

2.4 主对象树
双击相应的图标,就会立即创建一个转换或者作业文件,打开工作区且该区域切换为核心对象,以方便你进行下面的设计工作。而主对象树将以目录树的形式展示转换或者作业的各种信息。
2.4.1 转换的主对象树
新建一个转换后,你的主对象树将展现为下面这样子。
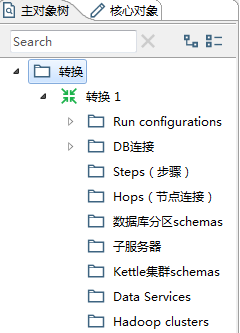
这些图标都是可以点击的哦!
- 双击“转换”将再次新建一个转换文件;
- 双击“转换 1”,即转换文件名称,将打开当前转换的属性面板;
- Run configurations:可以查看当前的运行设置,也可以新建一个,还没用过,后期补充;
- DB连接:可以查看当前的数据库连接,双击可以新建一个数据库连接;
- Step(步骤):查看当前都用了哪些组件;
- Hops(节点连接):查看当前所有的Transformation-Hop,双击可以新建一个Transformation-Hop来连接两个Step,只不过一般不这么用;
- 数据库分区schemas;
- 子服务器;
- Kettle集群schemas;
- Data Services;
- Hadoop clusters。
后面5部分的功能,我也没用过,后期补充。从这里开始下面罗列而未介绍的功能点,后期再补充。
2.4.2 作业主对象树
新建一个作业后,你的主对象树将展现为下面这样子。
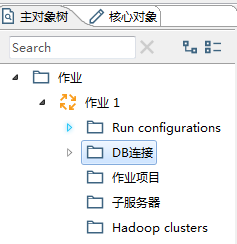
这些图标同样都是可以点击的!
- 双击“作业”将再次新建一个作业文件;
- 双击“作业1”,即作业文件名称,将打开当前作业的属性面板;
- Run configurations:可以查看当前的运行设置,也可以新建一个,还没用过,后期补充;
- DB连接:可以查看当前的数据库连接,双击可以新建一个数据库连接;
- 作业项目;
- 子服务器;
- Hadoop clusters。
2.5 核心对象
因核心对象的内容偏多且杂,同时是我们平时主要使用的工具。这里我将讲一个小的例子,来讲述几个我们平时经常用到的组件。后期会将“核心对象”分为单独的两章“转换核心对象”和“作业核心对象”来介绍,详情请参见后面的章节。
下面我们要讲的例子是:读取一个MySQL数据库中的两张表的信息,做Join连接,再输出到另一个MySQL数据库中。
2.5.1 新建转换(Transformation)
关于如何新建转换,Kettle为我们提供了多种方式,充分体现了“条条大路通罗马”的思想,你只需要选择一个自己习惯的方式即可。
如果忘记了怎么创建,请再仔细阅读一遍前面的内容吧。
新建一个转换之后,会立即打开一个画布(工作区)。为什么叫画布呢?用过Visio、Xmind、Axure的你们肯定非常熟悉这类工具,软件将各种我们平常使用的功能都封装成了一个个的组件,我们只需将需要的组件拖拽至画布,并在每个组件之间通过连线建立联系来完成我们的种种需求。而Kettle的组件被称为Step(步骤),不过你可能发现了我前面都是用的“组件”,因为感觉这是一个比较通用的名称。
画布已准备就绪,你就开始发挥自己的想象力,通过往里面添加组件,完成一幅惊世画作吧!
下面,我们将一步一步地完成这个小例子,来介绍下Kettle设计Transformation的过程,并着重介绍下这几个组件。
2.5.2 表输入(Input Table)
在左边的核心对象中,有很多文件夹,其实就是Kettle对不同组件的分类。每个文件夹下面都有很多不同的组件。
现在需要从源表中读取数据,可以理解为往程序里输入数据,所以要去“输入”文件夹中看看是否有我们需要的组件。你会发现这么有很多组件,如CSV文件输入、文本文件输入等,但这些都不是我们想要的,然后你会看到一个名为“表输入”的组件,就是它了,将它拖至画布即可。
需要的组件找到了,下面我们就来看看如何使用它吧?
双击画布中的“表输入”,会出现下面这个对话框:
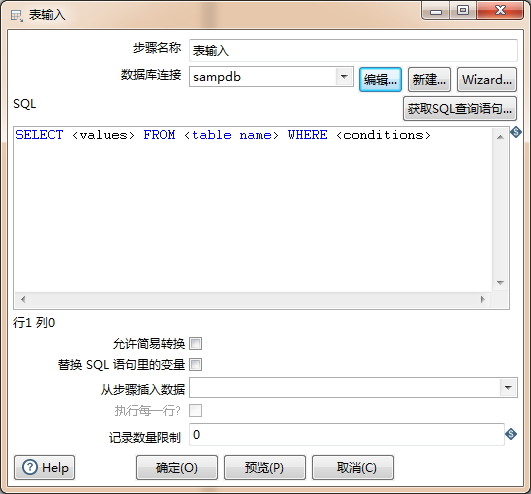
如你所见这个对话框有很多的属性,多到你一眼看过去,可能有点儿晕。在此我需要提前给你来个提醒,不要大惊小怪,后面章节“核心对象”中讲到的某些组件的属性比该组件多几倍。
这里我们先讲我们这个例子会用到的属性,其实它们都很好理解的。
- 步骤名称:就是给该步骤起一个通俗易懂又显而易见的名称,但需要注意在整个转换中步骤名称是唯一的,不可重复。
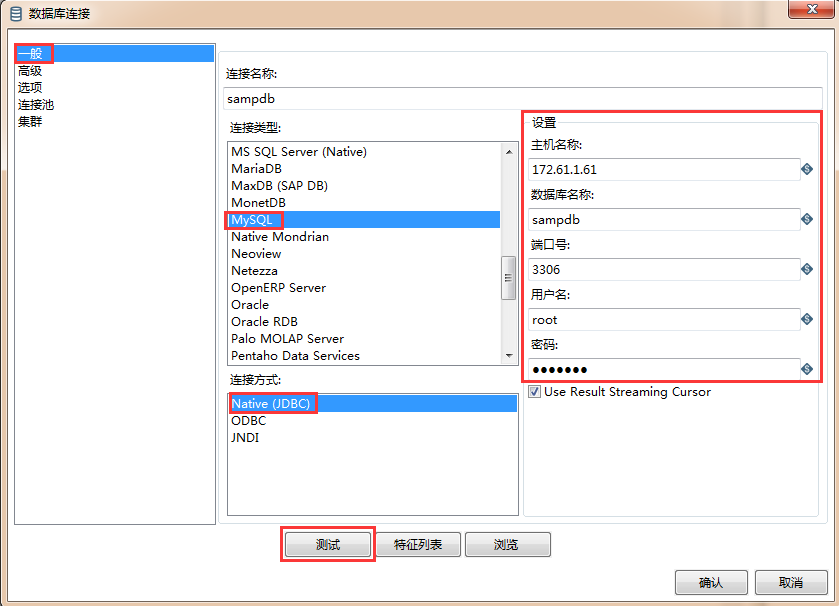
- 数据库连接:初次使用肯定是先需要创建一个数据库连接的,此处提供了两种方式。其实我们前面都已经介绍过了,“引导创建数据库”我觉得它比较啰嗦就不介绍了,也许你对它情有独钟,那就自行研究吧;此处再来展示下“新建”这种方式吧, 因为我们经常会用到它,不是因为我想凑字数呦~还是以MySQL为例,数据库连接展示图如下:
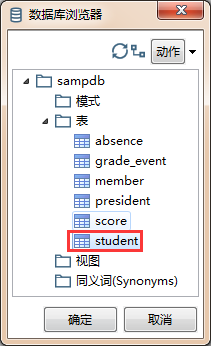
- 获取SQL查询语句:当你创建好数据库连接并选中它时,可以通过该按钮查看其表结构:
- SQL:这个编辑框是根据你数据库连接中选中的表动态生成的,这才是我们主要的工作区域,将多张表的连接SQL语句写在这里作为输入。
- 记录数据限制:指的是从源表中抽取多少条数据,默认为0表示数据没有限制,即将源表中的所有数据全部抽取出来:
- 预览:就是提前看看该步骤得到的数据是否满足你的需求,这里我们选择前10条展示下该功能。
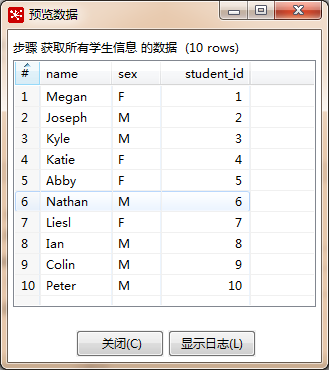
然后我们再拖拽一个表输入组件,命名为“获取所有分数信息”,选择好数据库连接“sampdb”,这次我们在SQL编辑框中自己写SQL语句:

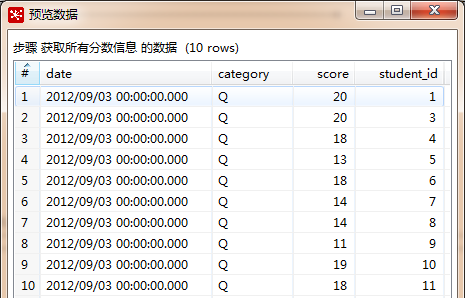
这里通过关联grade_event(考试事件)和score(分数),来获取每次考试的日期、类型、分数、学生ID等信息。
预览下效果:
到此两个表输入的组件我们就创建完毕了。
2.5.3 记录集连接
接下来我们需要连接操作,恰好“核心对象”中有“连接”这个文件夹,从中拖拽“记录集连接”至画布,然后用Transformation-Hop将它们连接起来,如下图所示:
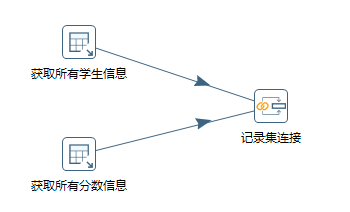
怎么创建Transformation-Hop呢?还记得我们前面讲的“主对象树”不?打开它双击Hops(节点连接),出现下面的对话框:
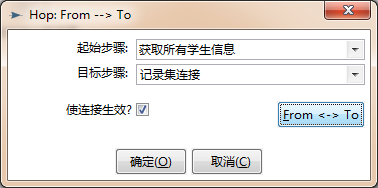
Transformation-Hop可以简单地理解为数据的流向,即数据从“起始步骤”流出,流入“目标步骤”。“From < -- > To”就是将两者的互换一下。点击确定后,Transformation-Hop就自动出现了。一条带箭头的线从“获取所有学生信息”指向了“记录连接”。
好吧,我很大度,为人很好,不会藏私的,将快捷方式介绍给你吧。按住Shift键,将鼠标箭头移至“获取所有学生信息”按住鼠标左键不动,往外移动鼠标,此时会出现一条置灰的带箭头的线,将鼠标拖至“记录集连接上”,松开鼠标左键,这样一条完美的线条婀娜的线就创建成功了。
双击“记录集连接”,得到如下属性对话框:
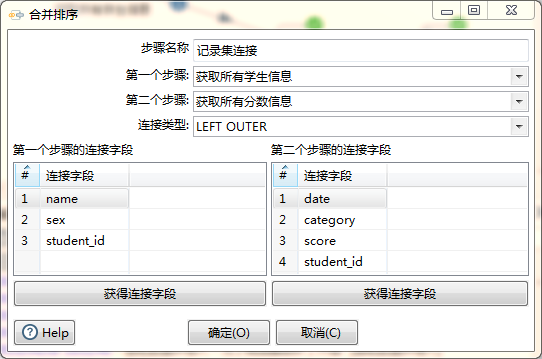
- 步骤名称:不用再多介绍了吧。
- 第一个步骤:就是连接的基表,从列表中选择“获取所有学生信息”。
- 第二个步骤:就是连接表,从列表中选择“获取所有分数信息”。
- 连接类型:就是我们常用到的Join、Left Join、Right Join等,这里默认。
- 获得连接字段:点击后,将相应步骤的所有字段都拉取出来,这里我们只留student_id,其他的都可以右键点击相应字段删除掉。
是不是很想看看这部分的数据呈现是否正确,可是却找不到像“表输入”属性对话框一样的“预览”按钮。别急,难道你忘了“大明湖畔夏雨荷”了吗?菜单栏“执行”的“预览”选项、转换工具栏的“预览”图标,都可以达到预览的效果,此处我们选择用快捷键“F10”,嘿嘿~
在下面的对话框中,选中左边的“记录集连接”,勾选右边的“获得前几行(预览)”,最后填入你想看到的行数,点击“快速启动”。
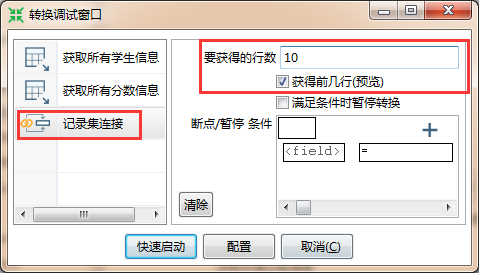
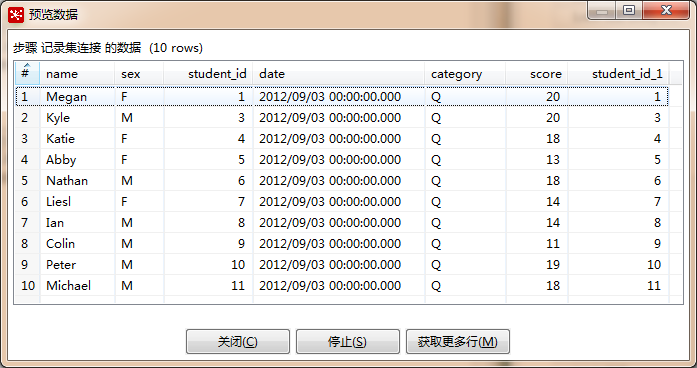
此时该转换程序就会启动,并运行至“记录集连接”这步,弹出“预览数据”列表,查看数据是否达到要求,并点击“停止”终止转换退出。期间你会看执行结果窗口的呈现,先不用理它,后面我在细讲。
2.5.4 表输出
数据已经从源表中抽取,并完成了连接,就差一步了,再听我啰嗦啰嗦呗。
从“核心对象”的“输出”文件夹中,将“表输出”拖拽出来,并创建它与“记录集连接”的Transformation-Hop。
双击“表输出”,得到其属性对话框:
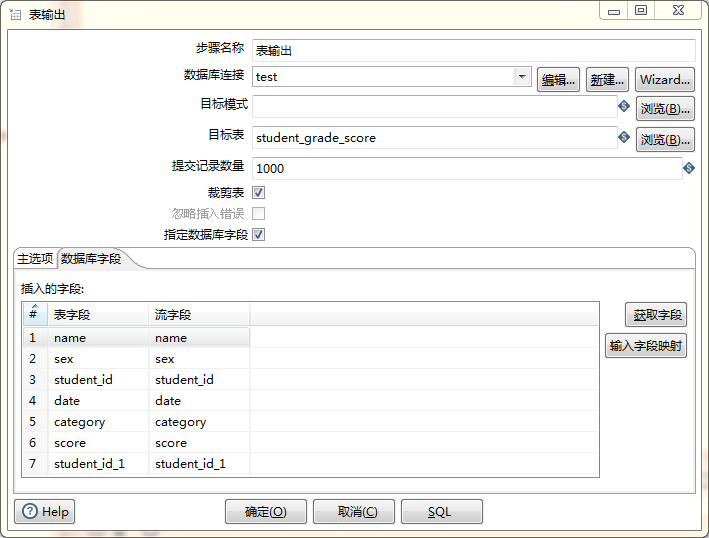
- 步骤名称:记住不可重复。
- 数据库连接:这里我们又新建了一个test。
- 目标模式:就是选择数据库连接中的数据库,但是这里数据库连接里已经选择了数据库,所以点击“浏览”获取不到任何信息。
- 目标表:就是整合后的数据要导入的表,通过点击“浏览”打开“数据库浏览器”进行选择,也可以手动填写。
- 提交记录数量:在数据表中用事务插入行的行数,如果N比0大,每N行提交一次连接。否则,不使用事务,速度会慢一些。
- 裁剪表:就是对目标表执行“Truncate Table”操作,清空其原始数据,之前我们着重介绍过,希望你没有忘记它。
- 指定数据库字段:这个是必须勾选的,反正每次我都会勾选。勾选后,Tab页“数据库字段”的“获取字段”和“输入字段映射”才会可点击。
- 两个Tab页:
- Tab页“主选项”:
- 表分区数据:使用这个选项可以在多个表之间拆分数据。
- 表名定义在一个字段:使用这些选项可以拆分数据到一个或多个表里,目标表名可以用你指定的字段来定义。例如如果你想存储顾客性别数据,这些数据可能会存储到表M和表F里面(female 女性和male 男性表)。这个选项可以阻止这些字段插入到对应的表里。
- 批量插入:如果你想批量插入的话,就使用这个选项。这个选项的速度最快,默认被选上。
- 返回一个自动产生的关键字:往表中插入行时,是否产生一个关键字。
- 自动产生关键字的字段名称:指定包含关键字的输出字段的字段名称。
- 指定数据库字段:只导入指定的字段,多余的字段忽略。
- Tab页“数据库字段”:
- 获取字段:Kettle会把上一个步骤“记录集连接”输入过来的所有字段都拉取出来,并与目标表的字段做名称上的对应,若目标表没有的字段直接命名为输入字段名。有点绕口哈。如你感觉Kettle自动生成的映射有问题,你可以点击相应的字段名,会出现下列列表供你选择应该对应的字段名。
- 输入字段映射:初次点击也许会报错,因为有些表字段在目标表中并不存在,若这些字段确实不需要你可以删除它们。删除后再点击“输入字段映射”,会出现如下对话框:
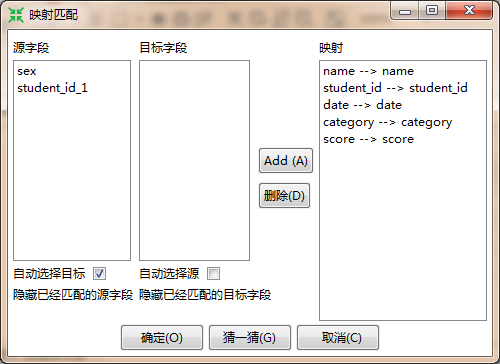
- 如果需要调整对应关系的话,可以在映射区,选中一个,然后点击删除,它们之间的映射关系就不存在了,重新回到了源字段和目标字段;
- 在源字段、目标字段分别选中一个字段,然后点击ADD,它们就会出现在映射区;
- 点击猜一猜,Kettle会自动给你创建相应的连接,是根据字段名匹配的,所以前面的步骤你可以有意识地命名一些与目标表字段名相同的名称。
- 获取字段:Kettle会把上一个步骤“记录集连接”输入过来的所有字段都拉取出来,并与目标表的字段做名称上的对应,若目标表没有的字段直接命名为输入字段名。有点绕口哈。如你感觉Kettle自动生成的映射有问题,你可以点击相应的字段名,会出现下列列表供你选择应该对应的字段名。
- Tab页“主选项”:
- SQL:点击右下角的“SQL”,会对“插入的字段”中的“表字段”与目标表的字段进行对比,若有目标表不存在的表字段会出现如下对话框:
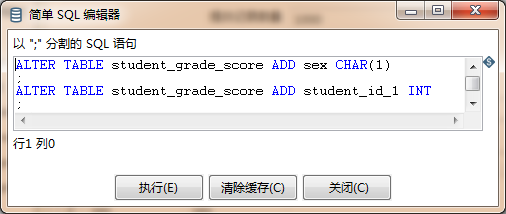
根据需求若这些表字段确实需要保留,可以点击“执行”来修改目标表的表结构新增这些字段。
2.5.5 小例子转换的整体效果图
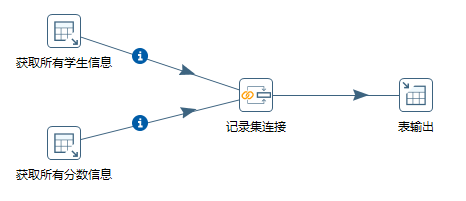
是不是感觉我其实挺有艺术气息的,哈哈~
此时,我们就完成了这个小例子“从sampdb数据库查出学生信息和分数信息,并导入test数据库中的student_grade_score表中”
2.5.6 执行转换
按快捷键“F9”(其他的方式你自己尝试,我就是这么懒,爱用快捷键),执行该转换。 执行结果如下所示:
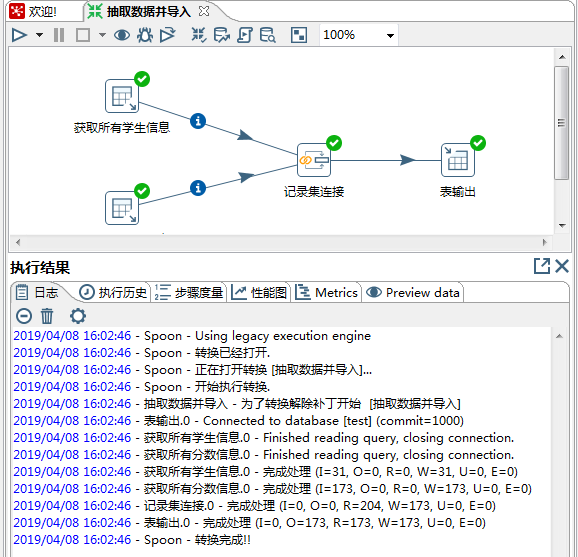
多完美,都是绿色的√号,说明该转换成功执行,没有任何错误。
其实这是同一个数据库的信息获取,完全可以通过编写SQL用单个“表输入”解决,就像第二个“表输入”中的SQL语句。这里为了例子的丰富性,就用两个“表输入”加“记录集连接”来呈现。实际中,我们经常要从不同的数据源整合数据,再导入到其他的数据库,这个例子是非常简单的基础运用。
2.6 执行结果
这里沿用“2.5 核心对象”中的小例子。
2.6.1 日志
日志里记录了一些运行信息,即每个步骤的执行情况。
- 执行成功后,日志如下图所示:
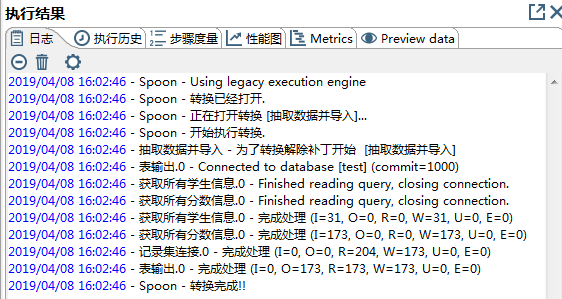
- I:表示从表中读取了多少行数据;
- O:表示向目标表中写入了多少行数据;
- R:从之前的步骤中读取了多少行数据;
- W:向下一个步骤写入了多少行数据;
- U:当前步骤更新过的记录数;
- E:当前步骤处理的记录数。
- 这里我故意在“表输出”中“表字段”添加了“student_id_1”这个目标表并不存在的字段,造成该转换无法执行成功。
执行不成功的日志如下图所示:
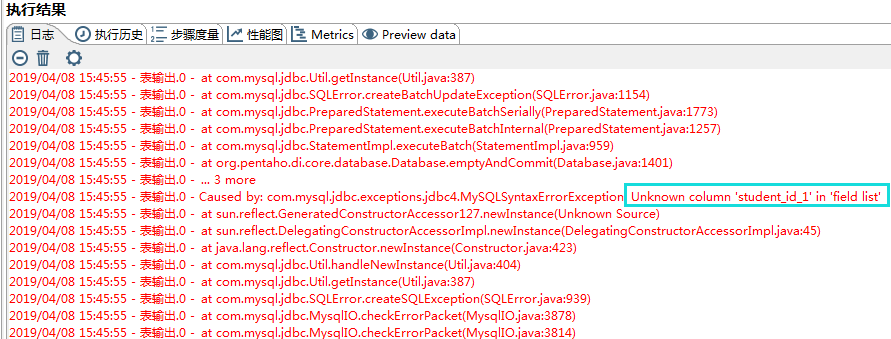
日志中明确指出了“Unknown column ‘student_id_1’ in ‘field_list’”,即student_id_1在目标表中不存在。
当报错后,查看日志,能让我们获取其报错原因,有利于修改步骤。
2.6.2 步骤度量
如下图所示,这里记录每个步骤执行的一些度量信息。
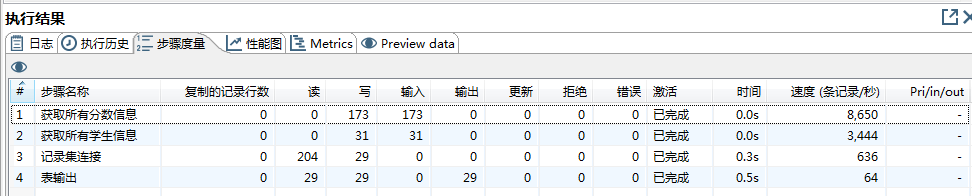
- 读、写、输入、输出、更新、拒绝和错误的行数;
- 激活是运行的状态,错误的话整行都会出现红色背景;
- 时间就是运行的时间;
- 速度:就是处理数据的速度,单位为“条记录/秒”。
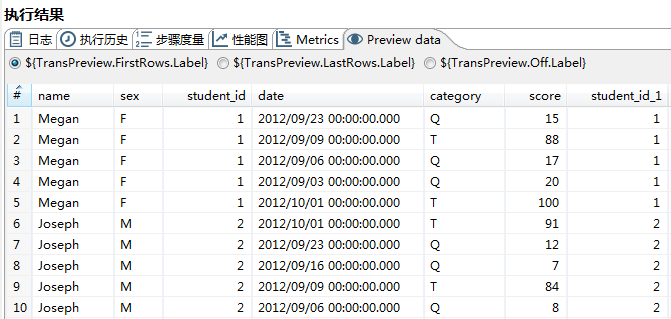
2.6.3 Preview data
执行完后,可以浏览每个步骤的数据,查看这个Tab页,然后点击不同的组件,就会呈现出每个步骤对外的输出结果集。
如“记录集连接”的效果图如下:
结束语
好了,讲到这里我们的Kettle基础教学就结束了。
相信大家肯定对Kettle有了最基本的一些认识,Kettle的架构,Kettle的使用场景,尤其是Kettle的基础结构的理解。然后对Spoon的界面使用做了重点介绍,因为这将是我们使用kettle最常用的工具。最后我们通过一个小例子学习了如何设计Transformation,讲述了三个基本的步骤(我个人还是喜欢用组件来称呼它),并讲述了执行结果,如何预览数据,通过查看日志查找错误原因等知识。
通过以上讲述,希望你能对Kettle有个最基本的认识。
谢谢大家,花费时间看完本文档。如果它对你认识和使用Kettle起到了一定的辅助作用,将是我最愿意见到的事情!
