

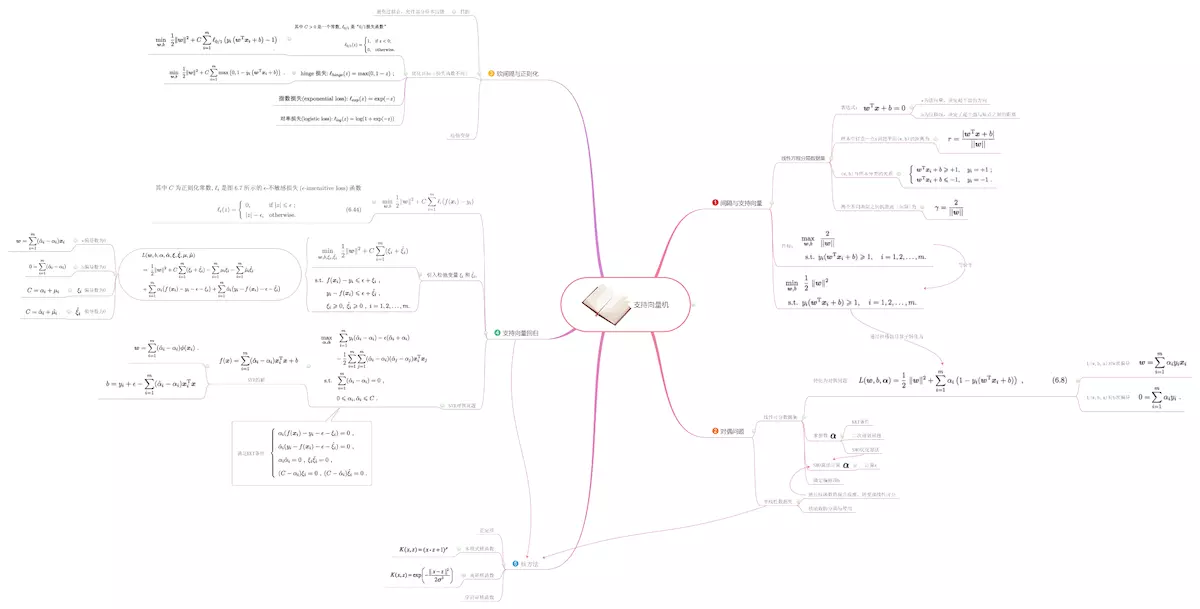
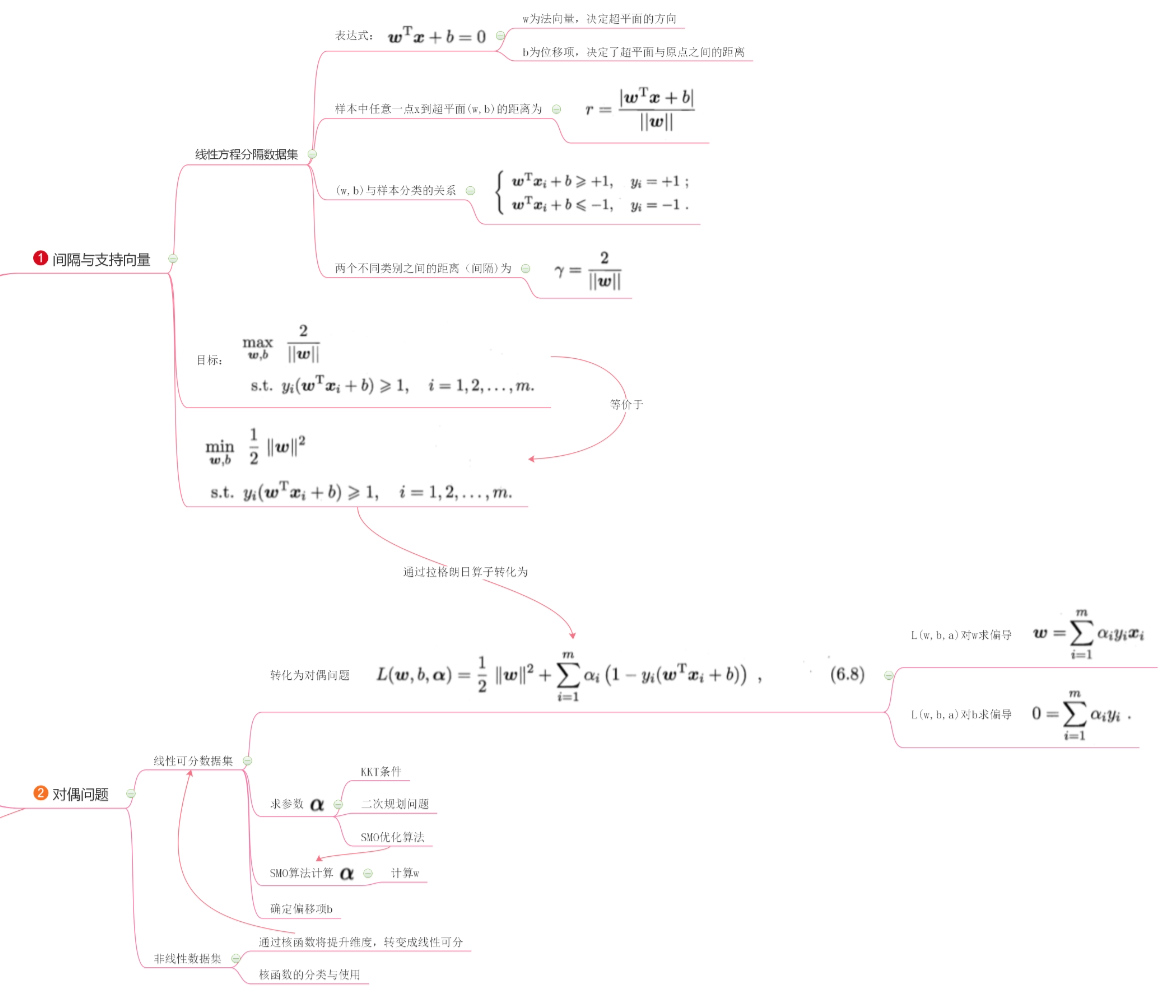
1. 间隔与支持向量
1.1 几个概念
支持向量机与感知机类似,都是在样本空间中找到划分超平面,将不同类别的样本分开。在样本空间中,划分超平面可以使用线性方程进行描述:
其中,为法向量,决定了超平面的方向,
为位移项,决定了超平面距离原点的位置。
一般来说,决定了点
到超平面的距离;
与
的符号是否一致决定了分类是否正确。
另外,做以下定义:函数间隔、几何间隔、间隔、支持向量。
1.1.1函数间隔
对于给定的训练数据集和超平面
,定义超平面
关于样本点
的函数间隔为
令:
1.1.2 几何间隔
当我们成比例的改变和
时,函数间隔也会发生等比例的变化,因此,对分离超平面的法向量
规范化,令其模长为1,使得间隔确定,此时称为几何间隔。
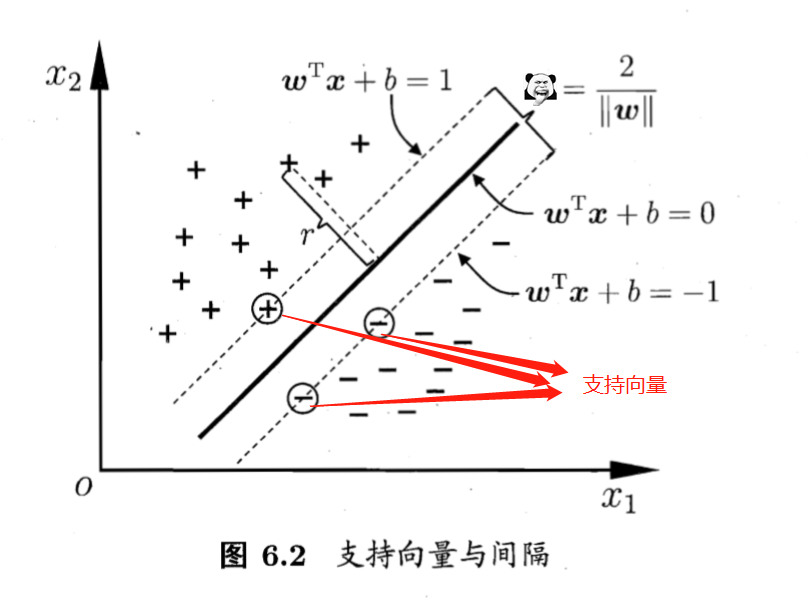
1.1.3 支持向量
间隔越大,说明不同类分的越开,因此可以把目标理解为:
而在公式(1.5)中,为何值并不影响最后的求解,因为
与
成比例变化。因此,取
。
那么,若存在
,距离超平面最近,有
,那么这
个训练样本点被称为支持向量。其中两个异类支持向量到超平面的距离之和为:
1.2 小结
- 其实这一部分与感知机没啥区别,就是定义了几个概念:函数间隔,几何间隔,支持向量。
- 观察图6.2可知,决定参数
的其实就只有支持向量这
个点,其他的点你皮任你皮,对我模型结果毫无影响。

2. 问题优化
2.1 确定目标
公式(1.5)就可以理解为:即要求(2只是一个系数,不用过分在意)
引入拉格朗日乘子,构造拉格朗日函数,借助对偶问题(啥是对偶问题?),有:
分别计算对
和
求导,并令其为
:
将(2.3)代入(2.2),则有:
根据(啥是对偶问题?)可知,公式(2.4)的KKT条件为:
2.2 换个角度
求公式(2.4)的最大等价于求公式(2.5)的最小:
接下来,如果解出每一个就可以算出
。具体怎么求,稍后再说。
又因为前面提过:若存在,距离超平面最近,有
,那么这
个训练样本点被称为支持向量。其中两个异类支持向量到超平面的距离之和为:
所以,在已知了每一个之后,可以计算出
分别为:
其中为支持向量样本中的任意一个值。为了保持鲁棒性,
使用所有支持向量计算其均值,因此:
其中,样本空间的大小,
为所有支持向量组成的样本空间大小,
是一个
维的向量。
留疑!!!
- 问题1:到目前为止,计算出的
和
都没有体现: "决定参数
结果是不是能体现。。。
- 问题2:西瓜书中的


解答:
- 问题1:记
为最后的计算结果,在这个计算结果中,一定有一个值(记为
)满足
,而且有其所对应的
正好满足
。
- 为什么一定有一个
,那么根据公式(2.6),有
,在拉格朗日乘子、KKT条件与对偶问题中提到过,如果拉格朗日乘子为0,说明所有的点都在限制条件所构成函数边界的内部,也就不存在什么支持向量了。所以,一定有一个
- 为什么
,那么,在
- 问题2:《统计学习方法》里面是整个样本空间,不是支持向量构成的样本空间,而且西瓜书里没交代
是什么鬼,所以单方面宣布是笔误好了qwq。

3. 线性支持向量机和软间隔最大化
3.1 线性支持向量机
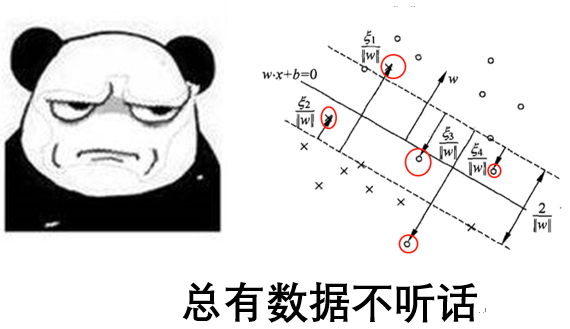
训练集中总有数据(记为)不能满足
这个条件(红圈中的点),删又不能删,只好帮他一把,修改一下底线,引入松弛变量
。这种修改底线的做法,叫做软间隔,原先叫做硬间隔。
这样,就有了:线性支持向量机(我要吐槽一句,不知道谁取的名字,误导性炒鸡强,人家本意原来是:数据集为线性不可分时的线性支持向量机。。。)
为了使软间隔最大化,限制条件变为:
目标函数变为,
其中,这里,称为惩罚参数,一般由应用问题决定,
值大时对误分类的惩罚增大,
值小时对误分类的惩罚减小。最小化目标函数(1.2)包含两层含义:
尽量小,即间隔尽量大。
- 使误分类点的个数尽量小,C是调和二者的系数。
3.2 确定目标
引入拉格朗日乘子,构造朗格朗日函数:
公式(3.3)分别对 求导:
令(3.4)中三式均为0,代入公式(3.3)中有:
因为我们的重点是求,所以对
的限制条件越多越好,所以公式(3.5)又可以写成
3.3 线性支持向量机的支持向量
在下图中,分离超平面由实线表示,间隔边界由虚线表示,正例点由“。”表示,负例点由“×”表示。
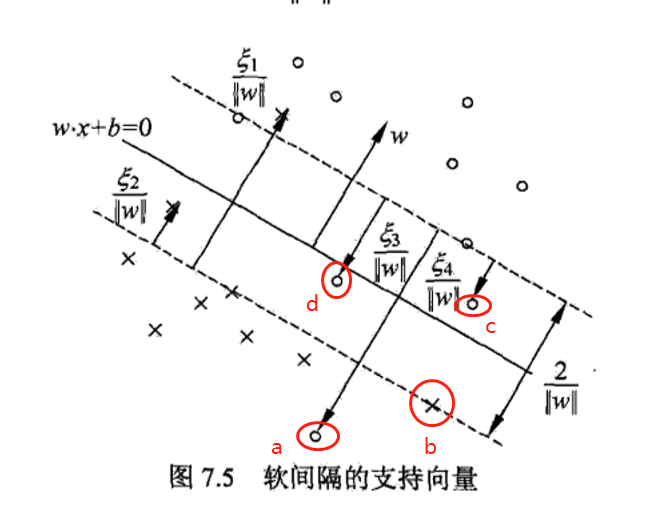
留疑!!! abcd这些点与
之间的对应状态是怎样的?
解答 先看看公式(2.2)和公式(3.3):
其KKT条件为:
根据(啥是对偶问题?)可知:
- 若
则点不会对
有影响,故而是大部分远离支持向量且正确分类的点,有
。
- 若
,则说明必有
。
- 若
,因为
,所以
,则
,此时为支持向量,如b点。
- 若
,因为
,则有:
- 若
,此时落在最大间隔内部,如c点。
- 若
,此时误分类,如a,d点。
4. 核技巧
4.1 核技巧之劳动改造
上面的数据集都有一个要求:那就是数据集线性可分,再不济也要基本可分(即大部分的点要线性可分),但是,如果数据集超出了容忍的底线怎么办?比如过像这样,下图这类数据集就GG了。
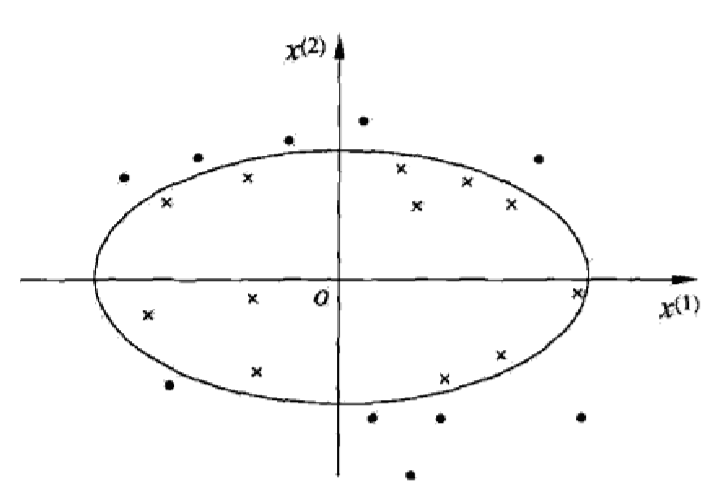
对于这种不听话的数据集,我们需要对其进行改造:具体咋改造呢?请参见核技巧。改造之后的数据集如何使用呢?观察到在公式(3.6)中,
只涉及输入实例与实例之间的内积。因此,可以用使用核函数代替,此时,公式(3.6)变为
这样,经过映射函数将原来的输入空间变换到一个新的特征空间,将输入空间中的内积,变换为特征空间中的内积
,在新的特征空间里从训练样本中学习线性支持向量机。当映射函数是非线性函数时,学习到的含有核函数的支持向量机是非线性分类模型。
4.2 核技巧之重返社会


5. 问题求解
观察公式(2.5)和公式(4.1),可知,该问题是一个二次规划问题[1],使用Sequential Minimal Optimization(SMO)算法求解。
5.1 SMO基本思路
先固定除了之外的所有参数值,求
上的极值,由于有
的约束条件,因此,另一个参数值
也可以用
表示,因此,SMO方法一次可以优化两个参数
和
,并固定其他参数。
###5.2 基本流程:
- 选取一对待更新的变量
和
。
- 固定
书上的简单例题。



6. 小结
线性支持向量机的算法总结流程图如下:

7. 参考文献
《统计学习方法》 《西瓜书》
注脚——凸二次规划问题:

,这里,
是一个
矩阵,
是一个
维向量,
是一个
