

第一章 TensorFlow 基础概念
TensorFlow安装
TensorFlow的安装官网已经有很详细的教程。这里不再赘述。我们更多的精力放在理解TensorFlow最基本的三个概念。以帮助我们之后学习神经网络的时候能够学的更加丝滑。
- Tensor(张量)
- Session(会话)
- Graph(计算图)
Tensor(张量)
张量是TensorFlow管理数据的形式,可以简单理解为数组或多维数组。
这么说大家可能没有概念,我们先来看一下一个最简单的张量。
# 定义tensor
v1 = tf.constant(1,name='v1',shape=(),dtype=tf.float32)
v2 = tf.constant(2,name='v2',shape=(),dtype=tf.float32)
# 定义一个tensor运算
add = v1 + v2
# 创建会话,运行运算,这部分会在之后详细介绍
with tf.Session() as sess:
print(sess.run(add)) #输出:3
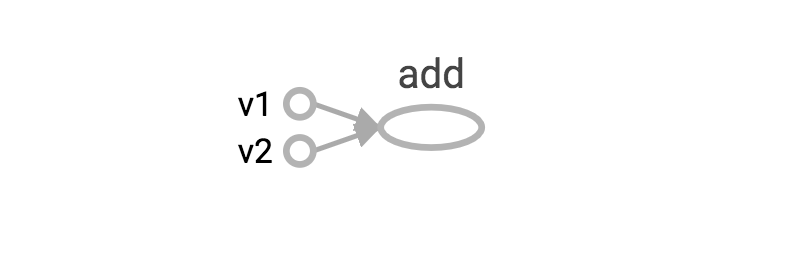
我们可以理解为tensor是TensorFlow中的一个常量,在第一步,我们定义了两个tensor两边v1和v2常量,然后我们定义了一个add常量,它的结果是v1和v2的和。然后我们通过Session(会话)去执行计算,获取计算的结果。
通过上面TensorFlow生产的可视化图片,我能能够直观的感受这以过程。
张量的三个属性
tensor具有三个很重要的属性:name、shape和type。下面我们进行一一介绍。
name
name是tensor的唯一标识符。
# 定义tensor,第一个参数是值;第二个参数是tensor的name;
#第三个参数是tensor的shape;第四个参数是tensor的type
v1 = tf.constant(1,name='v1',shape=(),dtype=tf.float32)
v2 = tf.constant(2,shape=(),dtype=tf.float32)
# 定义一个tensor运算
add = v1 + v2
print(v1) #Tensor("v1:0", shape=(), dtype=float32)
print(v2) #Tensor("Const:0", shape=(), dtype=float32)
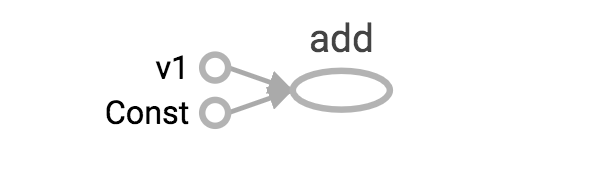
还是上面一样的代码,我们将v2常量定义的时候,不去定义它的name属性,然后直接打印v1和v2,我们可以看到当我们不指定name的时候,TensorFlow会自动帮我们定义name属性。
tensor通过node:src_output的形式展示,其中node就是tensor的name,src_output是当前tensor的第几个输出。例如:v1:0就是v1节点的第一个输出(src_output从0开始)
shape
shape是纬度,它描述了tensor的纬度信息,看一个简单的例子:
# 定义两个二维数组
v1 = tf.constant(1,name='v1',shape=(2,2),dtype=tf.float32)
v2 = tf.constant(2,name='v2',shape=(2,2),dtype=tf.float32)
add = v1 + v2
with tf.Session() as sess:
#[[1. 1.]
#[1. 1.]]
print(sess.run(v1))
#[[2. 2.]
#[2. 2.]]
print(sess.run(v2))
#[[3. 3.]
#[3. 3.]]
print(sess.run(add))
上面这个例子,我们生产了两个shape为二维的tensor,如果你觉得二维这个词比较难理解,其实我们可以直接把它理解成两行两列的矩阵,在深度学习过程中,tensor经常是以矩阵的形式存在。
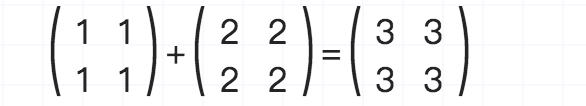
最后我们通过Session(会话)去计算v1+v2的值,它其实代表了矩阵的加法运算。如果对矩阵的运算不太了解的朋友,可以看一下阮一峰老师的关于矩阵的一篇博客。
而tensor有很多维度,在后面的计算运用中我们都会慢慢的接触到。
type
每一个tensor会有一个唯一的类型。TensorFlow会对参与计算的所有张量进行类型检测,当类型发生不匹配时会报错。
#TypeError: Input 'y' of 'Add' Op has type float32
#that does not match type int32 of argument 'x'
v1 = tf.constant(1,name='v1',shape=(1,2),dtype=tf.int32)
v2 = tf.constant(2,name='v2',shape=(2,1),dtype=tf.float32)
add = v1 + v2
上面,我们指定了v1的类型为int32,而v2的类型为float32,两个类型不同的tensor相加,导致了报错。
TensorFlow支持14种不同的类型:主要包括了实数(tf.foat32、tf.float64),整数(tf.int8、 tf.intl6、 tf.int32、 tf.int64、 tf.uint8),布尔型 (tf.bool),和复数(tf.complex64、 tf.complex128 )。
几种创建tensor的方式
tf.constant
生成指定的tensor
# 我们可以通过value和shape去指定tensor的值和维度
v1 = tf.constant(value=1,name='v1',shape=(1,2),dtype=tf.float32)
#[[1. 1.]]
# 也可以直接在value中直接写入带维度的value值
v2 = tf.constant(value=[[1,2,3],[4,5,6]],dtype=tf.float32)
#[[1. 2. 3.]
#[4. 5. 6.]]
tf.zeros
生成全为0填充的tensor
v3 = tf.zeros((1,2),tf.float32,name='zeros')
#[[0. 0.]
#[0. 0.]]
tf.ones
生成全为1填充的tensor
v4 = tf.ones((2,2),tf.float32,name='ones')
#[[1. 1.]
#[1. 1.]]
tf.diag
生成对角矩阵,对角线为指定的值,其他值为0
v8 = tf.diag([1,2,3],name='diag')
#[[1 0 0]
#[0 2 0]
#[0 0 3]]
tf.truncated_normal
生成正态分布的矩阵
v9 = tf.truncated_normal((2,3))
#[[ 0.18460223 -0.11237118 0.61098295]
#[ 0.02013025 0.3336802 -1.0556936 ]]
Variable 变量
我们使用Variable来定义变量,变量表示可通过对其运行操作来改变其值的张量。
tf.Variable创建变量
v1 = tf.Variable(tf.ones(shape=[1,2],dtype=tf.float32),name='v1')
with tf.Session() as sess:
# 初始化变量
sess.run(tf.global_variables_initializer())
print(v1)
# 输出:<tf.Variable 'v1:0' shape=(1, 2) dtype=float32_ref>
我们通过tf.Variable()来初始化一个变量,第一个参数就是我们的tensor,第二个参数是变量的名称,而与tensor不同的是:变量我们必须通过session去通过调用tf.global_variables_initializer()去初始化变量以后才能使用。否则则会报错。
tf.get_variable创建变量
tf.get_variable也能够创建一个变量。具体的创建方法如下:
v1 = tf.get_variable(name='v1',shape=(1,2),dtype=tf.float32,initializer=tf.ones_initializer())
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(v1)
# 输出<tf.Variable 'v1:0' shape=(1, 2) dtype=float32_ref>
tf.get_variable的创建方式的参数也大同小异,唯一区别是我们通过initializer参数去初始化变量的值。
两种创建方式的区别
v1 = tf.Variable(tf.ones(shape=[1,2],dtype=tf.float32),name='same')
v2 = tf.Variable(tf.ones(shape=[1,2],dtype=tf.float32),name='same')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(v1)
print(v2)
# 输出:<tf.Variable 'same:0' shape=(1, 2) dtype=float32_ref>
# 输出:<tf.Variable 'same_1:0' shape=(1, 2) dtype=float32_ref>
我们看到我们定义两个name相同的变量,我们初始化时并不会报错,TensorFlow会为我们重复的变量修改名字成same_1,来避免两个变量名相同。
v1 = tf.get_variable(name='same',shape=(1,2),dtype=tf.float32,initializer=tf.ones_initializer())
v2 = tf.get_variable(name='same',shape=(1,2),dtype=tf.float32,initializer=tf.ones_initializer())
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(v1)
print(v2)
# 报错: Variable same already exists, disallowed.
#Did you mean to set reuse=True or reuse=tf.AUTO_REUSE in VarScope?
当我们用get_variable创建两个相同name的变量时,我们会发现编译会报错,报错提醒我们变量名冲突。那如果我们想重用之前的变量怎么办?
with tf.variable_scope('my_scope',reuse=tf.AUTO_REUSE):
v1 = tf.get_variable(name='same', shape=(1, 2), dtype=tf.float32, initializer=tf.ones_initializer())
v1 = tf.get_variable(name='same', shape=(1, 2), dtype=tf.float32, initializer=tf.zeros_initializer())
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(v3)
print(v4)
# 输出:<tf.Variable 'my_scope/same:0' shape=(1, 2) dtype=float32_ref>
# 输出:<tf.Variable 'my_scope/same:0' shape=(1, 2) dtype=float32_ref>
我们通过定义一个scope,定义为my_scope,此时变量名会变成scope_name/name:src_output。
reuse我们可以定义这个scope中的变量是否可以重用,如果name相同时,我们可以重用之前相同name的变量,并为他重新定义新的initializer。
复盘
本节只介绍了TensorFlow中最重要的tensor和Variable,tensor和Variable在深度学习中的应用非常频繁。在这个过程中,我们可以把tensor理解成一个常量的定义,而Variable则是一个变量,它可以在过程中修改值,但它必须在使用前通过Session进行初始化。
在上面的文章中我们其实隐隐约约有感受到Session(会话)的作用,我们在定义好add计算后,它并不会被立刻执行得到结果,而需要通过Session的帮助进行计算,从而得到结果。关于这一点,我们会在下一节中详细介绍。
