

zset的两种实现方式
- ziplist:满足以下两个条件的时候
- 元素数量少于128的时候
- 每个元素的长度小于64字节
- skiplist:不满足上述两个条件就会使用跳表,具体来说是组合了map和skiplist
- map用来存储member到score的映射,这样就可以在O(1)时间内找到member对应的分数
- skiplist按从小到大的顺序存储分数
- skiplist每个元素的值都是[score,value]对
因为有了skiplist,才1能在O(logN)的时间内插入一个元素,并且实现快速的按分数范围查找元素
skiplist优势
skiplist本质上是并行的有序链表,但它克服了有序链表插入和查找性能不高的问题。它的插入和查询的时间复杂度都是O(logN)
skiplist原理
普通有序链表的插入需要一个一个向前查找是否可以插入,所以时间复杂度为O(N),比如下面这个链表插入23,就需要一直查找到22和26之间。

如果节点能够跳过一些节点,连接到更靠后的节点就可以优化插入速度:

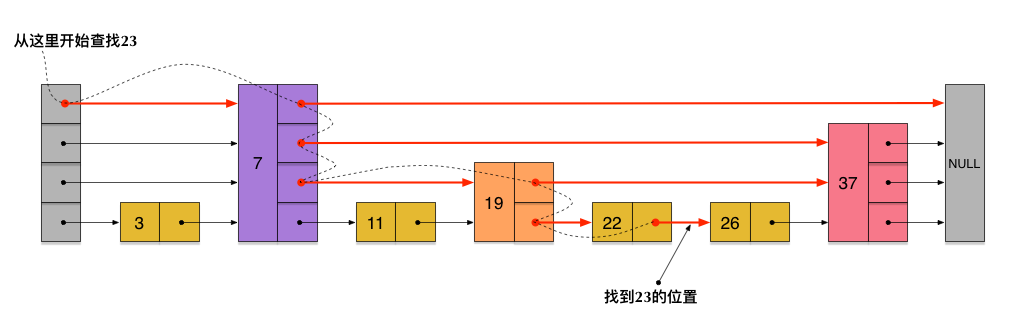
在上面这个结构中,插入23的过程是
- 先使用第2层链接head->7->19->26,发现26比23大,就回到19
- 再用第1层连接19->22->26,发现比23大,那么就插入到26之前,22之后
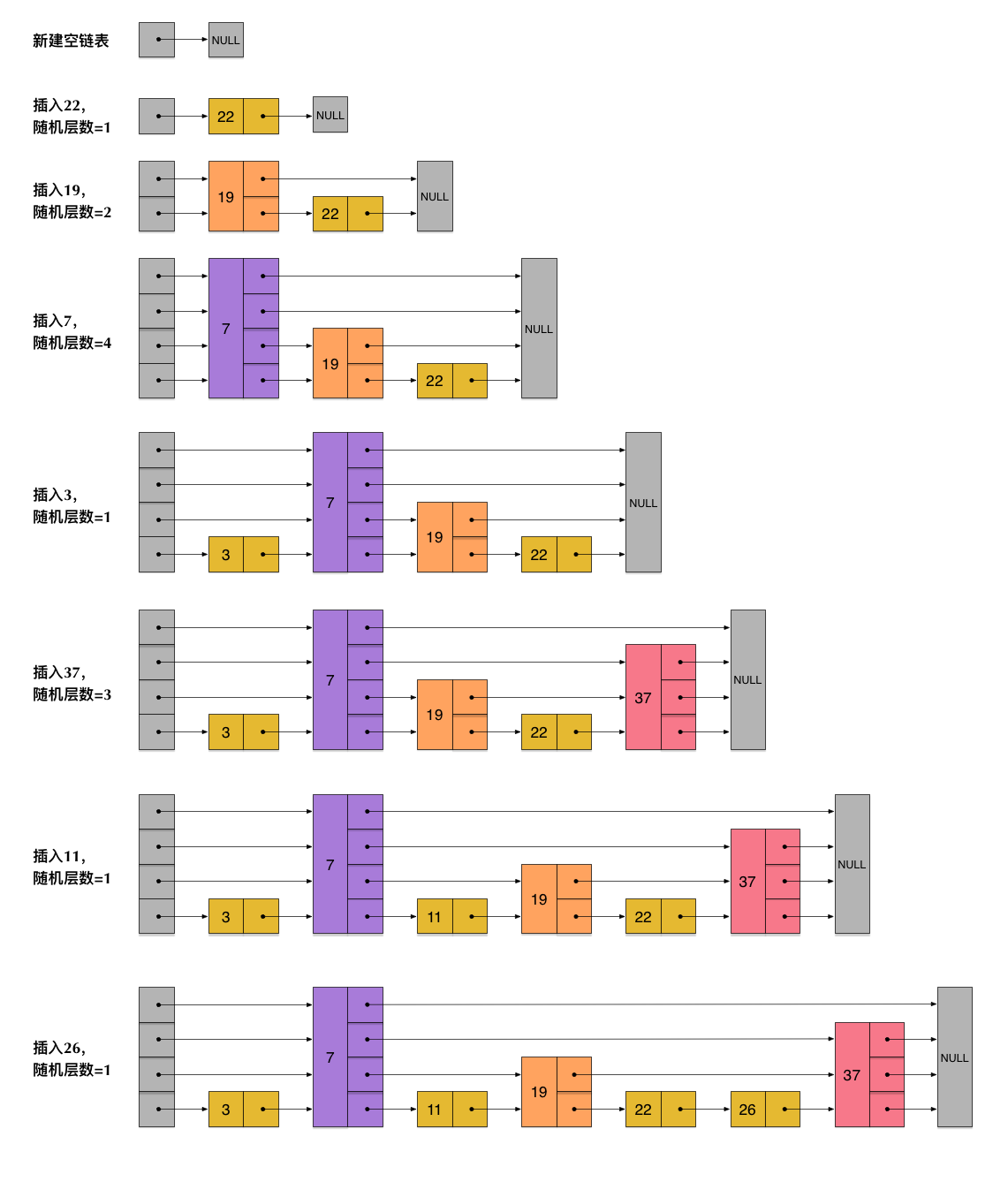
上面这张图就是跳表的初步原理,但一个元素插入链表后,应该拥有几层连接呢?跳表在这块的实现方式是随机的,也就是23这个元素插入后,随机出一个数,比如这个数是3,那么23就会有如下连接:
- 第3层head->23->end
- 第2层19->23->26
- 第1层22->23->26
下面这张图展示了如何形成一个跳表
在上述跳表中查找/插入23的过程为:
- 每个跳表都必须设定一个最大的连接层数MaxLevel
- 第一层连接会连接到表中的每个元素
- 插入一个元素会随机生成一个连接层数值[1, MaxLevel]之间,根据这个值跳表会给这元素建立N个连接
- 插入某个元素的时候先从最高层开始,当跳到比目标值大的元素后,回退到上一个元素,用该元素的下一层连接进行遍历,周而复始直到第一层连接,最终在第一层连接中找到合适的位置
skiplist在redis zset的使用
redis中skiplist的MaxLevel设定为32层
skiplist原理中提到skiplist一个元素插入后,会随机分配一个层数,而redis的实现,这个随机的规则是:
- 一个元素拥有第1层连接的概率为100%
- 一个元素拥有第2层连接的概率为50%
- 一个元素拥有第3层连接的概率为25%
- 以此类推...
为了提高搜索效率,redis会缓存MaxLevel的值,在每次插入/删除节点后都会去更新这个值,这样每次搜索的时候不需要从32层开始搜索,而是从MaxLevel指定的层数开始搜索
查找过程
对于zrangebyscore命令:score作为查找的对象,在跳表中跳跃查询,就和上面skiplist的查询一样
对于zrange还没搞清楚
插入过程
zadd [zset name] [score] [value]:
- 在map中查找value是否已存在,如果存在现需要在skiplist中找到对应的元素删除,再在skiplist做插入
- 插入过程也是用score来作为查询位置的依据,和skiplist插入元素方法一样。并需要更新value->score的map
如果score一样怎么办?根据value再排序,按照顺序插入
删除过程
zrem [zset name] [value]:从map中找到value所对应的score,然后再在跳表中搜索这个score,value对应的节点,并删除
排名是怎么算出来的
zrank [zset name] [value]的实现依赖与一些附加在跳表上的属性:
- 跳表的每个元素的Next指针都记录了这个指针能够跨越多少元素,redis在插入和删除元素的时候,都会更新这个值
- 然后在搜索的过程中按经过的路径将路径中的span值相加得到rank
