

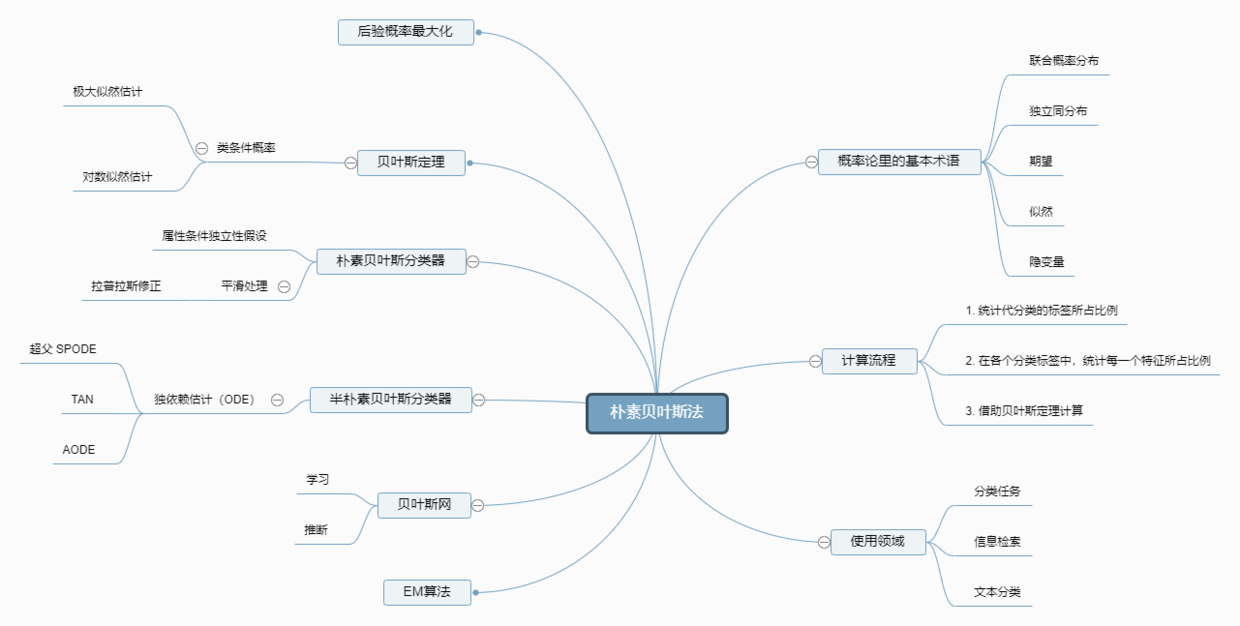
1. 贝叶斯的知识导图
2. 几个通俗易懂的例子
3. 正儿八经的看一看:贝叶斯分类器
3.1 贝叶斯定理
一个数据集中有种标签,记为
,每一种标签所对应的
个特征值记为
(
是一个向量
),那么,对于贝叶斯定理来说,有如下公式:
将公式3.1应用于每个标签,可以计算出每个标签对应的概率,计算概率最大的标签即为预测的值。
3.2 贝叶斯决策论
在分类中:贝叶斯的目标是如何在给定条件下选择最优的类别标记。那么,最优的判定准则是什么呢?
必然是把类别搞错了之后的代价啊!
假设有一个类别,记为,而特征
所对应的正确类别是
,此时,我们把
错认为是
所造成的损失记为
,
那么,对于样本空间中的所有样本而言,在给定特征
的情况下,把它们都认为是
所造成的总损失,记为
为:
而我们的任务是需要找到一个方法,让公式(3.2)最小。这个方法能够将特征映射到类别上,这个方法的对应的总风险为
那么,在整个训练集上,该函数损失的期望为:
显然,当条件风险最小时,总体风险
也最小,因此,在每个样本特征上选择使其条件风险最小的类别标记,便能够达到最优。
此时这个方法表示为:
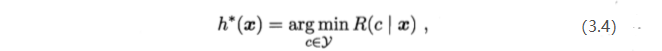

具体来说,如果目标是最小化分类错误率,则误判损失可写成:

3.3 贝叶斯的计算方法
我们的目标是获得后验概率,那么,有两种策略:
- 判别式模型:给定
直接通过建模
得到
.
- 生成式模型:先对联合概率
建模,然后再计算
3.4 这跟极大似然估计有什么关系?
3.4.1 极大似然估计
这篇文章用了四个例子简单介绍了贝叶斯的核心思想,这四个例子都是掰着手指头数一数,就能算出所有的概率,好像没有用到所谓的极大似然估计这个概念?(啥是似然函数?)
在统计学中,数学家们认为:当数据足够多的情况下,每一种特征的都是按照一定规律出现的,而这种“规律”是可以通过数学表达式计算得出。寻找表达式的过程就是参数估计,筛选出的最好的表达式的过程极大似然估计。
所以,概率模型的训练过程就是参数估计的过程。而贝叶斯学派的人认为:如果一个训练集中的第
类样本的集合表示为
,假设这些样本是独立同分布的,则参数
对于数据集
的似然是这样的:
3.4.2 对数似然
公式3.8在连乘操作下,很容易有溢出的问题,因此可以使用对数似然进行分析。
3.5 灵魂拷问
3.5.1 为什么要假设满足“属性条件独立假设”

看着貌似很简单,但是,这样有一个问题:
- 当特征的数量比较多的时候,它们组合的数据量是爆炸性增长的。
以病人分类为例:2个特征
。 “症状”特征有2种取值:
; “职业”特征有4种取值:
。 那么,通过排列组合,共有16种特征组合(打喷嚏+护士、打喷嚏+农夫、打喷嚏+建筑工人。。。)。 这样的数量是无法容忍的。
- 由于特征之间组合的数量过多,在实际的数据集中可能有的特征组合根本没有出现,比如(头痛+护士)到底算什么疾病?(注意,这里不能记为0,因为**“未被观测到”和“出现概率为0”**是两码事)。
所以,就有一个大前提:假设所有属性相互独立,在此基础上,则公式3.1可以写成
- 其中,
为特征的数目,
为
在第
个属性上的取值。
称为类先验概率。
、
、
-
是证据因子,即所取特征的概率相乘,对于类标记均相同。 (例如
、
)
-
是样本
对于类标记
的类条件概率(似然)
- 对于离散数据而言,
表示
中在第
- 对于离散数据而言,
(例如、
)
- 对于连续数据而言:
假定。其中,
分别为
类标签在第
个属性上的均值和方差。
3.5.2 要是出现了未知特征怎么办?
在估计概率值是需要进行“平滑”处理,常用的方法是“拉普拉斯修正”,公式为:
为训练集中可能的类别数(疾病分类中为3(感冒、过敏、脑震荡))。
为第
个属性可能的取值数(疾病分类中,职业属性的数为:4(护士、建筑工人、教师、农夫))。
4.pyhton代码实现
这里使用了《统计学习方法》和《西瓜书》里的数据
写了代码才发现,周志华老师的西瓜书里有两处疏忽:
-
概率计算错误。

-
连续值概率使用的是标准差而非方差

《西瓜书》中的数据为P84页表4.3。在代码中把前面的编号列删掉了。
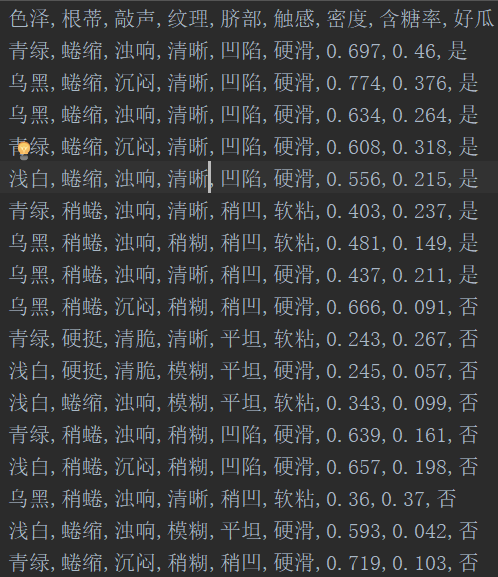
获取数据
def getData():
'''
获取数据
:return: 返回数据集,特征值名称以及标签类名称
'''
dataset = pd.DataFrame({
'x1': [1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3],
'x2': ['S', 'M', 'M', 'S', 'S', 'S', 'M', 'M', 'L', 'L', 'L', 'M', 'M', 'L', 'L'],
'Y': [-1, -1, 1, 1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, -1]}
)
# 有的特征如果是连续的话……要用概率密度函数来计算
features_info = {
'x1': 'dispersed',
'x2': 'dispersed'
}
label_names = 'Y'
target = {
'x1': 2,
'x2': 'S'
}
dataset = pd.read_csv('./data/WaterMelonDataset3.csv')
# dataset = dataset[1: ]
features_info = {
'色泽': 'dispersed',
'根蒂': 'dispersed',
'敲声': 'dispersed',
'纹理': 'dispersed',
'脐部': 'dispersed',
'触感': 'dispersed',
'密度': 'series',
'含糖率': 'series',
}
label_names = '好瓜'
target = {
'色泽': '青绿',
'根蒂': '蜷缩',
'敲声': '浊响',
'纹理': '清晰',
'脐部': '凹陷',
'触感': '硬滑',
'密度': 0.697,
'含糖率': 0.460,
}
return dataset, features_info, label_names, target
计算连续属性的概率密度
def calNormalDistribution(x_value, var_value, mean_value):
'''
用于计算连续属性的概率
:param x_value: 目标特征值
:param var_value: C类样本在第i个属性上的方差
:param mean_value: C类样本在第i个属性上的均值
:return: 概率结果
'''
return math.exp(-(x_value - mean_value) ** 2 / (2*(var_value**2))) / (math.sqrt(2*math.pi) * var_value)
class NativeBayesModel(object):
def __init__(
self,
dataset: pd.DataFrame,
features_info: dict,
label_names: str,
):
'''
获取训练数据
:param features_info: 数据的特征值的列名
:param label_names: 数据的标签值的列名
'''
self.features_info = features_info
self.label_names = label_names
# 类先验概率
self.prior_prob = {}
# 证据因子
self.evidence_prob = {}
# 类条件概率
self.class_conditional_prob = {}
# 给证据因子初始化
for ifeature in features_info:
self.evidence_prob[ifeature] = {}
# 对dataset特征和标签进行统计
self.features_stat, self.label_stat = self.getStatistic(dataset)
def getStatistic(self, dataset: pd.DataFrame):
'''
对每一类进行统计,存储于label_stat 和 features_stat 中
:param features_names: 数据的特征值的列名
:param label_names: 数据的标签值的列名
:return: 特征值和标签值的统计结果
'''
# 数据特征值的列名
features_name = [ifeature for ifeature in self.features_info.keys()]
features = dataset[features_name]
# 数据标签值的列名
labels = dataset[self.label_names]
# 把统计的结果转化成字典形式
label_stat = dict(labels.value_counts())
features_stat = {}
# 按照特征把统计的结果转化成字典形式
for ifeature in self.features_info.keys():
features_stat[ifeature] = dict(features[ifeature].value_counts())
return features_stat, label_stat
def getPriorProb(self, dataset_nums: int, regular=False):
'''
计算先验概率(类概率)
:param label_stat: 标签的统计结果
:param regular: 是否需要拉普拉斯修正标志
:return:
'''
# 如果不用拉普拉斯修正
if regular is False:
for iclass, counts in self.label_stat.items():
self.prior_prob[iclass] = counts / dataset_nums
else:
for iclass, counts in self.label_stat.items():
self.prior_prob[iclass] = (counts+1) / (dataset_nums+len(self.label_stat))
def getEvidenceProb(self, dataset_nums: int):
'''
计算证据因子,虽然对最后类标签的选择没啥卵用
:param features_stat: 特征的统计结果
:return:
'''
for ifeature in self.features_info.keys():
for ifeature_name, counts in self.features_stat[ifeature].items():
self.evidence_prob[ifeature][ifeature_name] = counts / dataset_nums
def getConditionData(self, dataset: pd.DataFrame):
'''
根据目标值,筛选数据
:param dataset:
:return: 筛选依据(标签值)筛选后的数据
'''
new_dataset = {}
for iclass in self.label_stat:
# 类条件概率初始化
self.class_conditional_prob[iclass] = {}
# 按照类划分数据集
new_dataset[iclass] = dataset[dataset[self.label_names] == iclass]
return new_dataset
def getClassConditionalProb(self, dataset, target, iclass, regular=False):
'''
计算类条件概率:P(feature_i = ifeature | class = iclass)
:param dataset: 仅包含第iclass 类的子数据集
:param target: 目标数据的特征值,字典形式
:param iclass: 类中的标签
:param regular: 是否需要拉普拉斯修正标志
:return: 计算结果为
{
class : {
feature_name: {
features
}
}
}
'''
for target_feature_name, target_feature in target.items():
# 初始化类条件概率,按照“类-特征列名-特征变量名”结构存储
if target_feature_name not in self.class_conditional_prob[iclass]:
self.class_conditional_prob[iclass][target_feature_name] = {}
if target_feature not in self.class_conditional_prob[iclass][target_feature_name]:
self.class_conditional_prob[iclass][target_feature_name][target_feature] = {}
# 判断该特征是连续的还是离散的
if self.features_info[target_feature_name] == 'dispersed':
# 筛选数据集
condition_dataset = dataset[dataset[target_feature_name] == target_feature]
# 如果使用拉普拉斯修正
if regular is False:
prob = condition_dataset.shape[0] / dataset.shape[0]
else:
prob = (condition_dataset.shape[0]+1) / (dataset.shape[0]+len(self.features_stat[target_feature_name]))
# 如果该特这是连续的
else:
x_value = target_feature
var_value = dataset[target_feature_name].var()
mean_value = dataset[target_feature_name].mean()
prob = calNormalDistribution(x_value, var_value, mean_value)
self.class_conditional_prob[iclass][target_feature_name][target_feature] = prob
def getPredictClass(self, target):
# 计算类别
max_prob = 0
predict_class = None
for iclass in self.label_stat:
prob = nb.prior_prob[iclass]
for target_feature_name, target_feature in target.items():
prob *= nb.class_conditional_prob[iclass][target_feature_name][target_feature]
print('label', iclass, '\'s probability is:', prob)
if prob > max_prob:
predict_class = iclass
max_prob = prob
return predict_class
函数调用
if __name__ == '__main__':
import pandas as pd
import math
# 是否需要拉普拉斯修正
regular_state = False
dataset, features_info, label_names, target = getData()
dataset_nums = dataset.shape[0]
nb = NativeBayesModel(dataset, features_info, label_names)
# 计算先验概率
nb.getPriorProb(dataset_nums, regular=regular_state)
# 计算证据因子
nb.getEvidenceProb(dataset_nums)
# 将数据集按照类标签划分为多个只包含一类标签的数据集
subDataset = nb.getConditionData(dataset)
# 依次计算每类标签的条件概率
for iclass, subdata in subDataset.items():
nb.getClassConditionalProb(subdata, target, iclass, regular=regular_state)
predict_class = nb.getPredictClass(target)
print('predict label is :', predict_class)
print('==============prior prob===================')
print(nb.prior_prob)
print('==============ClassConditionalProb===================')
print(nb.class_conditional_prob)
实例
参考
《统计学习方法》——李航 《机器学习》——周志华 贝叶斯通俗易懂推导
