

作为一名上班族,随着现在广州地铁安检新规的实施,每天进地铁都得过安检机了,安检机确实能保证乘客们的生命财产安全,预防危险事件的发生,同时能减缓人流(好还是坏?),减轻运输压力。但随着规定的推行,安检机的人工操作慢慢地显示出一些弊端。本文将从人工检查的弊端开始分析,然后基于技术上对神经网络做安检分析进行纸上谈兵式的讨论,有想法的读者欢迎在评论区交流。
漏检
曾经一次和朋友参加婚礼的时候,朋友拿出了他的发胶喷雾在做发型,因为朋友是坐地铁来的,我问他怎么带过来的发胶喷雾。他说直接装在包里面,安检机就给过了,也没人查他。旁边一位曾经担任过地铁警员的朋友就诧异道,这瓶喷雾按道理来说是绝对能检出来的,安检机一定能显示出它的形状,除非就是安检员没看监控屏幕!
安检员每天要看无数个包包经过安检机,有可能只是一时遗漏了而非没看屏幕,那么问题来了,人始终是人,注意力会有分散的时候,如何能保证人工检查的时候不开小差呢?

繁重
在思考这个问题的时候,特意在知乎搜了下相关的问题,一位匿名用户给出的答案说出了许多安检员的心声:如何评价国内地铁安检? - 知乎 。我们摘录部分吐槽:
能手检的时候,基本上就是看一眼包面,人就可以进站了,而且是必须得看一眼乘客的包,我们每天就像傻子一样,抬头低头抬头低头,有种脖子要断的感觉,眼睛也很难受啊。你就是看不到,也得做个拦的手势,不然,呵呵,被监控拍到就是一张罚单。而且我们还不能强行让乘客过包,乘客骂你你得受着(这个毕竟服务行业,我也能理解),乘客凶,就可以不过包,不凶,就可以拼命拦(我也不知道为什么会有这样不成文的规矩╮(╯▽╰)╭)。
作者:匿名用户
链接:https://www.zhihu.com/question/24890580/answer/240323815
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
所以你看,安检员也是非常难受的,每天都要低头看屏幕,眼睛疼脖子酸不说,不看的话被摄像头拍到又要开罚单,在这里先给安检员们致以深深的敬意。人始终不是机器,重复单调的劳动影响人的身体,也影响安检的效果。
机器如何代劳?
机器学习界大牛吴恩达老师说过:“只要是人类在正常情况下1秒就能做到的事情,人工智能都可以做到。”为大家解释一下吴老师的意思,人类在做一些操作重复、能根据一定规律执行的动作时,也就是假如这个操作是“有套路的”,那么人工智能或者说机器学习,就能从大量的案例当中学习出这个“套路”,甚至做得比人类还好。在计算机视觉领域,有一个著名的大赛:ILSVRC(ImageNet Large Scale Visual Recognition Competition),也就是由斯坦福李飞飞教授举办的ImageNet大规模视觉识别大赛,从2010年开始,已经举办到第8年,其中图像分类项目在2015年的时候,机器分类的成功率已经全面超越人类:
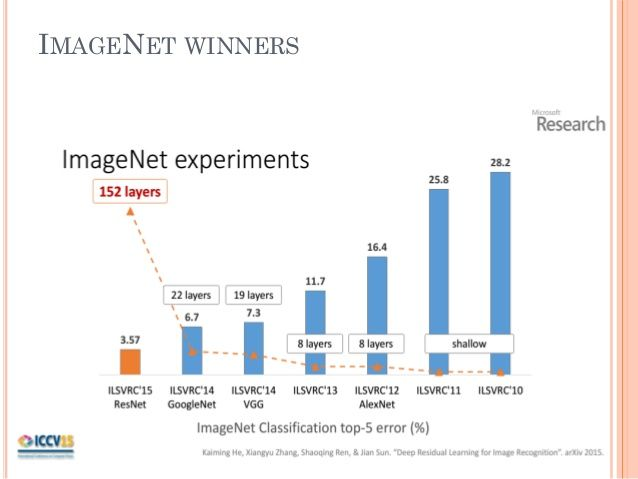
图像分类比赛的任务是,参赛者需要在大量的图片当中,对图片进行分类,分类类别数达到1000类,2015年Kaiming He[1]的团队发明的ResNet把错误率降到3.57%,超越人类表现。试想一下,一个在图像分类任务超越人类水平的机器,在进行地铁安检图危险品识别及分类的时候,表现是否会比人类更好、更快?
涉及哪些技术
Object Detection-目标检测
面对地铁安检图,最理想的状况就像图2,物品是按顺序摆放的,而且彼此之间的重叠率不高:
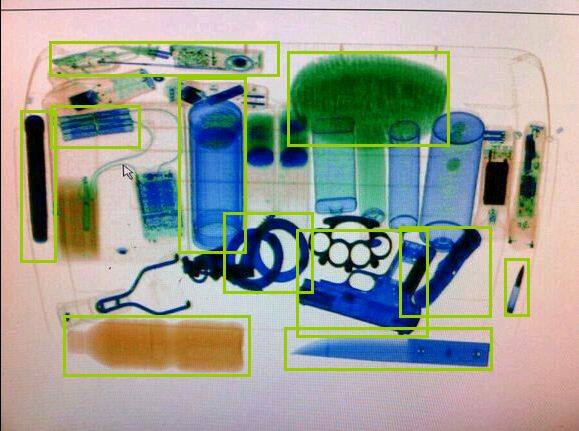
目标检测领域的工作都比较热门和连续,比如RBG大神、Kaiming He团队的一系列的工作:RCNN[2]、fast-RCNN[3]、faster-RCNN[4]都得到了非常好的结果,其中faster-RCNN的准确率目前仍然能保持SOTA(State Of The Art, 顶尖的领先的)。除此之外以速度著称的SSD[5]、YOLO[6]、YOLO9000[7],其中YOLO9000的mAP接近Fast R-CNN的mAP时,运行速度超过90FPS,基本能实现实时监测。

Segmentation-图像分割
在实际应用场景当中,箱包里面的物体并不能如此精确地不重叠摆放,运动过程中肯定会造成物体间有重叠的部分,这时候需要把这些重叠的物体分割出来再进行识别。还好的是安检机对于不同材质的物品呈现出不同的颜色,这有利于物体的分割。

最近最热门最顶尖的工作莫过于Kaiming He团队的mask rcnn[8],对其更多的评价请参见这个链接:如何评价 Kaiming He 最新的 Mask R-CNN?
另外一个也是非常热门的工作来自深度学习先驱者Geoffrey Hinton的CapsuleNet[9],其在重叠手写字体识别的效果上得到令人惊叹的效果:
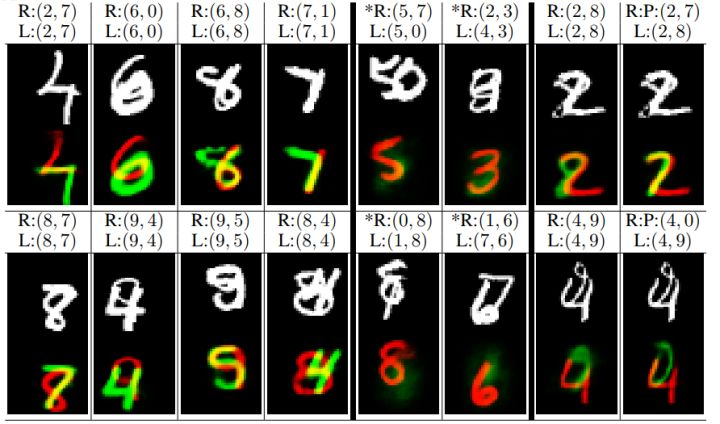
Hinton老爷子的工作让人看到了CapsuleNet极大的可能性,不过由于此领域才刚刚开启,能否用在工业环境中还有待研究。
数据集如何来
据了解,地铁安检机一般是外包给安检公司购买安装的,而且安检员在进行安检培训的时候不能拍照,所以笔者在网上能找到的安检机屏幕显示的图寥寥无几,估计数据都在安检公司当中存放,而且也有可能由于安全或隐私原因不适宜向公众开放。而kaggle上有个相类似的比赛项目,这是一项奖金 150 万美元的竞赛,用于自动识别安检站人体扫描仪拍摄图像中的夹带物品。这个项目的比赛数据是由200名工作人员自己携带一些物品反复通过安检机收集而成,不涉及真实乘客的隐私问题,国内的安检公司或者地铁或许能参考这一做法来设置数据集,举办一个安检机危险品检测识别大赛,设立高额奖金,相信能吸引不少的参赛队伍。
总结
这里针对地铁安检这一场景作了一些“纸上谈兵”式的讨论,探讨了图像目标检测、图像分割是否能用在安检图上的可能性,并没有作出实际的实验证明。同时由于缺乏公开数据集,成为测试这些技术的可行性的一大障碍,因此呼吁地铁部门或者安检公司能制作合适的数据集举办比赛,让深度学习真正为地铁安检加速。有更多想法的朋友欢迎在下面评论回复,我们探讨更多的可能性。
参考文献
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun 2015. Deep Residual Learning for Image RecognitionarXiv:1512.03385 [cs.CV]
[2] Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik 2013. Rich feature hierarchies for accurate object detection and semantic segmentationarXiv:1311.2524 [cs.CV]
[3] Ross Girshick 2015. Fast R-CNNarXiv:1504.08083 [cs.CV]
[4] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun 2015. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks arXiv:1506.01497 [cs.CV]
[5] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg 2015. SSD: Single Shot MultiBox DetectorarXiv:1512.02325 [cs.CV]
[6] Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi 2015. You Only Look Once: Unified, Real-Time Object Detection arXiv:1506.02640 [cs.CV]
[7] Joseph Redmon, Ali Farhadi 2016. YOLO9000: Better, Faster, Stronger arXiv:1612.08242 [cs.CV]
[8] Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick 2017. Mask R-CNN arXiv:1703.06870 [cs.CV]
[9] Sara Sabour, Nicholas Frosst, Geoffrey E Hinton 2017. Dynamic Routing Between CapsulesarXiv:1710.09829 [cs.CV]
