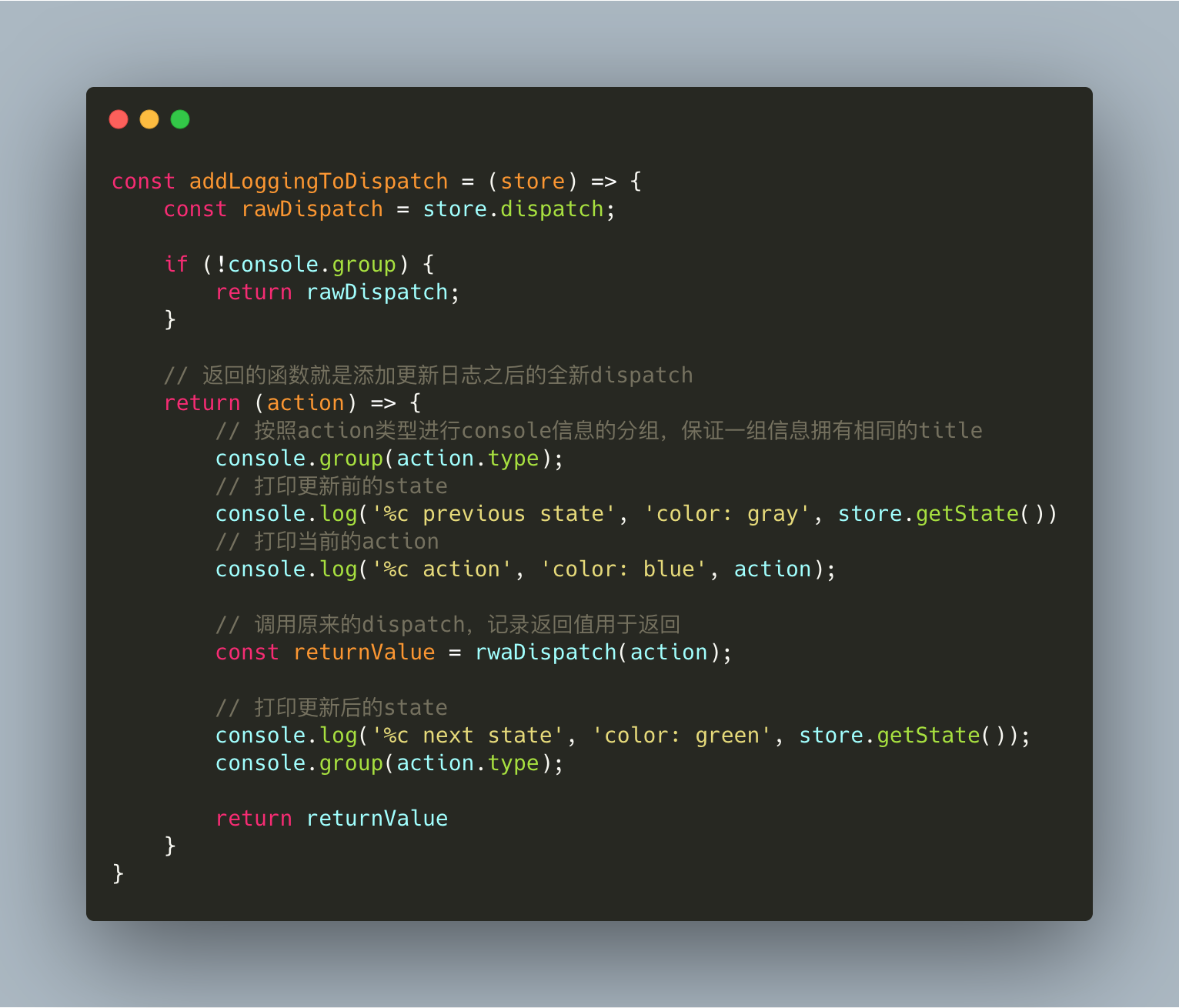
3.一个redux中间件的逻辑。
redux中间件的套路一般都比较统一,这个方法需要对store中的dispatch进行拦截,并记录原始的dispatch为rawDispatch。同时在前后进行自己一系列的行为,完成后还需返回一个全新的dispatch函数。
如下面的redux-logger的例子 02.png
4.数据结构扁平化能解决信息重复和深层嵌套的问题,也使得对数据的操作更加简单,高效
简单例子,一个文章列表的数据开始设计如下 03_01.png
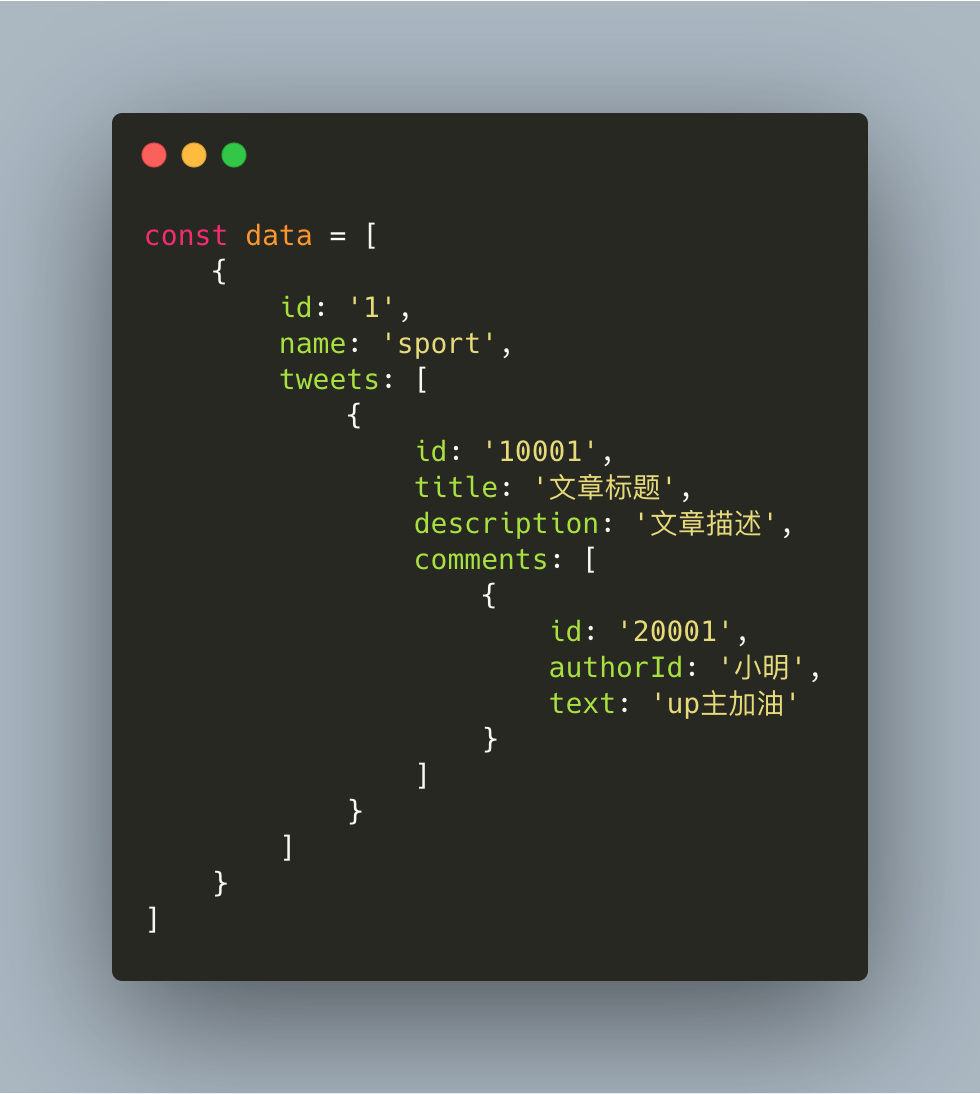
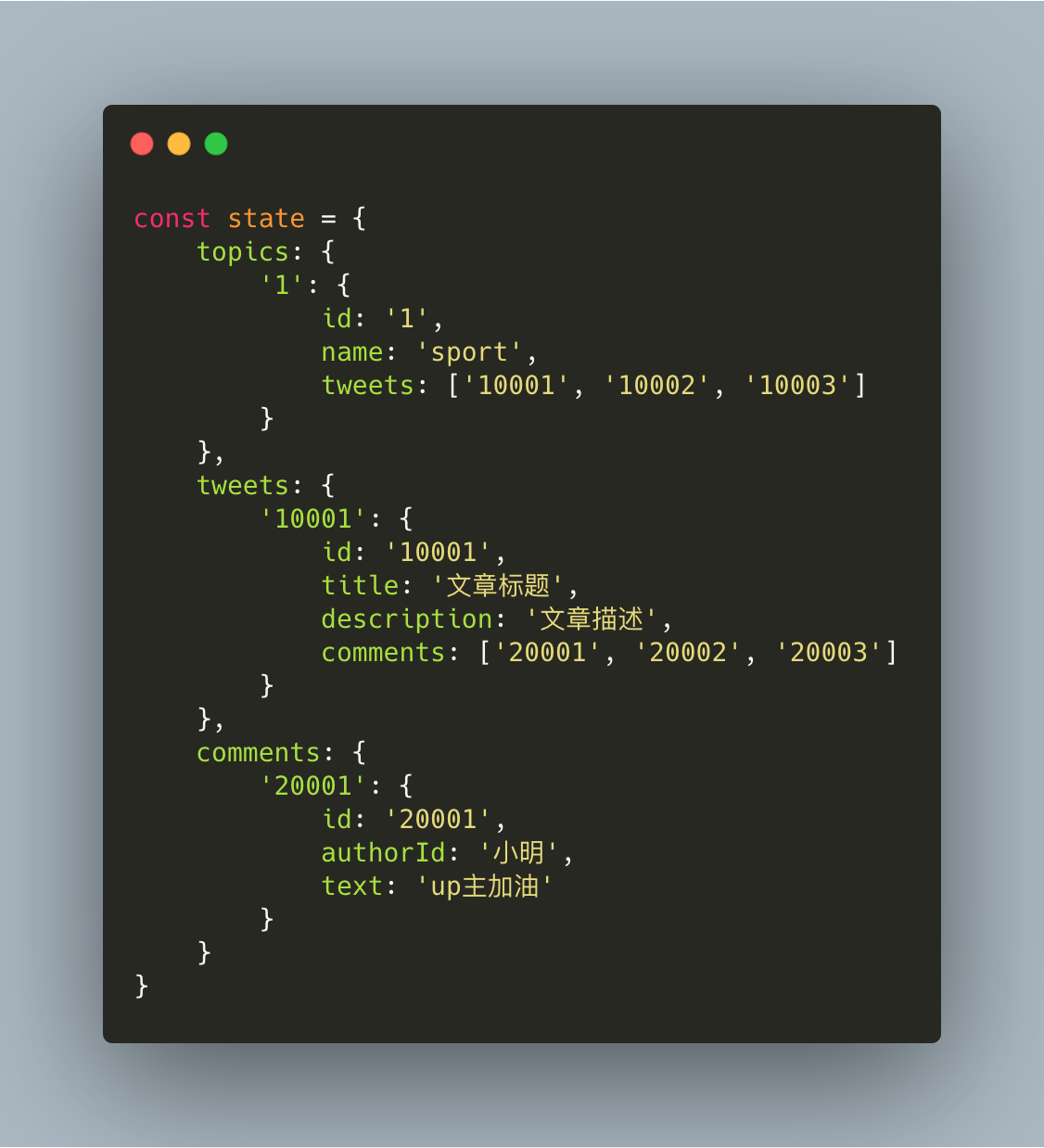
一开始的数据结构需要对data,tweets数据进行遍历还有筛选才能找到对应的index,同时为防止没查询到直接引用产生报错,还需加入许多判断代码。在效率性能上,如果数据很大,对目标文章的查找也会极其耗时。
采用第二种设计时,如有相关内容修改,可直接进入对应数组用object索引的方式找到目标,如果有关联关系的变动也仅需修改对应关联关系数组的id即可
5.react主要通过一下几种方式来保证虚拟DOM diff算法和更新的高效性能
- 高效的diff算法
- Batch操作
- 摒弃脏检查更新方式
为了减少diff算法复杂度,react设定了如下的假设
- DOM节点跨层级移动忽略不计
- 拥有相同类的两个组件生成相似的树形结构,拥有不同类的两个组件生成不同的树形结构
根据这些假设,采取如下策略
- React对组件树进行分层比较,两棵树只会对同一层级的节点进行比较
- 当对同一节点进行比较时,对于不同的组件类型,直接将整个组件替换为新类型组件,不继续比较子层级组件
6.setState的同步与异步问题
很多人都认为setState一定是一个异步的过程。实际让setState产生异步效果是因为React在处理生命周期和能被它控制的事件中,会去对state的变化做一个收集再一起处理,所以会造成异步的感觉。
其中有一个标志变量isBatchingUpdates,来决定是将组件放到dirtyComponents中等待批量更新,还是直接开启批量更新。
所以在setTimeout等不由react管理的方法中,setState是同步的
