

在 golang 中最经常使用的容器可能并不是 array 而是 slice,而使用 slice 时一定会要先理解两个内建函数 len 和 cap 的概念,以及如何对 slice 进行 append 操作。
len 和 cap
从别的语言转过来学习 golang 的时候,可能简单地把 slice 当作数组来看待,一般来说它也只有一个 len 的内建函数代表这个容器当前持有元素的个数。但是 golang 中的 slice 同 C++ 的 vector 很像,有着 len(长度)和 cap(容量)这两种概念。
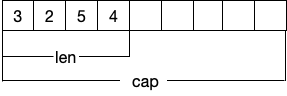
当有一个 []string 类型的值 s 时,实际上 s 会持有一个底层的数组,这个底层数组的长度就是 cap(s) 的大小,而 len(s) 则代表你能通过 s 访问到其底层数组的长度。简单来说可以理解为 len(s) 就是当前 s 所持有元素的个数,而 cap(s) 则代表 s 可以容纳元素的最大个数。可以简单按照下面这张图来进行理解:
那如果一个 slice 的容量是 5,而它当前已经有 5 个元素了,这时候继续对它进行新元素的增加怎么办?这时候就会发生扩容操作,扩容逻辑如下:
- 如果当前 slice 容量足以容纳新增元素,则不会扩容;
- 如果新增元素后的容量不足,则会扩容为原容量的 2 倍大小(或者是原容量的 n 倍,按照实际上新增元素的个数来决定),然后将底层数组原来的元素 copy 到扩容后的新数组上,添加新的元素后将 slice 的引用地址指向新的数组;
- 如果原 slice 容量已经达到了 1024,那最终扩容后的容量等于每次扩容前增加 1/4 ,直到满足最终容量大于等于新申请的容量。
以上这部分逻辑可以直接通过 golang 的 growslice 方法来得出结论。
那为什么 slice 的扩容是按照这种方式进行的呢,为什么不是每次 append 新元素时单独对要新增的元素进行容量扩容呢?这就涉及到平摊分析中的一点知识了。
扩容策略
从结果考虑,每次 slice 进行扩容的时候,要经历以下几个步骤:
- 为最终的容量申请到足够的内存空间;
- 从原有内存地址中将元素 copy 到新的内存中;
- 销毁原有内存地址中的元素;
也就是说,不考虑申请内存和销毁内存占用所需要的时间复杂度,对于一个元素个数为 n 的 slice,对它进行一次扩容需要 O(n) 的时间复杂度。
现在假设,每次对 slice 进行新元素的 append 操作时,都把 slice 的容量 +1,这样的话不会浪费一丁点的内存空间,但我们来算一下时间复杂度需要多少。假设在此操作的前提下,我们有一个空的 slice,然后对它依次添加 k 个元素,而每次扩容复杂度为 O(n),从 0 到 k 个元素扩容所需要的复杂度为
O(1 + 2 + 3 + ... + k) = O(n(n + 1) / 2)
从这个平方级别的复杂度来看这简直是个巨慢无比的操作。
所以每次 append 时都进行 +1 的扩容显然不可接受,那我们这样假设,每次进行新元素的 append 操作时,把 slice 的容量增加一个常数 C,也就是说每次扩容时会多处一个长度为 C 的内存块,那假设我们扩容了 k 次,也就是多处了 k 个长度为 C 的内存块,第一次扩容需要复制 C 个元素,第二次扩容需要复制 2 * C 个元素,以此类推,忽略常数级别的复杂度,最终的复杂度依然是 O(1 + 2 + ... + k),还是平方级别的。
那 golang 采用的每次容量不够的时候进行 2 倍扩容,这样的复杂度是多少呢?我们假设有一个 即将要发生扩容的 slice,在进行几次扩容之后它的 len 和 cap 都为 n,见下图:

也就是说,从一开始到经历过几次扩容之后,最终的 n 个元素中,有 n/2 个元素没有发生过 copy 操作,有 n/4 个元素只发生过 1 次的 copy 操作,有 n/8 个元素发生过 2 次的 copy 操作,依次计算下去,总过进行过 copy 的操作有 n/2 + n/4 + n/8 + n/16 + ...,当 n 足够大时,这个最终结果趋向等于 n,也就是说这种扩容策略的时间复杂度为 O(n),相比较平方级别的复杂度,这种效率明显增加了非常非常多。
看到这里可能有人会有疑问,那为什么一定要进行 2 倍的扩容策略呢,对这个好奇的人,可以参考一下 FBVector 这个实现,它里面并未按照原有 C++ 标准库按照 2 倍扩容的策略,而是使用 1.5 倍的扩容。
append 操作
了解了 len 和 cap 以及扩容策略,那看一下下面的这段代码,想一下它的输出结果是什么
package main
import "fmt"
func main() {
a := []int{1}
a = append(a, 2)
a = append(a, 3)
b := append(a, 4)
c := append(a, 5)
fmt.Println(a)
fmt.Println(b)
fmt.Println(c)
}
[1 2 3]
[1 2 3 5]
[1 2 3 5]
乍一看,这个输出结果跟直觉上的不太一样,但结合上述的扩容策略思考一下,其实这个结论就很显然易见了。一开始 a 的元素为 5,在经历过两次 append 操作之后,a 的 cap 变为了 4,这时候
append 4 和 5 这两个操作是分别为 a 添加了 4 和 5 的操作且并没有触发扩容,但是这两个操作的结果并没有赋值给 a,后一个操作覆盖了前一个操作,且最终的 a b c 指向的都是同一个地址,所以会得出这样的结果。
在 golang 的文档中关于 append 方法有这样一句话,“It is therefore necessary to store the result of append, often in the variable holding the slice itself”,所以上述的代码没有把 append 的结果赋值给原来的
slice,这样的做法往往是不推荐的。
