


作者介绍:吕磊,Better 队成员、美团点评高级 DBA,Better 队参加了 TiDB Hackathon 2019,其项目「基于 TiDB Binlog 的 Fast-PITR」获得了最佳贡献奖。
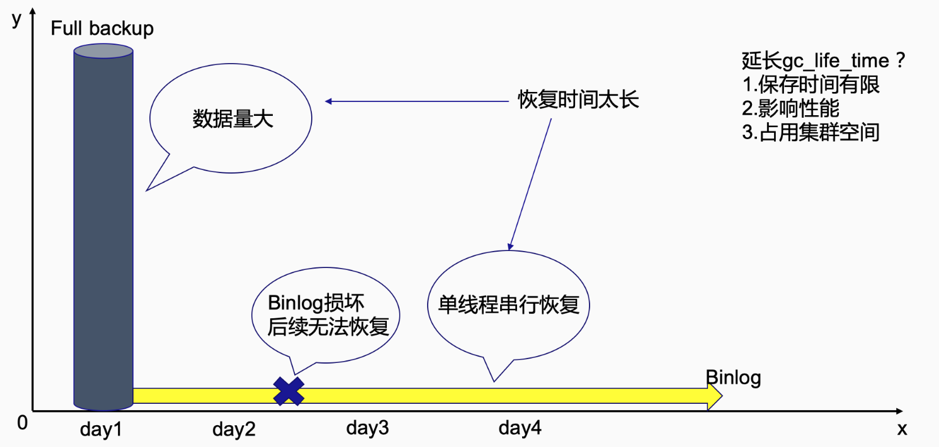
维护过数据库的同学应该都能体会,数据备份对于数据库来说可以说至关重要,尤其是关键业务。TiDB 原生的备份恢复方案已经在多家客户得到稳定运行的验证,但是对于业务量巨大的系统存在如下几个痛点:
-
集群中数据量很大的情况下,很难频繁做全量备份。
-
传统 TiDB Binlog 原样吐出 binlog 增量备份会消耗大量的磁盘空间,并且重放大量 binlog 需要较长时间。
-
binlog 本身是有向前依赖关系的,任何一个时间点的 binlog 丢失,都会导致后面的数据无法自动恢复。
-
调大 TiDB gc_life_time 保存更多版本的快照数据,一方面保存时间不能无限长,另一方面过多的版本会影响性能且占用集群空间。
我们在线上使用 TiDB 已经超过 2 年,从 1.0 RC 版本到 1.0 正式版、2.0、2.1 以及现在的 3.0,我们能感受到 TiDB 的飞速进步和性能提升,但备份恢复的这些痛点,是我们 TiDB 在关键业务中推广的一个掣肘因素。于是,我们选择了这个题目: 基于 TiDB Binlog 的 Fast-PITR (Fast point in time recovery),即基于 TiDB Binlog 的快速时间点恢复,实现了基于 TiDB Binlog 的逐级 merge,以最小的代价实现快速 PITR,解决了现有 TiDB 原生备份恢复方案的一些痛点问题。
方案介绍
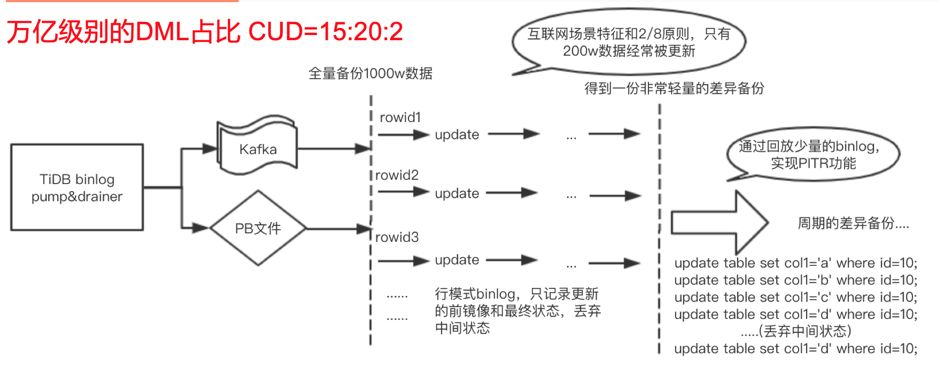
- 根据互联网行业特征和 2/8 原则,每天真正会被更新的数据只有 20% 而且是频繁更新。我们也统计了线上万亿级别 DML 中 CUD 真实占比为 15:20:2,其中 update 超过了 50%。row 模式的 binlog 中我们只记录前镜像和最终镜像,可以得到一份非常轻量的“差异备份”,如图所示:
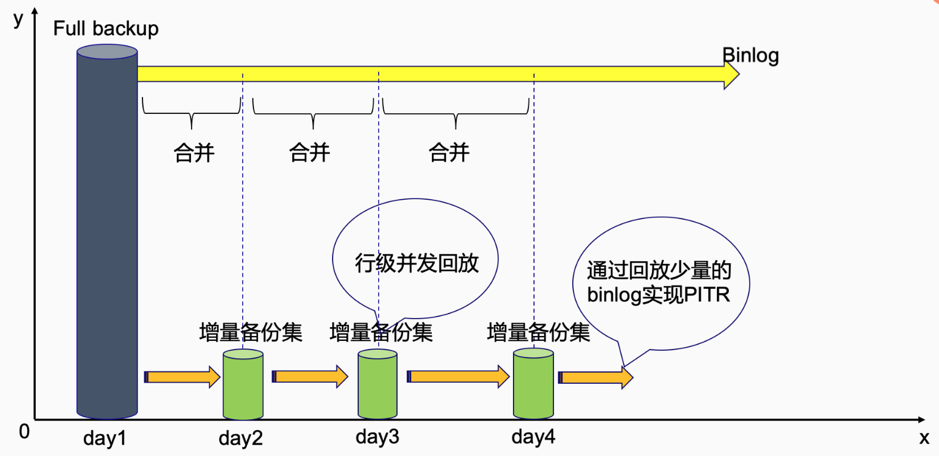
- 我们将 binlog 按照时间分段,举例说,每天的 binlog 为一个分段,每段按照上面的原则进行 merge,这段 binlog 合并后成为一个备份集,备份集是一些独立的文件。由于每一个备份集在 merge 阶段已经去掉了冲突,所以一方面对体积进行了压缩,另一方面可以以行级并发回放,提高回放速度,结合 full backup 快速恢复到目标时间点,完成 PITR 功能。而且,这种合并的另一个好处是,生成的备份集与原生 binlog file 可以形成互备关系,备份集能够通过原生 binlog file 重复生成。
binlog 分段方式可以灵活定义起点和终点:
-start-datetime string
recovery from start-datetime, empty string means starting from the beginning of the first file
-start-tso int
similar to start-datetime but in pd-server tso format
-stop-datetime string
recovery end in stop-datetime, empty string means never end.
-stop-tso int
similar to stop-datetime, but in pd-server tso format
- 在此基础上,我们做了些优化:
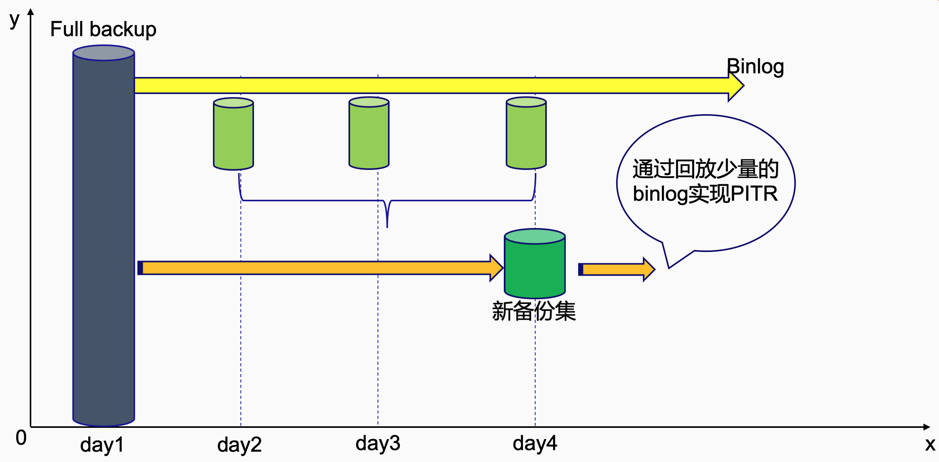
备份集的格式与 TiDB Binlog 相同,所以,备份集之间可以根据需要再次合并,形成新的备份集,加速整个恢复流程。
实现方式
Map-Reduce 模型
由于需要将同一 key(主键或者唯一索引键)的所有变更合并到一条 Event 中,需要在内存中维护这个 key 所在行的最新合并数据。如果 binlog 中包含大量不同的 key 的变更,则会占用大量的内存。因此设计了 Map-Reduce 模型来对 binlog 数据进行处理:
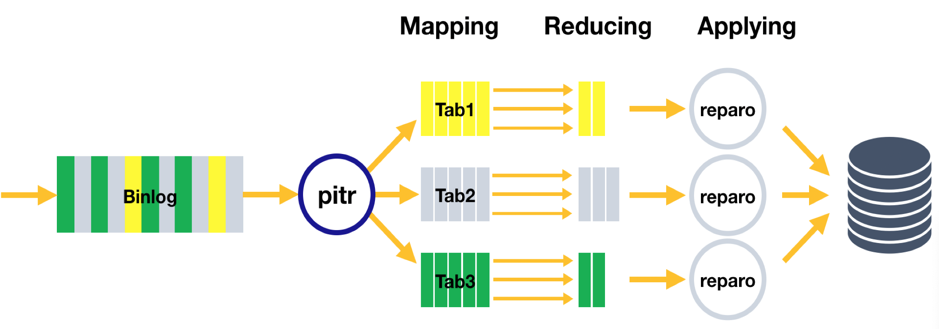
-
Mapping 阶段:读取 Binlog file,通过 PITR 工具将文件按库名 + 表名输出,再根据 Key hash 成不同的小文件存储,这样同一行数据的变更都保存在同一文件下,且方便 Reduce 阶段的处理。
-
Reducing 阶段:并发将小文件按照规则合并,去重,生成备份集文件。
| 原 Event 类型 | 新 Event 类型 | 合并后的 Event 类型 |
|---|---|---|
| INSERT | DELETE | Nil |
| INSERT | UPDATE | INSERT |
| UPDATE | DELETE | DELETE |
| UPDATE | UPDATE | UPDATE |
| DELETE | INSERT | UPDATE |
- 配合官方的 reparo 工具,将备份集并行回放到下游库。
DDL 的处理
Drainer 输出的 binlog 文件中只包含了各个列的数据,缺乏必要的表结构信息(PK/UK),因此需要获取初始的表结构信息,并且在处理到 DDL binlog 数据时更新表结构信息。DDL 的处理主要实现在 DDL Handle 结构中:
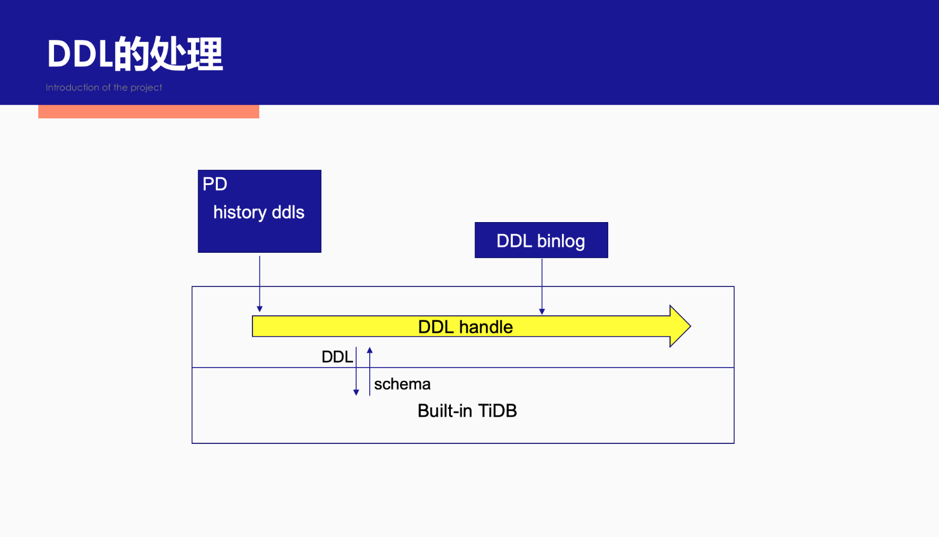
首先通过配置 TiDB 的 Restful API 获取 TiKV 中保存的历史 DDL 信息,通过这些历史 DDL 获取 binlog 处理时的初始表结构信息,然后在处理到 DDL binlog 时更新表结构信息。
由于 DDL 的种类比较多,且语法比较复杂,无法在短时间内完成一个完善的 DDL 处理模块,因此使用 tidb-lite 将 mocktikv 模式的 TiDB 内置到程序中,将 DDL 执行到该 TiDB,再重新获取表结构信息。
方案总结
-
恢复速度快:merge 掉了中间状态,不但减少了不必要的回放操作,且实现了行级并发。
-
节约磁盘空间:测试结果表明,我们的 binlog 压缩率可以达到 30% 左右。
-
完成度高:程序可以流畅的运行,并进行了现场演示。
-
表级恢复:由于备份集是按照表存储的,所以可以随时根据需求灵活恢复单表。
-
兼容性高:方案设计初期就考虑了组件的兼容性,PITR 工具可以兼容大部分的 TiDB 的生态工具。
方案展望
Hackathon 比赛时间只有两天,时间紧任务重,我们实现了上面的功能外,还有一些没来得及实现的功能。
增量与全量的合并
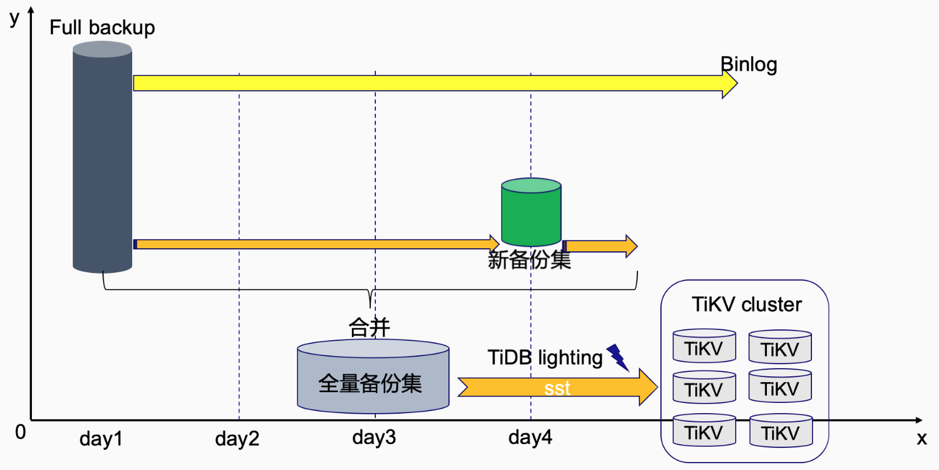
增量备份集,逻辑上是一些 insert+update+delete 语句。
全量备份集,是由 mydumper 生成的 create schema+insert 语句。
我们可以将增量备份中的 insert 语句前置到全量备份集中,全量备份集配合 Lightning 工具 急速导入到下游 TiKV 集群,Lightning 恢复速度是逻辑恢复的 5 - 10 倍 ,再加上一份更轻量的增量备份集 (update+delete) 直接实现 PITR 功能。
DDL 预处理
PIRT 工具实际上是一个 binlog 的 merge 过程,处理一段 binlog 期间,为了保证数据的一致性,理论上如果遇到 DDL 变更,merge 过程就要主动断掉,生成备份集,再从这个断点继续 merge 工作,因此会生成两个备份集,影响 binlog 的压缩率。
为了加速恢复速度,我们可以将 DDL 做一些预处理,比如发现一段 binlog 中包含某个表的 Drop table 操作,那么完全可以将 Drop table 前置,在程序一开始就忽略掉这个表的 binlog 不做处理,通过这些“前置”或“后置”的预处理,来提高备份和恢复的效率。

结语
我们是在坤坤(李坤)的热心撮合下组建了 Better 战队,成员包括黄潇、高海涛、我,以及 PingCAP 的王相同学。感谢几位大佬不离不弃带我飞,最终拿到了最佳贡献奖。比赛过程惊险刺激(差点翻车),比赛快结束的时候才调通代码,强烈建议以后参加 Hackathon 的同学们一定要抓紧时间,尽早完成作品。参赛的短短两天让我们学到很多,收获很多,见到非常多优秀的选手和炫酷的作品,我们还有很长的路要走,希望这个项目能继续维护下去,期待明年的 Hackathon 能见到更多优秀的团队和作品。

