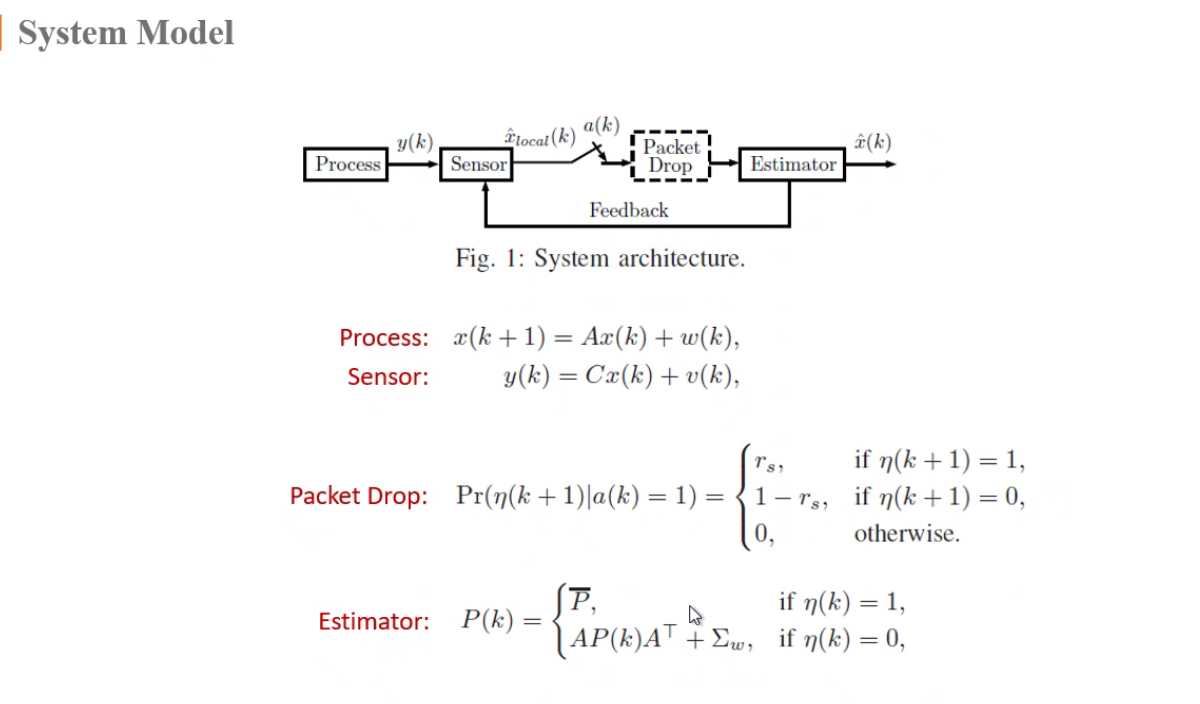

a(k)是策略
a=1发送,a=0不发送
是状态
:距离上一次接收到的时间

衡量指标
- 第一个:误差协方差的trace,一般用这种形式,无穷时间平均代价
- 第二个:传输比率
两个问题:
- 第一个:优化函数
- 第二个:把能量指标作为一个约束

最下面的式子就是我们的目标函数(形式同问题一)

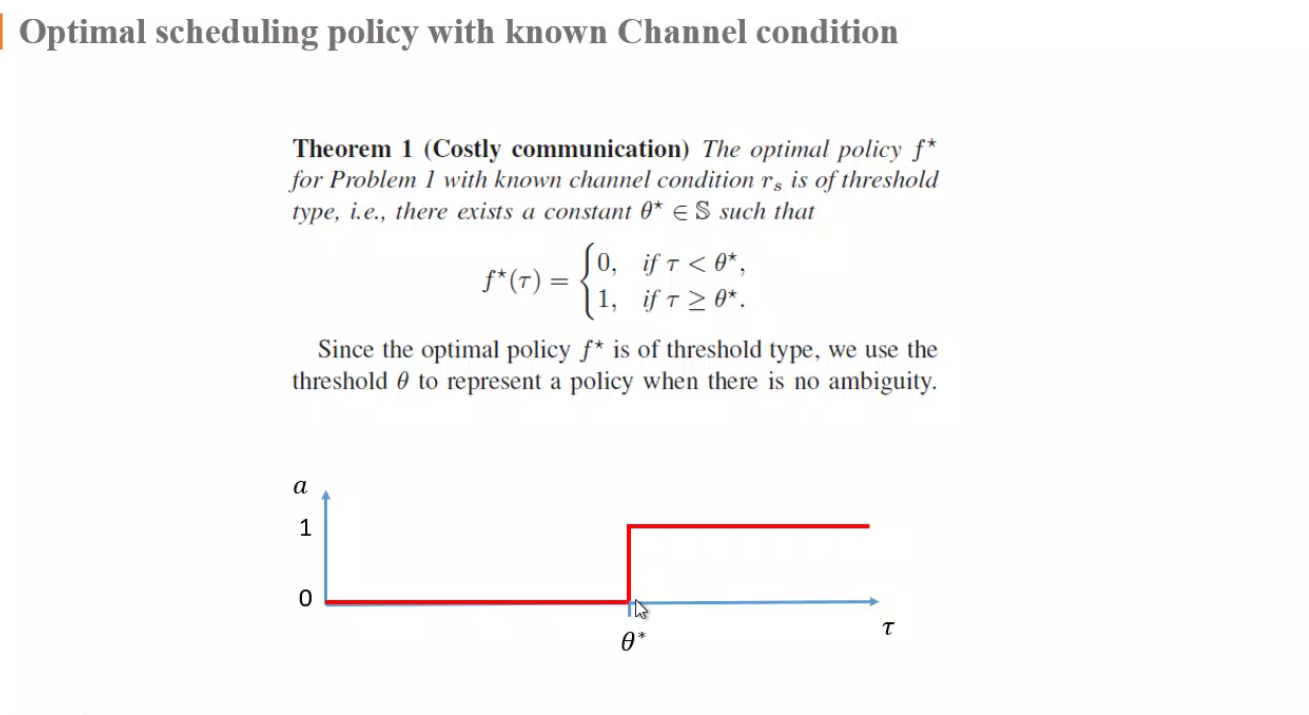
(3)是贝尔曼方程,j*是最小值,最优值
引理推出存在最优解,推出Q函数
解存在性引理由以下几个条件推导得出:


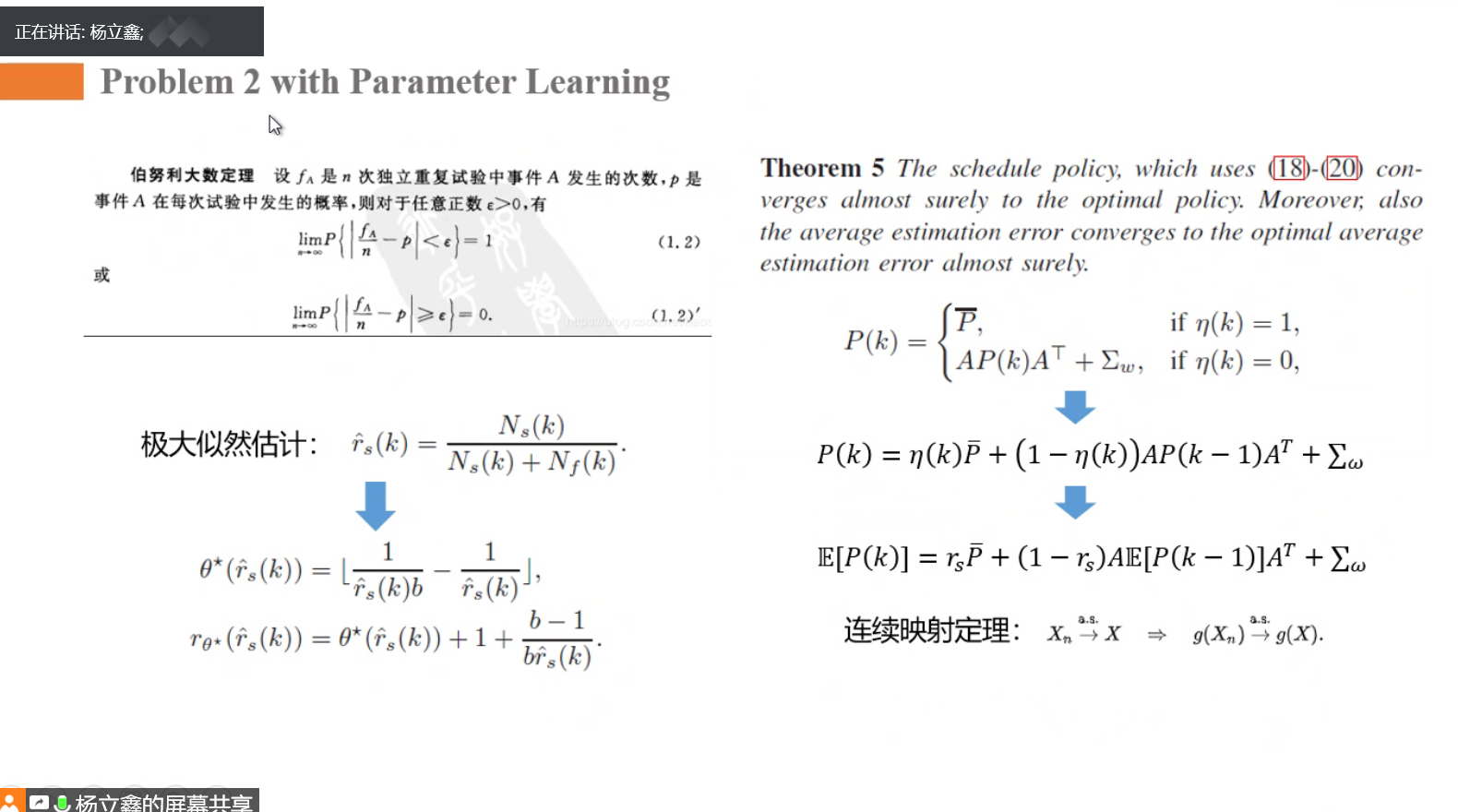
以下针对问题二:

☆ rs未知时,MDP的模型时未知的,用强化学习,如下:

- 随机逼近:Q-learning算法
- 参数逼近
随机逼近:Q-learning算法:
最优Q值是min
步长α=v_{k}依赖于被访问的次数
异步算法,每次只能访问一个动作对——》所以提出了改造方案:structural learning,通过之前证明的Q的次模性来改进,加快收敛速度


问题二
法一:
有约束条件的优化问题--用拉格朗日乘子法


λ用梯度上升的方法解,一直去迭代更新
法二: