Problem:
1虽然TD保证了即时性,那么它有没有保证正确性呢?幸运的是这一点是成立的。当上面的step-size parameter 恒定且足够小或者逐渐递减但是满足随即近似理论,最终的结果都是可以保证收敛的。随机近似理论第二章提到过:
2“batch updating
每一个新产生的episode,都会和之前所有经过的episodes一起算作新的batch,然后整体更新value。为什么TD竟然能比MC的最优估计还要好?原因是MC的最优是有限制的,而TD的最优更适合这种“不断添加新数据”的更新规则。
可是,面对新加入的episode,当进行“batch updating”时,你愿意得到那个答案呢?其实第一个才是更合理的,尽管它在当前的误差并不比MC小,但是它可以在新的数据加入时,逐渐得到更小的误差,它的泛化能力更强,也可以说TD能学到这批episode数据背后的规律。为什么呢?因为它引入了相邻变量之间的联系,说白了也就是引入了DP的bootstrap思想,而这个区别帮助TD找到了数据背后的规律。
MC算法每次都要等到episode序列结束,在等待过程中会引入大量的不确定性,最终的估计结果则自然带有很大的波动,也就是方差会很大。 ?
可以看出TD可以学到当前数据相关的马尔可夫模型的最大似然估计?
从图中可以看出,即使 α=1 ,Expected Sarsa 也一样能够收敛(此时其形式很接近 DP ),而 Sarsa 则只能在 α 较小时才有好的表现。
最大化操作下的估计值,很大概率会是正值,因此产生了正偏差?
Note:
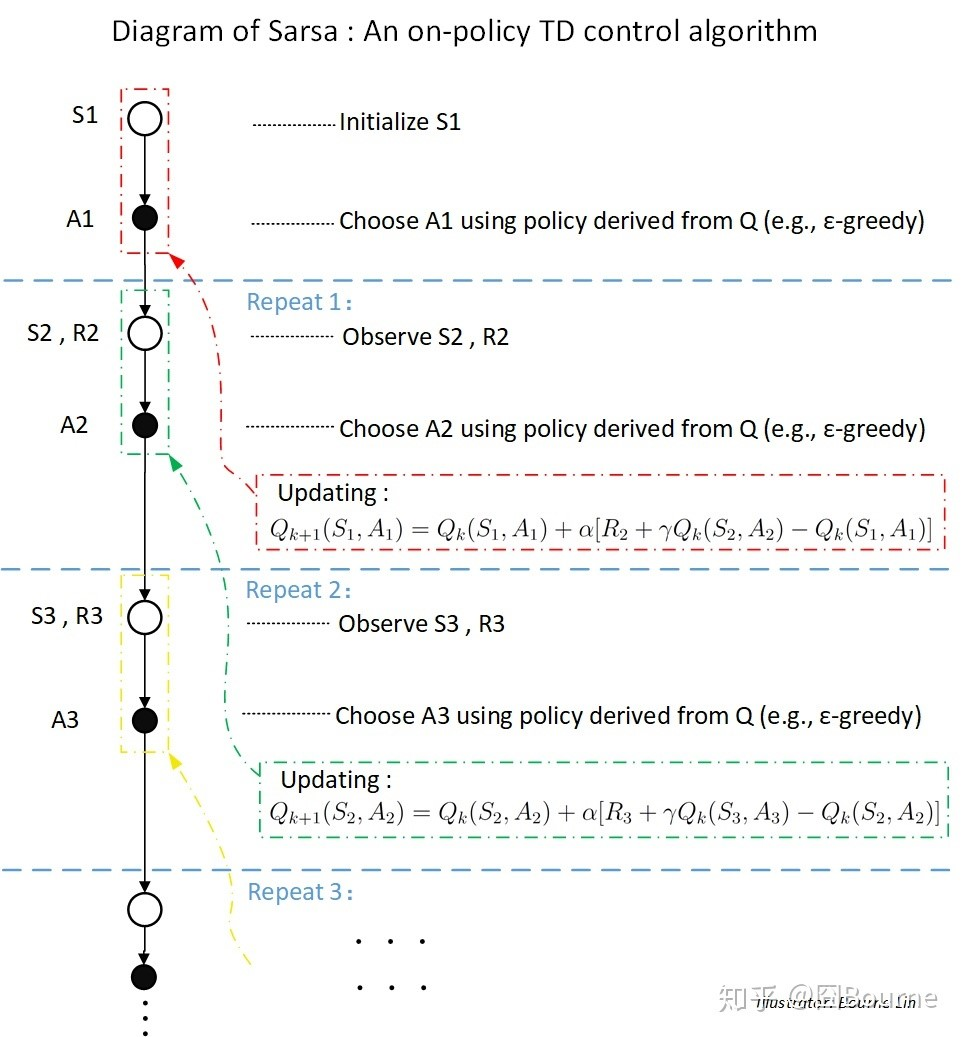
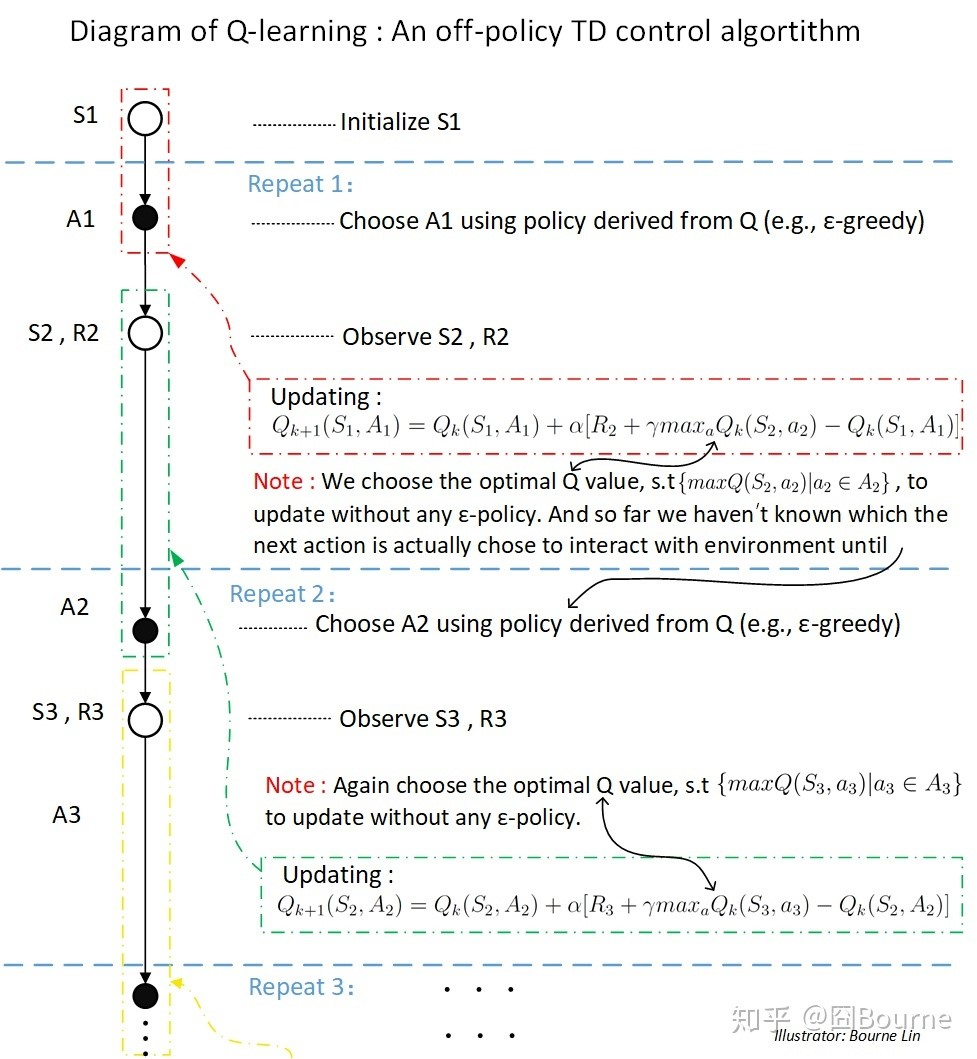
Sarsa和Q-learning的区别:QL(和expected Sarsa)更新Q值没有用到behavior policy产生的下一个动作。Sarsa用policy产生的下一个动作的值来更新Q值。