

蒙特卡罗树搜索,他就是AlphaGo用到的最主要方法。
蒙特卡洛树搜索的主要目标是:给定一个游戏状态来选择最佳的下一步。和之前我们讲过的基于模型或者不基于模型的learning方法不一样,之前讲的方法都是通过模拟的经验或者现实的经验,直接逐渐改进策略和值函数然后可能把他们记录在表格上,然后去下围棋的时候,通过查表去选择动作,相当于是没有确切目标的盲目的搜索。而我们的MCTS是在决策时刻做planning,他的意思也就是说,我从当前我处于的状态,往前进行一定程度地搜索,做planning,然后估计一下当前状态的各个动作值,然后选择最好的那个动作,提高了搜索效率,将计算资源和时间全部集中在当前的这个状态,是可以真实运用到棋牌类游戏的方法。
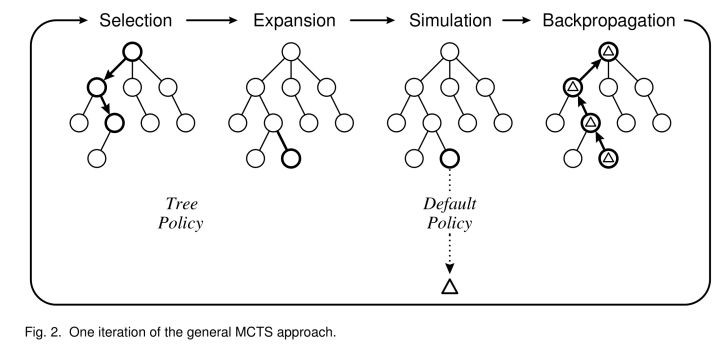
MCTS的算法分为四步。
第一步是Selection,就是在根节点下找到一个最好的值得探索的子节点,首先我们优先选择没有被探索过的子节点,
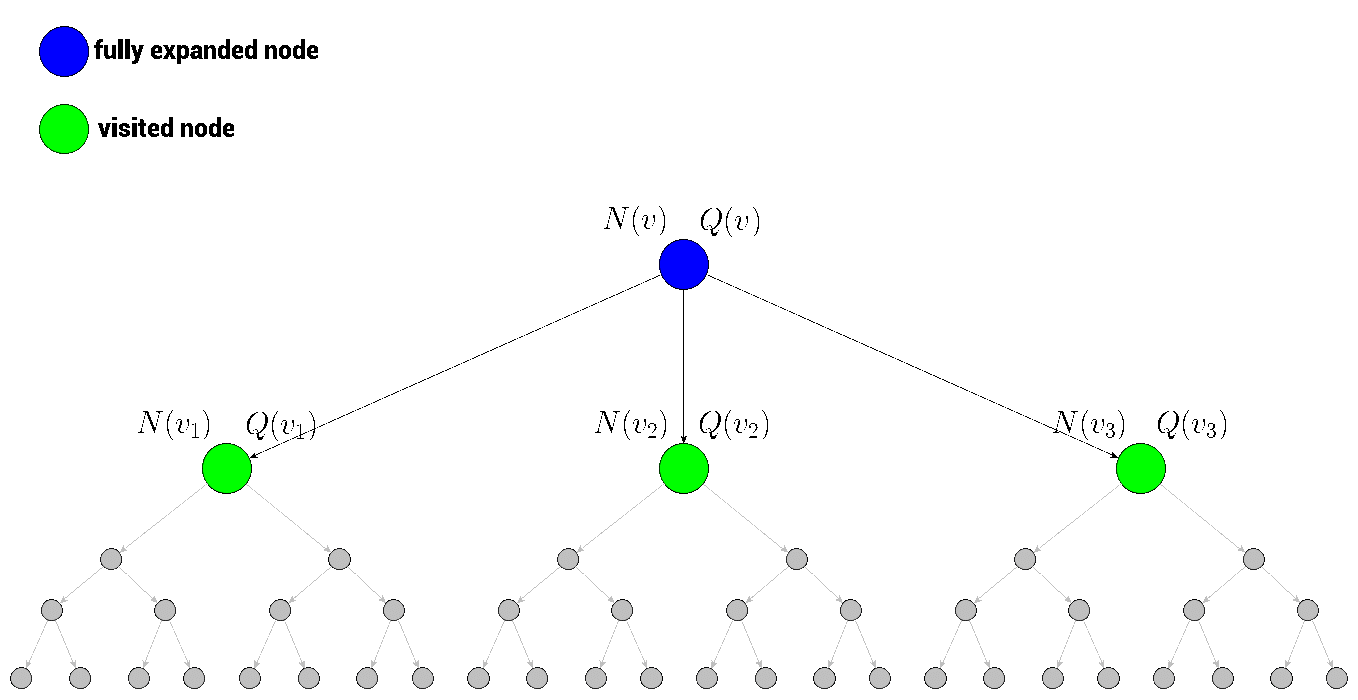
没有被探索过也就是说没有以它为起点产生过一次模拟经验,也就是说它没有被估值过,当一个根节点下面的所有子节点都是被探索过的,那么我们就称这个根节点 is fully expanded(被完全扩展了)。
如果一个根节点是被完全扩展了的,也就是它的子节点都被探索过。那么我们该如何选择呢?这时候我们就通过tree policy: ε -greedy或UCB(选择UCB值最大的子节点。)来对子节点进行selecion选择。
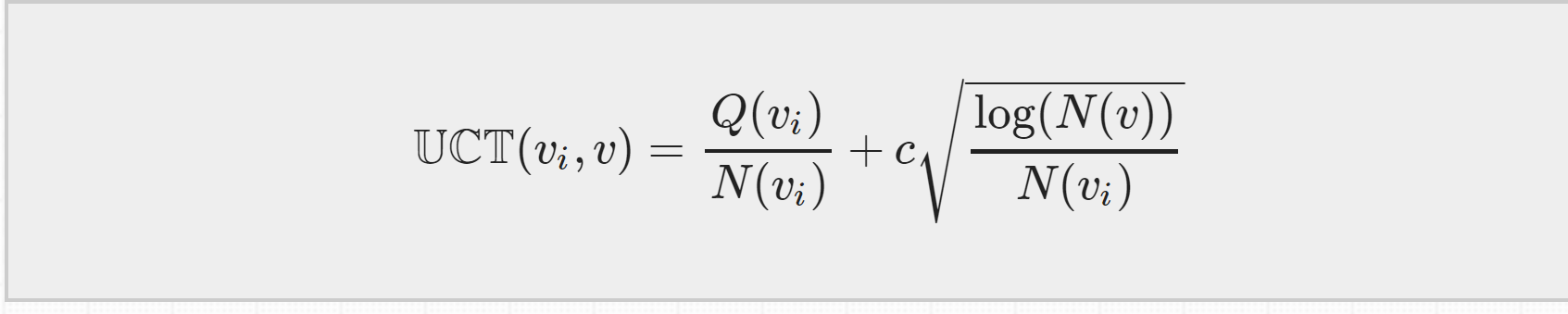
UCT = MCTS + UCB ,等下再来介绍他的公式,只要知道是根据它来选择子节点的就行了。
选择完一个子节点之后,第二步就是expansion。从前面选择到的那个子节点1往下随机走一步创建一个新的子节点2。
第三步就是 simulation,我们以子节点2为起点,使用rollout 算法产生许多条模拟经验,然后立刻像MC一样取各个模拟经验估值的平均来估计出子节点2的值。它和一般的MC不同之处在于,它产生模拟经验不是为了逐步改进策略和值函数,它只关注作为起点的节点,估计出节点的值并使用之后,它会立即丢弃掉这些估计值,所以,rollout算法只是为了更快速地估计出初始节点的值,可以节省更多时间,然后rollout policy默认设置为随机均匀地选择动作。
我们估计出子节点2的值之后,第四步backup,从子节点2开始,一路往回更新子节点1和根节点的值。我们这里的值指的是在回溯过程中,各个节点的累计回报Q值和各个节点被访问的次数N
这四步过程会一直持续的迭代,直到达到计算资源、时间资源的极限,迭代就会停止,然后我们就从根节点出发在现实中选择一个最优动作。而选择最优动作的依据就是根据第一步selection中提到的UCB 公式,因为是在MCTS中使用它,我们也把他成为UCT公式
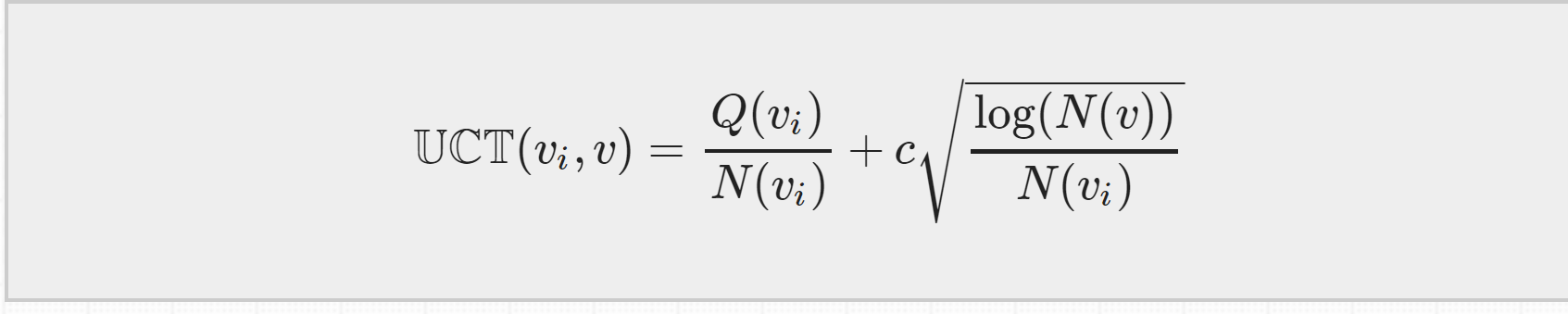
UCT公式分为两个部分:第一部分是exploitation component,各个叶节点的总的汇报Q除以它被访问的次数N,表示的是平均reward,平均reward越大,第一部分的值就越大。
第二部分是exploration component,如果某个叶节点的访问次数越少,第二部分的值就会越大。
所以这个公式平衡了探索和开发,不会陷入局部最优的情况。
所以当我们结束迭代的时候,哪一个叶节点的UCT值最大,我们在现实中就选择这个最优动作。**
MCTS整个的基本思路就是这样,我们首先从根节点(也就是我们现实中处于的状态)根据tree policy选择一个值得探索的叶节点1,然后从叶节点1往下扩展一步,来到了叶节点2,然后以叶节点2为起点,开始用rollout policy产生模拟经验,得到Q和N的信息,然后一路backup回去更新各个母节点的UCT值,不断地重复这一过程直到计算资源和时间耗尽,我们就选择UCT值最大的那个动作,移动到一个叶节点,整个叶节点就又变成了一个根节点,重复上面的过程展开成一棵树,进行动作的选择。
以上所说的是Alphago用到的核心的原始算法,之后有时间再介绍一下Alphago用到的变体UCT算法,以及结合深度学习的一些内容。
