


前言
为了降低加载时间,相信大多数人都做过如下尝试
- Keep-alive: TCP持久连接,增加了TCP连接的复用性,但只有当上一个请求/响应完全完成后,client才能发送下一个请求
- Pipelining: 可同时发送多个请求,但是服务器必须严格按照请求的先后顺序返回响应,若第一个请求的响应迟迟不能返回,那后面的响应都会被阻塞,也就是所谓的队头阻塞
- 请求合并:雪碧图,css/js内联、css/js合并等,然而请求合并又会带来缓存失效、解析变慢、阻塞渲染、木桶效应等诸多问题
- 域名散列:绕过了同域名最多6个TCP的限制,但增加了DNS开销和TCP开销,也会大幅降低缓存的利用率
- ……
不可否认,这些优化在一定程度上降低了网站加载时间,但对于一个web应用庞大的请求量来说,这些只是冰上一角、隔靴搔痒。
以上问题归根结底是HTTP1.1协议本身的问题,若要从根本上解决HTTP1.1的低效,只能从协议本身入手。为此Google开发了SPDY协议,主要是为了降低传输时间;基于SPDY协议,IETF和SPDY组全体成员共同开发了HTTP/2,并在2015年5月以RFC 7504正式发表。SPDY或者HTTP/2并不是一个全新的协议,它只是修改了HTTP的请求与应答在网络上的传输方式,增加了一个spdy传输层,用于处理、标记、简化和压缩HTTP请求,所以它们并不会破坏现有程序的工作,对于支持的场景,使用新特性可以获得更快的速度,对于不支持的场景,也可以实现平稳退化。
HTTP/2继承了spdy的多路复用、优先级排序等诸多优秀特性,也额外做了不少改进。其中较为显著的改进是HTTP/2使用了一份经过定制的压缩算法,以此替代了SPDY的动态流压缩算法,用于避免对协议的Oracle攻击。
多数主流浏览器已在2015年底支持了该标准(划重点)。具体支持度如下:
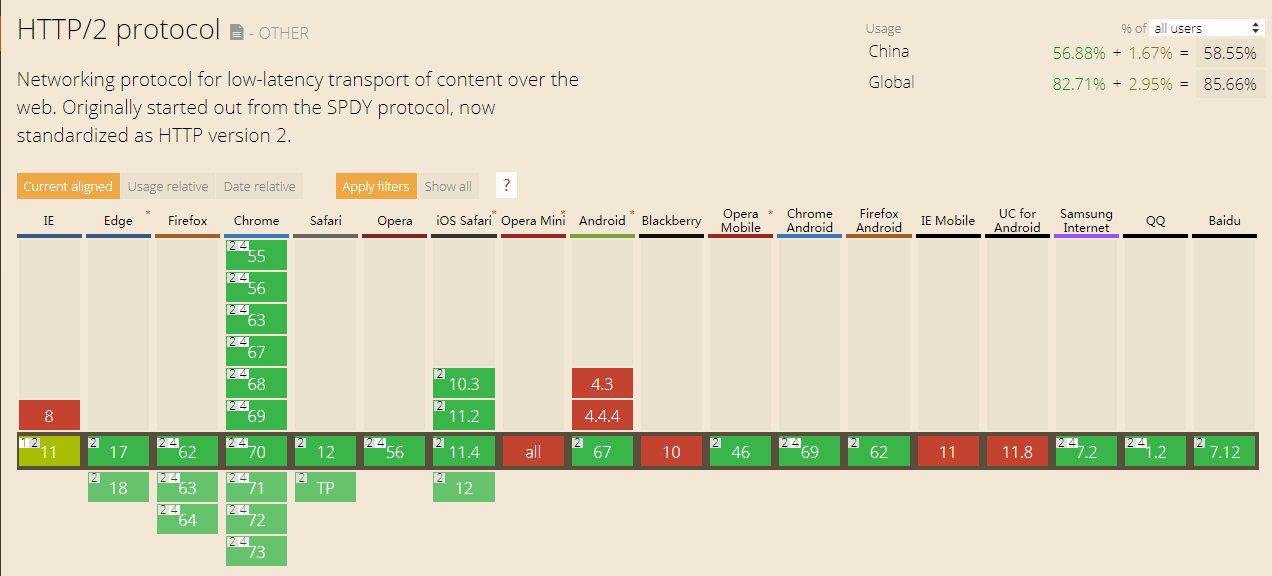
可以看到国内有58.55%的浏览器已经完全支持HTTP/2,而全球的支持度更是高达85.66%。这么高的支持度,so,你心动了吗
why HTTP/2
二进制格式传输
我们知道HTTP/1.1的头信息肯定是文本(ASCII编码),数据体可以是文本,也可以是二进制(需要做自己做额外的转换,协议本身并不会转换)。而在HTTP/2中,新增了二进制分帧层,将数据转换成二进制,也就是说HTTP/2中所有的内容都是采用二进制传输。
使用二进制有什么好处吗?当然!效率会更高,而且最主要的是可以定义额外的帧,如果用文本实现帧传输,解析起来将会十分麻烦。HTTP/2共定义了十种帧,较为常见的有数据帧、头部帧、PING帧、SETTING帧、优先级帧和PUSH_PROMISE帧等,为将来的高级应用打好了基础。
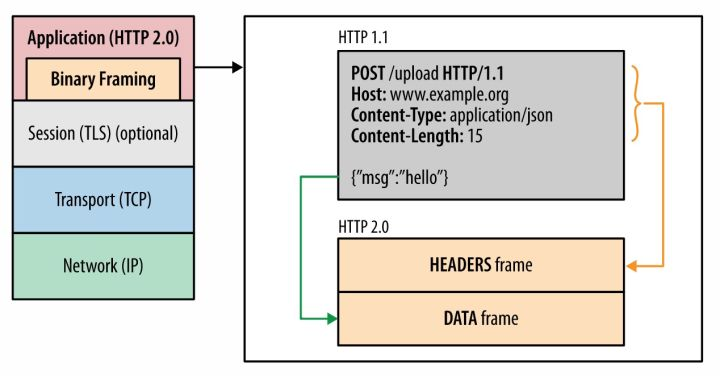
如上图,Binary Framing就是新增的二进制分帧层。
多路复用
二进制分帧层把数据转换为二进制的同时,也把数据分成了一个一个的帧。帧是HTTP/2中数据传输的最小单位;每个帧都有stream_ID字段,表示这个帧属于哪个流,接收方把stream_ID相同的所有帧组合到一起就是被传输的内容了。而流是HTTP/2中的一个逻辑上的概念,它代表着HTTP/1.1中的一个请求或者一个响应,协议规定client发给server的流的stream_ID为奇数,server发给client的流ID是偶数。需要注意的是,流只是一个逻辑概念,便于理解和记忆的,实际并不存在。
理解了帧和流的概念,完整的HTTP/2的通信就可以被形象地表示为这样:
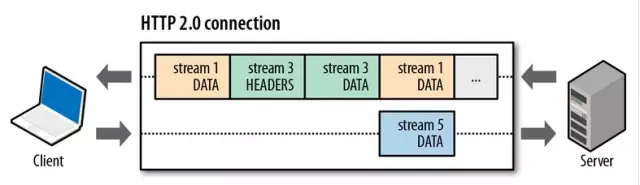
可以发现,在一个TCP链接中,可以同时双向地发送帧,而且不同流中的帧可以交错发送,不需要等某个流发送完,才发送下一个。也就是说在一个TCP连接中,可以同时传输多个流,即可以同时传输多个HTTP请求和响应,这种同时传输不需要遵循先入先出等规定,因此也不会产生阻塞,效率极高。
在这种传输模式下,HTTP请求变得十分廉价,我们不需要再时刻顾虑网站的http请求数是否太多、TCP连接数是否太多、是否会产生阻塞等问题了。
HPACK 首部压缩
为什么需要压缩?
在 HTTP/1 中,HTTP 请求和响应都是由「状态行、请求 / 响应头部、消息主体」三部分组成。一般而言,消息主体都会经过 gzip 压缩,或者本身传输的就是压缩过后的二进制文件(例如图片、音频),但状态行和头部却没有经过任何压缩,直接以纯文本传输。
随着 Web 功能越来越复杂,每个页面产生的请求数也越来越多,根据 HTTP Archive 的统计,当前平均每个页面都会产生上百个请求。越来越多的请求导致消耗在头部的流量越来越多,尤其是每次都要传输 UserAgent、Cookie 这类不会频繁变动的内容,完全是一种浪费。
为了减少冗余的头部信息带来的消耗,HTTP/2采用HPACK 算法压缩请求和响应的header。下面这张图非常直观地表达了HPACK头部压缩的原理:
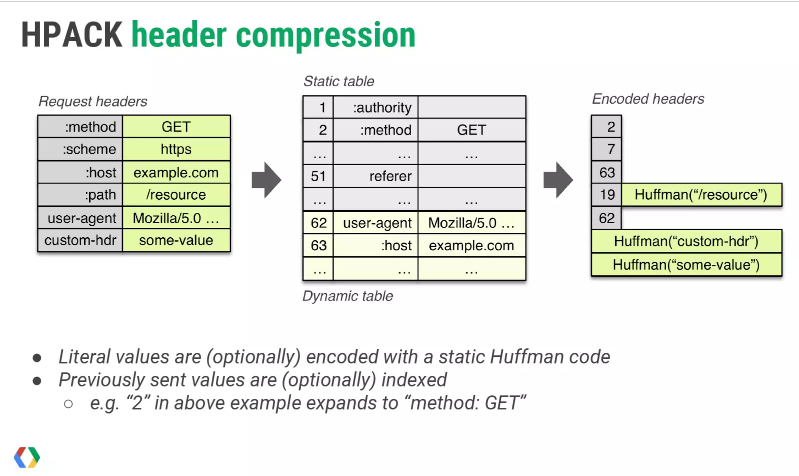
具体规则可以描述为:
- 通信双方共同维护了一份静态表,包含了常见的头部名称与值的组合
- 根据先入先出的原则,维护一份可动态添加内容的动态表
- 用基于该静态哈夫曼码表的哈夫曼编码数据
当要发送一个请求时,会先将其头部和静态表对照,对于完全匹配的键值对,可以直接使用一个数字表示,如上图中的2:method: GET,对于头部名称匹配的键值对,可以将名称使用一个数字传输,如上图中的19:path: /resource,同时告诉服务端将它添加到动态表中,以后的相同键值对就用一个数字表示了。这样,像cookie这些不经常变动的值,只用发送一次就好了。
server push
在开始HTTP/2 server push 前,我们先来看看一个HTTP/1.1的页面是如何加载的。
<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" href="style.css">
<script src="user.js"></script>
</head>
<body>
<h1>hello http2</h1>
</body>
</html>
- 浏览器向服务器请求
/user.html - 服务器处理请求,把
/user.html发给浏览器 - 浏览器解析收到的
/user.html,发现还需要请求/user.js和style.css静态资源 - 分别发送两个请求,获取
/user.js和style.css - 服务器分别响应两个请求,发送资源
- 浏览器收到资源,渲染页面
至此,这个页面才加载完毕,可以被用户看到。可以发现在步骤3和4中,服务器一直处于空闲等待状态,而浏览器到第6步才能得到资源渲染页面,这使页面的首次加载变得缓慢。
而HTTP/2的server push允许服务器在未收到请求时就向浏览器推送资源。即服务器发送/user.html后,就可以主动把/user.js和style.csspush给浏览器,使资源提前达到浏览器。这也是HTTP/2协议里面唯一一个需要开发者自己配置的功能。其他功能都是服务器和浏览器自动实现,无需开发者介入。
在HTTP1.1时代,也有提前获取资源的方法,如preload和prefetch,前者是在页面解析初期就告诉浏览器,这个资源是浏览器马上要用到的,可以立刻发送对资源的请求,当需要用到该资源时就可以直接用而不用等待请求和响应的返回了;后者是当前页面用不到但下一页面可能会用到的资源,优先级较低,只有当浏览器空闲时才会请求prefetch标记的资源。从应用层面上看,preload和server push并没有什么区别,但是server push减少浏览器请求的时间,略优于preload,在一些场景中,可以将两者结合使用。
实战
纸上谈兵终觉浅,来实践一下吧!亲手搭建自己的 HTTP/2 demo,并抓包验证。
spdy这个库实现了 HTTP/2,同时也提供了对express的支持,所以这里我选用spdy + express搭建demo。demo源码
路径说明:
- ca/ 证书、秘钥等文件
- src/
- img/
- js/
- page1.html
- server.js
HTTPS 秘钥和证书
虽然HTTP/2有加密(h2)和非加密(h2c)两种形式,但大多主流浏览器只支持h2-基于TLS/1.2或以上版本的加密连接,所以在搭建demo前,我们首先要自颁发一个证书,这样就可以在浏览器访问中使用https了,你可以自行搜索证书颁发方法,也可以按照下述步骤去生成
首先要安装open-ssl,然后执行以下命令
$ openssl genrsa -des3 -passout pass:x -out server.pass.key 2048
....
$ openssl rsa -passin pass:x -in server.pass.key -out server.key
writing RSA key
$ rm server.pass.key
$ openssl x509 -req -sha256 -days 365 -in server.csr -signkey server.key -out server.crt
....
$ openssl x509 -req -sha256 -days 365 -in server.csr -signkey server.key -out server.crt
然后你就会得到三个文件server.crt, server.csr, server.key,将它们拷贝到ca文件夹中,稍后会用到。
搭建HTTP/2服务
express是一个Node.js框架,这里我们用它声明了路由/,返回的html文件page1.html中引用了js和图片等静态资源。
// server.js
const http2 = require('spdy')
const express = require('express')
const app = express()
const publicPath = 'src'
app.use(express.static(publicPath))
app.get('/', function (req, res) {
res.setHeader('Content-Type', 'text/html')
res.sendFile(__dirname + '/src/page1.html')
})
var options = {
key: fs.readFileSync('./ca/server.key'),
cert: fs.readFileSync('./ca/server.crt')
}
http2.createServer(options, app).listen(8080, () => {
console.log(`Server is listening on https://127.0.0.1:8080 .`)
})
用浏览器访问https://127.0.0.1:8080/,打开控制台可以看所有的请求和它们的瀑布图:
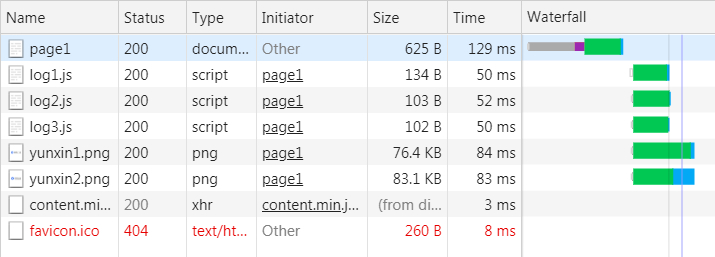
可以清楚地看到,当第一个请求,也就是对document的请求完全返回并解析后,浏览器才开始发起对js和图片等静态资源的的请求。前面说过,server push允许服务器主动向浏览器推送资源,那么是否可以在第一个请求未完成时,就把接下来所需的js和img推送给浏览器呢?这样不仅充分利用了HTTP/2的多路复用,还减少了服务器的空闲等待时间。
对路由的处理函数进行改造:
app.get('/', function (req, res) {
+ push('/img/yunxin1.png', res, 'image/png')
+ push('/img/yunxin2.png', res, 'image/png')
+ push('/js/log3.js', res, 'application/javascript')
res.setHeader('Content-Type', 'text/html')
res.sendFile(__dirname + '/src/page1.html')
})
function push (reqPath, target, type) {
let content = fs.readFileSync(path.join(__dirname, publicPath, reqPath))
let stream = target.push(reqPath, {
status: 200,
method: 'GET',
request: { accept: '*/*' },
response: {
'content-type': type
}
})
stream.on('error', function() {})
stream.end(content)
}
来看下应用了server push的瀑布图:
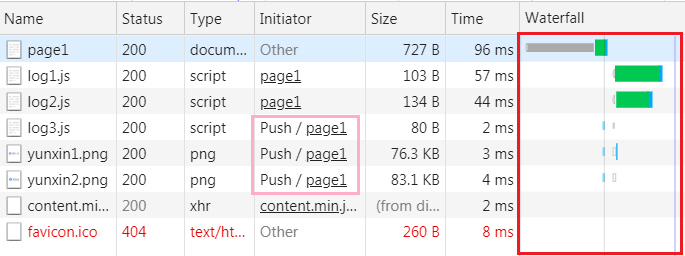
很明显,被push的静态资源可以很快地被使用,而没有被push的资源,如log1.js和log2.js则需要经过较长的时间才能被使用。
浏览器控制台看到的东西毕竟很有限,我们来玩点更有意思的~
wireshark 抓包验证
wireshark是一款可以识别HTTP/2的抓包工具,它的原理是直接读取并分析网卡数据,我们用它来验证是否真正实现了HTTP/2以及其底层通信原理。
首先去官网下载安装包并安装wireshark,这一步没啥好说的。
我们知道,http/2里的请求和响应都被拆分成了帧,如果我们直接去抓取HTTP/2通信包,那抓到的只能是一帧一帧地数据,像这样:
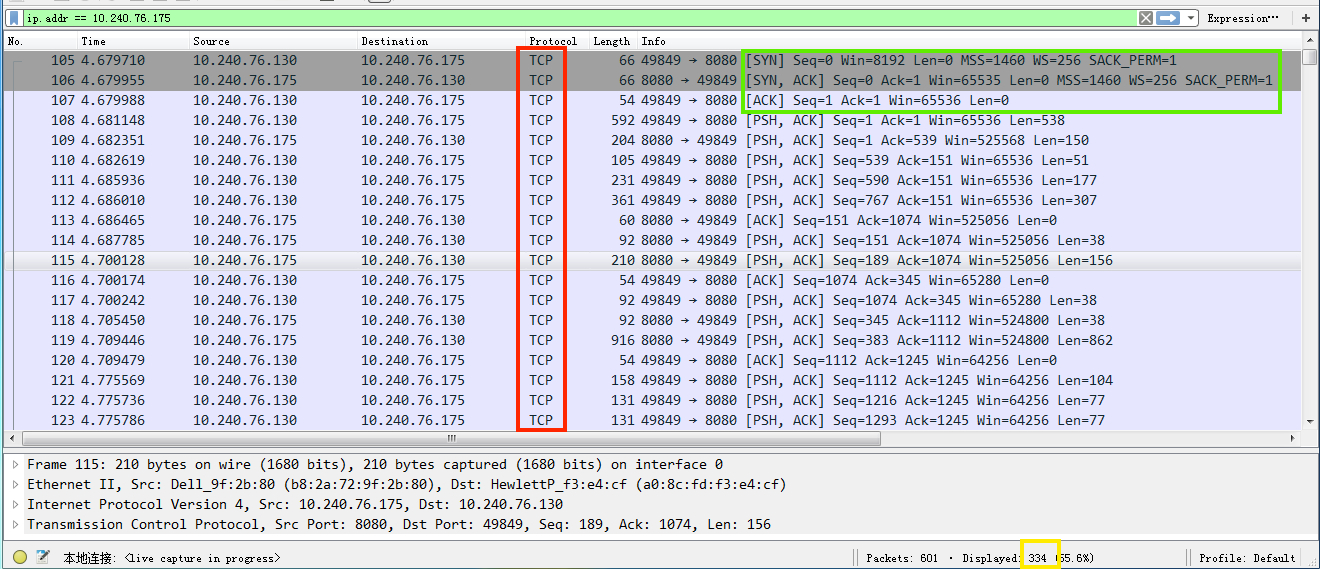
可以看到,抓到的都是TCP类型的包(红色方框);观察前三个包的内容(绿色方框),分别是SYN、[SYN, ACK]和ACK,这就我们所熟知的TCP三次握手;右下角的黄色小方框是请求当前页面后抓到的TCP包的总数,其实这个页面只有七八个请求,但抓到的包的数量却有334个,这也验证了HTTP/2的请求和响应的确是被分成了一帧一帧的。
抓HTTP1.1的包,我们可以清楚地看到都有哪些请求和响应,它们的协议、大小等,而HTTP/2的数据包却是一帧一帧地,那么怎么看HTTP/2都有哪些请求和响应呢?其实wireshark会自动帮我们重组拥有相同stream_ID的帧,重组后就可看到实际有哪些请求和响应了,但是因为我们用的是https,所有的数据都被加密了,wireshark就不知道该怎么去重组了。
有两个办法可以在wireshark中解密 HTTPS 流量:第一如果你拥有 HTTPS 网站的加密私钥,可以用加密私钥来解密这个网站的加密流量;2)某些浏览器支持将 TLS 会话中使用的对称密钥保存在外部文件中,可供 Wireshark 解密使用。
但是HTTP/2为了前向安全性,不允许使用RAS秘钥交换,所有我们无法使用第一个方法来解密HTTP/2流量。介绍第二种方法:当系统环境变量中存在SSLKEYFILELOG时,Chrome和firefox会将对称秘钥保存在该环境变量指向的文件中,然后把这个文件导入wireshark,就可以解密HTTP/2流量了,具体做法如下:
- 新建ssl.log文件
- 添加系统环境变量
SSLKEYFILELOG,指向第一步创建的文件 - 在wireshark中打开 preferences->Protocols,找到SSL,将配置面板的 「(Pre)-Master-Secret log filename」选中第一步创建的文件
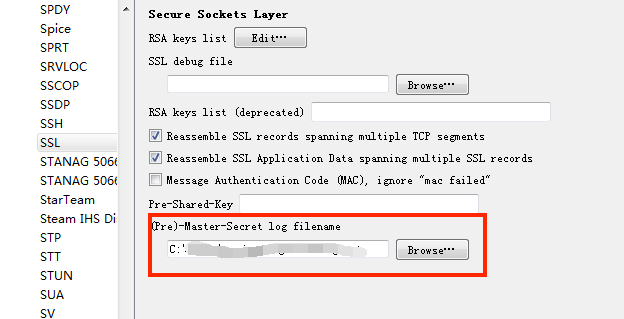
这时用Chrome或Firefox访问任何一个https页面,ssl.log中应该就有写入的秘钥数据了。
解密完成后,我们就可以看到HTTP/2的包了
下图是在demo的主页面抓取的包,可以清楚地看到有哪些HTTP/2请求。
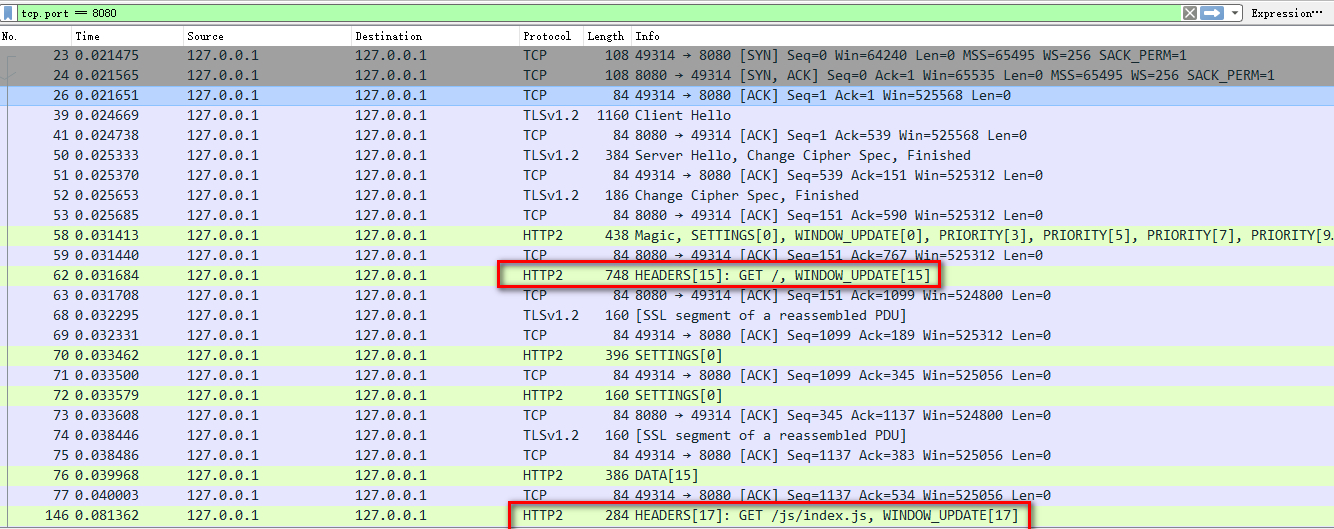
HTTP/2协议中的流和可以在一个TCP连接中交错传输,只需建立一个TCP连接就可以完成和服务器的所有通信,我们来看下在demo中的HTTP/2是不是这样的:
wireshark下方还有一个面板,里面有当前包的具体信息,如大小、源IP、目的IP、端口、数据、协议等,在Transmission Control Protocol下有一个[Stream index],如下图,它是TCP连接的编号,代表当前包是从哪个TCP连接中传输的。观察demo页面请求产生的包,可以发现它们的stream index 都相同,说明这些HTTP/2请求和响应是在一个TCP连接中被传输的,这么多流的确复用了一个TCP连接。
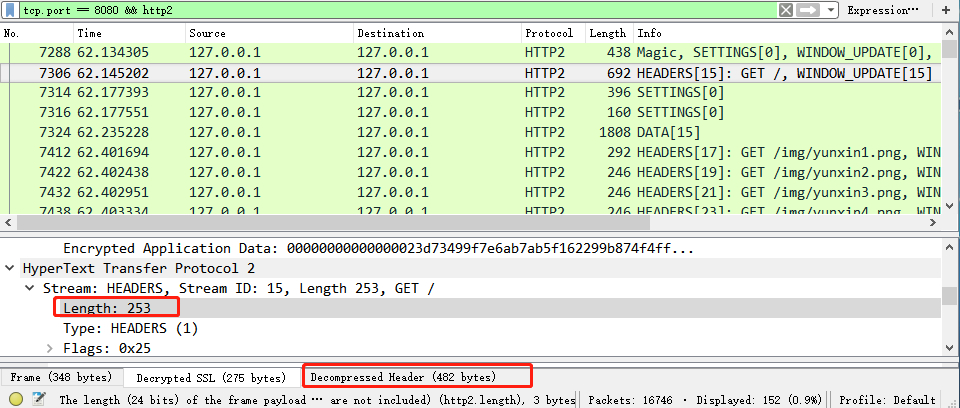
除了多路复用外,我们还可以通过抓包来观察HTTP/2的头部压缩。下图是当前路由下的第一个请求,实际被传输的头部数据有253bytes,解压后的头部信息有482bytes。压缩后的大小减少了几乎一半
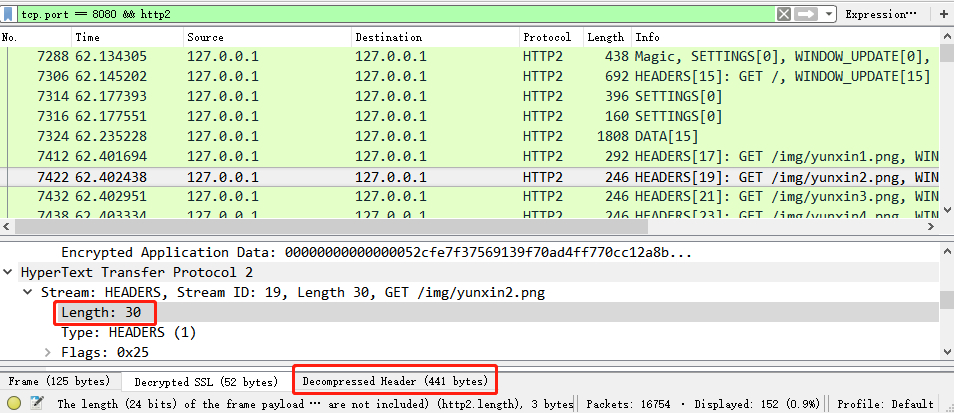
但这只是第一个请求,我们看看后来的请求,如第三个,实际传输的头部大小只有30bytes,而解压后的大小有441byte,压缩后的体积仅为原来的1/14!如今web应用单是一个页面就动辄几百的请求数,HPACK能节约的流量可想而知。
结语
在文章开篇,我们列举了HTTP1.x时代的困境,引入并简要说明了HTTP/2的起源;然后对比着HTTP1.x,介绍了HTTP/2的诸多优秀特性,来说明为什么选择HTTP/2;在文章的最后一部分,介绍了如何一步一步搭建一个HTTP/2实例,并抓包观察,验证了HTTP/2的多路复用,头部压缩等特性。最后,您是否也被这些高效特性吸引了呢?动手试试吧~
参考:
- HTTP/2 维基百科
- w3c-preload
- HTTP/2 Server Push with Node.js
- 使用 Wireshark 调试 HTTP/2 流量
- Optimize Your App with HTTP/2 Server Push Using Node and Express
- web性能优化与HTTP/2
想要阅读更多技术干货、行业洞察,欢迎关注网易云信博客。
了解网易云信。,来自网易核心架构的通信与视频云服务。
网易云信(NeteaseYunXin)是集网易18年IM以及音视频技术打造的PaaS服务产品,来自网易核心技术架构的通信与视频云服务,稳定易用且功能全面,致力于提供全球领先的技术能力和场景化解决方案。开发者通过集成客户端SDK和云端OPEN API,即可快速实现包含IM、音视频通话、直播、点播、互动白板、短信等功能。
