

迫于风控,真理部需要根据敏感词库对用户发布的文字内容进行审查并替换敏感词。如果单纯使用遍历匹配,随着敏感词库的线性增长审查的时间也会线性增长(毕竟黑话层出不穷2333)。对于这种使用部分值尝试搜索出可能的完全值的场景,使用 Trie 是更好的选择(也适用于拼写补全的场景)。
Trie (usually pronounced “try”)
Tries were first described by René de la Briandais in 1959. The term trie was coined two years later by Edward Fredkin, who pronounces it /ˈtriː/(as "tree"), after the middle syllable of retrieval. However, other authors pronounce it /ˈtraɪ/ (as "try"), in an attempt to distinguish it verbally from "tree".
Trie
Trie 又称前缀树,由一个共同的祖先衍生出多个子树表示不同的字符串,每个节点的子孙都有相同的前缀。如下为一个由 4 个敏感词构成的 Trie,不同词中存在重复的字符。
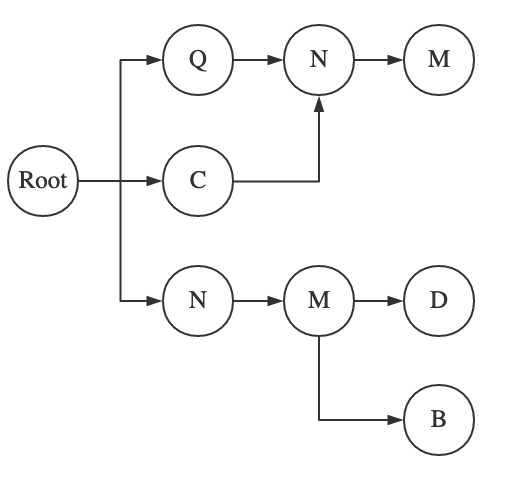
输入文本进行敏感词检测时,文本中每个字符由 Root 进入树,在二层节点中寻找匹配节点,若存在匹配节点,下个字符进入该节点子树进行匹配,至叶子节点则表示文本中存在敏感词,无法到达叶子节点则表示文本中搜索不到敏感词。
通常使用嵌套的 Map 来实现 Trie,以字符为 key,表每个节点,使用特殊标记表示叶子节点。代码表示如下:
//Trie.Add("fuck")
{
"f": {
"u": {
"c": {
"k": {},
"end": true
},
"end": false
},
"end": false
},
"end": false
}
使用 Trie 进行关键字过滤本质上相当于使用一个简单的 DFA ,行列组合构成状态转移函数,Root 为 inital state(下图 S0),每个节点表不同的 alphabet,构成的状态图如下:
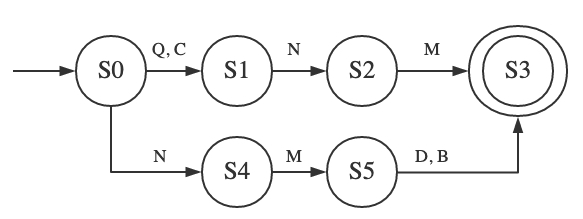
到达 final state 的文本视为 accept ,其中匹配的 alphabet 为存在的敏感词被过滤,而被 reject 的字符非已有的任何敏感词,故直接通过。
时间复杂度
- L:词集中最长单词长度
- A:词集中单词平均长度
- N:词集中单词数量
- S:表搜索的单词长度
-
Create
创建 trie 的时间复杂度取决于输入的词集中重复前缀的数量,最坏情况下(即词集中不存在重复的情况)为 O(L * N)。平均为 O(A * N)
-
Search:O(S)
-
Insert:O(S)
Trie 的缺点
- 单词多时需要占用大量内存,毕竟每个字符为一个节点。
Go 实现
github 上已经有相当多的敏感词过滤系统实现,故此处仅给出最基本的实现方式,若需要扩展仅需添加解析敏感词文本列表的函数。
type TrieNode struct {
Children map[rune]*TrieNode
End bool
}
func NewTrieNode() *TrieNode {
return &TrieNode{
Children: make(map[rune]*TrieNode),
End: false,
}
}
type TrieFilter struct {
Root *TrieNode
Placeholder rune
}
// eg: Add("fuck")
// {"f": {"u": {"c": {"k": {}, "end": true}, "end": false}, "end": false}, "end": false}
// trie 树实际上是一个 dfa
// (row, column) = transaction
func (t *TrieFilter) Add(kw string) {
if len(kw) < 1 {
return
}
chars := []rune(kw)
node := t.Root
for i := 0; i < len(chars); i++ {
if _, ok := node.Children[chars[i]]; !ok {
node.Children[chars[i]] = NewTrieNode()
}
node = node.Children[chars[i]]
}
node.End = true
}
func (t *TrieFilter) Replace(text string) string {
chars := []rune(text)
length := len(chars)
var result []rune
for i := 0; i < length; i++ {
node := t.Root
if _, ok := node.Children[chars[i]]; !ok {
result = append(result, chars[i])
continue
}
for j := i; ; j++{
if node.End || j >= length {
i = j - 1
break
}
node = node.Children[chars[j]]
result = append(result, t.Placeholder)
}
}
return string(result)
}
func NewTrieFilter() *TrieFilter {
return &TrieFilter{
Root: NewTrieNode(),
Placeholder: '*',
}
}
func main() {
text := "狗粉丝在赌博场所说黑话"
filter := NewTrieFilter()
filter.Add("赌博")
filter.Add("黑话")
filter.Add("狗粉丝")
fmt.Println(filter.Replace(text))
fmt.Println(filter.Replace("这是一段正常的文字"))
}
总结
Trie 不仅仅可以用于敏感词过滤,自动补全,拼写检测,还可以用于 IP 路由(最长前缀匹配),输入法文本预测等。当存在大量重复前缀的场景下通常使用 Trie 替代 Hash Table ,因为 Trie 不需要计算 Hash 也没有哈希冲突,并且实现字典序排序也非常方便。
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
