

引子
此时再谈Word2Vec,特别是ELMo、Bert相继大火后,有点炒冷饭的意味。但有一个点,很多同学可能好奇过却没有深究:自然语言处理里面应用Distribution representation做Embedding,word2vec不是第一个,对比Matrix Fatorication的方法,比如SVD、LSA,为何Word2Vec出来后,Emebedding变的这么火?
面试的时候,如果聊得时间有多,会顺便问下这个问题,大多数同学都没有想过这个问题,能提到Word2Vec比如SVD之类的更容易训练更多的数据,已经寥寥无几。
其实这个问题学术界相关的研究很多,但不熟悉的同学往往不知道该用什么关键词,而Word2Vec的相关的文献不计其数,导致真正有价值的信息被埋没了,比如上面这个问题,你如果搜why word2vec so good,出来的大多是描述其原理的(知乎上就有很好的讨论帖[2][3]),需要搜的key是word2vec matrix fatorication,这就需要你了解一些相关的背景。准确的定义问题的描述,往往比问题的答案更重要。
本文参考了一些相关论文,尽量少引入公式(主要是我懒,公式编辑太麻烦了),尝试解答上述问题。
背景知识
Word2Vec
详尽的原理,网上有很多非常好的资料,这里不再赘述。Word2Vec和Deep Learing的关系并不深,至少一点也不Deep。13、14年那段时间,很多学者都在尝试解释它到底学到了什么。无论是CBOW还是Skip-Gram,本质还是要基于word和context做文章,即可以理解为模型在学习word和context的co-occurrence。
参考[1]本文重点关注Skip-Gram with Negative Sample,简称为SGNS,让我们来回顾下它的目标函数:
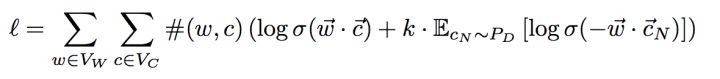
再介绍论文[1]如何将它一步步变成和Matrix Factorization等价前,我们先来了解下MF的背景。
Matrix Factorization
MF即矩阵分解,典型的算法有SVD、LSA,是一种常见的技术,在推荐、NLP都有应用。据资料显示,百度在2010年之前,就做过大规模分布式的plsa算法。简单来讲,MF就是将一个矩阵分解成多个矩阵的乘积。让我们回顾下word2vec,最终每一个word都会有两个向量:V_word和V_context,假设存在一个矩阵W = V_word * V_context,word2vec也可以理解成是对矩阵W的矩阵分解。那么,问题就变成这个matrix W是什么?
Pointwise Mutual Information(PMI)
论文[1]中有将SGNS的目标函数,一步步的变换,变成下面的形式(具体见论文)
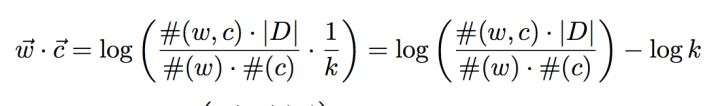
上述公司中,左边的部分就是大名鼎鼎的PMI,即w和c同时出现的次数/(w出现的次数 + c出现的次数)。和MF对比,就多了个常量logk。PMI是dense matrix,对模型优化带来很多困难,所以一般会用sparse matrix PPMI(positive PMI)来替代它。
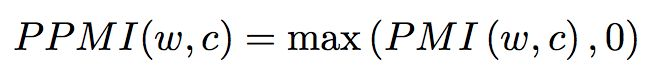
到此,可以说明word2vec和MF并没有本质的区别,是一种implicit的MF,正如论文[1]的标题。既然其本质差别不大,是否MF的测试效果也能和word2vec一致呢。首先,在word similar上,SVD和Word2vec差距并不大,但在word analogies上,word2vec要明显好于SVD。
Why
训练大规模语料的能力
这个当然是核心优点,虽然SVD有SMF的版本去处理大数据,LSA也有大数据的方案,但谁都没有word2vec的简单易实现。google一开始的开源代码,根本不需要分布式就能跑以前不能跑的数据规模。
Simple is Power!
举个不恰当的例子:很多人怀疑牛顿是先发明了微积分,后面才做出了很多重要的工作,为了装逼在他的著作里面用传统的数学方法重写了一遍,各种奇技淫巧。当然这个逼装的有点过,导致后面和莱布尼茨关于微积分的发明权吵了一辈子。
很多论文,因为word2vec的成果,有了方向后再去回溯传统,其价值自然远不如开创者。数据量的问题,在之前可能都不是核心问题,再加上LSA模型稳定,在小数据集上效果挺好,数据规模增长一点不一定能看出收益,而不像word2vec,在数据集小的时候,可能还不如CountVectorizer,必须往大数据去。
再一次,定义问题是什么,比找到方法难。
MF suffer from unobserved value
在word-context matrix中,这是个常见的问题。另外,对matrix中的value做不同的weight也不是件容易的事情。最重要的是,MF类的算法在analogies task上有明显劣势。即当初那个经典的word2vec展示case:king - queen = man - woman,即词向量可以相互做加减,具有实际意义。
这个case有点特殊,并不是所有的词向量都成立,但确实比MF类的模型总体上好。比较酷炫,其原理我还没有找到特别好的解释,如果有童鞋知道,求告知。
融合二者
Glove是其中代表,即结合了global matrix factorization and local context window methods。论文[5]中给出了不错的实验数据,但也有不少人质疑它,比如论文[6]。另外,word2vec比glove简单多了,也更容易被大家接受。我们自己实践来看,glove也没有明显增量。
最后
这篇是好奇心驱动的产物,实用价值并不高,只为答疑解惑。前期在搜索过程中看了不少无效的资料,浪费了不少时间,希望本文能给感兴趣的同学一些帮助。
参考文献
[1] Neural Word Embedding as Implicit Matrix Factorization
[2] word2vec 相比之前的 Word Embedding 方法好在什么地方?
[5]GloVe: Global Vectors for Word Representation [6]Improving Distributional Similarity with Lessons Learned from Word Embeddings
[7]Linguistic Regularities in Sparse and Explicit Word Representations
[8]ALL-BUT-THE-TOP: SIMPLE AND EFFECTIVE POSTPROCESSING FOR WORD REPRESENTATIONS
