

一、BP神经网络简介
在生物神经网络中, 每个神经元与其他神经元相连,当它“兴奋”时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位;如果某神经元的电位超过了一个“阈值”, 那么它就会被激活,即“兴奋“起来,向其他神经元发送化学物质。受此启发,神经网络算法便诞生了,虽然不同的神经网络算法有所不同,但都依赖于这种神经元之间的信息传递方式。
常见的神经网络所使用的是层级结构,每层神经元与下一神经元全互连,神经元之间不存在同层连接,也不存在跨层连接。这样的神经网络通常称为”多层前馈神经网络“(multi-layer feedforward neural networks)。其中输入层神经元接收外界输入,隐层与输出层神经元对信号进行加工,最终结果由输出层神经元输出;换言之,输入层神经元仅是接受输入,不进行函数处理,隐层与输出层包含功能神经元。神经网络的学习过程,就是根据训练数据来调整神经元之间的“连接权”以及每个功能神经元的阈值;换言之,神经网络“学”到的东西,蕴涵在连接权与阈值中.
BP神经网络(error BackPropagation neural networks)就是典型的多层前馈型网络,现实任务中使用神经网络时大多使用BP算法进行训练。
BP神经网络的训练过程包含3个阶段,首先是信号的前向传播阶段,然后是误差的反向传播阶段,最后是权值和阈值的更新阶段,如此反复迭代,在大于最大迭代次数或者小于目标误差时停止迭代,所得到的就是训练好的BP神经网络模型,可用于实际需求。
二、BP神经网络原理
(如果看不懂,建议直接看第三部分,一个示例,方便理解)
给定训练集,即输入示例由
个属性描述,输出
维实值向量。在神经网络中,输入神经元与输出神经元的个数便由这两个值确定,即有
个输入神经元,
个输出神经元,而隐层的层数和所包含的神经元个数由实际问题确定,这里假设只有一层,包含
个隐层神经元。
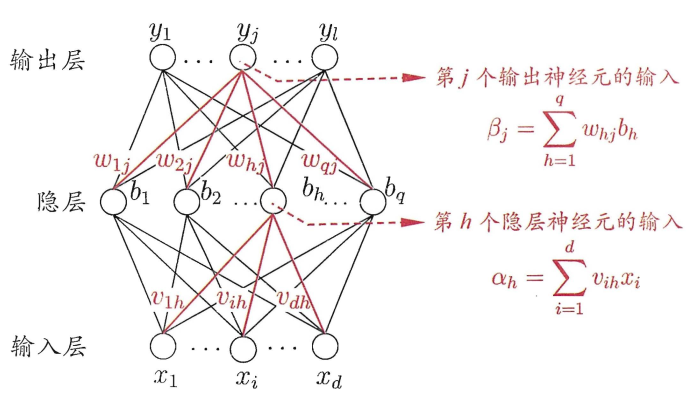
接下来介绍两个概念,权值和阈值,上文曾说,神经网络训练出的东西,蕴藏在这两个值中,因此这两个概念极为重要。BP神经网络中不同层之间相互连接,信号在不同层之间的传递需要通过带权重的连接进行传递。阈值存在于隐层神经元和输出神经元之中,在本示例神经网络中,隐层神经元接收来自输入层的信号,隐层的每个神经元接收到的总输入值与神经元的阈值进行比较,然后通过“激活函数”处理以产生神经元的输出。输出层的神经元也是以同样方式产生神经元的输出。
为便于区分,输入层第个神经元与隐层第
个神经元之间的连接权为
,隐层第
个神经元与输出层第
个神经元之间的连接权为
。隐层第
个神经元的阈值使用
表示,输出层的第
个神经元的阈值使用
表示。
| 权值 | |
|---|---|
| 输入层第 |
|
| 隐层第 |
| 阈值 | |
|---|---|
| 隐层第 |
|
| 输出层的第 |
记隐层第个神经元接收到的输入为
,输出为
。输出层第
个神经元接收到的输入为
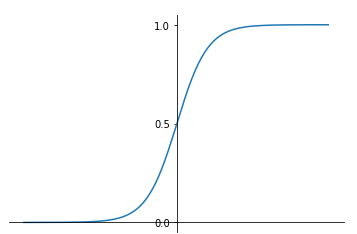
本示例中隐层与输出层的激活函数都采用Sigmoid函数。(实际上可以采用其它函数,后续会有说明)
对训练样例,假定神经网络的输出为
,即
则网络在上的均方误差为
权值的更新:BP神经网络基于梯度下降策略,以目标的负梯度方向对参数进行调整。(目前只提供最终结果,公式推导后续会给出)
给定学习率,(学习率由训练者自己给出,
,学习率控制着每一轮迭代的更新步长,若太大则容易振荡,若太小则收敛速度过慢。目前没有合适的办法计算最准确的学习率),输出层的梯度:
隐层的梯度:
更新公式:
三、迭代过程示例
已知一个BP神经网络,学习率为0.9,当前的训练样本为x={1,0,1},预期的分类标号为1,当前网络的权重和阈值如表,描述一次迭代过程。
| 0.2 | -0.3 | 0.4 | 0.1 | -0.5 | 0.2 | -0.3 | -0.2 | -0.4 | 0.2 | 0.1 |
第一阶段:信号的前向传播
| 神经元 | (输入) |
(输出) |
|---|---|---|
| 4 | ||
| 5 |
| 神经元 | (输入) |
(输出) |
|---|---|---|
| 6 |
第二阶段:反向计算梯度
输出层的梯度:
隐层的梯度:
| 神经元 | (梯度) |
|---|---|
| 6 |
| 神经元 | (梯度) |
|---|---|
| 5 | |
| 4 |
第三阶段:更新权值和阈值
权值:
| 权值 |
|
|---|---|
阈值
| 阈值 |
|---|
至此,完成一次迭代过程
单次迭代代码如下:
import numpy as np
#输入
x=np.array([[1,0,1]]).T
#目的结果
y=np.array([[1]]).T
#初始权值和阈值
w1=np.array([[0.2,-0.3],
[0.4,0.1],
[-0.5,0.2]])
w2=np.array([[-0.3,-0.2]])
b=np.array([[-0.4,0.2,0.1]]).T
#参数
net_max_time=2000 #最大迭代次数
net_goal=0.00001 #目标误差
net_lr=0.9 #学习率
def sigmoid(num1,num2):
return 1/(1+np.exp(num2-num1))
m1,n1=np.shape(w1)
m2,n2=np.shape(w2)
m3,n3=np.shape(b)
#正向传播
v=[]
for i in range(n1):
v.append(sigmoid(w1[:,i].dot(x),b[i])) #输入层至隐含层
v.append(sigmoid(w2.dot(v),b[-1])) #隐含层至输出层
#反向计算梯度
gra=[]
gra.append(v[-1]*(1-v[-1])*(y-v[-1])) #输出层至隐含层
for j in range(n2)[::-1]:
gra.append(v[j]*(1-v[j])*gra[0]*w2[0][j])
gra.reverse() #矩阵反转
#更新权值
for i in range(m2):
for j in range(n2):
w2[i][j]=w2[i][j]+net_lr*v[j]*gra[-1]
for i in range(m1):
for j in range(n1):
w1[i][j]=w1[i][j]+net_lr*x[i]*gra[j]
#更新阈值
b[-1]=b[-1]-net_lr*gra[-1]
for i in range(m3-1):
b[i][0]=b[i][0]-net_lr*gra[i]
print("更新权值后的w(输入层至隐层):\n",w1)
print("更新权值后的w(隐层至输出层):\n",w2.T)
print("更新阈值后的b:\n",b)
(一些数据采用了一维数组表示,实际上在应用中采用矩阵才是更好的选择,本代码只供参考,后续会增加更复杂的网络以及更完善的代码)
单次迭代更新的权值和阈值如下:

后文:BP神经网络(二)
参考文献
周志华《机器学习》
